看一遍就理解:MVCC原理詳解
前言
MVCC實現原理是一道非常高頻的面試題,最近技術討論群的小伙伴一直在討論,趁著國慶節有空,我們一起來聊聊。
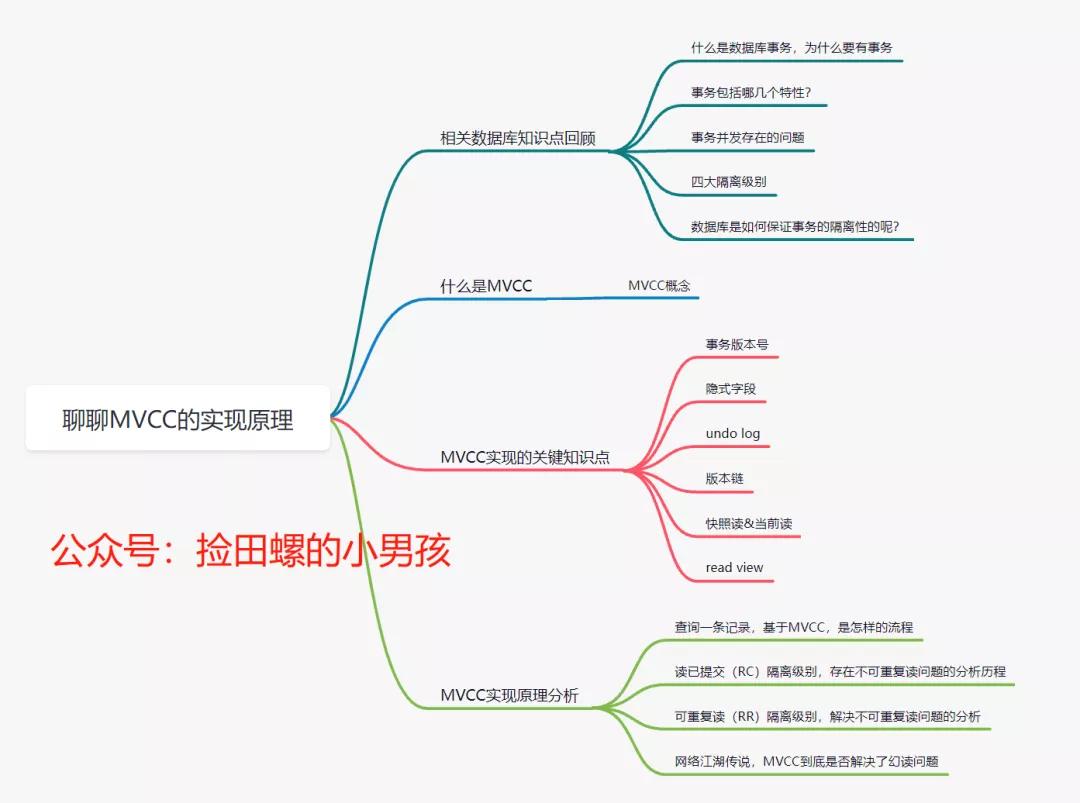
1. 相關數據庫知識點回顧
1.1 什么是數據庫事務,為什么要有事務
事務,由一個有限的數據庫操作序列構成,這些操作要么全部執行,要么全部不執行,是一個不可分割的工作單位。
假如A轉賬給B 100 元,先從A的賬戶里扣除 100 元,再在 B 的賬戶上加上 100 元。如果扣完A的100元后,還沒來得及給B加上,銀行系統異常了,最后導致A的余額減少了,B的余額卻沒有增加。所以就需要事務,將A的錢回滾回去,就是這么簡單。
為什么要有事務呢? 就是為了保證數據的最終一致性。
1.2 事務包括哪幾個特性?
