從頭捋了一遍Epoll原理,收獲頗豐!
Epoll 是個很老的知識點,是后端工程師的經典必修課。這種知識具備的特點就是研究的人多,所以研究的趨勢就會越來越深。當然分享的人也多,由于分享者水平參差不齊,也產生的大量錯誤理解。
圖片來自 Pexels
今天我再次分享 epoll,肯定不會列個表格,對比一下差異,那就太無聊了。
我將從線程阻塞的原理,中斷優化,網卡處理數據過程出發,深入的介紹 epoll 背后的原理,最后還會 diss 一些流行的觀點。相信無論你是否已經熟悉 epoll,本文都會對你有價值。
正文開始前,先問大家幾個問題:
①epoll 性能到底有多高。很多文章介紹 epoll 可以輕松處理幾十萬個連接。而傳統 IO 只能處理幾百個連接,是不是說 epoll 的性能就是傳統 IO 的千倍呢?
②很多文章把網絡 IO 劃分為阻塞,非阻塞,同步,異步。并表示:非阻塞的性能比阻塞性能好,異步的性能比同步性能好。
如果說阻塞導致性能低,那傳統 IO 為什么要阻塞呢?epoll 是否需要阻塞呢?Java 的 NIO 和 AIO 底層都是 epoll 實現的,這又怎么理解同步和異步的區別?
③都是 IO 多路復用。既生瑜何生亮,為什么會有 select,poll 和 epoll 呢?為什么 epoll 比 select 性能高?
PS:本文共包含三大部分:初識 epoll、epoll 背后的原理 、Diss 環節。本文的重點是介紹原理,建議讀者的關注點盡量放在:“為什么”。
Linux 下進程和線程的區別其實并不大,尤其是在討論原理和性能問題時,因此本文中“進程”和“線程”兩個詞是混用的。
初識 epoll
epoll 是 Linux 內核的可擴展 I/O 事件通知機制,其最大的特點就是性能優異。
下圖是 libevent(一個知名的異步事件處理軟件庫)對 select,poll,epoll ,kqueue 這幾個 I/O 多路復用技術做的性能測試。
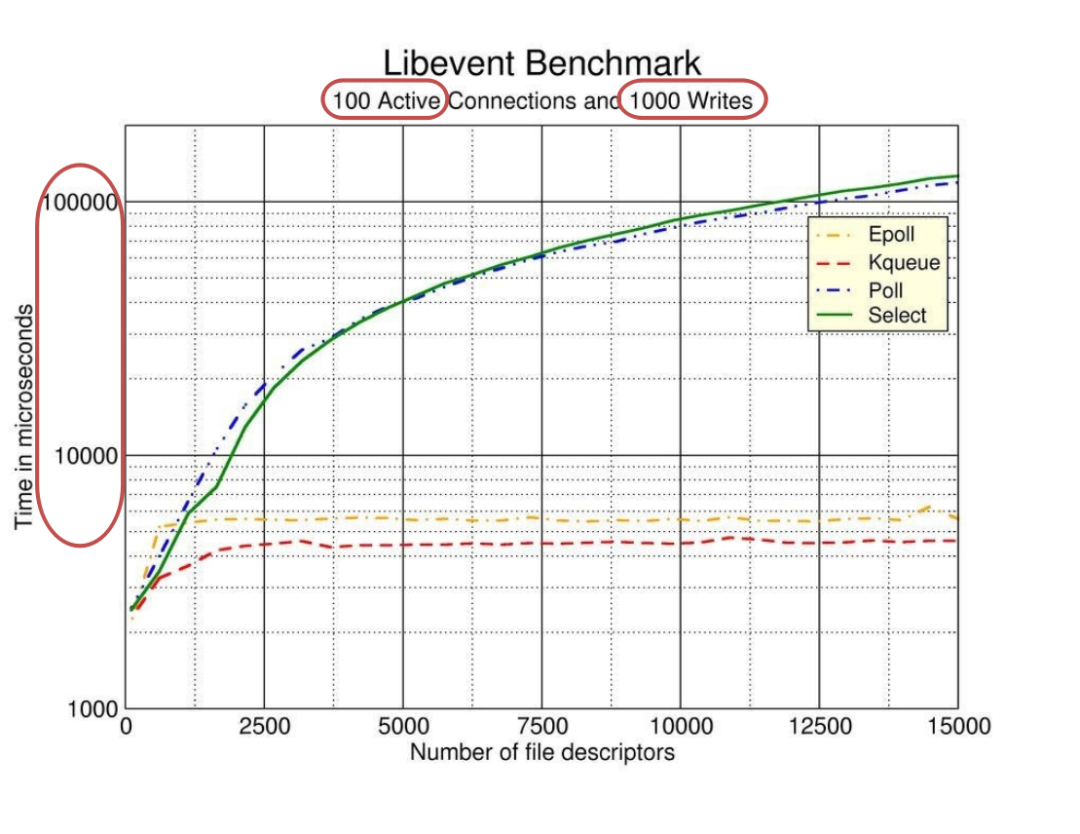
很多文章在描述 epoll 性能時都引用了這個基準測試,但少有文章能夠清晰的解釋這個測試結果。
