如何優化PyTorch以加快模型訓練速度?
譯文
譯者 | 布加迪
審校 | 重樓
PyTorch是當今生產環境中最流行的深度學習框架之一。隨著模型變得日益復雜、數據集日益龐大,優化模型訓練性能對于縮短訓練時間和提高生產力變得至關重要。
本文將分享幾個最新的性能調優技巧,以加速跨領域的機器學習模型的訓練。這些技巧對任何想要使用PyTorch實現高級性能調優的人都大有幫助。
技巧1:通過分析識別性能瓶頸
在開始調優之前,你應該了解模型訓練管道中的瓶頸。分析(Profiling)是優化過程中的關鍵步驟,因為它有助于識別需要注意的內容。你可以從PyTorch的內置自動求梯度分析器、TensorBoard和英偉達的Nsight系統中進行選擇。下面不妨看一下三個示例。
- 代碼示例:自動求梯度分析器
import torch.autograd.profiler as profiler
with profiler.profile(use_cuda=True) as prof:
# Run your model training code here
print(prof.key_averages().table(sort_by="cuda_time_total", row_limit=10))在這個示例中,PyTorch的內置自動求梯度分析器識別梯度計算開銷。use_cuda=True參數指定你想要分析CUDA內核執行時間。prof.key_average()函數返回一個匯總分析結果的表,按總的CUDA時間排序。
- 代碼示例:TensorBoard集成
import torch.utils.tensorboard as tensorboard
writer = tensorboard.SummaryWriter()
# Run your model training code here
writer.add_scalar('loss', loss.item(), global_step)
writer.close()你還可以使用TensorBoard集成來顯示和分析模型訓練。SummaryWriter類將匯總數據寫入到一個文件,該文件可以使用TensorBoard GUI加以顯示。
- 代碼示例:英偉達Nsight Systems
nsys profile -t cpu,gpu,memory python your_script.py對于系統級分析,可以考慮英偉達的Nsight Systems性能分析工具。上面的命令分析了Python腳本的CPU、GPU和內存使用情況。
技巧2:加速數據加載以提升速度和GPU利用率
數據加載是模型訓練管道的關鍵組成部分。在典型的機器學習訓練管道中,PyTorch的數據加載器在每個訓練輪次開始時從存儲中加載數據集。然后,數據集被傳輸到GPU實例的本地存儲,并在GPU內存中進行處理。如果數據傳輸到GPU的速度跟不上GPU的計算速度,就會導致GPU周期浪費。因此,優化數據加載對于加快訓練速度、盡量提升GPU利用率至關重要。
為了盡量減少數據加載瓶頸,你可以考慮以下優化:
- 使用多個worker并行化數據加載:使用PyTorch的數據加載器與多個worker并行化數據加載。這允許CPU并行加載和處理數據,從而減少GPU空閑時間。
- 使用緩存加速數據加載:使用Alluxio作為訓練節點和存儲之間的緩存層,以實現數據按需加載,而不是將遠程數據直接加載到本地存儲或將訓練數據復制到本地存儲。
- 代碼示例:并行化數據加載
下面這個示例是使用PyTorch的數據加載器和多個worker并行化加載數據:
import torch
from torch.utils.data import DataLoader, Dataset
class MyDataset(Dataset):
def __init__(self, data_path):
self.data_path = data_path
def __getitem__(self, index):
# Load and process data for the given index
data = load_data(self.data_path, index)
data = preprocess_data(data)
return data
def __len__(self):
return len(self.data_path)
dataset = MyDataset(data_path='path/to/data')
data_loader = DataLoader(dataset, batch_size=32, num_workers=4)
for batch in data_loader:
# Process the batch on the GPU
inputs, labels = batch
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()在這個示例中,定義了自定義數據集類MyDataset。它為每個索引加載和處理數據。然后創建一個有多個worker(本例中有四個)的數據加載器實例來并行化加載數據。
