人工智能專用SoC芯片IP需求分析
本文轉載自微信公眾號「智能計算芯世界」,作者synopsys 。轉載本文請聯系智能計算芯世界公眾號。
目前支持AI計算開發的半導體有獨立加速器和 in-memory/near-memory 計算技術兩種。獨立加速器以某種方式連接到應用處理器,并且有一些應用處理器在設備上添加了神經網絡硬件加速。獨立加速器可以通過芯片與芯片的互連而實現了將硬件擴展到多個芯片的巨大創新,從而實現最高性能,in-memory 和 near-memory 計算技術主要滿足減少能耗需求。
設備上的 AI 加速正在通過利用處理器和架構對他們的神經網絡處理器進行升級,這些處理器和架構是獨立半導體的先驅。半導體領導者、行業巨頭和數百家初創公司都在全力將 AI 能力推廣到各個行業的大量新型 SoC 和芯片組中,涵蓋從云服務器組到每個廚房中的家庭助理等所有環節。
深度學習神經網絡用在許多不同的應用中,為使用它們的人提供了強大的新工具。例如,它們可以用于高級安全威脅分析、預測和預防安全漏洞,以及通過預測潛在買家的購物流程而幫助廣告商識別和簡化銷售流程。這是在融合最新 GPU 和 AI 加速器半導體技術的服務器群中運行的數據中心應用的兩個實例。
但 AI 設計并未包含在數據中心內。許多新功能可基于傳感器輸入的組合而了解發生的情況,例如用于對象和面部檢測的視覺系統,用于改進人機接口的自然語言理解以及上下文感知)。這些深度學習能力已添加到所有行業的 SoC 中,包括汽車、移動、數字家庭、數據中心和物聯網 (IoT)。
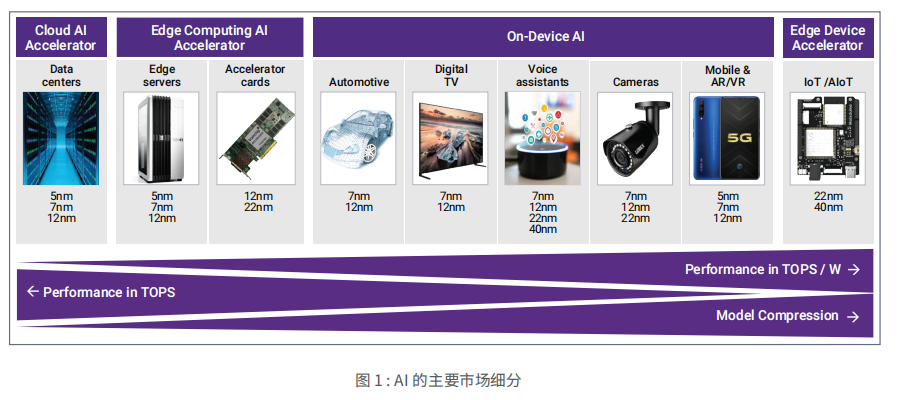
為實現最高性能,針對云 AI 加速的 SoC 設計人員致力于最大限度地提升性能以解決重大問題。執行 AI 訓練以及為了得到最高準確度而需要的最復雜的 AI 算法,需要很高的處理器運算能力(TOPS),這最終可通過縮短訓練時間而降低成本,并減少推理過程所需的能耗。云計算市場的這些半導體硬件創新使人們認為可能需要花費數年開發才能完成的工作成為可能,并縮短了取得突破的時間,例如,以識別和疫苗開發的形式找到當前最令人擔憂的健康問題的治療方法。
然而,并非所有問題都可以在云端解決,因此,許多 AI 加速器架構經過修改,可支持邊緣計算和設備端 AI。在邊緣服務器和插入式加速卡中,成本和功耗更加重要。隨著我們越來越靠近并進入數據收集點的應用“邊緣設備加速器”,單位能耗性能的優化成為最高設計要求。
邊緣設備加速器的資源、處理和內存有限,因此,經過訓練的算法需要壓縮和裁剪,以滿足功耗和性能的要求,同時保證所需的準確性。最大的 AI 細分市場是設備端 AI,它會影響多種應用,例如汽車 ADAS、數字電視的超高圖像分辨率、音頻和語音識別以及智能音箱中的語言理解。這類應用包括執行面部檢測、面部識別和物體識別的攝像頭。
