無需手工設計,從零開始搜索損失函數
近年來,自動機器學習(AutoML)在模型結構、訓練策略等眾多深度學習領域取得了進展。然而,損失函數作為深度學習模型訓練中不可或缺的部分,仍然缺乏良好的探索。目前,多數研究工作仍然使用交叉熵損失(Cross-Entropy Loss)、范數損失(L1/L2 Loss)來監督網絡訓練。盡管這類損失函數在多數情況下可以取得不錯的效果,但它們與網絡在測試時使用的評估指標之間大多存在差異,而這種差異會對模型訓練效果造成損傷。
目前對于損失函數進行改進的工作可以分為兩類:
手工設計。手工設計損失函數依賴于設計者對特定任務和評價指標的專業知識和理解,因此很難在不同任務上進行推廣。
自動設計。自動設計損失函數的工作嘗試自動搜索較優的損失函數,但當前的工作都僅僅關注于某個特定任務(如語義分割)或特定評價指標(如mAP),對特定情形進行了針對性設計,因此其可推廣性也存在疑問。
為了盡可能減少針對各種任務設計合適的損失函數時所需的人力成本,來自香港中文大學、商湯科技等機構的研究者設計了一個通用的損失函數搜索框架AutoLoss-Zero。為了確保通用性,該方法的搜索空間由一些基本的數學運算組成,而不包括對于某個評價指標的針對性設計。由于此類搜索空間中有效的損失函數十分稀疏,研究者提出了高效且通用的拒絕機制和梯度等價性檢測,以提高搜索的效率。給定任意任務和評價指標,AutoLoss-Zero可以以合理的開銷(4張V100,48h內)從隨機初始化開始,搜索到與手工設計的損失函數表現相似或更優的損失函數。

論文地址:
