一文帶你了解TiDB
一、簡介
TiDB并不陌生,很多團隊都在使用,我們為什么要是用它,它有哪些特點呢?
TiDB 是一款開源分布式關系型數據庫,可以同時支持在線事務處理與在線分析處理 (Hybrid Transactional and Analytical Processing, HTAP) 的融合型分布式數據庫產品,具備水平擴容或者縮容、金融級高可用、實時 HTAP、云原生的分布式數據庫、兼容 MySQL 5.7 協議和 MySQL 生態等重要特性,支持在本地和云上部署。
從中可以看到TiDB有如下特性:
- 同時支持OLTP和OLAP
- 分布式數據庫,金融級別高可用
- 完全兼容MySQL,無縫切換
二、TiDB結構介紹
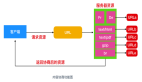
整體架構圖(以下用圖來自TiDB官方文檔&借鑒知乎)

2.1 TiDB Server
SQL 層,對外暴露 MySQL 協議的連接 endpoint,負責接受客戶端的連接,執行鑒權、 SQL 解析和優化,最終生成分布式執行計劃。TiDB 層本身是無狀態的,實踐中可以啟動多個 TiDB 實例,通過負載均衡組件(如 LVS、HAProxy 或 F5)對外提供統一的接入地址,客戶端的連接可以均勻地分攤在多個 TiDB 實例上以達到負載均衡的效果。TiDB Server 本身并不存儲數據,只是解析 SQL,將實際的數據讀取請求轉發給底層的存儲節點 TiKV(或 TiFlash)。
2.2 PD (Placement Driver) Server
整個 TiDB 集群的元信息管理模塊,負責存儲每個 TiKV 節點實時的數據分布情況和集群的整體拓撲結構,提供 TiDB Dashboard 管控界面,并為分布式事務分配事務 ID。PD 不僅存儲元信息,同時還會根據 TiKV 節點實時上報的數據分布狀態,下發數據調度命令給具體的 TiKV 節點,可以說是整個集群的“大腦”。此外,PD是無狀態的,通過raft一致性協議完成數據同步, 本身也是由至少 3 個節點構成,擁有高可用的能力,建議部署奇數個 PD 節點。
2.3 存儲節點(TiKV&TiFLASH)
- TiKV Server
TiDB的存儲方式皆為KV(key-value)存儲,一切皆KV。
負責存儲數據,從外部看 TiKV 是一個分布式的提供事務的 Key-Value 存儲引擎。存儲數據的基本單位是 Region,每個 Region 負責存儲一個 Key Range(從 StartKey 到 EndKey 的左閉右開區間)的數據,每個 TiKV 節點會負責多個 Region。TiKV 的 API 在 KV 鍵值對層面提供對分布式事務的原生支持,默認提供了 SI (Snapshot Isolation) 的隔離級別,這也是 TiDB 在 SQL 層面支持分布式事務的核心。TiDB 的 SQL 層做完 SQL 解析后,會將 SQL 的執行計劃轉換為對 TiKV API 的實際調用。所以,數據都存儲在 TiKV 中。另外,TiKV 中的數據都會自動維護多副本(默認為三副本),天然支持高可用和自動故障轉移,副本質檢也是通過raft協議維持數據一致。
- TiFlash
TiFlash 是一類特殊的存儲節點。和普通 TiKV 節點不一樣的是,在 TiFlash 內部數據是以列式的形式進行存儲,主要的功能是為分析型即OLAP場景加速。一般TiDB作數據庫使用OLTP功能,無需部署該節點。

- TiDB與MySQL差異
截止到TiDB4.0版本,與MySQL有如下差異(圖片引自知乎)

三、TiDB存儲介紹
作為保存數據的系統,首先要決定的是數據的存儲模型,也就是數據以什么樣的形式保存下來。TiKV 的選擇是 Key-Value 模型,并且提供有序遍歷方法。
TiKV 數據存儲的兩個關鍵點:
這是一個巨大的 Map,也就是存儲的是 Key-Value Pairs(鍵值對)
這個 Map 中的 Key-Value pair 按照 Key 的二進制順序有序,也就是可以 Seek 到某一個 Key 的位置,然后不斷地調用 Next 方法以遞增的順序獲取比這個 Key 大的 Key-Value。
3.1 持久化使用RocksDB
任何持久化的存儲引擎,數據終歸要保存在磁盤上,TiKV 也不例外。但是 TiKV 沒有選擇直接向磁盤上寫數據,而是把數據保存在 RocksDB 中,具體的數據落地由 RocksDB 負責。這個選擇的原因是開發一個單機存儲引擎工作量很大,特別是要做一個高性能的單機引擎,需要做各種細致的優化,而 RocksDB 是由 Facebook 開源的一個非常優秀的單機 KV 存儲引擎,可以滿足 TiKV 對單機引擎的各種要求。這里可以簡單的認為 RocksDB 是一個單機的持久化 Key-Value Map。
- Region
為了實現存儲的水平擴展,數據將被分散在多臺機器上。對于一個 KV 系統,將數據分散在多臺機器上有兩種比較典型的方案:
Hash:按照 Key 做 Hash,根據 Hash 值選擇對應的存儲節點。
Range:按照 Key 分 Range,某一段連續的 Key 都保存在一個存儲節點上。
TiKV 選擇了第二種方式,將整個 Key-Value 空間分成很多段,每一段是一系列連續的 Key,將每一段叫做一個 Region,并且會盡量保持每個 Region 中保存的數據不超過一定的大小,目前在 TiKV 中默認是 96MB。每一個 Region 都可以用 [StartKey,EndKey) 這樣一個左閉右開區間來描述。