事務四個典型特性,即ACID,原子性(Atomicity)、一致性(Consistency)、隔離性(Isolation)、持久性(Durability)。
- 原子性:事務作為一個整體被執行,包含在其中的對數據庫的操作要么全部都執行,要么都不執行。
- 一致性:指在事務開始之前和事務結束以后,數據不會被破壞,假如A賬戶給B賬戶轉10塊錢,不管成功與否,A和B的總金額是不變的。
- 隔離性:多個事務并發訪問時,事務之間是相互隔離的,一個事務不應該被其他事務干擾,多個并發事務之間要相互隔離。。
- 持久性:表示事務完成提交后,該事務對數據庫所作的操作更改,將持久地保存在數據庫之中。
1.3 事務并發存在的問題
事務并發會引起臟讀、不可重復讀、幻讀問題。
1.3.1 臟讀
如果一個事務讀取到了另一個未提交事務修改過的數據,我們就稱發生了臟讀現象。
假設現在有兩個事務A、B:
假設現在A的余額是100,事務A正在準備查詢Jay的余額
事務B先扣減Jay的余額,扣了10,但是還沒提交
最后A讀到的余額是90,即扣減后的余額

臟讀
因為事務A讀取到事務B未提交的數據,這就是臟讀。
1.3.2 不可重復讀
同一個事務內,前后多次讀取,讀取到的數據內容不一致
假設現在有兩個事務A和B:
- 事務A先查詢Jay的余額,查到結果是100
- 這時候事務B 對Jay的賬戶余額進行扣減,扣去10后,提交事務
- 事務A再去查詢Jay的賬戶余額發現變成了90

不可重復讀
事務A被事務B干擾到了!在事務A范圍內,兩個相同的查詢,讀取同一條記錄,卻返回了不同的數據,這就是不可重復讀。
1.3.3 幻讀
如果一個事務先根據某些搜索條件查詢出一些記錄,在該事務未提交時,另一個事務寫入了一些符合那些搜索條件的記錄(如insert、delete、update),就意味著發生了幻讀。
假設現在有兩個事務A、B:
- 事務A先查詢id大于2的賬戶記錄,得到記錄id=2和id=3的兩條記錄
- 這時候,事務B開啟,插入一條id=4的記錄,并且提交了
- 事務A再去執行相同的查詢,卻得到了id=2,3,4的3條記錄了。

幻讀
事務A查詢一個范圍的結果集,另一個并發事務B往這個范圍中插入新的數據,并提交事務,然后事務A再次查詢相同的范圍,兩次讀取到的結果集卻不一樣了,這就是幻讀。
1.4 四大隔離級別
為了解決并發事務存在的臟讀、不可重復讀、幻讀等問題,數據庫大叔設計了四種隔離級別。分別是讀未提交,讀已提交,可重復讀,串行化(Serializable)。
1.4.1 讀未提交
讀未提交隔離級別,只限制了兩個數據不能同時修改,但是修改數據的時候,即使事務未提交,都是可以被別的事務讀取到的,這級別的事務隔離有臟讀、重復讀、幻讀的問題;
1.4.2 讀已提交
讀已提交隔離級別,當前事務只能讀取到其他事務提交的數據,所以這種事務的隔離級別解決了臟讀問題,但還是會存在重復讀、幻讀問題;
1.4 3 可重復讀
可重復讀隔離級別,限制了讀取數據的時候,不可以進行修改,所以解決了重復讀的問題,但是讀取范圍數據的時候,是可以插入數據,所以還會存在幻讀問題;
1.4.4 串行化
事務最高的隔離級別,在該級別下,所有事務都是進行串行化順序執行的。可以避免臟讀、不可重復讀與幻讀所有并發問題。但是這種事務隔離級別下,事務執行很耗性能。
1.4.5 四大隔離級別,都會存在哪些并發問題呢
| 隔離級別 | 臟讀 | 不可重復讀 | 幻讀 |
|---|---|---|---|
| 讀未提交 | √ | √ | √ |
| 讀已提交 | × | √ | √ |
| 可重復讀 | × | × | √ |
| 串行化 | × | × | × |
1.5 數據庫是如何保證事務的隔離性的呢?
數據庫是通過加鎖,來實現事務的隔離性的。這就好像,如果你想一個人靜靜,不被別人打擾,你就可以在房門上加上一把鎖。
加鎖確實好使,可以保證隔離性。比如串行化隔離級別就是加鎖實現的。但是頻繁的加鎖,導致讀數據時,沒辦法修改,修改數據時,沒辦法讀取,大大降低了數據庫性能。
那么,如何解決加鎖后的性能問題的?
答案就是,MVCC多版本并發控制!它實現讀取數據不用加鎖,可以讓讀取數據同時修改。修改數據時同時可讀取。
2. 什么是 MVCC?
MVCC,即Multi-Version Concurrency Control (多版本并發控制)。它是一種并發控制的方法,一般在數據庫管理系統中,實現對數據庫的并發訪問,在編程語言中實現事務內存。
通俗的講,數據庫中同時存在多個版本的數據,并不是整個數據庫的多個版本,而是某一條記錄的多個版本同時存在,在某個事務對其進行操作的時候,需要查看這一條記錄的隱藏列事務版本id,比對事務id并根據事物隔離級別去判斷讀取哪個版本的數據。
數據庫隔離級別讀已提交、可重復讀 都是基于MVCC實現的,相對于加鎖簡單粗暴的方式,它用更好的方式去處理讀寫沖突,能有效提高數據庫并發性能。
3. MVCC實現的關鍵知識點
3.1 事務版本號
事務每次開啟前,都會從數據庫獲得一個自增長的事務ID,可以從事務ID判斷事務的執行先后順序。這就是事務版本號。
3.2 隱式字段
對于InnoDB存儲引擎,每一行記錄都有兩個隱藏列trx_id、roll_pointer,如果表中沒有主鍵和非NULL唯一鍵時,則還會有第三個隱藏的主鍵列row_id。
| 列名 | 是否必須 | 描述 |
|---|---|---|
| row_id | 否 | 單調遞增的行ID,不是必需的,占用6個字節。 |
| trx_id | 是 | 記錄操作該數據事務的事務ID |
| roll_pointer | 是 | 這個隱藏列就相當于一個指針,指向回滾段的undo日志 |
3.3 undo log
undo log,回滾日志,用于記錄數據被修改前的信息。在表記錄修改之前,會先把數據拷貝到undo log里,如果事務回滾,即可以通過undo log來還原數據。
可以這樣認為,當delete一條記錄時,undo log 中會記錄一條對應的insert記錄,當update一條記錄時,它記錄一條對應相反的update記錄。
undo log有什么用途呢?
