一文帶你了解得物推薦系統是如何做排序的。網友:真牛
引言
信息時代到來以后,我們被各種各樣海量的信息所淹沒,從新聞、廣告、電商、直播、短視頻等各種涉及這些場景的APP中,大量個性化的信息被推送到我們眼前。例如在使用得物APP購物的過程中,我們也常常會聽到這樣的問題,為什么會給我推這雙鞋/這件衣服?為什么瀏覽收藏過的商品反復出現在推薦流中?推薦流是怎么猜測我的喜好的?推薦的排序邏輯是怎樣的,都考慮了哪些因素?能不能主動增加某些類目的曝光量?這些種種的問題,都和我們的排序模型、排序邏輯有關,下面就讓我們來聊聊推薦系統中是如何對商品做排序的。

圖1. 得物APP首頁推薦瀑布流
推薦系統
首先來簡單說一下推薦系統的基本架構,借用youtube論文中的一張圖片來說明。推薦系統的核心目標是從我們的總商品庫中,為用戶挑選出他最感興趣的一部分商品,從而節省用戶時間,也提高平臺的轉化效率,為交易的順利進行提供助力。除開一些工程實現部分的細節,整個過程可以大致分為兩個階段,即召回(candidate generation)和排序(ranking),其中召回的任務是從海量商品中選取部分用戶“大概率”感興趣的商品集,而排序則負責將召回選出來的這部分商品仔細分析,按照用戶可能感興趣的程度(probability),從高到低進行排序,展示給用戶觀看,整個過程在毫秒級的時間內完成。
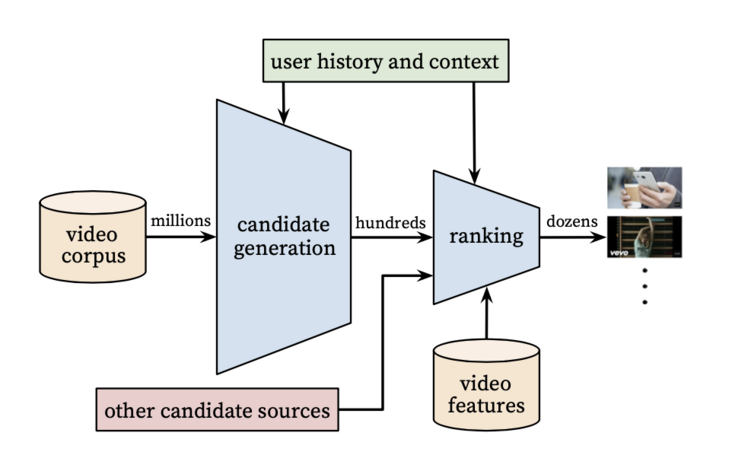
圖2. 引用自論文:Deep Neural Networks for YouTube Recommendations
召回層面的策略和邏輯有很多,也演化了很長一段時間,不過這不是我們今天聊的重點,我們來詳細聊聊,當我們拿到了召回結果,大概在一萬件以內的規模下,模型是怎樣確定他們的先后順序的,機器怎樣自動化地計算出分數來評估用戶對他們的感興趣程度的。
排序模型的發展也有很長一段時間了,從互聯網逐漸興起開始,為用戶快速篩選出有價值的信息一直是一件非常核心的事。我們不妨來看看,為了完成這項任務,都經歷了哪些演變過程。
先看一個簡單例子,一位女性用戶來到我們平臺,我們可以拿到的信息有她的性別、訪問時間、行為歷史記錄等,假設她之前逛了逛衣服,收藏了一雙鞋,最近又在瀏覽吹風機,而我們的召回候選集中又恰好有衣服、鞋和吹風機,我們應該怎樣來定義排序的邏輯呢?
