













雙鏈表,這回徹底搞dong了
前言
前面有很詳細的講過線性表(順序表和鏈表),當時講的鏈表以單鏈表為主,但實際上在實際應用中雙鏈表的應用多一些就比如LinkedList。
雙鏈表與單鏈表區別
邏輯上它們均是線性表的鏈式實現,主要的區別是節點結構上的構造有所區別,這個區別從而引起操作的一些差異。
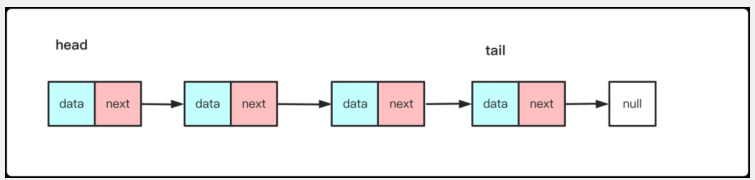
單鏈表:
單鏈表的一個節點,有儲存數據的data,還有后驅節點next(指針)。也就是這個單鏈表想要一些遍歷的操作都得通過前節點—>后節點。
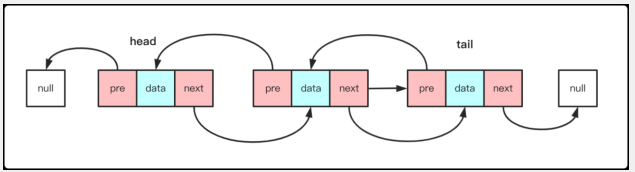
雙鏈表:
雙鏈表的一個節點,有存儲數據的data,也有后驅節點next(指針),這和單鏈表是一樣的,但它還有一個前驅節點pre(指針)。
雙鏈表結構的設計
上文講單鏈表的時候,我們當時設計的是一個帶頭結點的鏈表就錯過了不帶頭結點操作方式,這里雙鏈表咱們就不帶頭結點設計實現。并且上文單鏈表實現的時候是沒有尾指針tail的,在這里我們設計的雙鏈表帶尾指針。
所以我們構造的這個雙鏈表是:不帶頭節點、帶尾指針(tail)、雙向鏈表。
對于node節點:
- class node<T> {
- T data;
- node<T> pre;
- node<T> next;
- public node() {
