AI訓練的福音:關于合成數據的一切
如今,AI技術面臨數個難以攻克的核心挑戰。其不僅需要大量數據以提供準確結果,同時也要求我們認真挑選數據內容以避免引入偏見,而且必須嚴格遵守日益苛刻的數據隱私法規。過去幾年以來,圍繞這些挑戰誕生出一系列解決方案——包括用于幫助識別并減少偏差/偏見的各類工具、用戶數據匿名化方案以及用于保證僅在用戶同意時收集數據的管理框架等等。然而,每一種解決方案都有著自己的問題與短板。

如今,我們正迎來合成數據這一新興行業,有望全面破除上述困局。合成數據是指由計算機人工生成的數據,可用于替代自現實世界中采集的真實數據。
合成數據集必須與真實數據集擁有相同的數學與統計學屬性,但不可明確指代真實個體。大家可以將其理解為真實數據的一種數字化鏡像,能夠在統計學層面反映實際情況。如此一來,我們就可以在完全虛擬的場域當中訓練AI系統,并更輕松地針對醫療保健、零售、金融、運輸乃至農業等各類用例實現數據定制。
由此掀起的革命浪潮正在孕育當中。StartUs Insights去年6月發布的研究結果表明,已經有50多家供應商開發出合成數據解決方案。但在具體介紹領先廠商之前,我們先來了解合成數據能夠解決哪些具體問題。
真實數據帶來的大麻煩
過去幾年以來,人們越來越關注數據集中的固有偏差/偏見如何在無意之間給AI算法帶來永久存在的系統性歧視。根據Gartner公司的預測,到2022年,由數據、算法或AI項目管理團隊引入的偏差/偏見將在所有錯誤交付結果中占據85%的比例。
AI算法的激增也引發了人們對于數據隱私的日益關注。為此,歐盟通過GDPR、加利福尼亞州頒布州內隱私法案,弗吉尼亞州最近也著手制定更為嚴苛的消費者數據隱私與保護條款。
相關法律的出臺,使消費者能夠更好地控制其個人數據。例如,弗吉尼亞州的新法律向消費者授予訪問、更正、刪除及獲取個人數據副本的權利,同時也允許消費者隨時拒絕企業銷售其個人數據、或者出于針對性廣告發布等目的對個人數據/資料進行算法訪問的行為。
通過限制信息訪問渠道,個人信息確實得到了有效保護,但這同時也將犧牲算法的預測效果。要獲得高準確性AI算法,模型希望數據供應越多越好;而如果得不到充足的數據,則AI優勢在實際應用(例如協助醫學診斷及藥物研究)方面的表現也可能受到影響。
另一種隱私問題解決方案則是消費者信息匿名化。例如,我們可以通過掩蔽或消除身份特征(例如刪除電子商務交易記錄中的姓名、信用卡號,或者清除醫療記錄中的身份內容等)實現個人數據匿名化。但越來越多的證據表明,即使對某一數據源完成匿名處理,對方仍能夠利用不慎泄露的其他消費者數據集實現內容關聯與還原。實際上,通過合并來自多個來源的數據,即使經過一定程度的匿名化,惡意方仍然能夠整理出令人驚訝的清晰身份形象。在某些特定情況下,對方甚至能夠直接關聯公共來源數據,在無需任何惡意攻擊的前提下完成身份定位。
合成數據解決方案
合成數據承諾在實現AI優勢的同時,消除各類負面影響。除了將真實個人數據排除在外,合成數據還強調糾正現實場景中產生的種種偏差/偏見,由此實現超越真實數據的素材質量。