這是一個限制了 100 個活躍連接的基準測試,每個連接發生 1000 次讀寫操作為止。縱軸是請求的響應時間,橫軸是持有的 socket 句柄數量。
隨著句柄數量的增加,epoll 和 kqueue 響應時間幾乎無變化,而 poll 和 select 的響應時間卻增長了非常多。
可以看出來,epoll 性能是很高的,并且隨著監聽的文件描述符的增加,epoll 的優勢更加明顯。
不過,這里限制的 100 個連接很重要。epoll 在應對大量網絡連接時,只有活躍連接很少的情況下才能表現的性能優異。
換句話說,epoll 在處理大量非活躍的連接時性能才會表現的優異。如果15000個 socket 都是活躍的,epoll 和 select 其實差不了太多。
為什么 epoll 的高性能有這樣的局限性?問題好像越來越多了,看來我們需要更深入的研究了。
epoll 背后的原理
阻塞
①為什么阻塞
我們以網卡接收數據舉例,回顧一下之前我分享過的網卡接收數據的過程。
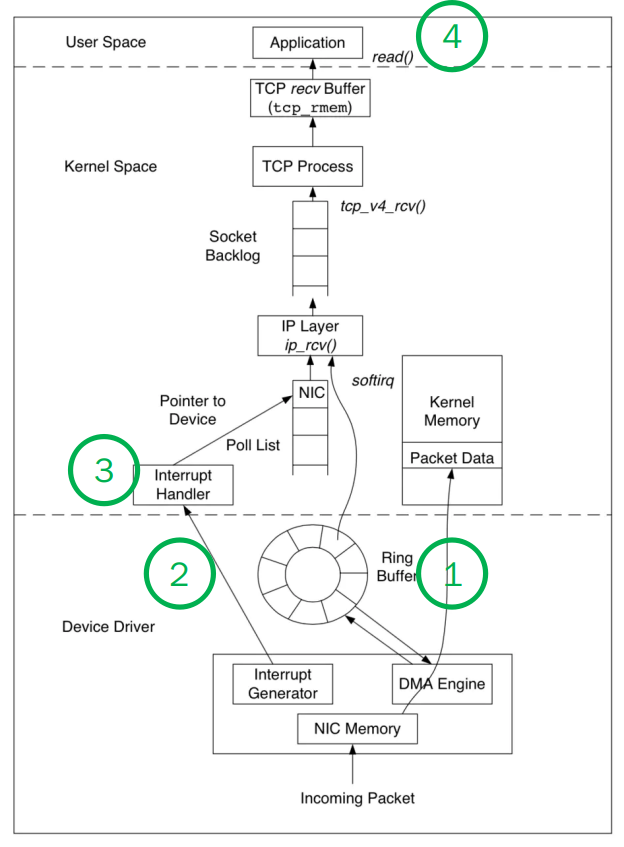
為了方便理解,我盡量簡化技術細節,可以把接收數據的過程分為四步:
- NIC(網卡)接收到數據,通過 DMA 方式寫入內存(Ring Buffer 和 sk_buff)。
- NIC 發出中斷請求(IRQ),告訴內核有新的數據過來了。
- Linux 內核響應中斷,系統切換為內核態,處理 Interrupt Handler,從RingBuffer 拿出一個 Packet, 并處理協議棧,填充 Socket 并交給用戶進程。
- 系統切換為用戶態,用戶進程處理數據內容。
網卡何時接收到數據是依賴發送方和傳輸路徑的,這個延遲通常都很高,是毫秒(ms)級別的。而應用程序處理數據是納秒(ns)級別的。
也就是說整個過程中,內核態等待數據,處理協議棧是個相對很慢的過程。這么長的時間里,用戶態的進程是無事可做的,因此用到了“阻塞(掛起)”。
②阻塞不占用 CPU
阻塞是進程調度的關鍵一環,指的是進程在等待某事件發生之前的等待狀態。
請看下表,在 Linux 中,進程狀態大致有 7 種(在 include/linux/sched.h 中有更多狀態):
