快速可微分排序算法包,自定義C ++和CUDA,性能更好
谷歌去年年初在論文《Fast Differentiable Sorting and Ranking》中,重磅推出了首個(gè)具有 O(nlogn) 時(shí)間復(fù)雜度、O(n) 空間復(fù)雜度可微分排序算法,速度比現(xiàn)有方法快出一個(gè)數(shù)量級!
近日,有人在 GitHub 上開源了一個(gè)項(xiàng)目,通過軟件包的形式實(shí)現(xiàn)了快速可微分排序和排名,上線幾天,收獲 300 + 星。
- 項(xiàng)目地址:https://github.com/teddykoker/torchsort
- 《Fast Differentiable Sorting and Ranking》論文地址:https://arxiv.org/pdf/2002.08871.pdf
Torchsort
Torchsort 實(shí)現(xiàn)了 Blondel 等人提出的快速可微分排序和排名(Fast Differentiable Sorting and Ranking),是基于純 PyTorch 實(shí)現(xiàn)的。大部分代碼是在項(xiàng)目「google-research/fast-soft-sort」中的原始 Numpy 實(shí)現(xiàn)復(fù)制而來,并配有自定義 C ++ 和 CUDA 內(nèi)核以實(shí)現(xiàn)快速性能。
Torchsort 安裝方式非常簡單,采用常用的 pip 安裝即可,安裝代碼如下:
- pip install torchsort
如果你想構(gòu)建 CUDA 擴(kuò)展,你需要安裝 CUDA 工具鏈。如果你想在沒有 CUDA 運(yùn)行環(huán)境中構(gòu)建如 docker 的應(yīng)用,在安裝前需要導(dǎo)出環(huán)境變量「TORCH_CUDA_ARCH_LIST="Pascal;Volta;Turing"」。
使用方法
torchsort 有兩個(gè)函數(shù):soft_rank 和 soft_sort,每個(gè)函數(shù)都有參數(shù) regularization (l2 或 kl) (正則化函數(shù))和 regularization_strength(標(biāo)量值)。每個(gè)都將對二維張量的最后一個(gè)維度進(jìn)行排序,準(zhǔn)確率取決于正則化強(qiáng)度:
- import torch
- import torchsort
- x = torch.tensor([[8, 0, 5, 3, 2, 1, 6, 7, 9]])
- torchsort.soft_sort(x, regularization_strength=1.0)
- # tensor([[0.5556, 1.5556, 2.5556, 3.5556, 4.5556, 5.5556, 6.5556, 7.5556, 8.5556]])
- torchsort.soft_sort(x, regularization_strength=0.1)
- # tensor([[-0., 1., 2., 3., 5., 6., 7., 8., 9.]])
- torchsort.soft_rank(x)
- # tensor([[8., 1., 5., 4., 3., 2., 6., 7., 9.]])
這兩個(gè)操作都是完全可微的,在 CPU 或 GPU 的實(shí)現(xiàn)方式如下:
- x = torch.tensor([[8., 0., 5., 3., 2., 1., 6., 7., 9.]], requires_grad=True).cuda()
- y = torchsort.soft_sort(x)
- torch.autograd.grad(y[0, 0], x)
- # (tensor([[0.1111, 0.1111, 0.1111, 0.1111, 0.1111, 0.1111, 0.1111, 0.1111, 0.1111]],
- # device='cuda:0'),)
示例展示
斯皮爾曼等級系數(shù)是用于測量兩個(gè)變量之間單調(diào)相關(guān)性的非常有用的指標(biāo)。我們可以使用 Torchsort 來創(chuàng)建可微的斯皮爾曼等級系數(shù)函數(shù),以便可以直接針對該指標(biāo)優(yōu)化模型:
- import torch
- import torchsort
- def spearmanr(pred, target, **kw):
- pred = torchsort.soft_rank(pred, **kw)
- target = torchsort.soft_rank(target, **kw)
- pred = pred - pred.mean()
- pred = pred / pred.norm()
- target = target - target.mean()
- target = target / target.norm()
- return (pred * target).sum()
- pred = torch.tensor([[1., 2., 3., 4., 5.]], requires_grad=True)
- target = torch.tensor([[5., 6., 7., 8., 7.]])