- }
- public node(T data) {
- this.data = data;
- }
- }
對于鏈表:
- public class doubleList<T> {
- private node<T> head;// 頭節點
- private node<T> tail;// 尾節點
- private int length;
- //各種方法
- }
具體操作分析
對于一個鏈表主要的操作還是增刪。增刪的話不光需要考慮鏈表是否帶頭節點,還有頭插、尾插、中間插等多種插入刪除形式,其中的一些細節處理也是比較重要的(防止鏈表崩掉出錯),如果你對這塊理解不夠深入很容易寫錯也很難排查出來。當然,鏈表的查找、按位修改操作相比增刪操作還是容易很多。
初始化
雙鏈表在最初的時候頭指針指向為null。那么對于這個不帶頭節點的雙鏈表而言。它的head始終指向第一個真實有效的節點。tail也指向最后一個有效的節點。在最初的時候head=null,并且tail=head,此時鏈表為空,等待節點插入。
- public doubleList() {
- head = null;
- tail = head;
- length = 0;
- }
插入
空鏈表插入
對于空鏈表來說。增加第一個元素可以特殊考慮。因為在鏈表為空的時候head和tail均為null。但head和tail又需要實實在在指向鏈表中的真實數據(帶頭指針就不需要考慮)。所以這時候就新建一個node讓head、tail等于它。