https://arxiv.org/abs/2103.14026
該研究的主要貢獻包括:
AutoLoss-Zero是首個通用于各種任務的損失函數搜索框架,其搜索空間由基本數學運算構成,無需先驗知識,可以極大地減少損失函數設計所需的人力。該研究在多項計算機視覺任務(目標檢測、語義分割、實例分割、姿態估計)上驗證了AutoLoss-Zero的有效性;
該研究提出了高效的拒絕機制,從而快速地篩選掉絕大多數沒有希望的損失函數。同時,該研究提出了一個基于梯度的等價性檢測,以避免對于彼此等價的損失函數進行重復的評估;
實驗表明,該方法搜索出的損失函數可以很好地遷移到不同數據集和網絡結構上。
搜索空間
該研究首先定義了搜索目標。給定任意任務上的評價指標 ξ ,該方法嘗試搜索一個最優的損失函數 L(y ̂,y;N_ω ),其中N_ω表示參數為ω的網絡,y ̂表示網絡的預測,y表示網絡的訓練目標。因此,搜索目標可以表示為一個嵌套優化(nested optimization):
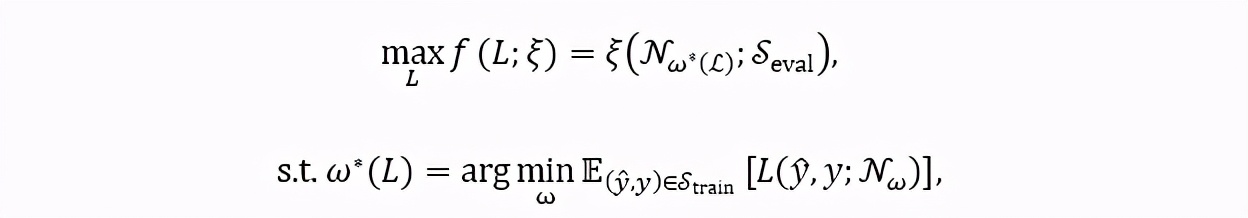
其中優化目標 f(L;ξ) 表示損失函數 L 在評價指標 ξ 上的得分,ω^* (L) 表示使用損失函數L訓練的網絡參數,E(⋅) 表示數學期望,S_train 和S_eval 表示搜索過程中使用的訓練集和驗證集。
該搜索空間由一些基礎的數學運算組成,這個集合稱為 H,如下表所示。
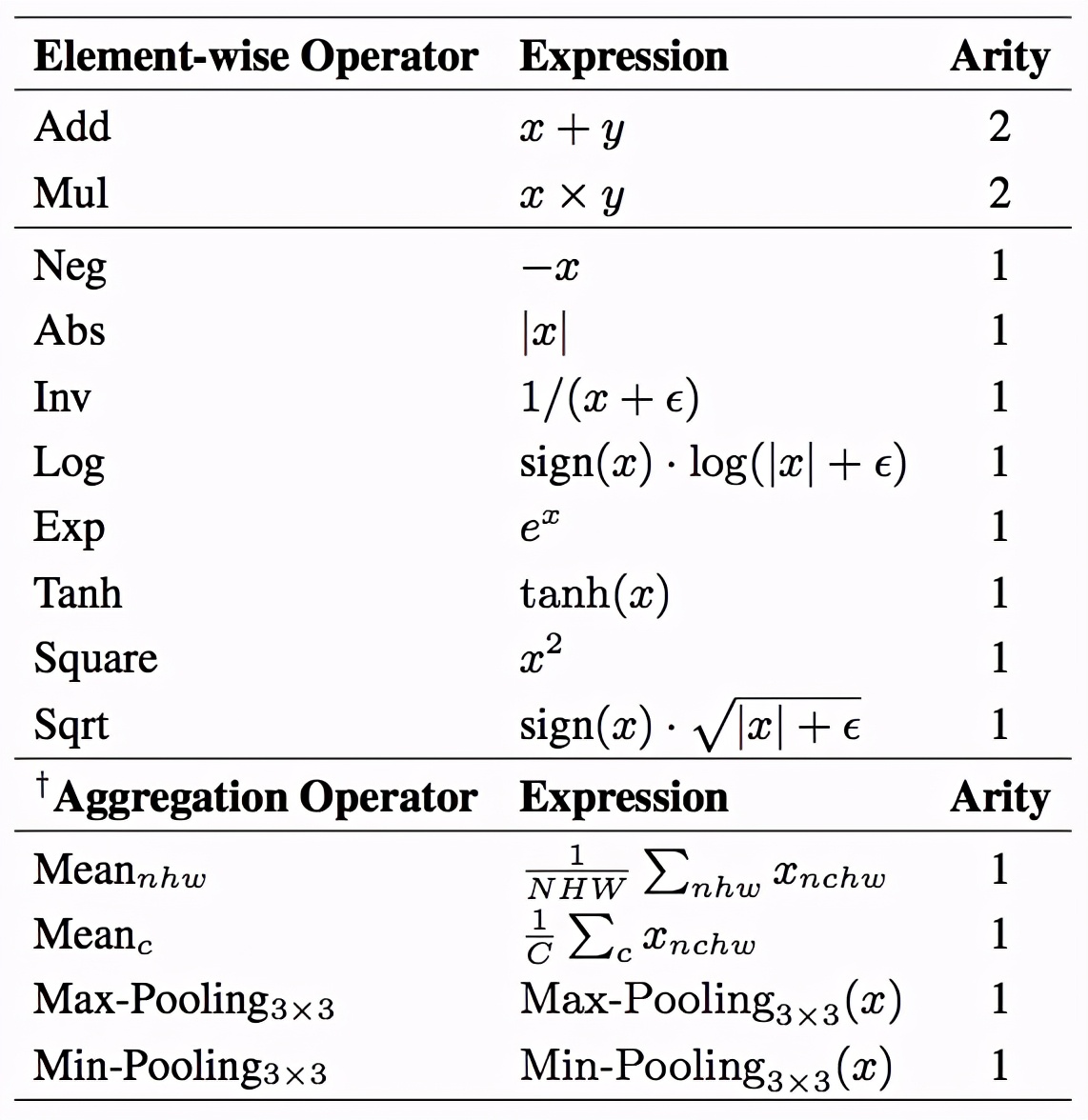
表1. 搜索空間候選運算