將數據劃分成 Region 后,TiKV 將會做兩件重要的事情:
- 以 Region 為單位,將數據分散在集群中所有的節點上,并且盡量保證每個節點上服務的 Region 數量差不多。
- 以 Region 為單位做 Raft 的復制和成員管理。
以 Region 為單位做數據的分散和復制,TiKV 就成為了一個分布式的具備一定容災能力的 KeyValue 系統,不用再擔心數據存不下,或者是磁盤故障丟失數據的問題。

3.2 TiDB索引介紹
- 表數據與key-value的映射
TiDB的存儲方式key-value的鍵值對,為了方便查找在設計上做了如下優化:
為同一張表設計一個表id,用TableID表示,整數且全局唯一
為每一張表的每一行設計一個行id,用RowId表示,整數且同一張表內唯一。這里還有個小優化,如果這張表有主鍵,則TiDB把主鍵作為RowId,否則自行分配一個。
映射結構示例:
Key: tablePrefix{TableID}_recordPrefixSep{RowID}
Value: [col1, col2, col3, col4]
其中,tablePrefix、recordPrefixSep都是固定的常量,為了在key空間內區分其他數據。
- 索引與key-value的映射
TiDB索引支持主鍵索引(MySQL主鍵索引)和二級索引(MySQL平臺非聚簇索引,分唯一索引和非唯一索引),它和表與key-value的映射方式相似,也會分配一個全局唯一整數索引id,使用IndexId表示。
對于主鍵索引和唯一索引,由于列的數據是唯一的,因此對應的key-value的結構如下:
Key:tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue Value:RowID
其中indexedColumnsValue表示查詢列的值,最終是列值對應一個RowId
對于非唯一索引,由于列的數據不唯一,一個鍵值可能對應多行,需要根據鍵值范圍查詢對應的 RowID。因此,按照如下規則編碼成 (Key, Value) 鍵值對:
Key:tablePrefix{TableID}_indexPrefixSep{IndexID}_indexedColumnsValue_{RowID} Value:null
這里需要注意的是,value是null,并不是RowID,而RowID是拼接在key的結尾的。這里為什么不把value設計為RowID呢?猜測是因為key是不能夠重復的,要全局唯一,而且要均勻分布在TiKV的各個節點,只能把RowID拼接在key的結尾處,而且查詢的時候是根據鍵值RowID前面的范圍來查詢。
- 索引示例
上述所有編碼規則中的 tablePrefix、recordPrefixSep? 和 indexPrefixSep 都是字符串常量,用于在 Key 空間內區分其他數據,定義如下:
另外請注意,上述方案中,無論是表數據還是索引數據的 Key 編碼方案,一個表內所有的行都有相同的 Key 前綴,一個索引的所有數據也都有相同的前綴。這樣具有相同的前綴的數據,在 TiKV 的 Key 空間內,是排列在一起的。因此只要小心地設計后綴部分的編碼方案,保證編碼前和編碼后的比較關系不變,就可以將表數據或者索引數據有序地保存在 TiKV 中。采用這種編碼后,一個表的所有行數據會按照 RowID? 順序地排列在 TiKV 的 Key 空間中,某一個索引的數據也會按照索引數據的具體的值(編碼方案中的 indexedColumnsValue)順序地排列在 Key 空間內。
通過一個簡單的例子,來理解 TiDB 的 Key-Value 映射關系。假設 TiDB 中有如下這個表:
假設該表中有4行數據:
首先每行數據都會映射為一個 (Key, Value) 鍵值對,同時該表有一個 int? 類型的主鍵,所以 RowID? 的值即為該主鍵的值。假設該表的 TableID 為 10,則其存儲在 TiKV 上的表數據為:
除了主鍵外,該表還有一個非唯一的普通二級索引 idxAge?,假設這個索引的 IndexID 為 1,則其存儲在 TiKV 上的索引數據為:
四、TiDB執行計劃查看
4.1 概覽
由于TiDB除了協議上與MySQL兼容之外,其余的林林總總都有著自己獨特的實現,尤其是最核心的存儲實現方式更是天差地別,因此查看執行計劃也是完全不一樣的,以一個簡單SQL為例來解析說明TiDB執行計劃的含義。
SQL:

執行計劃(SQL1):

執行計劃(SQL3):

首先,create_time列上加了普通二級索引。先介紹各個列的含義:
- id 為算子名,或執行 SQL 語句需要執行的子任務。
- estRows 為顯示 TiDB 預計會處理的行數。該預估數可能基于字典信息(例如訪問方法基于主鍵或唯一鍵),或基于 CMSketch 或直方圖等統計信息估算而來(說了這么多,其實就是和MySQL執行計劃的rows類似)。
- task 顯示算子在執行語句時的所在位置。
- access object 顯示被訪問的表、分區和索引。顯示的索引為部分索引。以上示例中 TiDB 使用了 a 列的索引。尤其是在有組合索引的情況下,該字段顯示的信息很有參考意義。
- operator info 顯示訪問表、分區和索引的其他信息。
4.2 詳細介紹
4.2.1 算子
算子是為返回查詢結果而執行的特定步驟。真正執行掃表(讀盤或者讀 TiKV Block Cache)操作的算子有如下幾類:
- TableFullScan:全表掃描。
- TableRangeScan:帶有范圍的表數據掃描。
- TableRowIDScan:根據上層傳遞下來的 RowID 掃描表數據。時常在索引讀操作后檢索符合條件的行。
- IndexFullScan:另一種“全表掃描”,掃的是索引數據,不是表數據。
- IndexRangeScan:帶有范圍的索引數據掃描操作。
TiDB 會匯聚 TiKV/TiFlash 上掃描的數據或者計算結果,這種“數據匯聚”算子目前有如下幾類:
- TableReader:將 TiKV 上底層掃表算子 TableFullScan 或 TableRangeScan 得到的數據進行匯總。
- IndexReader:將 TiKV 上底層掃表算子 IndexFullScan 或 IndexRangeScan 得到的數據進行匯總。
- IndexLookUp:先匯總 Build 端 TiKV 掃描上來的 RowID,再去 Probe 端上根據這些RowID? 精確地讀取 TiKV 上的數據。Build 端是IndexFullScan? 或IndexRangeScan? 類型的算子,Probe 端是TableRowIDScan 類型的算子。
- IndexMerge:和IndexLookupReader? 類似,可以看做是它的擴展,可以同時讀取多個索引的數據,有多個 Build 端,一個 Probe 端。執行過程也很類似,先匯總所有 Build 端 TiKV 掃描上來的 RowID,再去 Probe 端上根據這些 RowID 精確地讀取 TiKV 上的數據。Build 端是IndexFullScan? 或IndexRangeScan? 類型的算子,Probe 端是TableRowIDScan 類型的算子。
- 算子的執行順序
算子的結構是樹狀的,但在查詢執行過程中,并不嚴格要求子節點任務在父節點之前完成。TiDB 支持同一查詢內的并行處理,即子節點“流入”父節點。父節點、子節點和同級節點可能并行執行查詢的一部分。
在SQL1示例中,│ └─IndexFullScan_15 算子為 idx_create_time(create_time) 索引中掃描并降序排序取出RowID,├─Limit_17(Build)算子拿出前10個RowID,└─TableRowIDScan_16(Probe) 算子隨后拿上面返回的RowID從表中檢索出數據。
Build 總是先于 Probe 執行,并且 Build 總是出現在 Probe 前面。即如果一個算子有多個子節點,子節點 ID 后面有 Build 關鍵字的算子總是先于有 Probe 關鍵字的算子執行。TiDB 在展現執行計劃的時候,Build 端總是第一個出現,接著才是 Probe 端。
- 范圍查詢
在 WHERE/HAVING/ON? 條件中,TiDB 優化器會分析主鍵或索引鍵的查詢返回。如數字、日期類型的比較符,如大于、小于、等于以及大于等于、小于等于,字符類型的 LIKE 符號等。
若要使用索引,條件必須是 "Sargable" (Search ARGument ABLE) 的。例如條件 YEAR(date_column) < 1992? 不能使用索引,但 date_column < '1992-01-01 就可以使用索引。
推薦使用同一類型的數據以及同一類型的字符串和排序規則進行比較,以避免引入額外的 cast 操作而導致不能利用索引。
可以在范圍查詢條件中使用 AND?(求交集)和 OR?(求并集)進行組合。對于多維組合索引,可以對多個列使用條件。例如對組合索引 (a, b, c):
- 當 a? 為等值查詢時,可以繼續求 b 的查詢范圍。
- 當 b? 也為等值查詢時,可以繼續求 c 的查詢范圍。