- 事務回滾時,保證原子性和一致性。
- 用于MVCC快照讀。
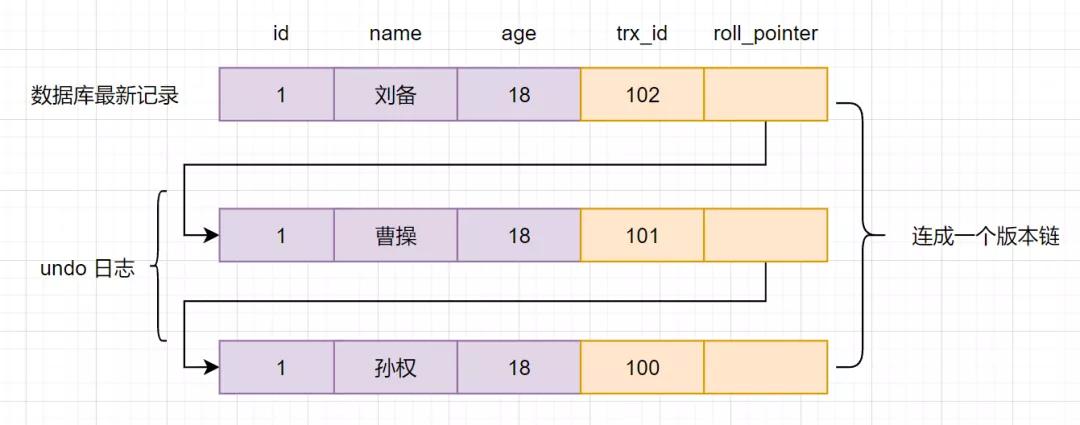
3.4 版本鏈
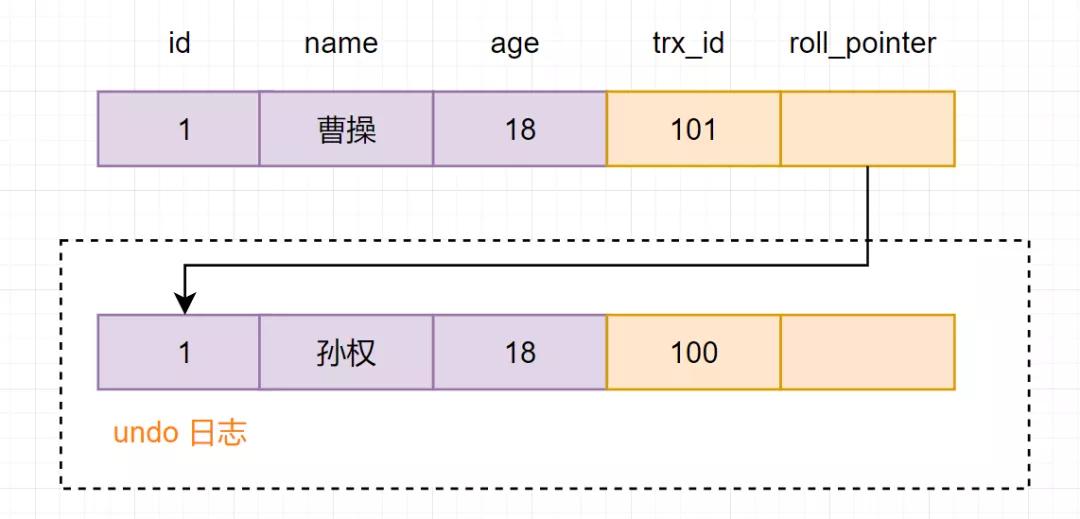
多個事務并行操作某一行數據時,不同事務對該行數據的修改會產生多個版本,然后通過回滾指針(roll_pointer),連成一個鏈表,這個鏈表就稱為版本鏈。如下:
版本鏈
其實,通過版本鏈,我們就可以看出事務版本號、表格隱藏的列和undo log它們之間的關系。我們再來小分析一下。
1)假設現在有一張core_user表,表里面有一條數據,id為1,名字為孫權:
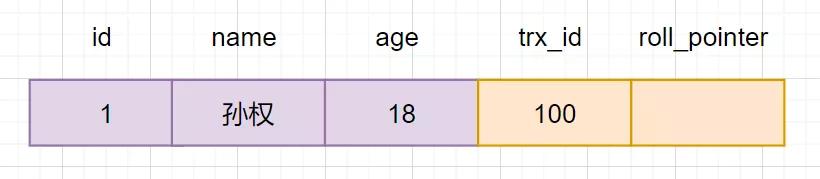
2)現在開啟一個事務A:對core_user表執行update core_user set name ="曹操" where id=1,會進行如下流程操作
- 首先獲得一個事務ID=100
- 把core_user表修改前的數據,拷貝到undo log
- 修改core_user表中,id=1的數據,名字改為曹操
- 把修改后的數據事務Id=101改成當前事務版本號,并把roll_pointer指向undo log數據地址。
3.5 快照讀和當前讀
快照讀: 讀取的是記錄數據的可見版本(有舊的版本)。不加鎖,普通的select語句都是快照讀,如:
- select * from core_user where id > 2;
當前讀:讀取的是記錄數據的最新版本,顯式加鎖的都是當前讀
- select * from core_user where id > 2 for update;
- select * from account where id>2 lock in share mode;
3.6 Read View
- Read View是什么呢? 它就是事務執行SQL語句時,產生的讀視圖。實際上在innodb中,每個SQL語句執行前都會得到一個Read View。
- Read View有什么用呢? 它主要是用來做可見性判斷的,即判斷當前事務可見哪個版本的數據~