該方法將損失函數表示為一個計算圖 G。G 是一個有根樹(rooted tree),其中葉子節點表示損失函數的輸入(即網絡預測 y ^和訓練目標 y),根節點表示損失函數的輸出 o,其他的中間節點從表中的數學運算里采樣得到。此外,該方法還添加一個常數 1 作為損失函數的候選輸入,以增加其表示能力。在整個運算圖內,所有的張量(tensor)都保持同樣的形狀 (N,C,H,W),分別代表(batch, channel, height, width)四個維度的尺寸。計算圖 G 的輸出 o 會被融合(aggregate)為最終的損失值:
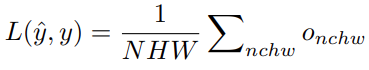
在一些任務中,損失函數由多個分支組成(如目標檢測中的分類和邊框回歸分支)。在這種情況下,我們將每個分支表示為一個獨立的計算圖 G,并將它們的損失值求和作為最終的損失值。搜索對所有的分支同時進行。
搜索算法
該方法使用進化算法對損失函數進行搜索。圖1為整個搜索算法的流程圖。
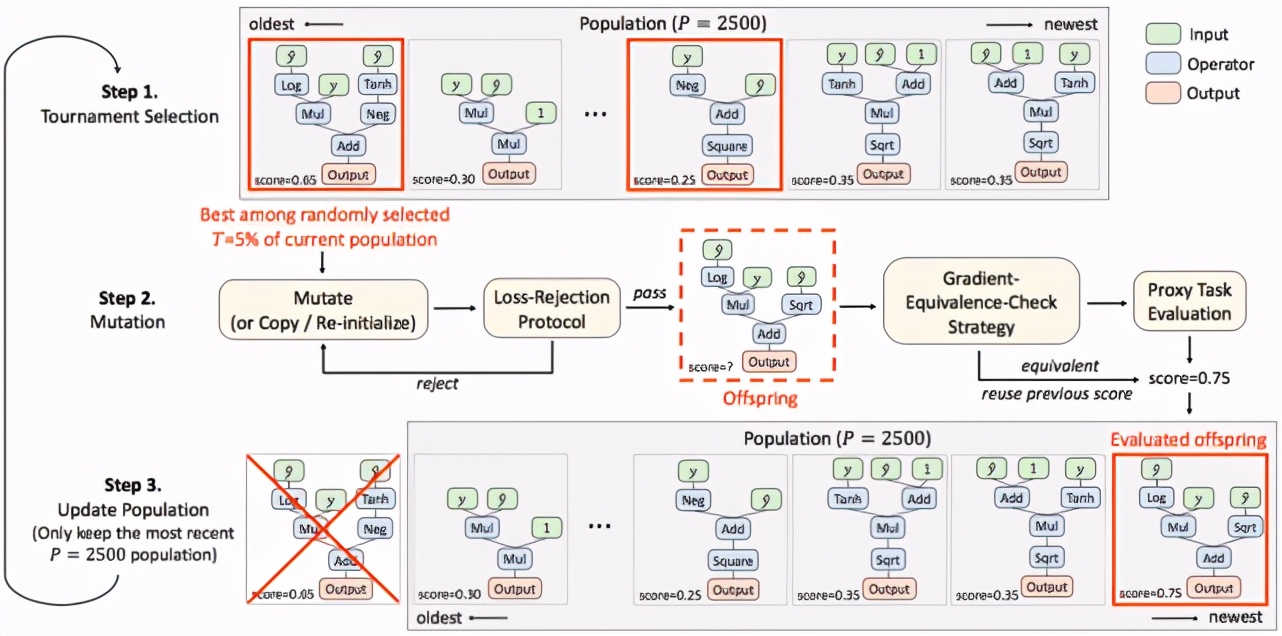
圖 1. 搜索算法流程圖
在搜索初始化階段,我們首先隨機生成 K(默認K=20)個損失函數作為初始種群。此后,每一次更新隨機采樣當前種群內 T(默認T=5%)比例的損失函數,并對其中在代理任務上得分最高的一個進行變異(mutation),得到后代個體,并加入種群。在種群的更新過程中,只有最新的 P=2500 個個體會被保留。
