













優化Pytorch模型訓練的小技巧
在本文中,我將描述并展示4種不同的Pytorch訓練技巧的代碼,這些技巧是我個人發現的,用于改進我的深度學習模型的訓練。
混合精度
在一個常規的訓練循環中,PyTorch以32位精度存儲所有浮點數變量。對于那些在嚴格的約束下訓練模型的人來說,這有時會導致他們的模型占用過多的內存,迫使他們使用更小的模型和更小的批處理大小進行更慢的訓練過程。所以在模型中以16位精度存儲所有變量/數字可以改善并修復大部分這些問題,比如顯著減少模型的內存消耗,加速訓練循環,同時仍然保持模型的性能/精度。
在Pytorch中將所有計算轉換為16位精度非常簡單,只需要幾行代碼。這里是:
- scaler = torch.cuda.amp.GradScaler()
上面的方法創建一個梯度縮放標量,以最大程度避免使用fp16進行運算時的梯度下溢。
- optimizer.zero_grad()
- with torch.cuda.amp.autocast():
- output = model(input).to(device)
- loss = criterion(output, correct_answer).to(device)
- scaler.scale(loss).backward()
- scaler.step(optimizer)
- scaler.update()
當使用loss和優化器進行反向傳播時,您需要使用scale .scale(loss),而不是使用loss.backward()和optimizer.step()。使用scaler.step(optimizer)來更新優化器。這允許你的標量轉換所有的梯度,并在16位精度做所有的計算,最后用scaler.update()來更新縮放標量以使其適應訓練的梯度。
當以16位精度做所有事情時,可能會有一些數值不穩定,導致您可能使用的一些函數不能正常工作。只有某些操作在16位精度下才能正常工作。具體可參考官方的文檔。
進度條
有一個進度條來表示每個階段的訓練完成的百分比是非常有用的。為了獲得進度條,我們將使用tqdm庫。以下是如何下載并導入它:
- pip install tqdm
- from tqdm import tqdm
在你的訓練和驗證循環中,你必須這樣做:
- for index, batch in tqdm(enumerate(loader), total = len(loader), position = 0, leave = True):
訓練和驗證循環添加tqdm代碼后將得到一個進度條,它表示您的模型完成的訓練的百分比。它應該是這樣的:
在圖中,691代表我的模型需要完成多少批,7:28代表我的模型在691批上的總時間,1.54 it/s代表我的模型在每批上花費的平均時間。
梯度積累
如果您遇到CUDA內存不足的錯誤,這意味著您已經超出了您的計算資源。為了解決這個問題,你可以做幾件事,包括把所有東西都轉換成16位精度,減少模型的批處理大小,更換更小的模型等等。
但是有時切換到16位精度并不能完全解決問題。解決這個問題最直接的方法是減少批處理大小,但是假設您不想減少批處理大小可以使用梯度累積來模擬所需的批大小。請注意,CUDA內存不足問題的另一個解決方案是簡單地使用多個GPU,但這是一個很多人無法使用的選項。
假設你的機器/模型只能支持16的批處理大小,增加它會導致CUDA內存不足錯誤,并且您希望批處理大小為32。梯度累加的工作原理是:以16個批的規模運行模型兩次,將計算出的每個批的梯度累加起來,最后在這兩次前向傳播和梯度累加之后執行一個優化步驟。
要理解梯度積累,重要的是要理解在訓練神經網絡時所做的具體功能。假設你有以下訓練循環:
- model = model.train()
- for index, batch in enumerate(train_loader):
- input = batch[0].to(device)
- correct_answer = batch[1].to(device)
- optimizer.zero_grad()
- output = model(input).to(device)
- loss = criterion(output, correct_answer).to(device)