規則學習
解決問題的第一階段,往往是依賴于直覺的,直覺告訴我們,每一個和用戶或者是商品有關的信息,都會影響到用戶的決策,這之中又必然存在著一定的數量關系,排序便有了最初的思路:人工規則。顧名思義,就是根據平臺運營人員對業務的熟悉程度,來直接定義物品的先后順序,例如平臺最近某件衣服是爆款,賣得很好,所以要排在前面,盡可能讓顧客看到,考慮到個性化因素,這位又是女性用戶,那么就把最近所有女性用戶購買的商品做一個統計,按照銷量從高到低排序,或者更近一步,某個地區的女性用戶,最近收藏過鞋子的某地區的女性用戶….只要劃分用戶特定維度后的數據流足夠多,規則足夠明確,最終所有商品對一個具體用戶都會有一個排序結果,一個粗糙的推薦排序策略也就成型了。
那么以上策略是否就是我們的排序方案呢?顯然并不是的。以上方案有兩個不太合理的地方:
- 人工的策略會因人而異,很難有一個統一的標準,而且幾乎不可能把所有信息整合在一起利用起來。
- 優化的目標模糊,依賴于線上實踐結果來評價好壞,總體而言大家都是為了讓平臺更好,但是每一個具體的策略,到底是優化點擊率還是轉化率還是用戶的停留時長、下拉深度,很難在給出規則時對結果有一個預期,線上實驗的成本很高,而且方案的迭代周期可能是無限長的(人總能想到各種不同的規則組合)。
有沒有一個方案能整合利用所有能拿到的信息,并且在上線前對結果有一個合理預期,甚至不需要上線實驗,離線就能評估策略的好壞呢?這個時候,機器學習方法出現在了我們眼前。
機器學習
解決問題的第二階段,就是在直覺的基礎上引入可量化的模型。模型是一個比較抽象的詞,在這里它指的是對一種映射的抽象描述,即 f(context,user,item)—> score,任何能用具體公式提供這個分數計算邏輯的方案,都可以叫做模型。衡量一個模型好壞的標準,就是這個假設出來的映射關系與現實中真實的內在關系的距離。比如個子越高,體重就越大,就是一個根據身高信息去映射體重信息的線型模型,這個模型顯然是不嚴謹的,但在很多時候也是成立的。說回我們的排序模型,我們需要設計一個方案,從用戶、商品和上下文信息(事件發生的時間、場景等客觀信息)中,提煉出用戶對商品的偏好程度。
一個能同時整合所有信息,在形式上足夠簡單,在工業界的大數據和高并發下又擁有足夠穩定性的模型,早就已經被數學所給出,那就是著名的邏輯回歸模型,形式如下:
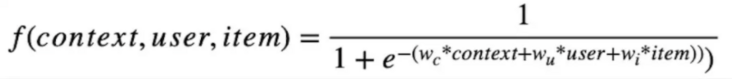
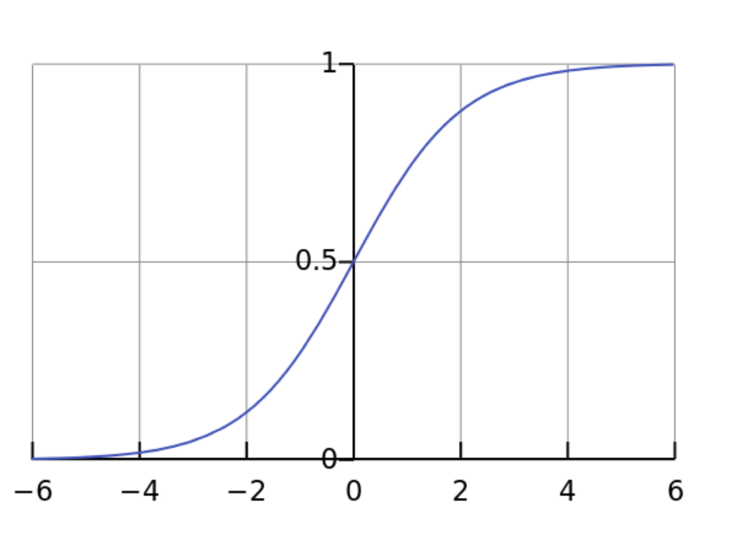
圖3. 邏輯回歸函數圖像
這個模型的形式雖然簡單,但思想足夠深刻,里面整合了數學界在參數估計、信息論和凸優化等方向的研究成果,將變量用線性的方式結合起來,把定義在(-∞,+∞)的自變量映射到(0,1)的值域上,這里的(0,1)之間的分數可以理解為用戶感興趣的概率,整個過程便成了一個點擊率預估問題。當我們用線上實時收集到的用戶行為數據作為基礎,把用戶的點擊行為轉化為0或1的訓練目標,便可以用很成熟的數學方案快速地求出公式中的所有最優化參數w,從而確定下最終的計算過程。雖然邏輯回歸模型在學術界已經是基礎中的基礎,但由于其穩定性和極高的計算效率,工業界也依然有很多業務場景中使用這套模型作為線上服務的主要擔當或者降級備用方案。
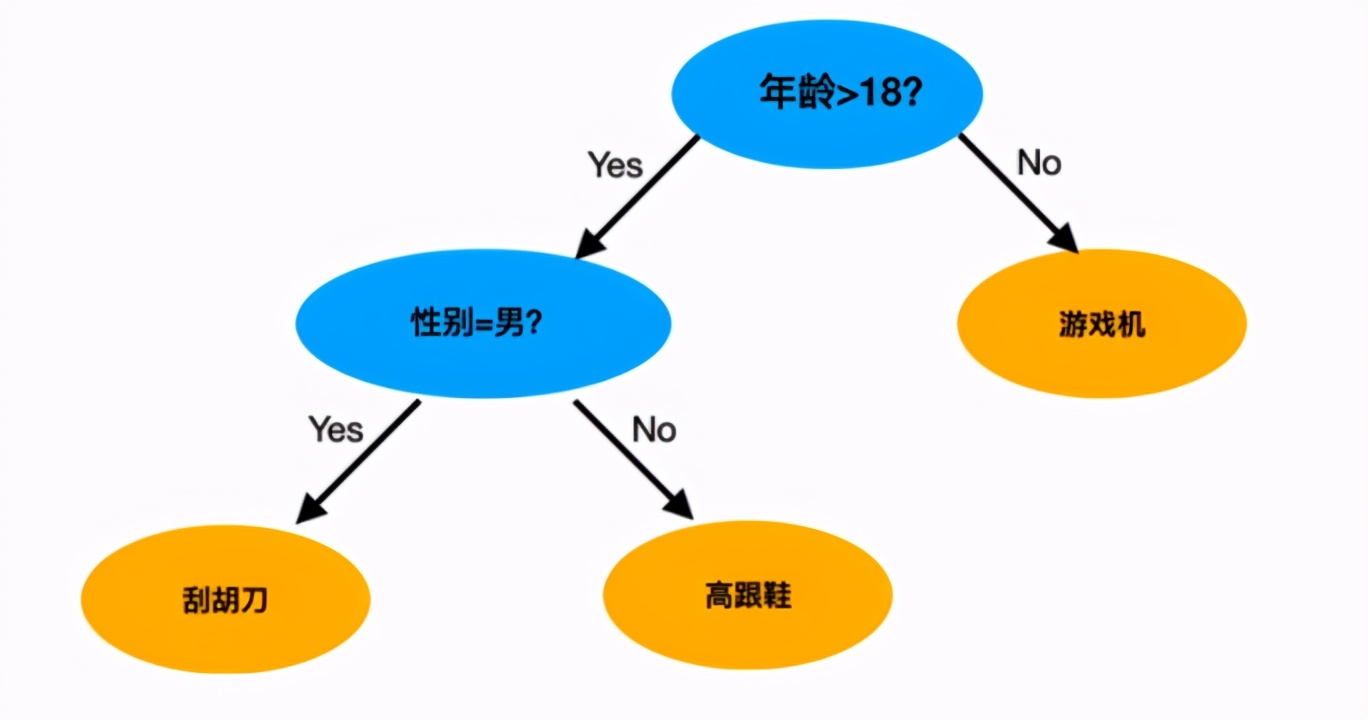
除了邏輯回歸以外,還有許多機器學習的模型被應用在排序環節中如NB, SVM和GBDT等,其中比較成功的模型是GBDT,這里面又以陳天奇博士提出的XGBoost模型最為著名,在工業界也有廣泛的應用。GBDT模型是以決策樹模型為基礎提出的組合模型,樹模型的特點是更加符合我們人對事物的判斷方式,大概的思想類似下圖:
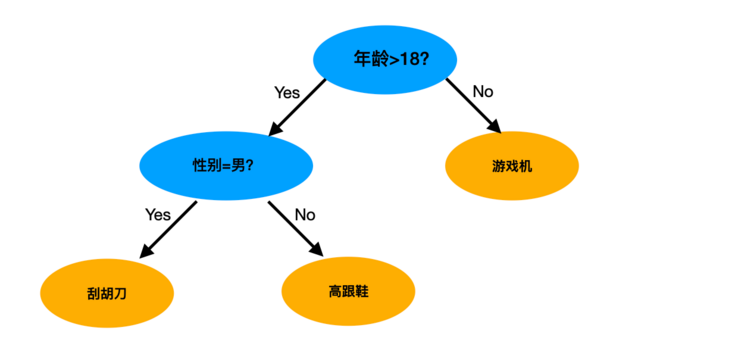
圖4. 樹模型決策思路簡述
剛才提到的GBDT模型就是將以上這種決策行為給定量化,并且使用多棵決策樹進行組合決策的結果,相比于邏輯回歸模型,它提出了一個更符合人類直覺的視角,將排序問題拆解為對若干特征的而二分類組合,將各種用戶和商品特征在決策過程中進行了交叉,實踐中效果往往是更優的,這也符合我們提到的“模型是對真實決策關系的模擬”這一觀點。但是樹模型也有它的不足,比如它優化性能較低,對大數據量的計算性能較差,對增量訓練的支持度較差等等。
總的來說,無論是邏輯回歸還是GBDT模型,都是機器學習在推薦領域很好的實踐和探索,他們各自都還存在一些明顯的不足,業界針對這些不足的地方也都有各種補充和優化的方案,經過幾年的迭代,伴隨著理論和硬件條件雙重發展的基礎上,推薦系統迎來了它的深度學習時代。
深度學習