Read View是如何保證可見性判斷的呢?我們先看看Read view 的幾個重要屬性
- m_ids:當前系統中那些活躍(未提交)的讀寫事務ID, 它數據結構為一個List。
- min_limit_id:表示在生成Read View時,當前系統中活躍的讀寫事務中最小的事務id,即m_ids中的最小值。
- max_limit_id:表示生成Read View時,系統中應該分配給下一個事務的id值。
- creator_trx_id: 創建當前Read View的事務ID
Read view 匹配條件規則如下:
- 如果數據事務ID trx_id < min_limit_id,表明生成該版本的事務在生成Read View前,已經提交(因為事務ID是遞增的),所以該版本可以被當前事務訪問。
- 如果trx_id>= max_limit_id,表明生成該版本的事務在生成ReadView后才生成,所以該版本不可以被當前事務訪問。
- 如果 min_limit_id =
(1).如果m_ids包含trx_id,則代表Read View生成時刻,這個事務還未提交,但是如果數據的trx_id等于creator_trx_id的話,表明數據是自己生成的,因此是可見的。
(2)如果m_ids包含trx_id,并且trx_id不等于creator_trx_id,則Read View生成時,事務未提交,并且不是自己生產的,所以當前事務也是看不見的;
(3).如果m_ids不包含trx_id,則說明你這個事務在Read View生成之前就已經提交了,修改的結果,當前事務是能看見的。
4. MVCC實現原理分析
4.1 查詢一條記錄,基于MVCC,是怎樣的流程
- 獲取事務自己的版本號,即事務ID
- 獲取Read View
- 查詢得到的數據,然后Read View中的事務版本號進行比較。
- 如果不符合Read View的可見性規則, 即就需要Undo log中歷史快照;
- 最后返回符合規則的數據
InnoDB 實現MVCC,是通過Read View+ Undo Log 實現的,Undo Log 保存了歷史快照,Read View可見性規則幫助判斷當前版本的數據是否可見。