- node<T> teamNode = new node(data);
- if (isEmpty()) {
- head = teamNode;
- tail = teamNode;
- }
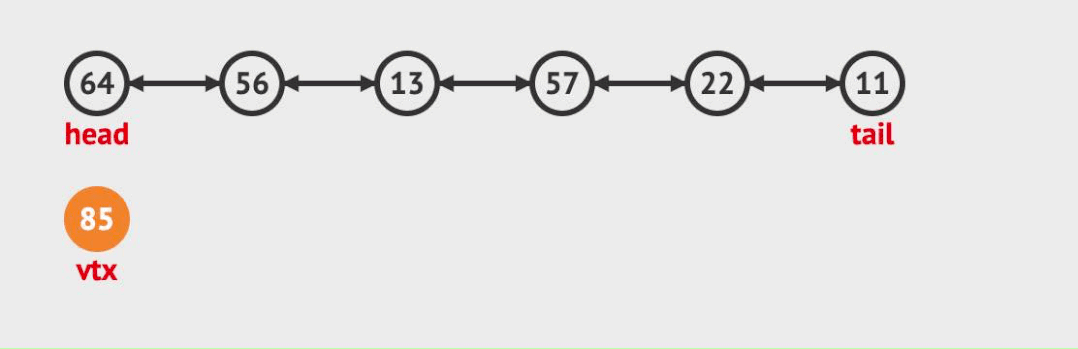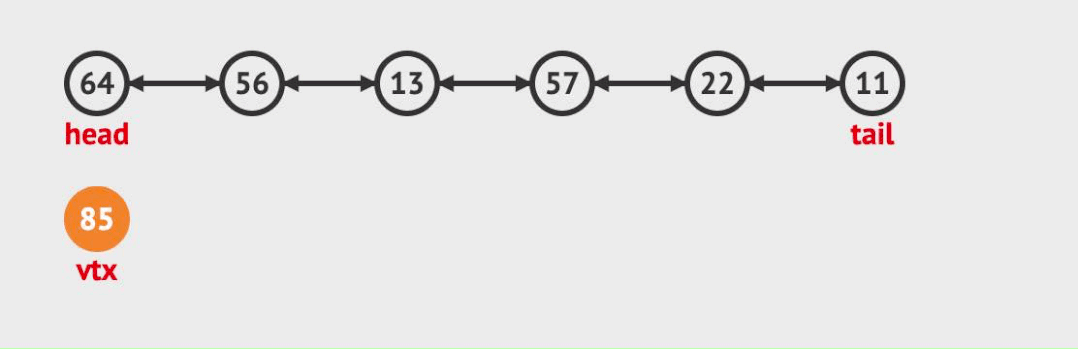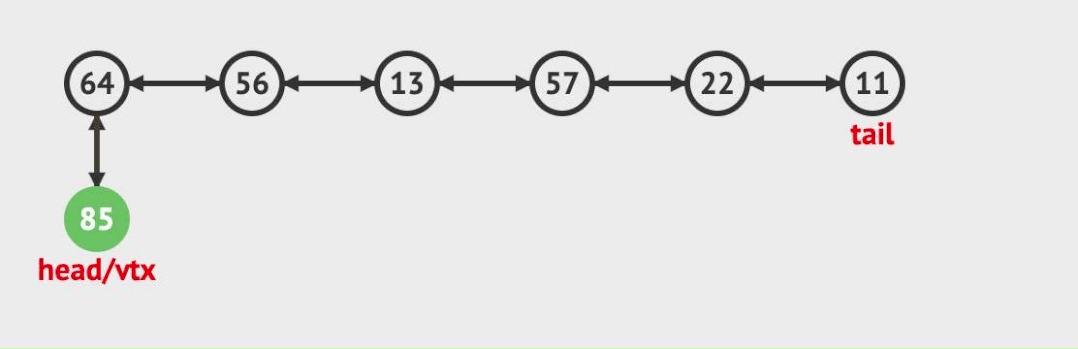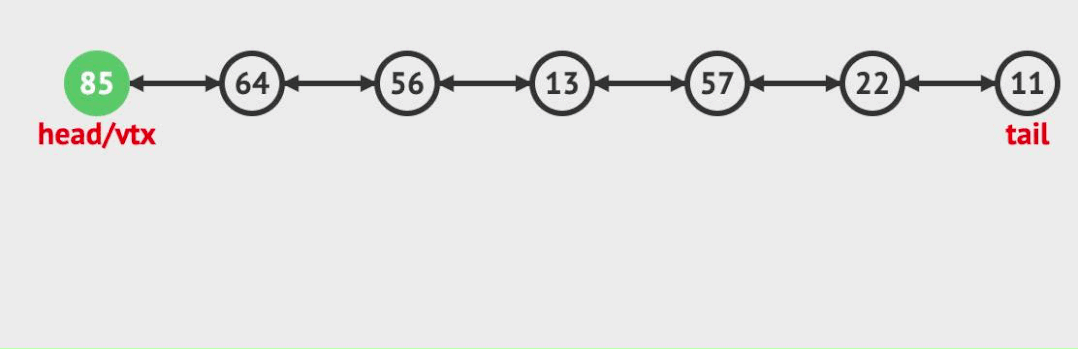
頭插
對于頭插入來說。步驟很簡單,只需考慮head節點的變化。
- 新建插入節點node
- head前驅指向node
- node后驅指向head
- head指向node。(這時候head只是表示第二個節點,而head需要表示第一個節點故改變指向)
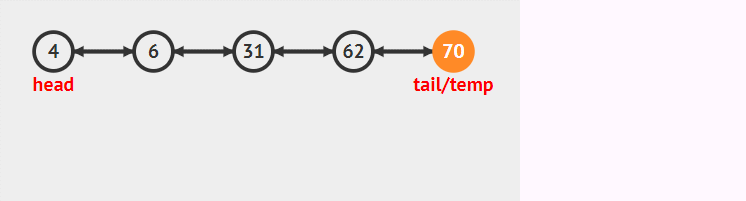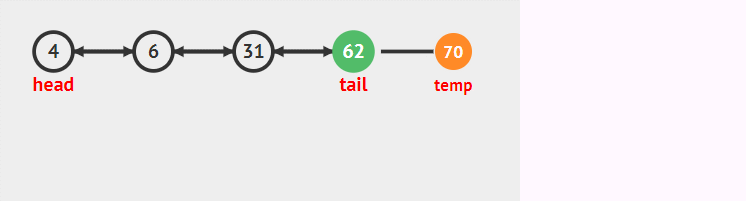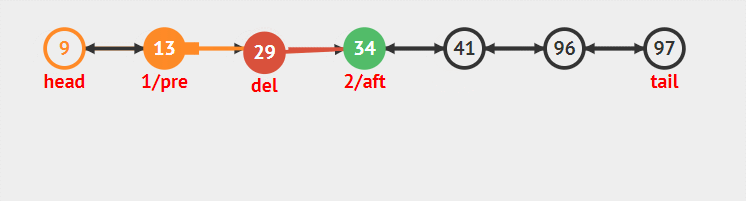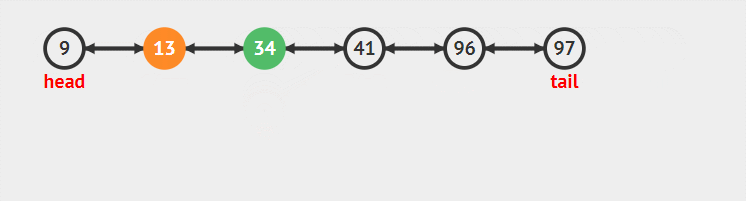
尾插:
對于尾插入來說。只需考慮尾節點tail節點的變化。