由于搜索空間中有效的損失函數十分稀疏,盡管代理任務相對于最終的網絡訓練已經相當簡化,但對于每個候選的損失函數都進行代理任務上的評估,時間成本仍然是不可接受的。為此,研究者設計了一個損失函數拒絕機制(loss-rejection protocol),對候選的損失函數進行初步篩選。在損失函數的隨機生成和變異過程中,如果候選子代個體無法通過篩選,則重新進行隨機生成/變異,直到得到可以通過篩選的損失函數,用于代理任務上的評估。此外,該方法在對候選的損失函數進行評估前,會先檢測其是否與已評估過的損失函數等價(
gradient-equivalence-check strategy),若等價則跳過代理任務的網絡訓練,復用之前相同個體的分數。
接下來,我們來看下搜索算法中的幾個關鍵部分。
隨機初始化
損失函數隨機初始化的過程如圖2所示。計算圖從根節點開始,遞歸地從候選運算集合 H 中隨機采樣運算符作為其子節點。每個節點的子節點數由這個節點所代表的運算的操作數決定。該方法固定隨機初始化的計算圖深度為 D(默認D=3),在當前節點深度達到 D 后,其從候選的輸入集合 中有放回地隨機采樣子節點,這些子節點即為計算圖的葉子節點。
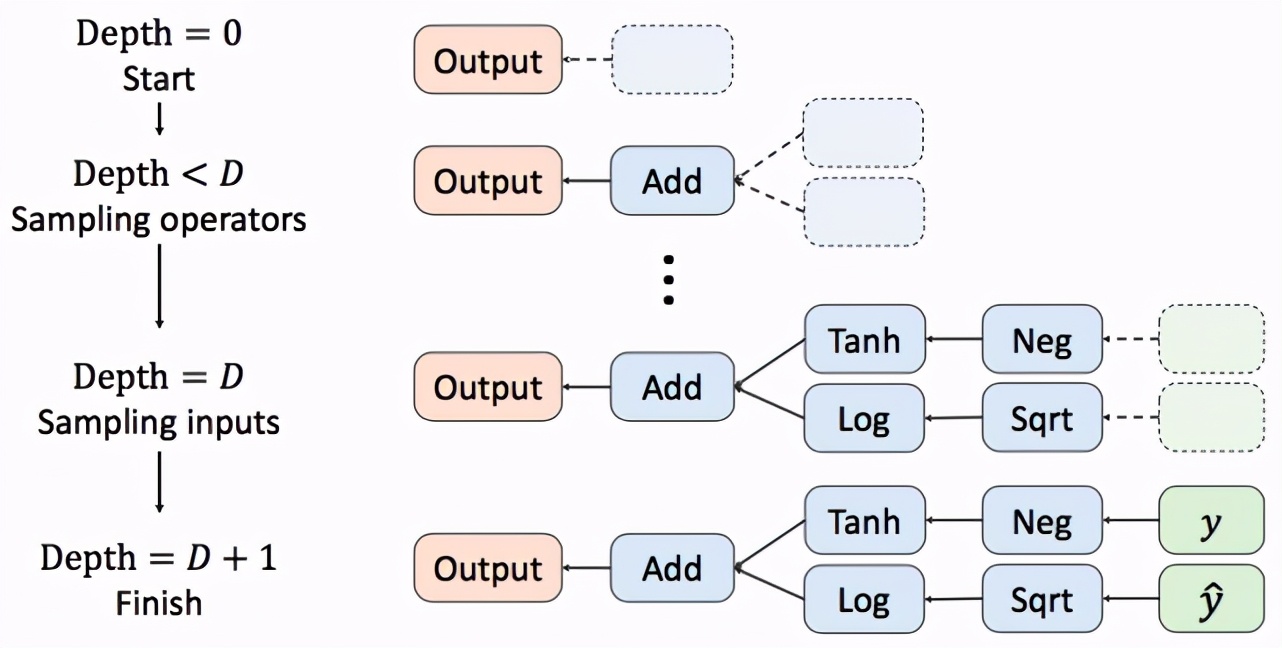
圖2. 損失函數隨機初始化
變異
基于該研究提出的損失函數表示形式,研究者定義了三種不同的變異類型:插入(Insertion),刪除(Deletion)及替換(Replacement)。三種變異類型的示意圖如圖3所示。

圖3. 變異類型