4.2 讀已提交(RC)隔離級別,存在不可重復讀問題的分析歷程
創建core_user表,插入一條初始化數據,如下:
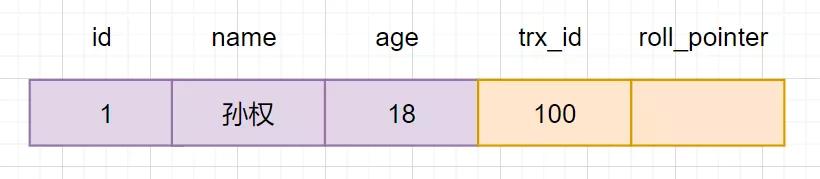
隔離級別設置為讀已提交(RC),事務A和事務B同時對core_user表進行查詢和修改操作。
- 事務A: select * fom core_user where id=1
- 事務B: update core_user set name =”曹操”
執行流程如下:
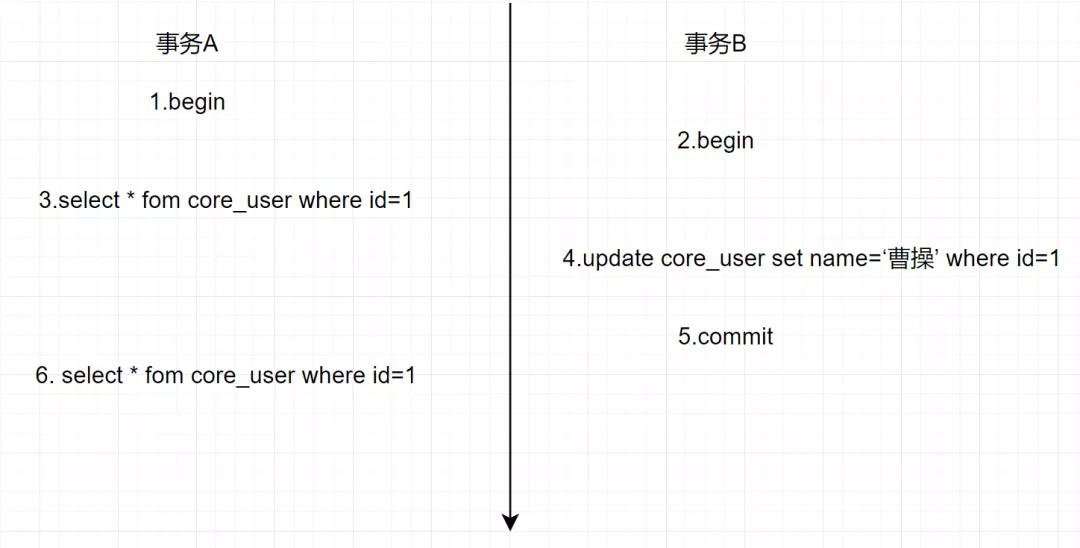
最后事務A查詢到的結果是,name=曹操的記錄,我們基于MVCC,來分析一下執行流程:
(1). A開啟事務,首先得到一個事務ID為100
(2).B開啟事務,得到事務ID為101
(3).事務A生成一個Read View,read view對應的值如下
| 變量 | 值 |
|---|---|
| m_ids | 100,101 |
| max_limit_id | 102 |
| min_limit_id | 100 |
| creator_trx_id | 100 |
然后回到版本鏈:開始從版本鏈中挑選可見的記錄:
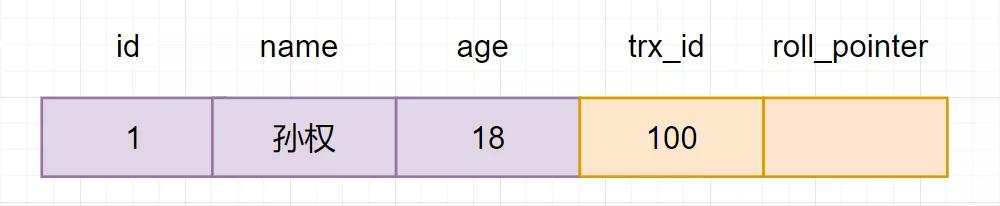
版本鏈
由圖可以看出,最新版本的列name的內容是孫權,該版本的trx_id值為100。開始執行read view可見性規則校驗:
- min_limit_id(100)=<trx_id(100)<102;
- creator_trx_id = trx_id =100;
由此可得,trx_id=100的這個記錄,當前事務是可見的。所以查到是name為孫權的記錄。
(4). 事務B進行修改操作,把名字改為曹操。把原數據拷貝到undo log,然后對數據進行修改,標記事務ID和上一個數據版本在undo log的地址。
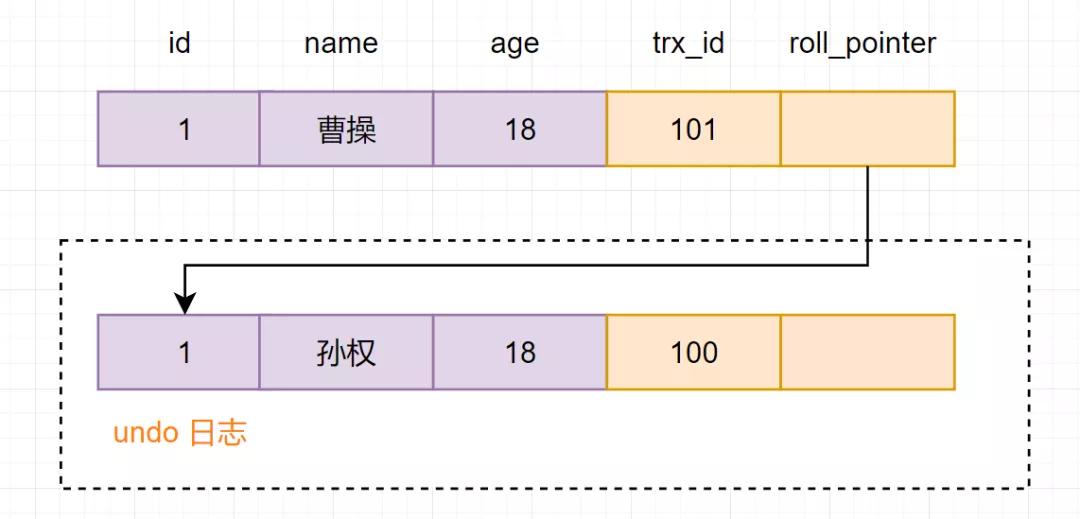
(5) 提交事務