- 新建插入節點node
- node前驅指向tail
- tail后驅指向node
- tail指向node。(這時候tail只是表示倒數第二個節點,而tail需要表示最后節點故指向node)

按編號插入
對于編號插入來說。要考慮查找和插入兩步,而插入既和head無關也和tail無關。
1 新建插入節點node
2 找到欲插入node的前一個節點preNode。和后一個節點nextNode
3 node后驅指向nextNode,nextNode前驅指向node(此時node和后面與鏈表已經聯立,但是和前面處理分離狀態)
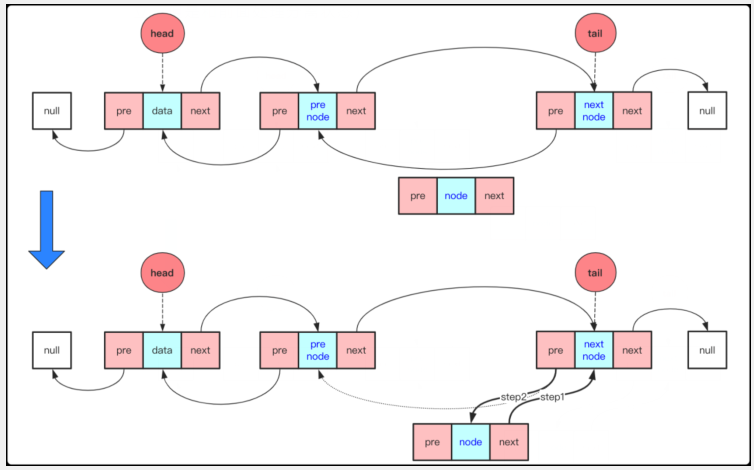
4 preNode后驅指向node。node前驅指向preNode(此時插入完整操作完畢)
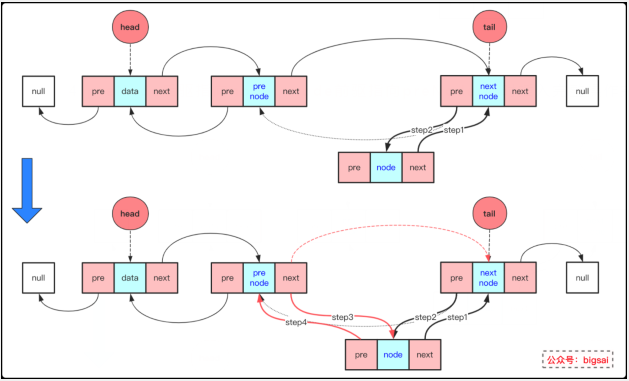
整個流程的動態圖為:
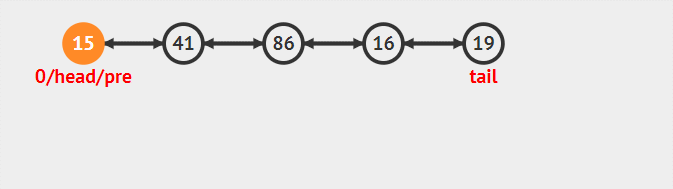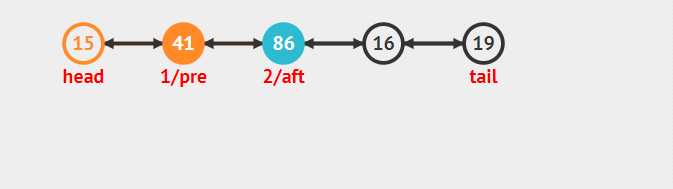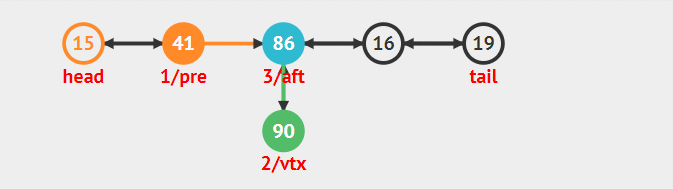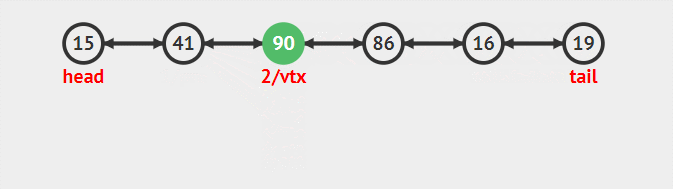
刪除
只有單個節點刪除
無論頭刪還是尾刪,遇到單節點刪除的需要將鏈表從新初始化!