- 代碼示例:使用Alluxio緩存來加速PyTorch的數據加載
Alluxio是一個開源分布式緩存系統,提供快速訪問數據的機制。Alluxio緩存可以識別從底部存儲(比如Amazon S3)頻繁訪問的數據,并在Alluxio集群的NVMe存儲上分布式存儲熱數據的多個副本。如果使用Alluxio作為緩存層,你可以顯著縮短將數據加載到訓練節點所需的時間,這在處理大規模數據集或慢速存儲系統時特別有用。
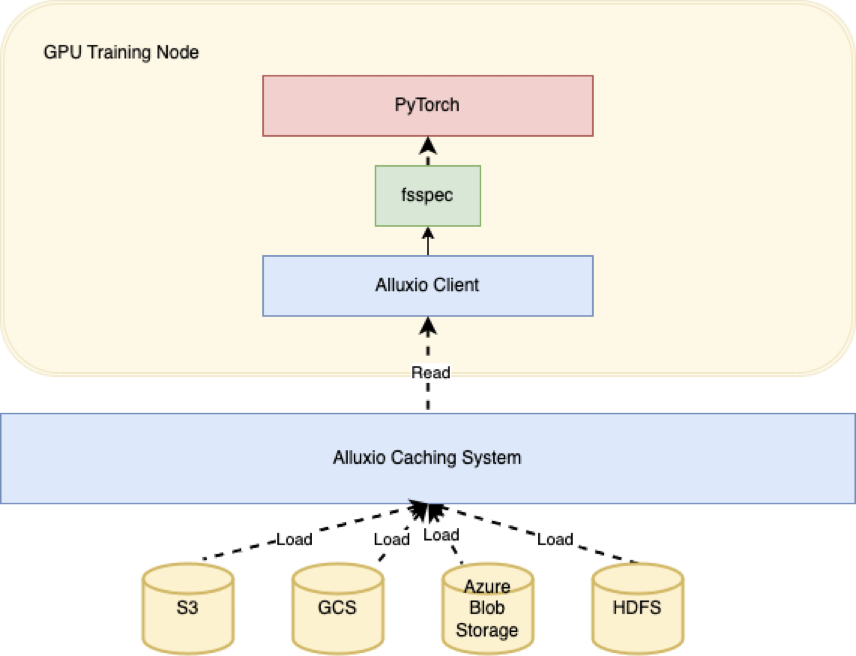
下面這個示例表明了你如何使用Alluxio與PyTorch和fsspec(文件系統規范)來加速數據加載:
首先,安裝所需的依賴項:
pip install alluxiofs
pip install s3fs接下來,創建一個Alluxio實例:
import fsspec
from alluxiofs import AlluxioFileSystem
# Register Alluxio to fsspec
fsspec.register_implementation("alluxiofs", AlluxioFileSystem,
clobber=True)
# Create Alluxio instance
alluxio_fs = fsspec.filesystem("alluxiofs", etcd_hosts="localhost",
target_protocol="s3")然后,使用Alluxio和PyArrow在PyTorch中加載Parquet文件這個數據集:
# Example: Read a Parquet file using Pyarrow
import pyarrow.dataset as ds
dataset = ds.dataset("s3://example_bucket/datasets/example.parquet",
filesystem=alluxio_fs)
# Get a count of the number of records in the parquet file
dataset.count_rows()
# Display the schema derived from the parquet file header record
dataset.schema
# Display the first record
dataset.take(0)在這個示例中,創建了一個Alluxio實例并將其傳遞給PyArrow的dataset函數。這允許我們通過Alluxio緩存層從底層存儲系統(本例中為S3)讀取數據。
技巧3:為資源利用率優化批任務大小
優化GPU利用率的另一項重要技術是調整批任務大小,它會顯著影響GPU和內存利用率。
- 代碼示例:批任務大小優化
import torch
import torchvision
import torchvision.transforms as transforms
# Define the model and optimizer
model = torchvision.models.resnet50(pretrained=True)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# Define the data loader with a batch size of 32
data_loader = torch.utils.data.DataLoader(
dataset,
batch_size=32,
shuffle=True,
num_workers=4
)
# Train the model with the optimized batch size
for epoch in range(5):
for inputs, labels in data_loader:
inputs, labels = inputs.cuda(), labels.cuda()
optimizer.zero_grad()
outputs = model(inputs)
loss = torch.nn.CrossEntropyLoss()(outputs, labels)
loss.backward()
optimizer.step()在本例中,批任務大小定義為32。batch_size參數指定了每個批中的樣本數量。shuffle=True參數隨機化批處理的順序,num_workers=4參數指定用于加載數據的worker線程的數量。你可以嘗試不同的批任務大小,以找到在可用內存范圍內盡量提高GPU利用率的最佳值。
技巧4:可識別GPU的模型并行性
處理大型復雜模型時,單個GPU的限制可能會成為訓練的瓶頸。模型并行化可以通過在多個GPU上共同分布模型以使用它們的加速能力來克服這一挑戰。
1.利用PyTorch的DistributedDataParallel(DDP)模塊
PyTorch提供了DistributedDataParallel(DDP)模塊,它可以通過支持多個后端來實現簡單的模型并行化。為了盡量提高性能,使用NCCL后端,它針對英偉達GPU進行了優化。如果使用DDP來封裝模型,你可以跨多個GPU無縫分布模型,將訓練擴展到前所未有的層面。