(6) 事務A再次執行查詢操作,新生成一個Read View,Read View對應的值如下
| 變量 | 值 |
|---|---|
| m_ids | 100 |
| max_limit_id | 102 |
| min_limit_id | 100 |
| creator_trx_id | 100 |
然后再次回到版本鏈:從版本鏈中挑選可見的記錄:
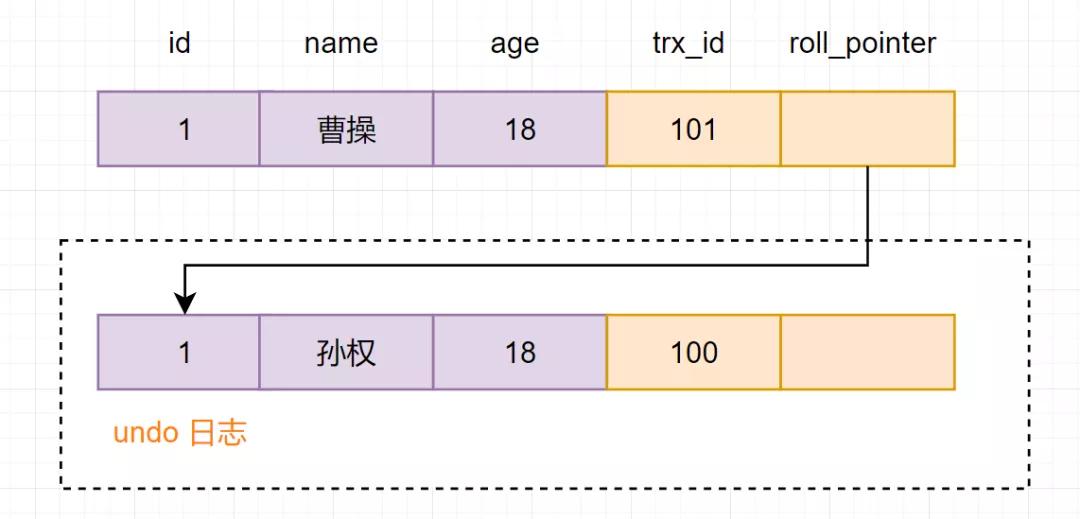
從圖可得,最新版本的列name的內容是曹操,該版本的trx_id值為101。開始執行Read View可見性規則校驗:
- min_limit_id(100)=<trx_id(101)<max_limit_id(102);
- 但是,trx_id=101,不屬于m_ids集合
因此,trx_id=101這個記錄,對于當前事務是可見的。所以SQL查詢到的是name為曹操的記錄。
綜上所述,在讀已提交(RC)隔離級別下,同一個事務里,兩個相同的查詢,讀取同一條記錄(id=1),卻返回了不同的數據(第一次查出來是孫權,第二次查出來是曹操那條記錄),因此RC隔離級別,存在不可重復讀并發問題。
4.3 可重復讀(RR)隔離級別,解決不可重復讀問題的分析
在RR隔離級別下,是如何解決不可重復讀問題的呢?我們一起再來看下,
還是4.2小節那個流程,還是這個事務A和事務B,如下:
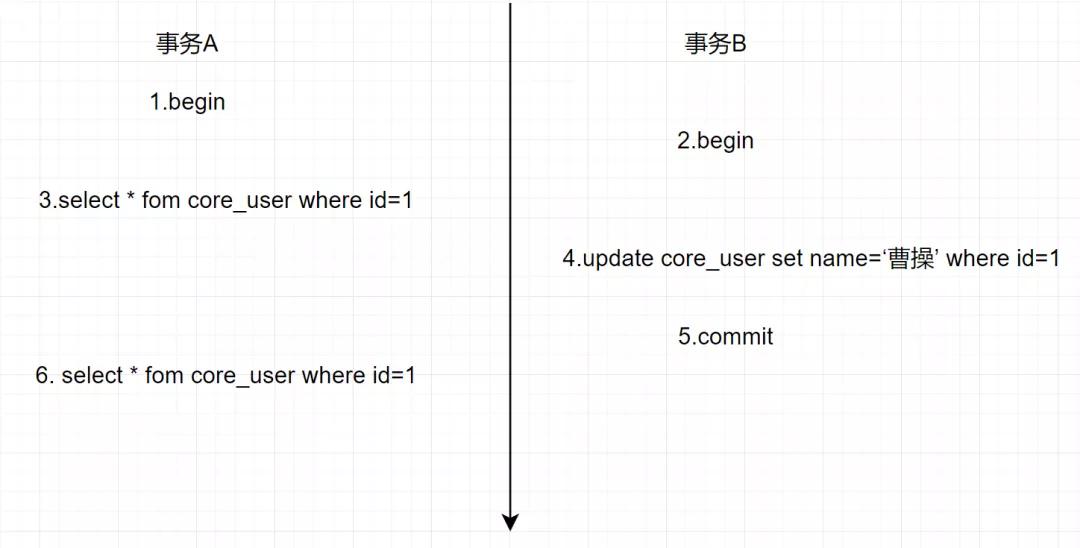
4.3.1 不同隔離級別下,Read View的工作方式不同
實際上,各種事務隔離級別下的Read view工作方式,是不一樣的,RR可以解決不可重復讀問題,就是跟Read view工作方式有關。
- 在讀已提交(RC)隔離級別下,同一個事務里面,每一次查詢都會產生一個新的Read View副本,這樣就可能造成同一個事務里前后讀取數據可能不一致的問題(不可重復讀并發問題)。
| begin | |
|---|---|
| select * from core_user where id =1 | 生成一個Read View |
| / | / |
| / | / |
