













六大基本AI術語:如何做好人工智能咨詢服務?
本文轉載自公眾號“讀芯術”(ID:AI_Discovery)
想要使用人工智能咨詢服務,就要先理解這六個人工智能術語,才能很大程度地利用好咨詢內容。
1. 數據整理(Data Wrangling)
數據整理是指獲取元數據,并將其轉換為機器學習和人工智能可以識別的形式和架構的過程。為了獲取客戶所收集的數據,并用這些數據建立軟件解決方案所需的任何模型,數據整理是任何人工智能顧問都會采取的前期步驟之一。
這個過程包含了許多步驟,包括數據輸入、數據結構化、清理不良數據,以及處理數據來創建更多有效字段。這部分看起來簡單,但可能是最重要的一部分,其間需要客戶輸入的數據來引導新顧問整理這些數據。
2.人工智能模型的數據插補
大部分數據集都存在缺值字段,這就讓數據集顯得稀疏零落。最快速的解決方法就是干脆從數據集中清除掉這種字段或者屬性,但是通常來說這種解決方案非常低級,畢竟顧問起初能夠獲取的任何數據都是很寶貴的。
在這種情況下,大多數人工智能咨詢公司會根據其余數據,通過數據加工技術賦予缺值最合理的數值。最通用的技術是均值插補法,即取該字段已知數據的均值,填充進空缺處。很多數據科學顧問都采用這種技術,這是一種在不影響當前數據架構的情況下填補空缺的好方法。
3.數據分區
許多采用人工智能和機器學習的模型會將數據進行分組處理,以便用于模型訓練和測試。很多人工智能咨詢公司會要求提供的數據,無論是文件大小還是行數都要符合一定的數量要求,從而確保有足夠的數據用于分組。