- if (length == 1)// 只有一個元素
- {
- head = null;
- tail = head;
- length--;
- }
頭刪除
頭刪除需要注意的就是刪除不為空時候頭刪除只和head節點有關
流程大致分為:
1 head節點的后驅節點的前指針pre改為null。(head后面節點本指向head但是要刪除第一個先讓后面那個和head斷絕關系)
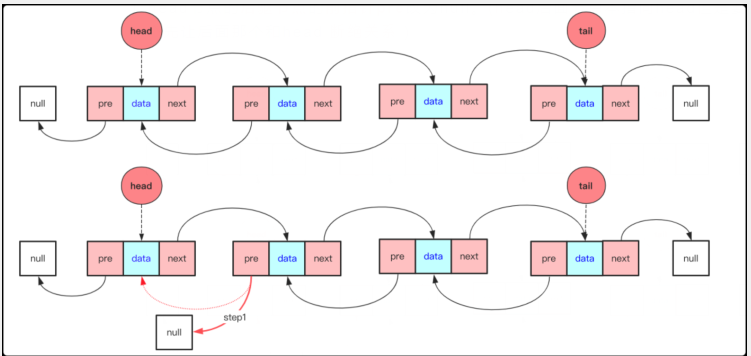
2 head節點指向head.next(這樣head就指向我們需要的第一個節點了,前面節點就被刪除成功,如果有c++等語言第一個被孤立的節點刪除釋放即可,但Java會自動釋放)
尾刪除
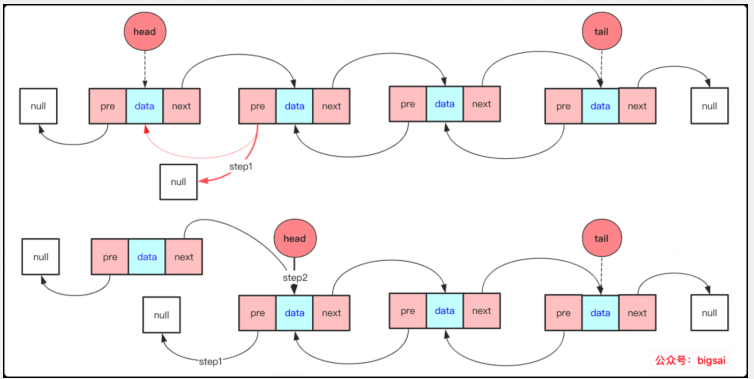
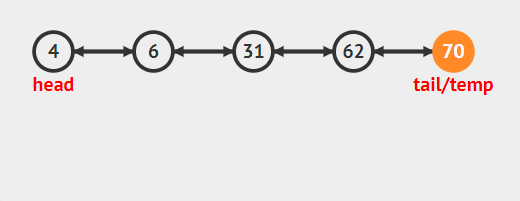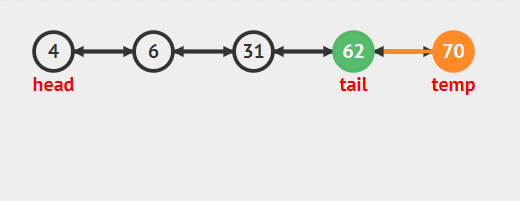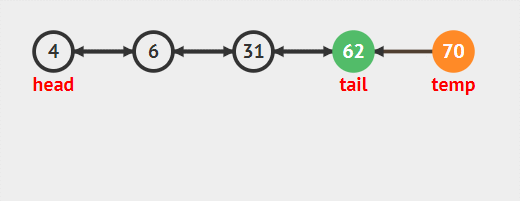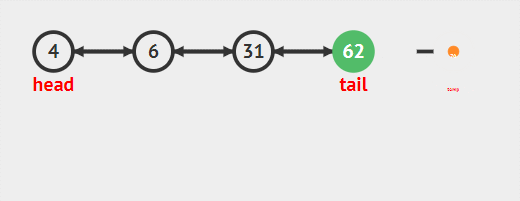