| select * from core_user where id =1 | 生成一個Read View |
在可重復讀(RR)隔離級別下,一個事務里只會獲取一次read view,都是副本共用的,從而保證每次查詢的數據都是一樣的。
| begin | |
|---|---|
| select * from core_user where id =1 | 生成一個Read View |
| / | |
| / | |
| select * from core_user where id =1 | 共用一個Read View副本 |
4.3.2 實例分析
我們穿越下,回到剛4.2的例子,然后執行第2個查詢的時候:
事務A再次執行查詢操作,復用老的Read View副本,Read View對應的值如下
| 變量 | 值 |
|---|---|
| m_ids | 100,101 |
| max_limit_id | 102 |
| min_limit_id | 100 |
| creator_trx_id | 100 |
然后再次回到版本鏈:從版本鏈中挑選可見的記錄:
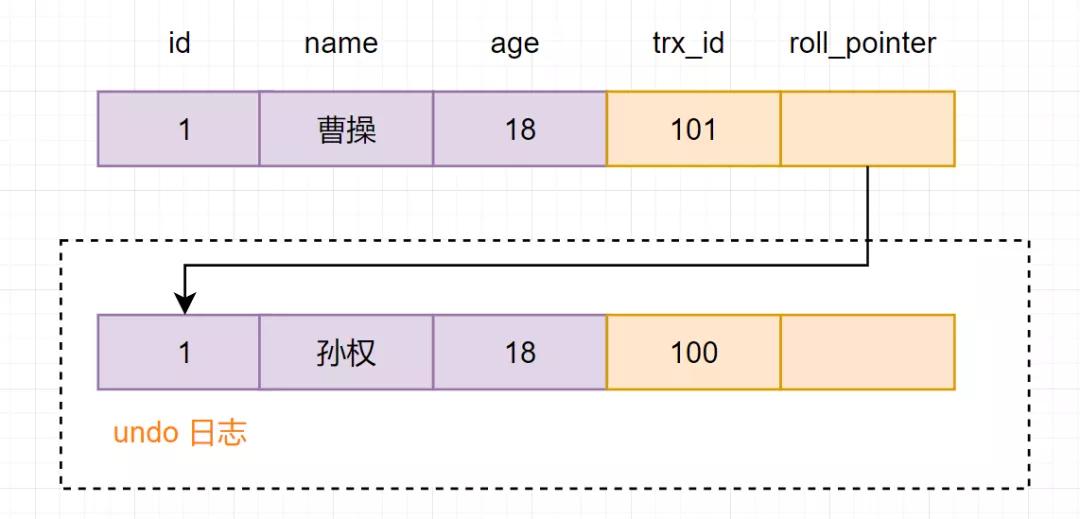
從圖可得,最新版本的列name的內容是曹操,該版本的trx_id值為101。開始執行read view可見性規則校驗:
- min_limit_id(100)=<trx_id(101)<max_limit_id(102);
- 因為m_ids{100,101}包含trx_id(101),
- 并且creator_trx_id (100) 不等于trx_id(101)
所以,trx_id=101這個記錄,對于當前事務是不可見的。這時候呢,版本鏈roll_pointer跳到下一個版本,trx_id=100這個記錄,再次校驗是否可見:
- min_limit_id(100)=<trx_id(100)< max_limit_id(102);
- 因為m_ids{100,101}包含trx_id(100),
- 并且creator_trx_id (100) 等于trx_id(100)