解決問題的第三階段,是在成熟的工業界方案基礎上,加入自己對具體業務場景的理解。邏輯回歸公式簡潔,性能可靠,GBDT思路清晰,效果出色,但他們是否就是問題的最終解決方案呢?顯然還是不夠的,如上面提到的,他們各自都還有不少的問題需要解決:
- 邏輯回歸對特征間關系的刻畫過于簡單,對特征僅僅做了線性組合,與現實中大量的非線性關系的存在是違背的,比如女性、上海、數碼產品這幾個特征的簡單加減法來描述用戶購買傾向,與我們的認知不符,這三個特征和購買意愿的關系,更有可能是非線性的,而GBDT在處理特征組合時使用的方式也比較單一,難以刻畫更為復雜的組合關系。
- 數據的排序邏輯過于單一,都是以點擊率作為目標,單一目標的問題在于,很容易導致結果缺乏多樣性,用戶此刻想看數碼產品,并不意味著滿屏的推薦都應該變成數碼產品,這可能反而會降低用戶體驗。
從解決這兩個問題出發,我們的思路又細分到了兩個方向上,分別是拓寬模型的復雜度和多目標下的后排序干預。
第一個問題是拓寬模型的復雜度,在具體操作中可以分為兩個方面的工作,第一個方面,是在特征組合上盡可能提供復雜的特征,比如我們例子中,本身模型輸入的信息是性別、地區、用戶行為、商品屬性,但是我們可以人工定義一些其他的復雜特征,比如用戶是否購買過同類商品,用戶對同品牌商品的點擊次數等,通過增加特征的復雜度,來增加模型輸入的信息量,把一些非線性的關系轉化到線性模型上來解決,這樣做的好處是有效節省了計算資源,也減輕了線上推斷所帶來的壓力,對效果提升也很有幫助;不過弊端也是明顯的,那就是整體思路又回到了我們一開始人工規則的老路上,依賴于人的經驗來做優化,不過這里的人由平臺運營換成了算法工程師。所以能不能把拓寬非線性關系的工作也交給機器來完成呢?這便是第二個方面,引入深度學習的模型。
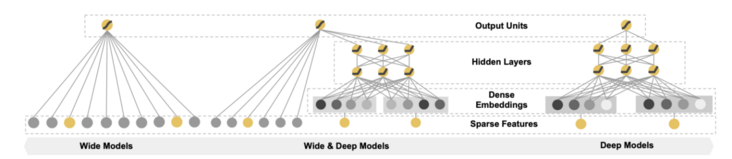
圖5. Google提出的模型的Wide&Deep模型架構
深度學習在如今的工業界早已是大名鼎鼎,從2016年起,在谷歌的W&D模型的影響下,工業界的推薦系統開始紛紛效仿,大踏步地邁進了深度學習所統治的時代,如今各大廠的主流推薦模型,都是在深度學習的基礎上做的開發,關于深度學習的理論知識,相關講解有很多,這里就不詳細展開。對于推薦系統來說,深度學習所解決的核心問題,就是特征間非線性關系的自動化挖掘。