在每次產生子代的過程中,存在10%的概率不進行變異,而直接復制父代個體。此外,為了鼓勵算法進行探索,在變異時,損失函數有50%的概率被重新隨機初始化。
損失函數拒絕機制
搜索的目標是找到可以盡可能最大化評價指標ξ的損失函數 L。基于此,研究者提出一個損失函數L和評價指標ξ之間的相關性分數 g(L;ξ),來衡量一個損失函數對評價指標進行優化的能力。
該研究從訓練數據集中隨機選擇 B 個樣本(在實驗中統一使用B=5),使用一個隨機初始化的網絡 N_(ω_0 ) 對這 B 個樣本進行計算,并將網絡預測 y ^ 和對應的訓練目標 y 存儲下來,記作 {(y ^_b,y_b )}_(b=1)^B。接下來,通過梯度下降的方式,使用候選的損失函數 L(y ^,y) 對網絡預測 y ^ 直接進行優化,并計算優化結果 y ^* 在評價指標 ξ上的得分,即
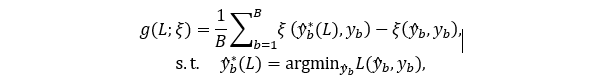
g(L;ξ) 即為優化結果相對于初始預測的提升。這個分數越高,意味著損失函數對評價指標的優化能力越強。因此,該研究設置了一個閾值 η(實驗中默認η=0.6),相關性分數 g(L;ξ) 低于此閾值的損失函數被認為是沒有希望(unpromising)的,會被直接拒絕。在此過程中并沒有網絡計算的參與,而是直接對輸入進行優化,這使得該損失函數拒絕機制十分高效。實驗表明,在一個 GPU 上,每分鐘可以篩選 500~1000 個候選損失函數。這大大提高了算法探索搜索空間的能力。
梯度等價性檢測