例如,在某些行業中,攝像頭中的設備端 AI 可對工業應用執行缺陷分析。設備端 AI 類別還包括消費類應用,例如手機和 AR/VR 耳機,這些應用可實現前面提到的許多AI 功能,例如導航、超高圖像分辨率、語音理解、對象 / 面部檢測等,而且所有這些都在小巧的體積中實現。移動設備通過最新的工藝節點而持續在工藝中保持領先地位,這與用于云計算的工藝節點類似。邊緣和設備端計算不斷優化性能。根據市場的不同,可以采用傳統工藝節點。
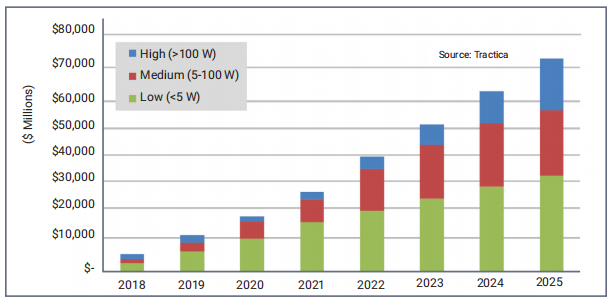
2020 年,AI 市場仍處于初期階段,并有望在未來幾年內快速增長。大于 100W 的云 AI SoC 廠商包括市場領導者NVIDIA 和 Intel。通過先發優勢,這些廠商占據了主導地位。大量初創企業希望在效率方面比這些解決方案高出多倍。此外,Google、TPU、阿里巴巴、亞馬遜和百度等系統公司也設計自己的芯片,并通過優化而支持其業務模式。所有這些公司都為客戶提供云出租服務,使客戶能夠在云端進行培訓和推理。

邊緣計算 (>5W) SoC 通常利用現有的云解決方案,或者經過修改的云架構,但是許多初創企業通過更低功耗和更優化的解決方案而找到了自己的市場位置,同時在性能上遠遠超越當今的解決方案。
在圖2 中,5W 以下市場包括設備端和獨立加速器,通常稱為 AIoT 加速器,這一市場正在迅速發展。對于設備端解決方案,移動市場在出貨量方面占主導地位,而汽車市場也在快速增長,例如 Tesla ASIC。在低于 5W 的市場中,AIoT 加速器仍然只占很小的比例,但 Perceive、Kneron、Gyrfalcon、Brainchip 和 GrAI Matter Labs 等公司都在試圖突圍。
每個 AI 市場細分都有不同的目標和挑戰。云 AI SoC 設計人員注重縮短昂貴的訓練時間,同時適應可包含 80 億個甚至更多參數的最復雜的新算法。邊緣計算 AI 設計更注重降低功耗和延遲。5G 和設備端 AI 旨在實現低延遲,但對于 5G,這些 AI 并不用于壓縮模型,因為這可能是非常昂貴且耗時的設計過程。對于設備端 AI,您需要通過壓縮模型,最大程度優化功能和性能的推理。
最后,AIoT獨立加速器設計人員使用更多創新技術,并且往往是 TOPS/W 的領導者。在提高密度,縮短延遲,以及應對存儲系數的波動方面,他們承擔著更多的風險,而且他們還是裁剪和壓縮算法以及為客戶實施算法的專家,提供了獨特的差異化能力。
除這些獨特的挑戰外,AI 市場也面臨著一系列核心挑戰,包括:
添加專門的處理能力,可以更高效地執行必要的數學運算,例如矩陣乘法和點積
高效的內存訪問,可處理深度學習所需的唯一系數,例如權重和激活
可靠且經過驗證的實時接口,用于芯片到芯片、芯片到云端、傳感器數據以及加速器到主機的連接
保護數據并防止黑客攻擊和數據損壞