除了高度依賴個人數據的應用場景之外,合成數據還有其他多種用途。其一就是復雜的計算機視覺建模,這里往往涉及多種因素的實時交互。我們可以使用由高級游戲引擎合成的視頻數據集創建出超逼真圖像,用以描繪自動駕駛場景中可能發生的各種事件,由此獲得現實場景下幾乎不可能捕捉到、或者可能極度危險的圖像或視頻。這些合成數據集的出現,極大提升并改善了自動駕駛系統的訓練效率與效果。
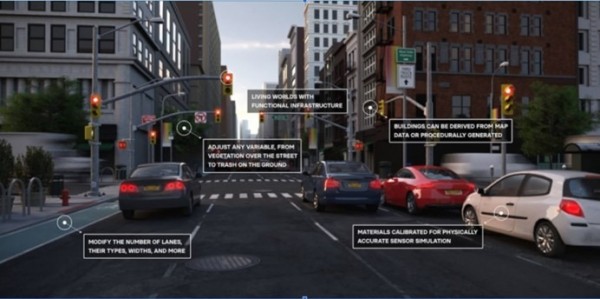
圖:使用合成圖像訓練自動駕駛車輛算法
頗為諷刺的是,用于構建合成數據的主要工具之一,恰巧與創建Deepfake深度偽造視頻的工具相同。二者均使用到生成對抗網絡,即GAN。GAN的本質在于創建兩套神經網絡,其一生成合成數據,其二則嘗試檢測合成數據是否真實。在整個操作循環當中,生成器網絡將不斷改善數據質量,直到分類器無法找出真實數據與合成數據之間的差異為止。
新興生態系統
Forrester Research最近確定了多項關鍵技術,其中就將合成數據列為實現“AI 2.0”的必要因素之一,使其能夠從本質上擴展AI的應用可能性。通過更完備的數據匿名化功能以及強大的固有偏差/偏見糾正能力,再加上批量創建以往難于獲取的數據,合成數據有望成為多種大數據應用的效率之選。
合成數據還具有其他一系列優勢:您可以快速創建數據集,并重復使用這些標記數據實現監督學習。另外,合成數據不像真實數據那樣需要清洗與維護,因此至少從理論上講,這項技術能夠節約下大量時間與成本。
目前,市場上已經出現了幾家信譽卓著的合成數據廠商。IBM表示其正著力推進數據制造業務,希望通過創建合成測試數據以消除機密信息泄露風險、解決GDPR及其他法規問題。AWS則開發出內部合成數據工具,通過生成的數據集不斷對Alexa進行新語種訓練。微軟還與哈佛大學合作開發一款工具,其中的合成數據功能可以增強各研究部門之間的協作。雖然形勢一片大好,但合成數據仍處于起步階段,市場走向將在很大程度上由新興企業的發展所決定。
下面,我們整理出一份簡單的合成數據行業早期領導廠商清單,具體信息來自G2與StartUs Insights等行業研究組織。
1、AiFi — 使用合成數據模擬零售商店與購物者行為特征。
2、AI.Reverie — 生成合成數據以訓練計算機視覺算法,借此實現活動識別、目標檢測與劃分。應用范圍包括智慧城市、稀有物質示板識別、農業以及智能零售等場景。
3、Anyverse — 使用原始傳感器數據、圖像處理功能以及汽車行業的定制化激光雷達創建合成數據集,借此實現場景模擬。
4、Cvedia — 創建合成圖像,簡化標記、真實與視覺數據的收集流程。這套模擬平臺使用多種傳感器合成逼真環境,借此創建出豐富的實證數據集。
5、DataGen — 室內環境用例,支持智能商店、家用機器人及增強現實等場景。
6、Diveplane — 為醫療保健行業創建與原始數據具有相同統計學屬性的合成“孿生”數據集。
7、Gretel — 為開發人員提供與GitHub數據等效的合成數據集,其中包含與原始數據源相同的洞見。
8、Hazy — 生成數據集以增強欺詐與洗錢檢測能力,用以打擊各類金融犯罪。
9、Mostly AI — 專注于保險與金融領域,也是最早創建合成結構化數據的廠商之一。
10、OneView – 開發虛擬合成數據集,用于通過機器學習算法分析地球觀測圖像。