尾刪除需要注意的就是刪除不為空時候尾刪除只和tail節點有關。記得在普通鏈表中,我們刪除尾節點需要找到尾節點的前驅節點。需要遍歷整個表,而雙向鏈表可以直接從尾節點遍歷到前面。
尾刪除就是刪除雙向鏈表中的最后一個節點,也就是尾指針所指向的那個節點,思想和頭刪除的思想一致,具體步驟為:
- tail.pre.next=null尾節點的前一個節點(pre)的后驅節點等于null
- tail=tail.pre尾節點指向它的前驅節點,此時尾節點由于步驟1next已經為null。完成刪除
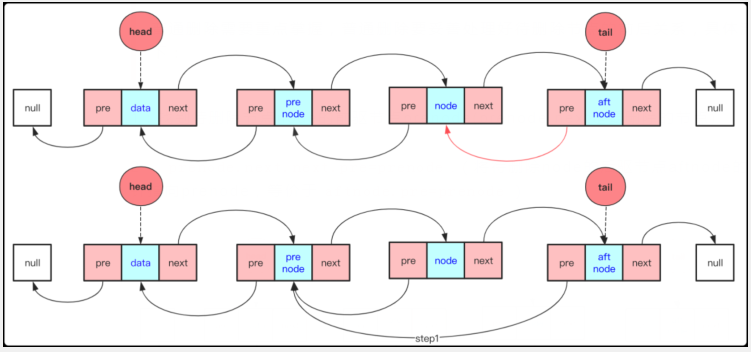
普通刪除
普通刪除需要重點掌握,普通刪除要妥善處理好待刪除節點的前后關系,具體流程如下:
1:找到待刪除節點node的前驅節點prenode(prenode.next是要刪除的節點)
2 : prenode.next.next.pre=prenode.(將待刪除node的后驅節點aftnode的pre指針指向prenode,等價于aftnode.pre=prenode)
3: prenode.next=prenode.next.next;此時node被跳過成功刪除。
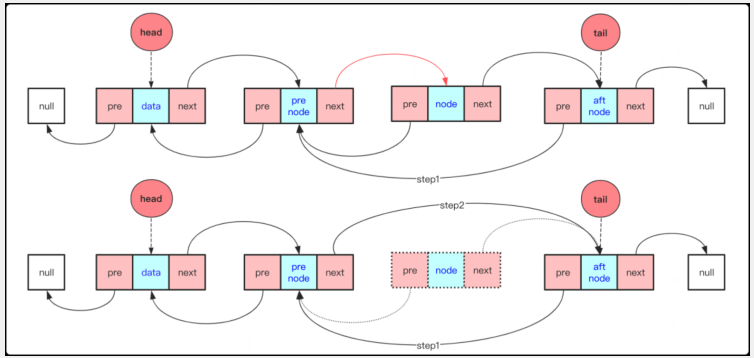
完成刪除整個流程的動態圖為:
實現與測試