AI 模型使用大量內存,這增加了芯片的成本。訓練神經網絡可能需要幾 GB 到 10 GB 的數據,這需要使用最新的 DDR 技術,以滿足容量要求。例如,作為圖像神經網絡的 VGG-16 在訓練時需要大約 9GB 的內存。更精確的模型 VGG-512 需要 89GB 的數據才能進行訓練。為了提高 AI 模型的準確性,數據科學家使用了更大的數據集。同樣,這會增加訓練模型所需的時間或增加解決方案的內存需求。
由于需要大規模并行矩陣乘法運算以及模型的大小和所需系數的數量,這需要具有高帶寬存取能力的外部存儲器。新的半導體接口 IP,如高帶寬存儲器 (HBM2) 和未來的衍生產品 (HBM2e),正被迅速采用,以滿足這些需求。先進的 FinFET 技術支持更大的片上 SRAM 陣列和獨特的配置,具有定制的存儲器到處理器和存儲器到存儲器接口,這些技術正在開發中,目的是更好地復制人腦并消除存儲器的約束。
AI 模型可以壓縮。這種技術是確保模型在位于手機、汽車和物聯網應用邊緣的 SoC 中受限的存儲器架構上運行所必需的。壓縮采用剪枝(pruning)和量化(pruning)技術進行,而不降低結果的準確性。這使得傳統 SoC 架構(具有 LPDDR 或在某些情況下沒有外部存儲器)支持神經網絡,然而,在功耗和其他方面需要權衡。隨著這些模型的壓縮,不規則的存儲器存取和不規則的計算強度增加,延長了系統的執行時間和延遲。因此,系統設計人員正在開發創新的異構存儲器架構。
AI SoC設計解決方案
在SoC中添加 AI 功能突顯了當今 SoC 架構在 AI 方面的薄弱。在為非 AI 應用構建的 SoC 上實施視覺、語音識別和其他深度學習和機器學習算法時,資源非常匱乏。IP 的選擇和集成明確界定了 AI SoC 的基準效率,這構成了 AI SoC 的“DNA”,或者叫先天性。例如,引入定制處理器或處理器陣列可以加速 AI 應用中所需的大規模矩陣乘法。
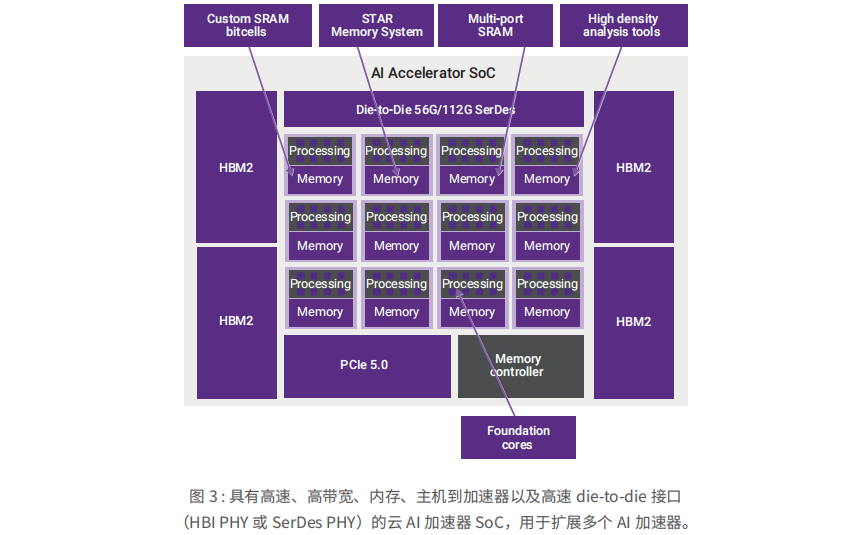
云AI加速器
為了應對帶寬和可靠性挑戰,云 AI 加速器 SoC 設計人員正在集成 HBM2e 和 HBM3,以及用于芯片到芯片通信的高速 SerDes die-to-die 或 PCIe。安全(包括支持 AI 模型加密和身份驗證的高速安全協議加速器)的作用越來越明顯。嵌入式內存解決方案的多端口存儲器 (TCAMs) 與 SRAM 編譯器一起有助于減少泄漏。
邊緣計算AI 加速器
許多邊緣計算應用的主要目標是圍繞與較低延遲相關的新服務。為了支持較低的延遲,許多新系統都采用了一些最新的行業接口標準,包括 PCIe 5.0、LPDDR5、DDR5、HBM2e、USB 3.2、CXL、基于 PCIe 的 NVMe 以及其他基于新一代標準的技術。與上一代產品相比,每一種技術都通過增加帶寬而降低延遲。
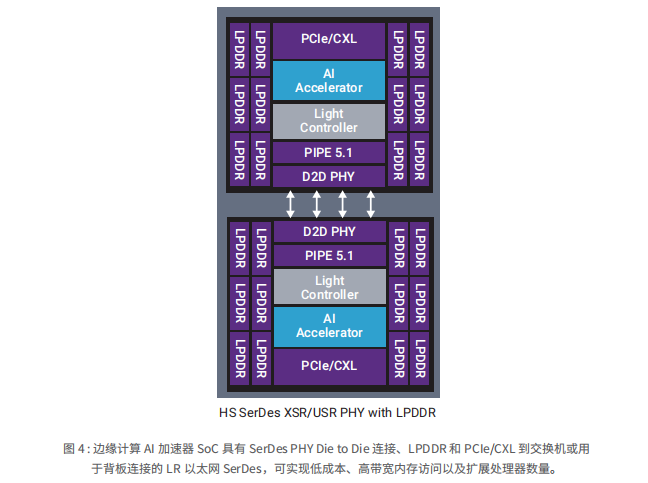