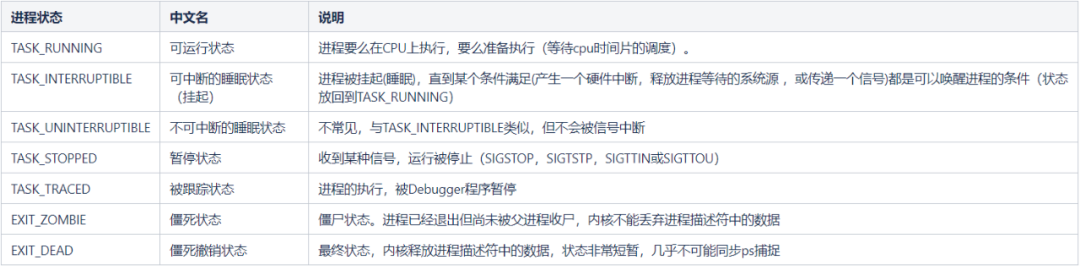
從說明中其實就可以發現,“可運行狀態”會占用 CPU 資源,另外創建和銷毀進程也需要占用 CPU 資源(內核)。重點是,當進程被"阻塞/掛起"時,是不會占用 CPU 資源的。
換個角度來講。為了支持多任務,Linux 實現了進程調度的功能(CPU 時間片的調度)。
而這個時間片的切換,只會在“可運行狀態”的進程間進行。因此“阻塞/掛起”的進程是不占用 CPU 資源的。
另外講個知識點,為了方便時間片的調度,所有“可運行狀態”狀態的進程,會組成一個隊列,就叫“工作隊列”。
③阻塞的恢復
內核當然可以很容易的修改一個進程的狀態,問題是網絡 IO 中,內核該修改那個進程的狀態。
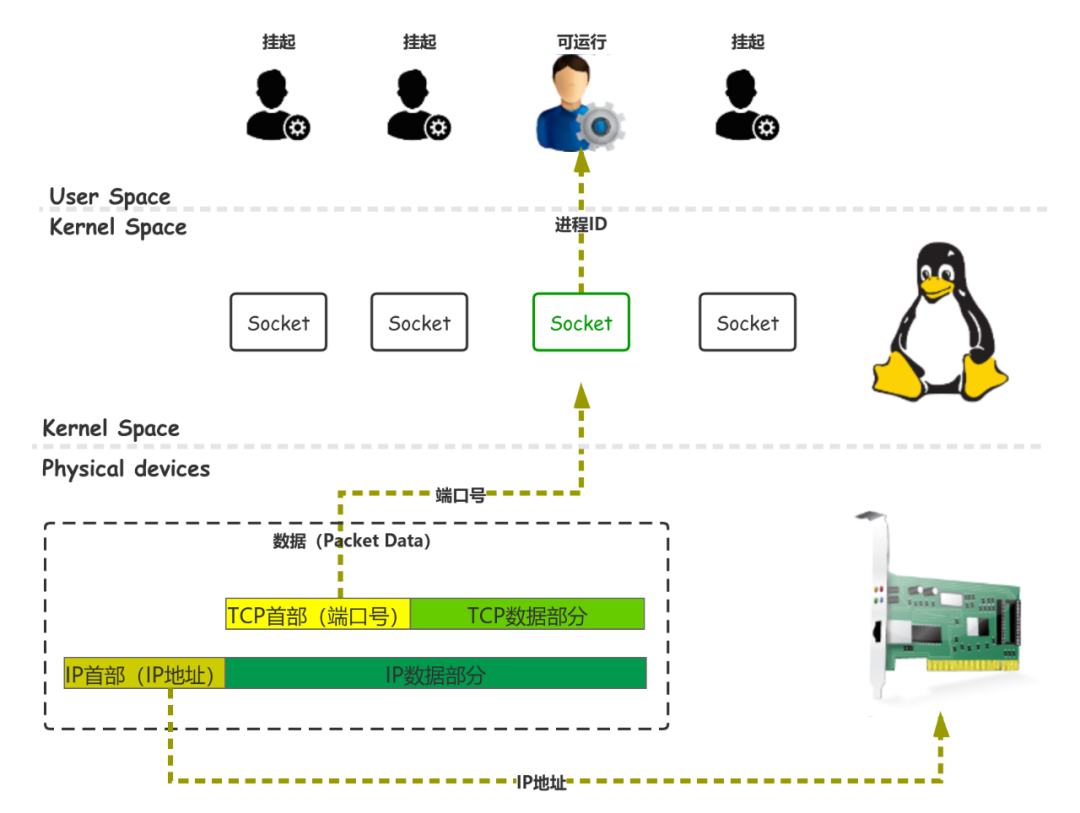
socket 結構體,包含了兩個重要數據:進程 ID 和端口號。進程 ID 存放的就是執行 connect,send,read 函數,被掛起的進程。
在 socket 創建之初,端口號就被確定了下來,操作系統會維護一個端口號到 socket 的數據結構。
當網卡接收到數據時,數據中一定會帶著端口號,內核就可以找到對應的 socket,并從中取得“掛起”進程的 ID。
將進程的狀態修改為“可運行狀態”(加入到工作隊列)。此時內核代碼執行完畢,將控制權交還給用戶態。通過正常的“CPU 時間片的調度”,用戶進程得以處理數據。
④進程模型
上面介紹的整個過程,基本就是 BIO(阻塞 IO)的基本原理了。用戶進程都是獨立的處理自己的業務,這其實是一種符合進程模型的處理方式。
上下文切換的優化
上面介紹的過程中,有兩個地方會造成頻繁的上下文切換,效率可能會很低:
- 如果頻繁的收到數據包,NIC 可能頻繁發出中斷請求(IRQ)。CPU 也許在用戶態,也許在內核態,也許還在處理上一條數據的協議棧。但無論如何,CPU 都要盡快的響應中斷。這么做實際上非常低效,造成了大量的上下文切換,也可能導致用戶進程長時間無法獲得數據。(即使是多核,每次協議棧都沒有處理完,自然無法交給用戶進程)