為了避免對于相互等價的損失函數進行重復的代理任務評估,對于每個評估過的損失函數,該方法記錄其相對于上文「損失函數拒絕機制」中使用的B個樣本的梯度的二范數,即。若兩個損失函數對于這B個樣本,其梯度二范數均相同(取兩位有效數字),則我們認為這兩個損失函數是等價的,并將較早的損失函數的代理任務分數復用于新的損失函數。
實驗
該研究在語義分割、目標檢測、實例分割和姿態估計等四項計算機視覺任務上從隨機初始化開始進行了搜索。此外,該研究對搜索得到的損失函數的泛化性進行了研究,并對前文所提到搜索算法中的各項技術對于搜索效率的影響進行了分析。
語義分割
該研究使用 PASCAL VOC 數據集對語義分割任務中主流的 6 個評價指標進行了搜索,并使用得到的損失函數對 DeepLab V3+ 網絡進行了重新訓練(re-train)。表 2 為該研究的實驗結果。該研究將搜索得到的損失函數與常見的基于手工設計的損失函數及自動搜索的損失函數(ASL, Auto Seg-Loss)進行了比較。結果表明,在主流的幾個評價指標上,AutoLoss-Zero 搜索到的損失函數達到或超過了當前最好的結果,僅在 BIoU 這一指標上略低于為專門關注語義分割任務的 ASL 方法,但也大大超過了現有基于手工設計的損失函數。
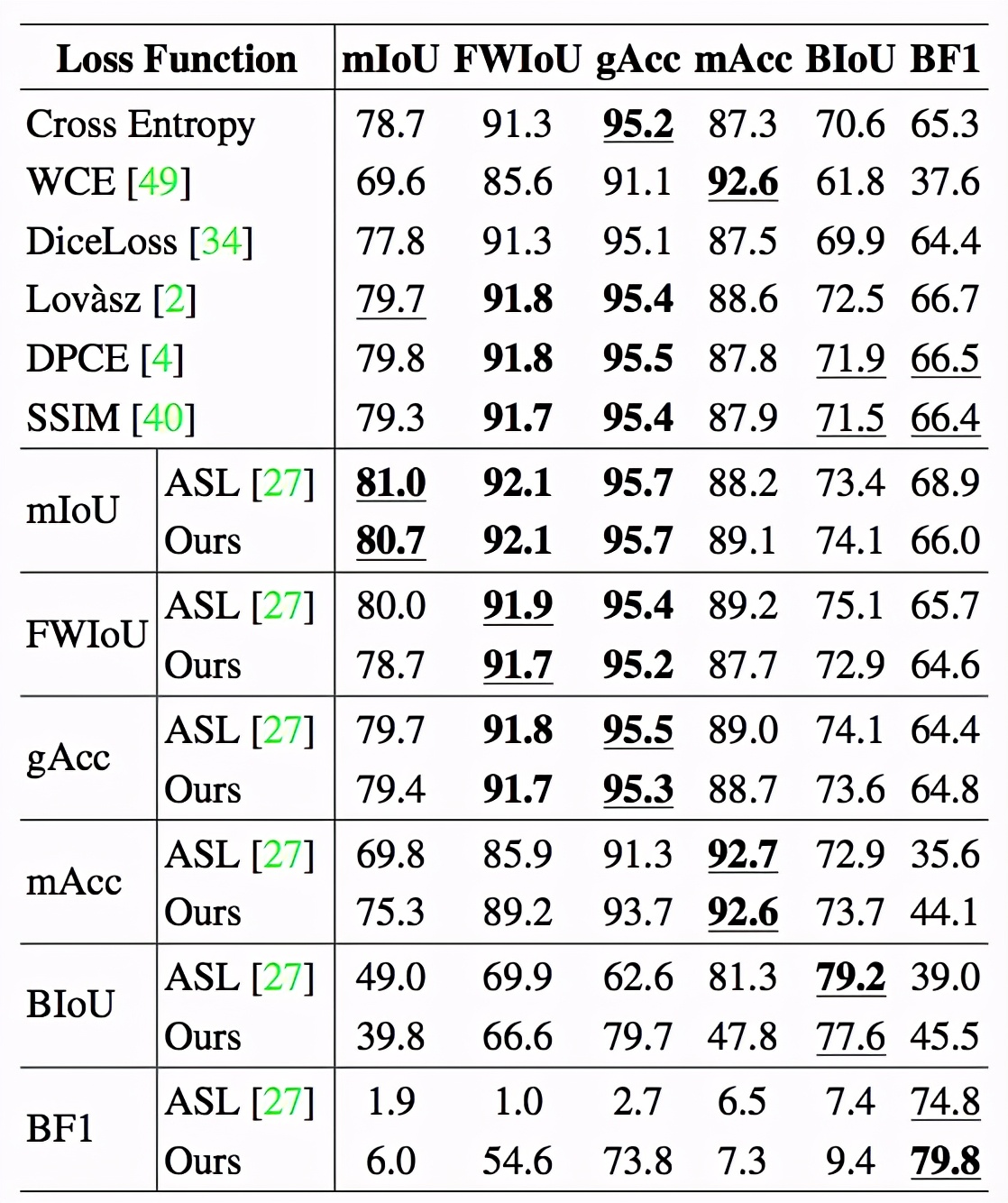
表2. 語義分割實驗結果
該研究還對搜索得到的損失函數的在不同數據集和不同網絡結構上的泛化性進行了驗證。表3中,該研究使用ResNet50-DeepLabV3+ 網絡在PASCAL VOC上搜索,并將得到的損失函數應用于不同數據集(Cityscapes)和不同網絡結構(PSPNet)。表3中的結果表明,該方法搜索得到的損失函數具有良好的泛化性。