通過上面的思路簡單的實現一下雙鏈表,當然有些地方命名不太規范,實現效率有待提升,主要目的還是帶著大家理解。
代碼(代碼以圖片方式貼出,如需源碼可閱讀原文或者加我好友發你):
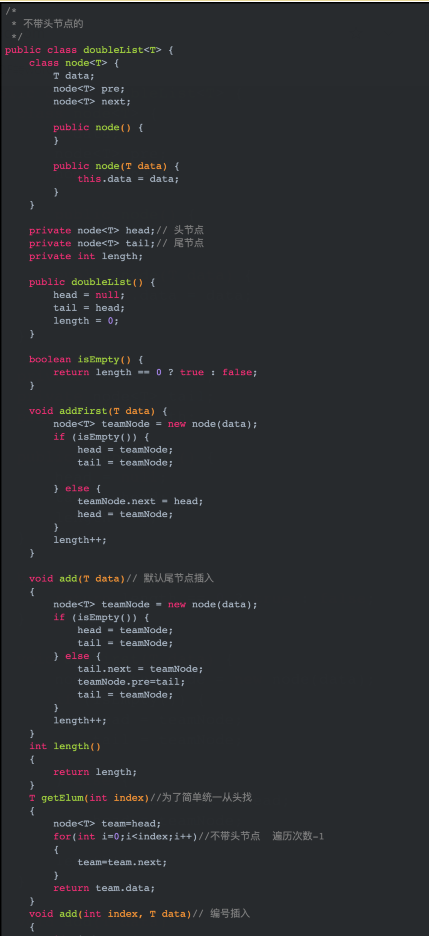
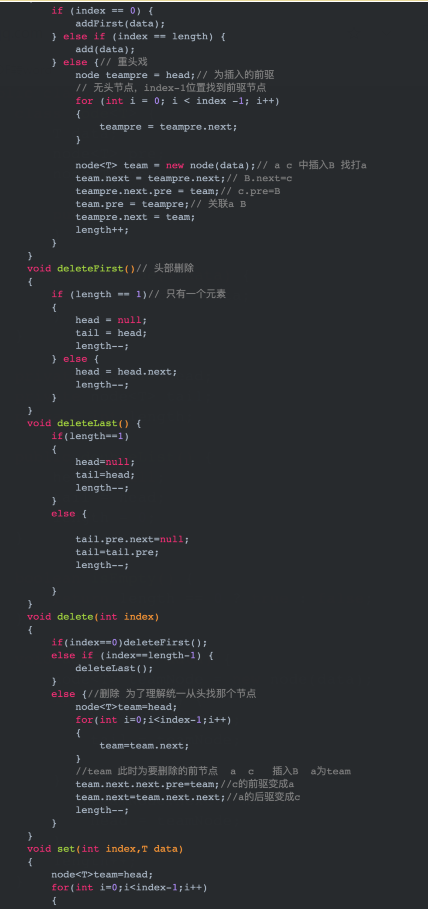
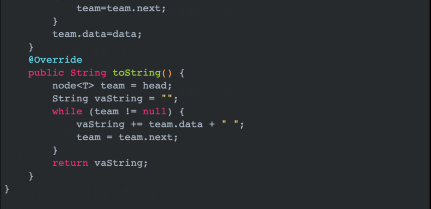
測試:
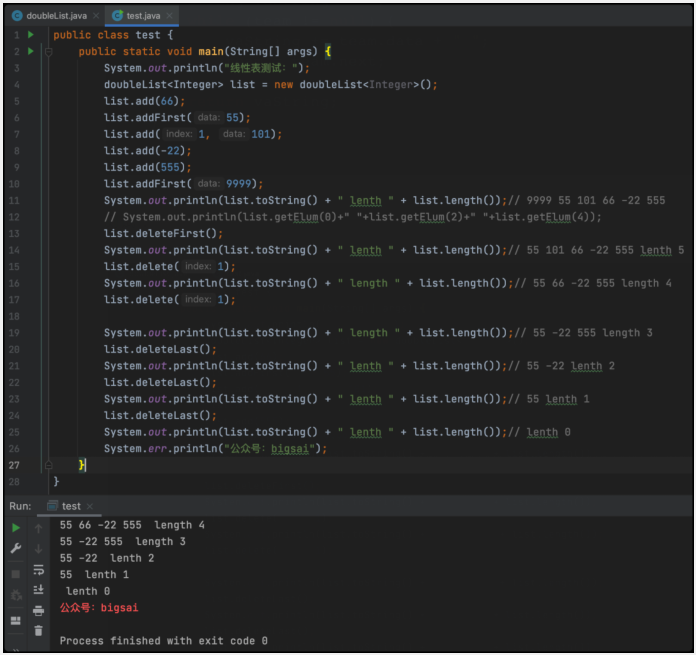
結語
在插入刪除的步驟,很多人可能因為繁瑣的過程而弄不明白,但實際上這個操作的寫法可能是多樣的,但本質操作都是一致的,所以看到其他不同版本有差距也是正常的。
還有很多人可能對一堆next.next搞不清楚,那我教你一個技巧,如果在等號右側,那么它表示一個節點,如果在等號左側,那么除了最后一個.next其他的表示節點。例如node.next.next.next可以看成(node.next.next).next。
在做數據結構與算法鏈表相關題的時候,不同題可能給不同節點去完成插入、刪除操作。這種情況操作時候要謹慎先后順序防止破壞鏈表結構。
代碼操作可能有些優化空間,還請各位大佬指正!如有收獲
