- 反之,如果 a? 為非等值查詢,則只能求 a 的范圍。
4.2.2 task簡介
目前 TiDB 的計算任務分為兩種不同的 task:cop task 和 root task。Cop task 是指使用 TiKV 中的 Coprocessor 執行的計算任務,root task 是指在 TiDB 中執行的計算任務。
SQL 優化的目標之一是將計算盡可能地下推到 TiKV 中執行。TiKV 中的 Coprocessor 能支持大部分 SQL 內建函數(包括聚合函數和標量函數)、SQL LIMIT 操作、索引掃描和表掃描。但是,所有的 Join 操作都只能作為 root task 在 TiDB 上執行。
4.2.3 operator info簡介
EXPLAIN? 返回結果中 operator info? 列可顯示諸如條件下推等信息。本文以上示例中,operator info 結果各字段解釋如下:
- range: [1,1]? 表示查詢的 WHERE? 字句 (a = 1?) 被下推到了 TiKV,對應的 task 為 cop[tikv]。
- keep order:false? 表示該查詢的語義不需要 TiKV 按順序返回結果。如果查詢指定了排序(例如 SELECT * FROM t WHERE a = 1 ORDER BY id?),該字段的返回結果為 keep order:true。
- stats:pseudo? 表示 estRows? 顯示的預估數可能不準確。TiDB 定期在后臺更新統計信息。也可以通過執行 ANALYZE TABLE t 來手動更新統計信息。
EXPLAIN? 執行后,不同算子返回不同的信息。你可以使用 Optimizer Hints 來控制優化器的行為,以此控制物理算子的選擇。例如 /*+ HASH_JOIN(t1, t2) */ 表示優化器將使用 Hash Join 算法。
4.2.4 索引總結
SQL1中的執行計劃:
- 算子│ └─IndexFullScan_15在TiKV操作掃描索引idx_create_time(create_time)并降序排序(operator info表明)
- 算子├─Limit_17(Build)獲取前10條(根據operator info的offset:0, count:10得知)數據的RowID
- 算子└─TableRowIDScan_16(Probe)在TiKV根據上面拿到的RowID去表中查詢數據
- 算子IndexLookUp_18在TiDB匯總結果├─Limit_17(Build)上的RowID,之后使用RowID從算子└─TableRowIDScan_16(Probe)精確查找數據
其實IndexLookUp_18這個算子作用就是匯聚作用,匯總從TableRowIDScan或TableRangeScan和 IndexFullScan 或 IndexRangeScan的數據。
SQL3中的執行計劃:
- 算子└─IndexFullScan_19在TiKV從索引create_time索引降序排序讀取10條RowID
- 算子└─IndexReader_21在TiDB匯總數據直接返回,無需再去讀表,因為SELECT的字段就是索引上的
- 算子Limit_10為根算子,把結果返回客戶端
寫在最后,以上是執行計劃,是相對粗略的結果,如果要獲取詳細的結果(帶有性能、執行時間等),需要查看性能分析結果,方法為SQL語句前加上EXPLAIN ANALYZE,以下為SQL1的性能分析示例:

分析結果:


由于execution_info信息比較長,分開兩次截取。性能分析計劃相比執行計劃多出了actRows和execution_info兩個比較重要需要常去關注的信息。actRows為實際掃描行數,execution_info表明了各種執行的細節。
五、總結
TiDB目前的使用還是很廣泛的,在很多家知名企業都有著非常成功的實踐。本文介紹了TiDB的架構、使用的場景、與MySQL的兼容性、數據以及索引的存儲原理、執行計劃的查看,基本涵蓋了TiDB使用的所有基礎性東西。當然TiDB的復雜度遠遠高于文中所介紹的,其內部的設計以及各種實現是相當復雜的,非常值得細究。
通過本篇文章的介紹,希望讀者對TiDB有一個大致的了解,可以擴充知識點。總結一句話,MySQL可以無縫切換到TiDB,但僅限于查詢使用,事務支持上兩者其實還有著細微的差別,并不建議從業務上直接完全替換。
參考文獻:
TiDB 簡介 | PingCAP Docs https://docs.pingcap.com/zh/tidb/stable/overview
TiDB介紹 - 知乎https://zhuanlan.zhihu.com/p/494715695