比減少延遲的驅動因素更為突出的是為所有這些邊緣計算系統增加 AI 加速。AI 加速由某些服務器芯片通過 x86 擴展 AVX-512 向量神經網絡指令 (AVX512 VNNI) 等新指令提供,或者提供給移動應用處理器,例如高通 DSP 內核。很多時候,這種額外的指令集不足以提供預期任務所需的低延遲和低功耗,因此,大多數新系統中還添加了定制 AI 加速器。這些芯片所需的連接能力通常采用帶寬最高的主機而實現加速器連接。例如,由于這些帶寬要求直接影響延遲,PCIe 5.0 正迅速得到廣泛的應用,最常見的是用在具有多個 AI 加速器的某種交換配置中。
CXL 是另一種為降低延遲并提供緩存一致性而專門開發的接口,正迅速興起。由于 AI 算法具有異構計算需求和大量內存需求,因此,確保緩存一致性至關重要。
除了本地網關和聚合服務器系統之外,單個 AI 加速器通常無法提供足夠的性能,因此需要借助帶寬極高的芯片到芯片的 SerDes PHY 而擴展這些加速器。最新發布的 PHY 支持 56G 和 112G 連接。支持 AI 擴展的芯片到芯片要求已經在多個項目中實施。在基于標準的實施項目中,以太網可能是一種可擴展的選項,現在已經推出了一些基于這種理念的解決方案。然而,當今許多實施項目都是通過專有控制器而利用最高帶寬的 SerDes。不同的架構可能會改變服務器系統的未來 SoC 架構,從而將網絡、服務器、AI 和存儲組件整合到集成度更高的 SoC 中,而不是目前實施的 4 種不同 SoC 中。
設備端AI
關于設備端 AI 處理的一個最大關注點就是軟件能力。算法變化很快。設計人員需要采用 Tensorflow 和 Caffe 等傳統工具訓練初始模型,然后將其映射到設備上的處理器。借助可針對特定處理器進行優化并保持高精度的圖形映射工具,以及進行壓縮和修剪的工具,許多工程可以節省數月的時間和精力。如果沒有這些工具,軟件和系統的設計速度趕不上硬件的設計。
優化的內存配置可以優化設備端 AI 系統。在開始設備本身的架構設計之前,設計人員需要擁有可模擬多個 IP 權限和配置的工具。在運行實際算法的同時,通過利用處理器模擬片上和片外存儲器,可以在開始設計之前為設計人員提供最有效的架構。由于有些設計人員尚不清楚如何優化系統,因此,他們經常需要為同一過程節點開發多代產品,這會浪費數月的時間。
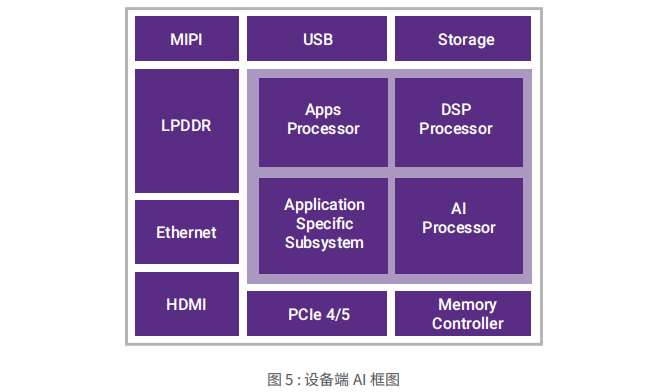
最后,傳感器連接對于設備端 AI 系統的視覺至關重要。MIPI CSI-2 是 CMOS 圖像傳感器的最常見實施。新的 V3 規范旨在提高機器感知能力,并支持更高的精度,從而提供更高質量的圖像。特別需要指出的是,智能化能力應有助于提高效率,因為新數據僅在需要時才提供,而不是提供整個圖像。I3C 整合了多個傳感器,為支持多個系統輸入源提供了一種低成本的方法。
隨著 AI 能力進入新市場,選擇用于集成的 IP 為 AI SoC 提供了關鍵組件。但除了 IP 之外,設計人員還發現,利用 AI 專業知識、服務和工具具有明顯的優勢,能夠確保設計的按時交付,為最終客戶提供高質量的服務和高價值,以滿足新的創新應用需求。