- spearman = spearmanr(pred, target)
- # tensor(0.8321)
- torch.autograd.grad(spearman, pred)
- # (tensor([[-5.5470e-02, 2.9802e-09, 5.5470e-02, 1.1094e-01, -1.1094e-01]]),)
基準(zhǔn)
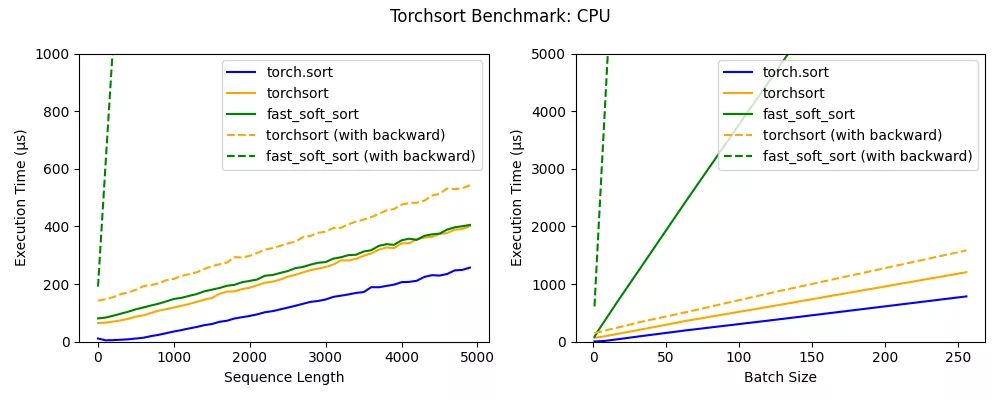
torchsort 和 fast_soft_sort 這兩個(gè)操作的時(shí)間復(fù)雜度為 O(n log n),與內(nèi)置 torch.sort 相比,每個(gè)操作都具有一些額外的開銷。Numba JIT 的批處理大小為 1(請參見左圖),fast_soft_sort 的前向傳遞與 Torchsort CPU 內(nèi)核的性能大致相同,但是其后向傳遞仍然依賴于某些 Python 代碼,這極大地降低了其性能。
此外,torchsort 內(nèi)核支持批處理,隨著批處理大小的增加,會產(chǎn)生比 fast_soft_sort 更好的性能。
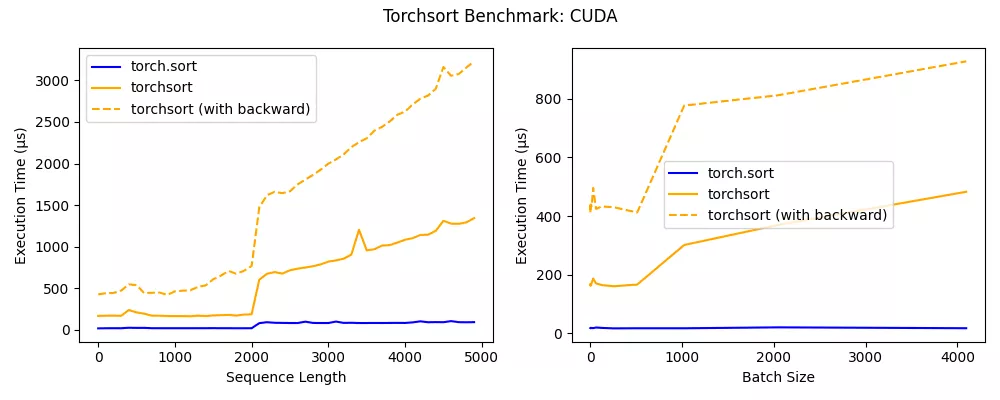
torchsort CUDA 內(nèi)核在序列長度低于 2000 時(shí)表現(xiàn)出色,并且可以擴(kuò)展到非常大的 batch。在未來,CUDA 內(nèi)核可能會進(jìn)一步優(yōu)化,以達(dá)到接近內(nèi)置的 torch.sort 的性能。