- 每個 Packet 對應一個 socket,每個 socket 對應一個用戶態的進程。這些用戶態進程轉為“可運行狀態”,必然要引起進程間的上下文切換。
①網卡驅動的 NAPI 機制
在 NIC 上,解決頻繁 IRQ 的技術叫做 New API(NAPI)。
原理其實特別簡單,把 Interrupt Handler 分為兩部分:
- 函數名為 napi_schedule,專門快速響應 IRQ,只記錄必要信息,并在合適的時機發出軟中斷 softirq。
- 函數名為 netrxaction,在另一個進程中執行,專門響應 napi_schedule 發出的軟中斷,批量的處理 RingBuffer 中的數據。
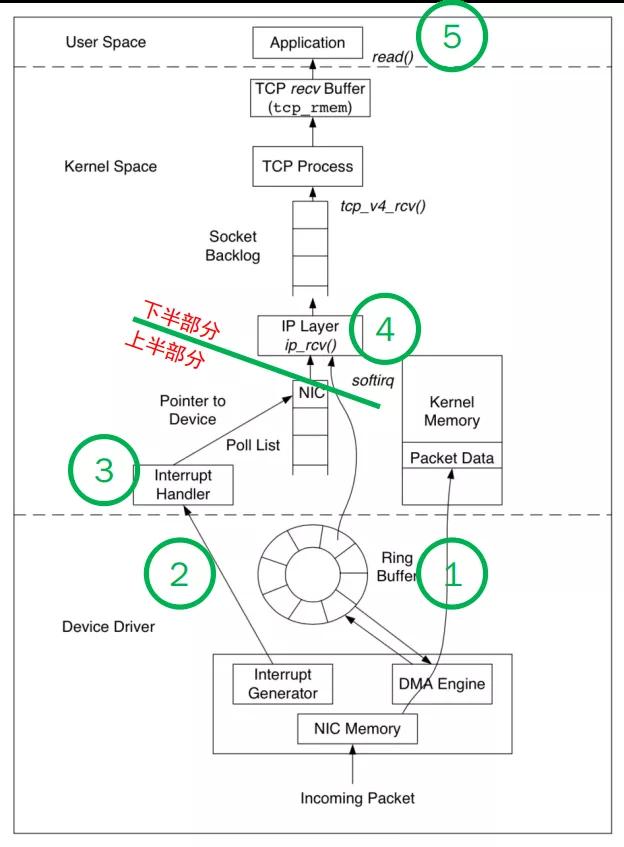
所以使用了 NAPI 的驅動,接收數據過程可以簡化描述為:
- NIC 接收到數據,通過 DMA 方式寫入內存(Ring Buffer 和 sk_buff)。
- NIC 發出中斷請求(IRQ),告訴內核有新的數據過來了。
- driver 的 napi_schedule 函數響應 IRQ,并在合適的時機發出軟中斷(NET_RX_SOFTIRQ)。
- driver 的 net_rx_action 函數響應軟中斷,從 Ring Buffer 中批量拉取收到的數據。并處理協議棧,填充 Socket 并交給用戶進程。
- 系統切換為用戶態,多個用戶進程切換為“可運行狀態”,按 CPU 時間片調度,處理數據內容。
一句話概括就是:等著收到一批數據,再一次批量的處理數據。
②單線程的 IO 多路復用
內核優化“進程間上下文切換”的技術叫的“IO 多路復用”,思路和 NAPI 是很接近的。
每個 socket 不再阻塞讀寫它的進程,而是用一個專門的線程,批量的處理用戶態數據,這樣就減少了線程間的上下文切換。
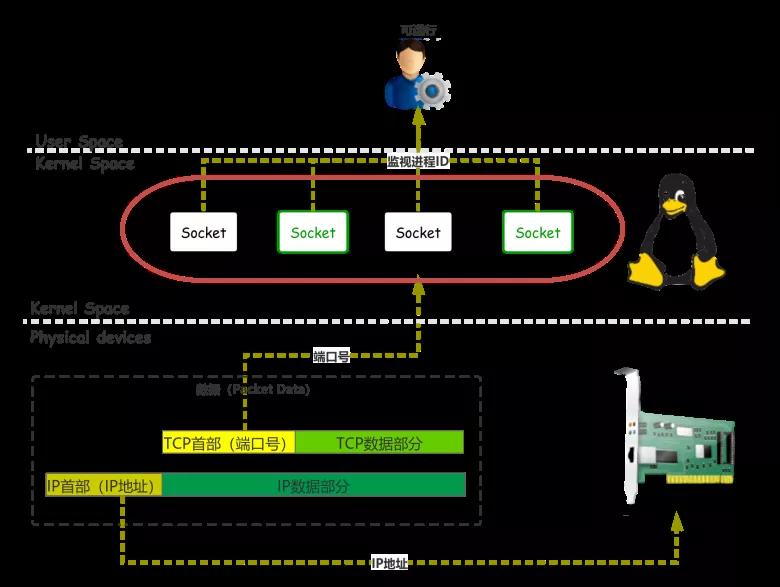
作為 IO 多路復用的一個實現,select 的原理也很簡單。所有的 socket 統一保存執行 select 函數的(監視進程)進程 ID。
任何一個 socket 接收了數據,都會喚醒“監視進程”。內核只要告訴“監視進程”,那些 socket 已經就緒,監視進程就可以批量處理了。