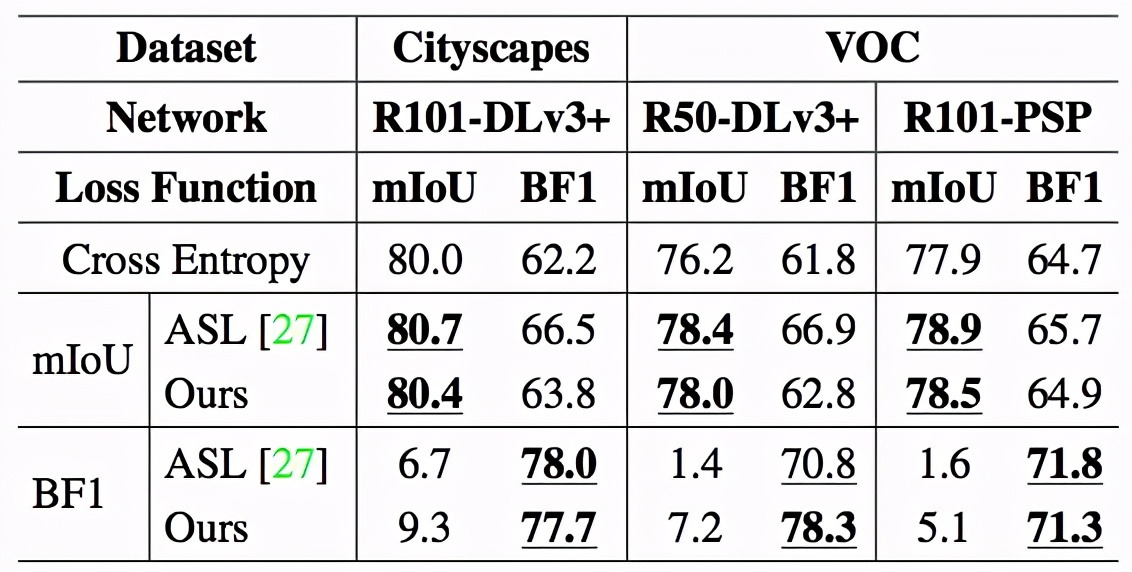
表3. 語義分割泛化性
目標檢測
該研究使用 Faster R-CNN 在 COCO 數據集上進行實驗。對于 Faster R-CNN 中的四個損失函數分支(RPN 網絡的分類、回歸,Fast R-CNN 子網絡的分類、回歸),該方法同時進行搜索。表 4 給出了該方法與常用的 IoULoss、GIoULoss,以及針對目標檢測任務進行損失函數搜索的工作 CSE-AutoLoss-A 進行比較的 結果。實驗表明,該方法搜索到的損失函數與這些損失函數表現相似。
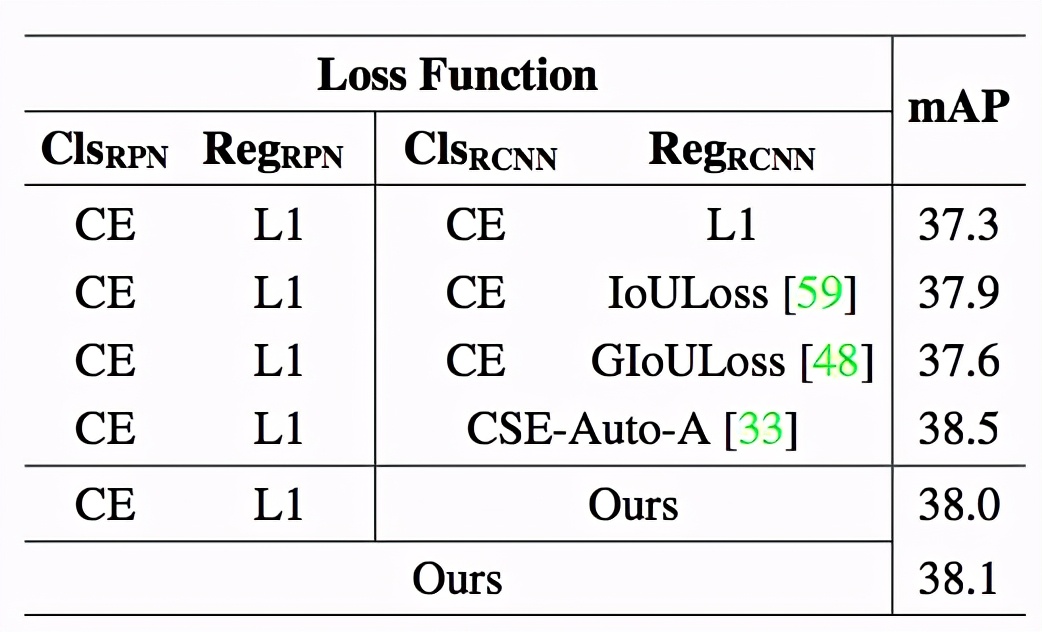
表4. 目標檢測實驗結果
該研究也對目標檢測搜索得到的損失函數的泛化性進行了實驗。表 5 為實驗結果。
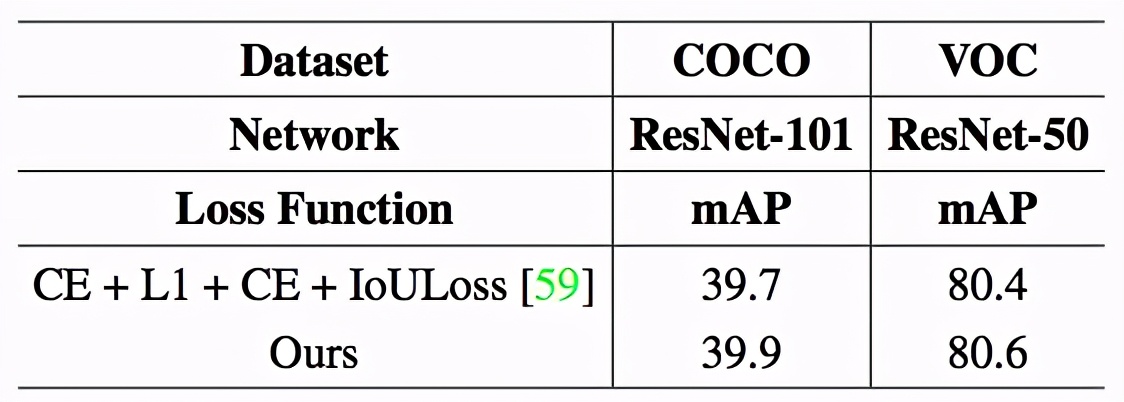
表5. 目標檢測泛化性
實例分割
該研究使用 Mask R-CNN 在 COCO數 據集上進行實驗,并對五個損失函數分支同時進行搜索。表 6 表明該方法搜索到的損失函數與手工設計的損失函數表現相近。

表 6. 實例分割實驗結果
姿態估計
該研究在 COCO 上對姿態估計任務進行了實驗。表 7 為實驗結果。該研究與姿態估計中常用的均方誤差損失(MSE Loss)進行了比較,實驗表明,AutoLoss-Zero 從零開始搜索到的損失函數表現略好于 MSE Loss。