- loss.backward()
- optimizer.step()
看看上面的代碼,需要記住的關鍵是loss.backward()為模型創建并存儲梯度,而optimizer.step()實際上更新權重。在如果在調用優化器之前兩次調用loss.backward()就會對梯度進行累加。下面是如何在PyTorch中實現梯度累加:
- model = model.train()
- optimizer.zero_grad()
- for index, batch in enumerate(train_loader):
- input = batch[0].to(device)
- correct_answer = batch[1].to(device)
- output = model(input).to(device)
- loss = criterion(output, correct_answer).to(device)
- loss.backward()
- if (index+1) % 2 == 0:
- optimizer.step()
- optimizer.zero_grad()
在上面的例子中,我們的機器只能支持16批大小的批量,我們想要32批大小的批量,我們本質上計算2批的梯度,然后更新實際權重。這導致有效批大小為32。
譯者注:梯度累加只是一個折中方案,經過我們的測試,如果對梯度進行累加,那么最后一次loss.backward()的梯度會比前幾次反向傳播的權重高,具體為什么我們也不清楚,哈。雖然有這樣的問題,但是使用這種方式進行訓練還是有效果的。
16位精度的梯度累加非常類似。
- model = model.train()
- optimizer.zero_grad()
- for index, batch in enumerate(train_loader):
- input = batch[0].to(device)
- correct_answer = batch[1].to(device)
- with torch.cuda.amp.autocast():
- output = model(input).to(device)
- loss = criterion(output, correct_answer).to(device)
- scaler.scale(loss).backward()
- if (index+1) % 2 == 0:
- scaler.step(optimizer)
- scaler.update()
- optimizer.zero_grad()
結果評估
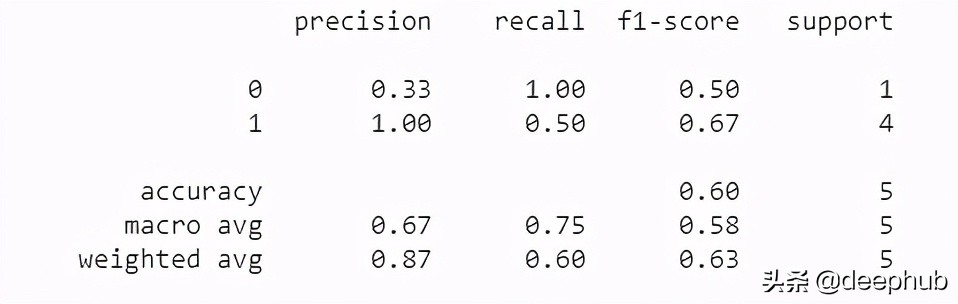
在大多數機器學習項目中,人們傾向于手動計算用于評估的指標。盡管計算準確率、精度、召回率和F1等指標并不困難,但在某些情況下,您可能希望擁有這些指標的某些變體,如加權精度、召回率和F1。計算這些可能需要更多的工作,如果你的實現可能不正確、高效、快速且無錯誤地計算所有這些指標,可以使用sklearns classification_report庫。這是一個專門為計算這些指標而設計的庫。
- from sklearn.metrics import classification_report
- y_pred = [0, 1, 0, 0, 1]
- y_correct = [1, 1, 0, 1, 1]print(classification_report(y_correct, y_pred))
上面的代碼用于二進制分類。你可以為更多的目的配置這個函數。第一個列表表示模型的預測,第二個列表表示正確數值。上面的代碼將輸出:
結論
在這篇文章中,我討論了4種pytorch中優化深度神經網絡訓練的方法。16位精度減少內存消耗,梯度積累可以通過模擬使用更大的批大小,tqdm進度條和sklearns的classification_report兩個方便的庫,可以輕松地跟蹤模型的訓練和評估模型的性能。就我個人而言,我總是用上面所有的訓練技巧來訓練我的神經網絡,并且在必要的時候我使用梯度積累。
最后,如果你使用的是pytorch或者是pytorch的初學者,可以使用這個庫:
github/deephub-ai/torch-handle
他會對你有很大的幫助。



