有時候他們會同客戶一起收集未來的數據作為測試集,將其添加到已建立的數據集中。在Scalr.ai,特別是在未來數據可以輕易地通過容易掌控的數據流來獲取的情況下,我們會試著將兩者結合起來。
4.監督學習
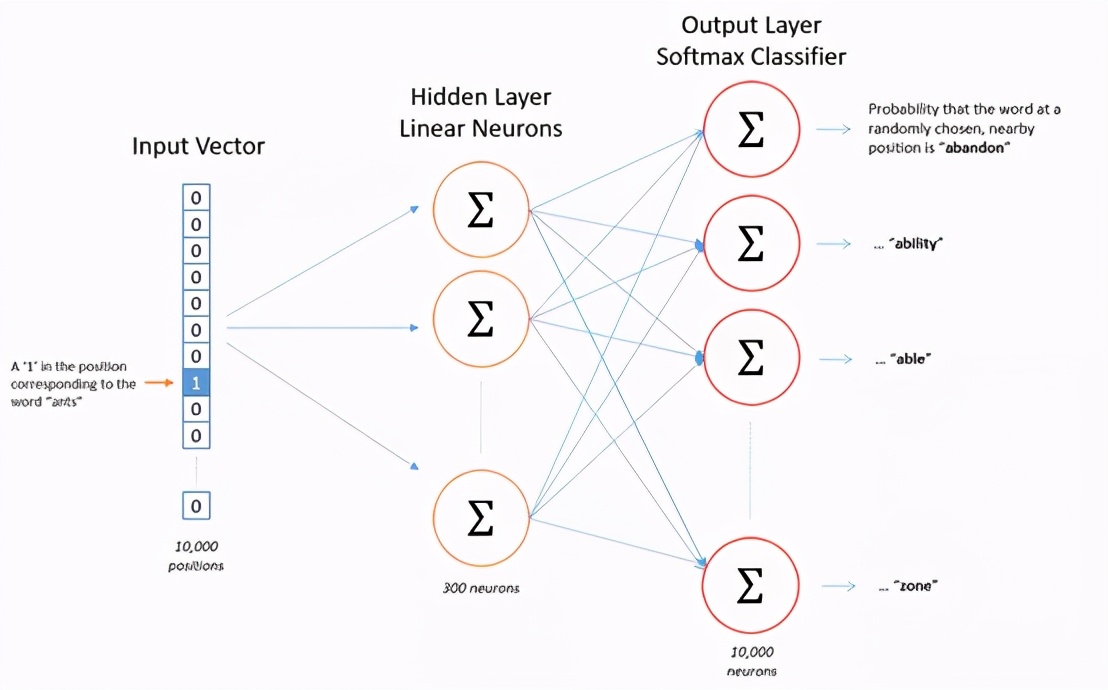
很多人工智能咨詢服務都是使用機器學習或者數據科學,并且采用算法根據屬性(又稱為字段)和最終已知目標來查找二者之間的聯系。大多數人工智能顧問在AI軟件解決方案中使用這其中至少一種方法。
這種方法有一個典型例子,就是以房屋的平方英尺、層數和房門數作為字段的一種模型。目標變量是已知的房屋價值,運用這種模型,就能預測未來的房價。
5.無監督學習
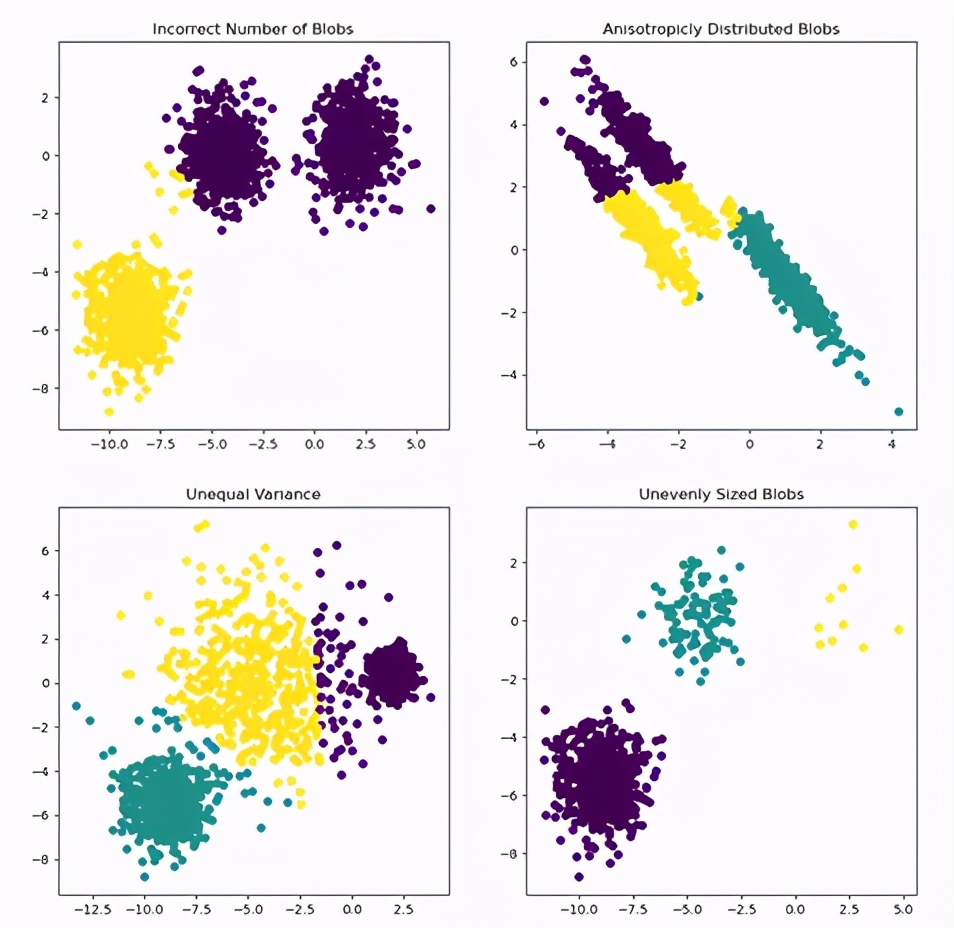
你估計能猜到了,這個過程中使用的是上面那組輸入數據,但是沒有使用目標變量,從而得到了不一樣的結論。一般而言,這么做是因為目標變量未知,有關數據的總體信息未知,卻要開始構建一些目標變量。
大多數人工智能咨詢公司會使用這些算法查找出數據中的離群值,比如安全系統中超出范圍的數據點,這些點有可能是危險信號。
6.模型的評估指標
最后,雇人來構建有效的模型和算法,得到想要的結果。人工智能顧問可以通過評估指標,掌握所完成工作的實際進展,并且根據出現的問題就如何調整解決做出決策。
大多數時候,你能聽到的用來評估模型的術語有準確性、AUC和精度,但其實,評估軟件中的模型的方法還有很多。

