IO 多路復用的進化
①對比 epoll 與 select
select,poll 和 epoll 都是“IO 多路復用”,那為什么還會有性能差距呢?篇幅限制,這里我們只簡單對比 select 和 epoll 的基本原理差異。
對于內核,同時處理的 socket 可能有很多,監視進程也可能有多個。所以監視進程每次“批量處理數據”,都需要告訴內核它“關心的 socket”。
內核在喚醒監視進程時,就可以把“關心的 socket”中,就緒的 socket 傳給監視進程。
換句話說,在執行系統調用 select 或 epoll_create 時,入參是“關心的 socket”,出參是“就緒的 socket”。
而 select 與 epoll 的區別在于:
select (一次O(n)查找):
- 每次傳給內核一個用戶空間分配的 fd_set 用于表示“關心的 socket”。其結構(相當于 bitset)限制了只能保存 1024 個 socket。
- 每次 socket 狀態變化,內核利用 fd_set 查詢 O(1),就能知道監視進程是否關心這個 socket。
- 內核是復用了 fd_set 作為出參,返還給監視進程(所以每次 select 入參需要重置)。
然而監視進程必須遍歷一遍 socket 數組 O(n),才知道哪些 socket 就緒了。
epoll (全是O(1)查找):
- 每次傳給內核一個實例句柄。這個句柄是在內核分配的紅黑樹 rbr+雙向鏈表 rdllist。只要句柄不變,內核就能復用上次計算的結果。
- 每次 socket 狀態變化,內核就可以快速從 rbr 查詢O(1),監視進程是否關心這個 socket。同時修改 rdllist,所以 rdllist 實際上是“就緒的 socket”的一個緩存。
- 內核復制 rdllist 的一部分或者全部(LT 和 ET),到專門的 epoll_event 作為出參。
所以監視進程,可以直接一個個處理數據,無需再遍歷確認。
Select 示例代碼:

Epoll 示例代碼:

另外,epoll_create 底層實現,到底是不是紅黑樹,其實也不太重要(完全可以換成 hashtable)。