所以,trx_id=100這個記錄,對于當前事務是可見的,所以兩次查詢結果,都是name=孫權的那個記錄。即在可重復讀(RR)隔離級別下,復用老的Read View副本,解決了不可重復讀的問題。
4.4 網絡江湖傳說,MVCC是否解決了幻讀問題呢?
網絡江湖有個傳說,說MVCC的RR隔離級別,解決了幻讀問題,我們來一起分析一下。
4.4.1 RR級別下,一個快照讀的例子,不存在幻讀問題
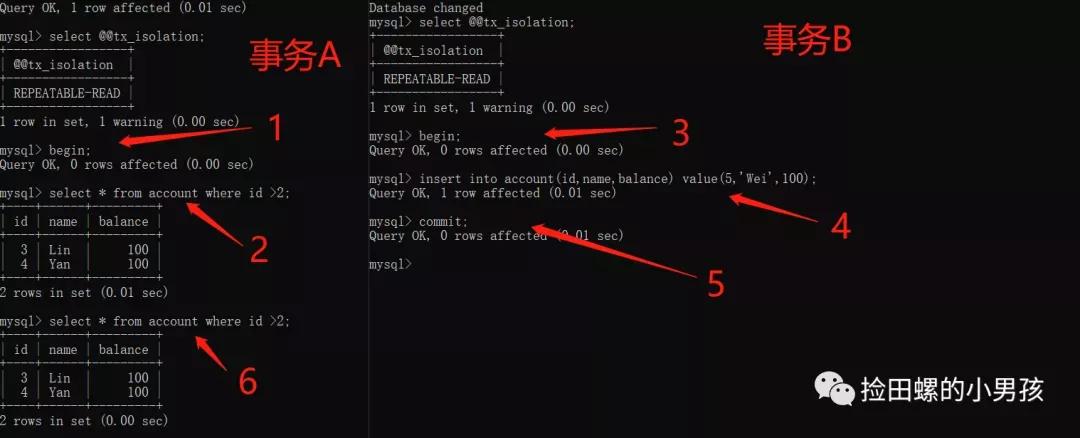
由圖可得,步驟2和步驟6查詢結果集沒有變化,看起來RR級別是已經解決幻讀問題啦~
4.4.2 RR級別下,一個當前讀的例子
假設現在有個account表,表中有4條數據,RR級別。
- 開啟事務A,執行當前讀,查詢id>2的所有記錄。
- 再開啟事務B,插入id=5的一條數據。
流程如下:
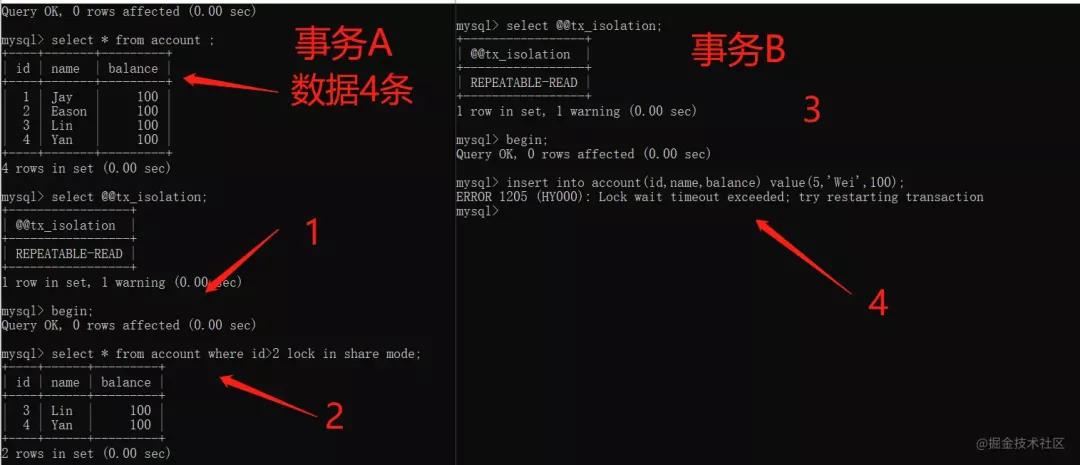
顯然,事務B執行插入操作時,阻塞了~因為事務A在執行select ... lock in share mode(當前讀)的時候,不僅在id = 3,4 這2條記錄上加了鎖,而且在id > 2這個范圍上也加了間隙鎖。
因此,我們可以發現,RR隔離級別下,加鎖的select, update, delete等語句,會使用間隙鎖+ 臨鍵鎖,鎖住索引記錄之間的范圍,避免范圍間插入記錄,以避免產生幻影行記錄,那就是說RR隔離級別解決了幻讀問題?
4.4.3 這種特殊場景,似乎有幻讀問題
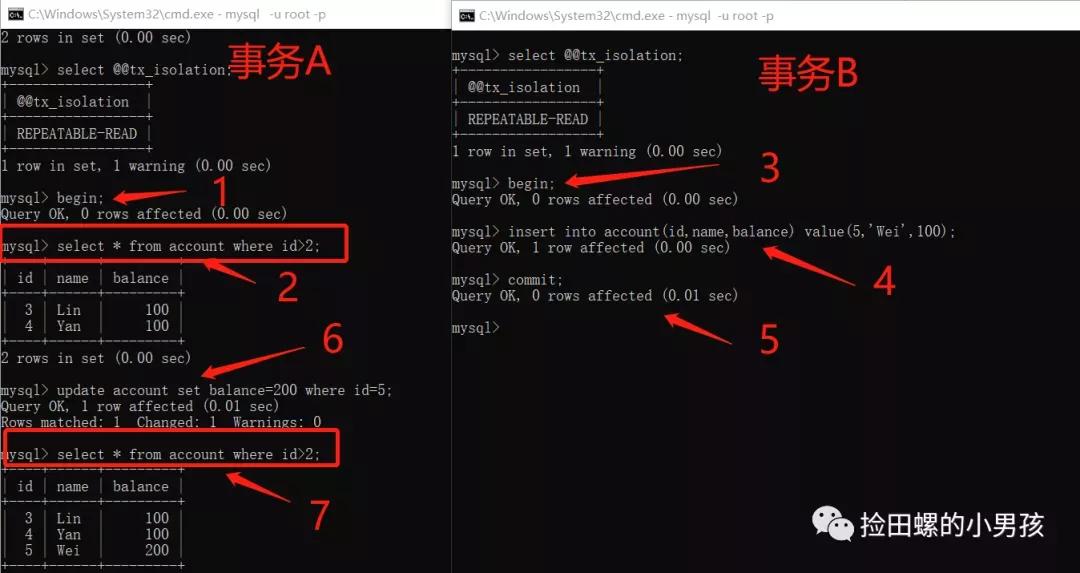
其實,上圖事務A中,多加了update account set balance=200 where id=5;這步操作,同一個事務,相同的sql,查出的結果集不同了,這個結果,就符合了幻讀的定義~
這個問題,親愛的朋友,你覺得它算幻讀問題嗎,所以RR隔離級別,還是存在幻讀問題吧?歡迎大家評論區留言哈。
參考資料
[1]數據庫基礎(四)Innodb MVCC實現原理: https://zhuanlan.zhihu.com/p/52977862