這里面的邏輯,可以說是一個“用魔法來打敗魔法”的過程。我對這個問題的理解是這樣的,特征間正確的組合方式是存在的,只是組合成幾何級增長,遍歷嘗試的操作代價難以承受,這便是第一重“魔法”;而深度學習從理論上證明,只要給定入參和目標,它可以擬合任意復雜的函數,但是最終你也不會知道擬合出來的函數具體形式是怎樣的(可解釋性目前為止也是學術界的一個很重要的方向),這便是第二重“魔法”;一邊是你無法遍歷的組合結果,另一邊是你無法解釋的組合結果,但最終產出了符合你預期的業務效果,所以我稱之為一個用魔法去打敗魔法的過程,這也是業內深度學習算法工程師又被戲稱為“煉丹工程師”的原因,很多時候工程師對于模型的具體作用原理也是難以解釋的,唯一知道的,就是它是否“有效”。
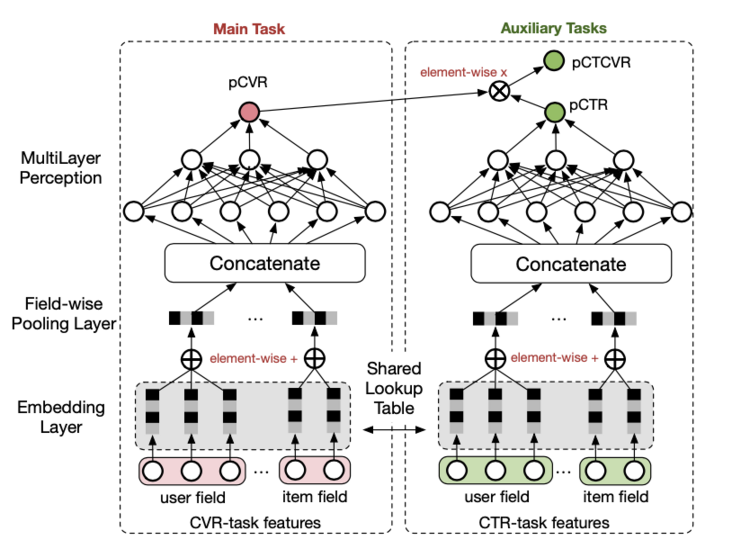
圖6.阿里巴巴提出的ESMM多目標網絡
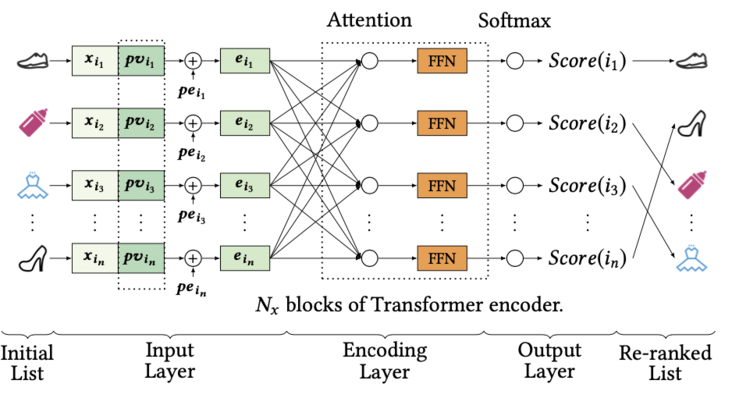
圖7.阿里巴巴提出的重排序網絡
關于邏輯回歸的第二個問題,多目標和多樣性,就不能簡單通過拓寬模型復雜度來解決了。多目標優化和后排序干預也是現在推薦排序側很重要的邏輯,由于深度學習這個魔法特別好用,所以業界也產出了很多相關的理論模型,比如阿里的ESMM和Re-ranking模型。不過由于后排序這塊是直接影響到用戶最終體驗的,不可解釋的魔法結果在目前的實用性和可控性上還是比不上能夠靈活調整的規則,因此在模型排序的結果環節,又加入了一些人工規則,比如類目打散、品牌打散和曝光過濾等,來滿足一些主觀需求。最終的排序流程,還是一個計算機模型和人工規則互相輔助來實現的。
總結
以上便是推薦系統的大體排序邏輯,以后的模型還會越來越多,也未必都會局限在深度學習的領域,整個業界也還在探尋什么樣的模型能以最小的代價刻畫出人與物的協同關系,這個問題很可能沒有一個標準答案,需要算法工程師根據具體的業務場景和業務特點去構造和處理排序的問題。最終的排序結果是在訓練數據、特征選擇、模型結構和后排序邏輯的共同干預作用下決定的,數據會是排序邏輯的核心,而不是人工主觀意識在駕馭和操縱的。雖然小的細節還在不斷地調整和改變,但是大的方向一定是以更復雜的特征、更合理的模型結構、更高效的迭代方式,更靈活的規則調整來實現更好的業務指標。