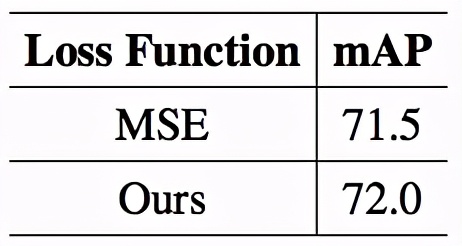
表7. 姿態估計實驗結果
搜索效率
該搜索算法基于進化算法。為了提高搜索效率,研究者設計了損失函數拒絕機制(Loss-Rejection Protocol)和梯度等價性檢測(
Gradient-Equivalence-Check Strategy)。如圖 4 所示,研究者發現這些模塊可以有效地提高搜索的效率。尤其是在目標檢測任務上,由于同時對 4 個分支進行搜索,搜索空間尤為稀疏,這使得在沒有損失函數拒絕機制的情況下,搜索過程無法在合理的時間內(約 400 次代理任務評估)找到任何分數大于 0 的損失函數。這表明高效的拒絕機制是搜索有效的關鍵。
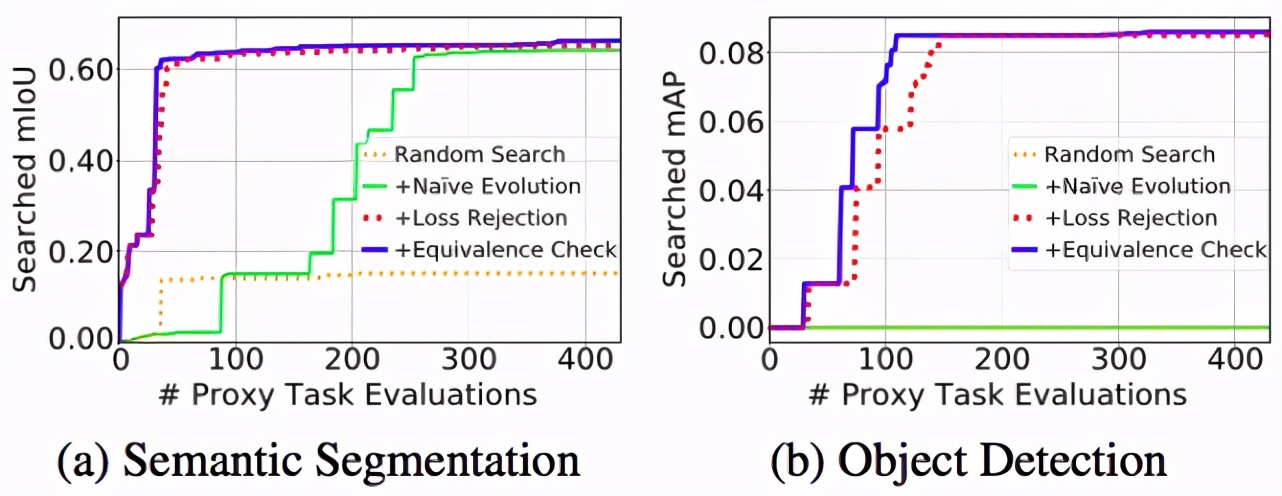
圖4. 搜索效率對比
研究者在表 8 中進一步分析了各個模塊給搜索效率帶來的提升。“滿血”的 AutoLoss-Zero 可以在 48 小時內(使用 4 塊 V100 GPU)探索超過10^6 個候選損失函數,這使得它可以在龐大而稀疏的搜索空間內有效地探索。
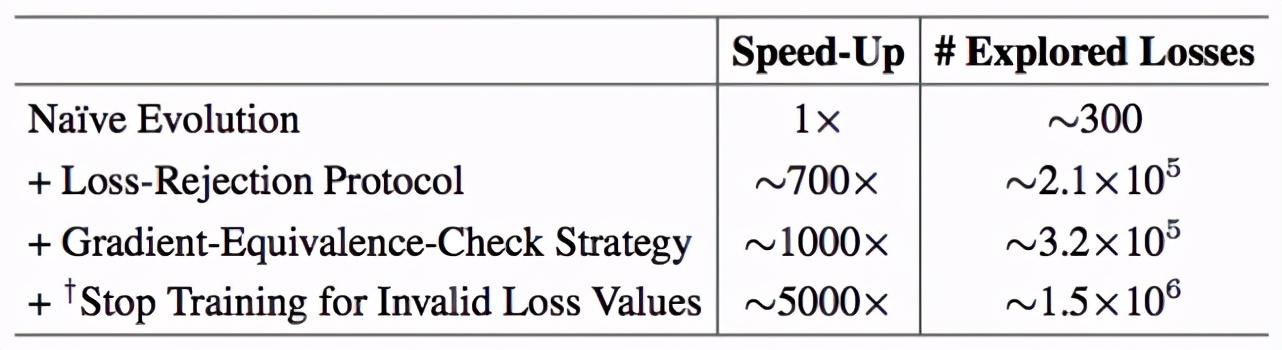
表8. 目標檢測任務的搜索效率分析。(“# Explored Losses”表示算法在48小時內探索的損失函數數量。“Stop Training for Invalid Loss Values”表示網絡在代理任務的前20輪更新內即由于出現NaN或Inf而停止了訓練。)