重要的是 efd 是個指針,其數據結構完全可以對外透明的修改成任意其他數據結構。
②API 發布的時間線
另外,我們再來看看網絡 IO 中,各個 api 的發布時間線:
- 1983,socket 發布在 Unix(4.2 BSD)
- 1983,select 發布在 Unix(4.2 BSD)
- 1994,Linux 的 1.0,已經支持 socket 和 select
- 1997,poll 發布在 Linux 2.1.23
- 2002,epoll 發布在 Linux 2.5.44
就可以得到兩個有意思的結論:
- socket 和 select 是同時發布的。這說明了,select 不是用來代替傳統 IO 的。這是兩種不同的用法(或模型),適用于不同的場景。
- select、poll 和 epoll,這三個“IO 多路復用 API”是相繼發布的。這說明了,它們是 IO 多路復用的 3 個進化版本。
因為 API 設計缺陷,無法在不改變 API 的前提下優化內部邏輯。所以用 poll 替代 select,再用 epoll 替代 poll。
總結
我們花了三個章節,闡述 epoll 背后的原理,現在用三句話總結一下:
- 基于數據收發的基本原理,系統利用阻塞提高了 CPU 利用率。
- 為了優化上線文切換,設計了“IO 多路復用”(和 NAPI)。
- 為了優化“內核與監視進程的交互”,設計了三個版本的 API(select,poll,epoll)。
Diss 環節
講完“epoll 背后的原理”,已經可以回答最初的幾個問題。這已經是一個完整的文章,很多人勸我刪掉下面的 diss 環節。
我的觀點是:學習就是個研究+理解的過程。上面是研究,下面再講一下我的個人“理解”,歡迎指正。
關于 IO 模型的分類
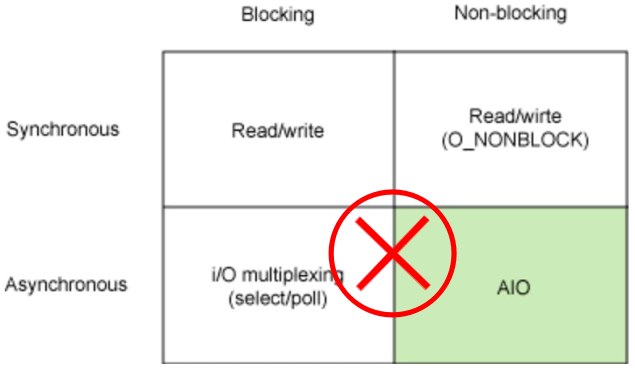
關于阻塞,非阻塞,同步,異步的分類,這么分自然有其道理。但是在操作系統的角度來看“這樣分類,容易產生誤解,并不好”。
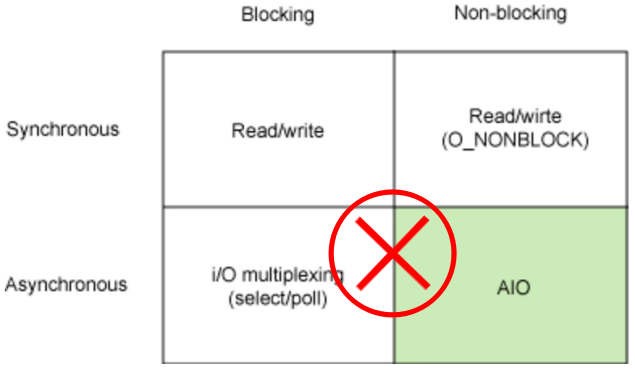
①阻塞和非阻塞