- 代碼示例:使用DDP
import torch
from torch.nn.parallel import DistributedDataParallel as DDP
# Define your model and move it to the desired device(s)
model = MyModel()
device_ids = [0, 1, 2, 3] # Use 4 GPUs for training
model.to(device_ids[0])
model_ddp = DDP(model, device_ids=device_ids)
# Train your model as usual2.使用PyTorch的Pipe模塊實現管道并行處理
對于需要順序處理的模型,比如那些具有循環或自回歸組件的模型,管道并行性可以改變游戲規則。PyTorch的Pipe允許你將模型分解為更小的部分,在單獨的GPU上處理每個部分。這使得復雜模型可以高效并行化,縮短了訓練時間,提高了整體系統利用率。
3.減少通信開銷
雖然模型并行化提供了巨大的好處,但也帶來了設備之間的通信開銷。以下是盡量減小影響的幾個建議:
a.最小化梯度聚合:通過使用更大的批大小或在同步之前本地累積梯度,減少梯度聚合的頻次。
b.使用異步更新:使用異步更新,隱藏延遲和最大化GPU利用率。
c.啟用NCCL的分層通信:讓NCCL庫決定使用哪種分層算法:環還是樹,這可以減少特定場景下的通信開銷。
d.調整NCCL的緩沖區大小:調整NCCL_BUFF_SIZE環境變量,為你的特定用例優化緩沖區大小。
技巧5:混合精度訓練
混合精度訓練是一種強大的技術,可以顯著加速模型訓練。通過利用現代英偉達GPU的功能,你可以減少訓練所需的計算資源,從而加快迭代時間并提高生產力。
1.使用Tensor Cores加速訓練
英偉達的Tensor Cores是專門用于加速矩陣乘法的硬件塊。這些核心可以比傳統的CUDA核心更快地執行某些操作。
2.使用PyTorch的AMP簡化混合精度訓練
實現混合精度訓練可能很復雜,而且容易出錯。幸好,PyTorch提供了一個amp模塊來簡化這個過程。使用自動混合精度(AMP),你可以針對模型的不同部分在不同精度格式(例如float32和float16)之間切換,從而優化性能和內存使用。
- 代碼示例:PyTorch的AMP
以下這個示例表明了如何使用PyTorch的amp模塊來實現混合精度訓練:
import torch
from torch.amp import autocast
# Define your model and optimizer
model = MyModel()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# Enable mixed precision training with AMP
with autocast(enabled=True, dtype=torch.float16):
# Train your model as usual
for epoch in range(10):
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()3.使用低精度格式優化內存使用
以較低精度格式(比如float16)存儲模型權重可以顯著減少內存使用。當處理大型模型或有限的GPU資源時,這點尤為重要。如果使用精度較低的格式,你可以將較大的模型放入到內存中,從而減少對昂貴內存訪問的需求,并提高整體訓練性能。
記住要嘗試不同的精度格式并優化內存使用,以便為你的特定用例獲得最佳結果。
技巧6:新的硬件優化:GPU和網絡
新的硬件技術出現為加速模型訓練提供了大好機會。記得嘗試不同的硬件配置,并優化你的工作流,以便為特定用例獲得最佳結果。
1.利用英偉達A100和H100 GPU
最新的英偉達A100和H100 GPU有先進的性能和內存帶寬。這些GPU為用戶提供了更多的處理能力,使用戶能夠訓練更大的模型、處理更大的批任務,并縮短迭代時間。
2.利用NVLink和InfiniBand加速GPU-GPU通信
當跨多個GPU訓練大型模型時,設備之間的通信開銷可能成為一大瓶頸。英偉達的NVLink互連技術在GPU之間提供了高帶寬低延遲的鏈路,從而實現更快的數據傳輸和同步。此外,InfiniBand互連技術為連接多個GPU和節點提供了一種易于擴展的高性能解決方案。它有助于盡量減小通信開銷,縮短同步梯度和加速模型訓練所花費的時間。
結語
上述這六個技巧將幫助你顯著加快模型訓練速度。切記,獲得最佳結果的關鍵是嘗試這些技術的不同組合,為你的特定用例找到最佳配置。
原文標題:This Is How To Optimize PyTorch for Faster Model Training,作者:Hope Wang
鏈接:https://thenewstack.io/this-is-how-to-optimize-pytorch-for-faster-model-training/。