Linux 下所有的 IO 模型都是阻塞的,這是收發數據的基本原理導致的。阻塞用戶線程是一種高效的方式。
你當然可以寫一個程序,socket 設置成非阻塞模式,在不使用監視器的情況下,依靠死循環完成一次 IO 操作。但是這樣做的效率實在是太低了,完全沒有實際意義。
換句話說,阻塞不是問題,運行才是問題,運行才會消耗 CPU。IO 多路復用不是減少了阻塞,是減少了運行。
上下文切換才是問題,IO 多路復用,通過減少運行的進程,有效的減少了上下文切換。
②同步和異步
Linux 下所有的 IO 模型都是同步的。BIO 是同步的,select 同步的,poll 同步的,epoll 還是同步的。
Java 提供的 AIO,也許可以稱作“異步”的。但是 JVM 是運行在用戶態的,Linux 沒有提供任何的異步支持。
因此 JVM 提供的異步支持,和你自己封裝成“異步”的框架是沒有本質區別的(你完全可以使用 BIO 封裝成異步框架)。
所謂的“同步“和”異步”只是兩種事件分發器(event dispatcher)或者說是兩個設計模式(Reactor 和 Proactor)。
都是運行在用戶態的,兩個設計模式能有多少性能差異呢?
- Reactor 對應 Java 的 NIO,也就是 Channel,Buffer 和 Selector 構成的核心的 API。
- Proactor對應 java 的 AIO,也就是 Async 組件和 Future 或 Callback 構成的核心的 API。
③我的分類
我認為 IO 模型只分兩類:
- 更加符合程序員理解和使用的,進程模型。
- 更加符合操作系統處理邏輯的,IO 多路復用模型。
對于“IO 多路復用”的事件分發,又分為兩類:Reactor 和 Proactor。
關于 mmap
epoll 到底用沒用到 mmap?答案:沒有!
這是個以訛傳訛的謠言。其實很容易證明的,用 epoll 寫個 demo。strace 一下就清楚了。
作者:馮志明
簡介:2019 年至今負責搜索算法的相關工作,擅長處理復雜的業務系統,對底層技術有濃厚興趣。
編輯:陶家龍
出處:轉載自公眾號Qunar技術沙龍(ID:QunarTL)