機器學習5種特征選擇的方法!
我們知道模型的性能會隨著使用特征數量的增加而增加。但是,當超過峰值時,模型性能將會下降。這就是為什么我們只需要選擇能夠有效預測的特征的原因。
特征選擇類似于降維技術,其目的是減少特征的數量,但是從根本上說,它們是不同的。區別在于要素選擇會選擇要保留或從數據集中刪除的要素,而降維會創建數據的投影,從而產生全新的輸入要素。
特征選擇有很多方法,在本文中我將介紹 Scikit-Learn 中 5 個方法,因為它們是最簡單但卻非常有用的,讓我們開始吧。
1、方差閾值特征選擇
具有較高方差的特征表示該特征內的值變化大,較低的方差意味著要素內的值相似,而零方差意味著您具有相同值的要素。
方差選擇法,先要計算各個特征的方差,然后根據閾值,選擇方差大于閾值的特征,使用方法我們舉例說明:
- import pandas as pd
- import seaborn as sns
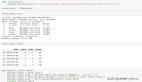
- mpg = sns.load_dataset('mpg').select_dtypes('number')
- mpg.head()
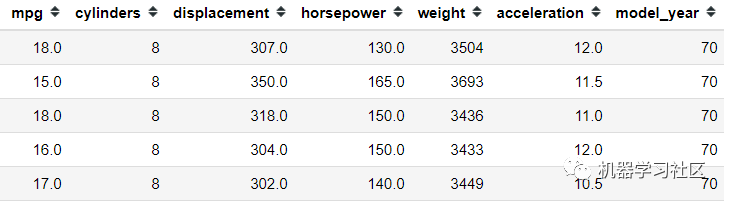
對于此示例,我僅出于簡化目的使用數字特征。在使用方差閾值特征選擇之前,我們需要對所有這些數字特征進行轉換,因為方差受數字刻度的影響。
- from sklearn.preprocessing import StandardScaler
- scaler = StandardScaler()
- mpg = pd.DataFrame(scaler.fit_transform(mpg), columns = mpg.columns)
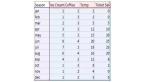
- mpg.head()
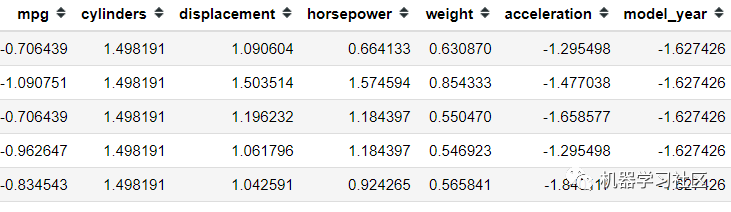
所有特征都在同一比例上,讓我們嘗試僅使用方差閾值方法選擇我們想要的特征。假設我的方差限制為一個方差。
- from sklearn.feature_selection import VarianceThreshold
- selector = VarianceThreshold(1)
- selector.fit(mpg)
- mpg.columns[selector.get_support()]
方差閾值是一種無監督學習的特征選擇方法。如果我們希望出于監督學習的目的而選擇功能怎么辦?那就是我們接下來要討論的。
2、SelectKBest特征特征
單變量特征選擇是一種基于單變量統計檢驗的方法,例如:chi2,Pearson等等。
SelectKBest 的前提是將未經驗證的統計測試與基于 X 和 y 之間的統計結果選擇 K 數的特征相結合。
- mpg = sns.load_dataset('mpg')
- mpg = mpg.select_dtypes('number').dropna()
- #Divide the features into Independent and Dependent Variable
- X = mpg.drop('mpg' , axis =1)
- y = mpg['mpg']
由于單變量特征選擇方法旨在進行監督學習,因此我們將特征分為獨立變量和因變量。接下來,我們將使用SelectKBest,假設我只想要最重要的兩個特征。
- from sklearn.feature_selection import SelectKBest, mutual_info_regression
- #Select top 2 features based on mutual info regression
- selector = SelectKBest(mutual_info_regression, k =2)
- selector.fit(X, y)
- X.columns[selector.get_support()]
3、遞歸特征消除(RFE)
遞歸特征消除或RFE是一種特征選擇方法,利用機器學習模型通過在遞歸訓練后消除最不重要的特征來選擇特征。
根據Scikit-Learn,RFE是一種通過遞歸考慮越來越少的特征集來選擇特征的方法。
- 首先對估計器進行初始特征集訓練,然后通過coef_attribute或feature_importances_attribute獲得每個特征的重要性。
- 然后從當前特征中刪除最不重要的特征。在修剪后的數據集上遞歸地重復該過程,直到最終達到所需的要選擇的特征數量。
在此示例中,我想使用泰坦尼克號數據集進行分類問題,在那里我想預測誰將生存下來。
- #Load the dataset and only selecting the numerical features for example purposes
- titanic = sns.load_dataset('titanic')[['survived', 'pclass', 'age', 'parch', 'sibsp', 'fare']].dropna()
- X = titanic.drop('survived', axis = 1)
- y = titanic['survived']
我想看看哪些特征最能幫助我預測誰可以幸免于泰坦尼克號事件。讓我們使用LogisticRegression模型獲得最佳特征。
- from sklearn.feature_selection import RFE
- from sklearn.linear_model import LogisticRegression
- # #Selecting the Best important features according to Logistic Regression
- rfe_selector = RFE(estimator=LogisticRegression(),n_features_to_select = 2, step = 1)
- rfe_selector.fit(X, y)
- X.columns[rfe_selector.get_support()]
默認情況下,為RFE選擇的特征數是全部特征的中位數,步長是1.當然,你可以根據自己的經驗進行更改。
4、SelectFromModel 特征選擇
Scikit-Learn 的 SelectFromModel 用于選擇特征的機器學習模型估計,它基于重要性屬性閾值。默認情況下,閾值是平均值。
讓我們使用一個數據集示例來更好地理解這一概念。我將使用之前的數據。
- from sklearn.feature_selection import SelectFromModel
- sfm_selector = SelectFromModel(estimator=LogisticRegression())
- sfm_selector.fit(X, y)
- X.columns[sfm_selector.get_support()]
與RFE一樣,你可以使用任何機器學習模型來選擇功能,只要可以調用它來估計特征重要性即可。你可以使用隨機森林模或XGBoost進行嘗試。
5、順序特征選擇(SFS)
順序特征選擇是一種貪婪算法,用于根據交叉驗證得分和估計量來向前或向后查找最佳特征,它是 Scikit-Learn 版本0.24中的新增功能。方法如下:
- SFS-Forward 通過從零個特征開始進行功能選擇,并找到了一個針對單個特征訓練機器學習模型時可以最大化交叉驗證得分的特征。
- 一旦選擇了第一個功能,便會通過向所選功能添加新功能來重復該過程。當我們發現達到所需數量的功能時,該過程將停止。
讓我們舉一個例子說明。
- from sklearn.feature_selection import SequentialFeatureSelector
- sfs_selector = SequentialFeatureSelector(estimator=LogisticRegression(), n_features_to_select = 3, cv =10, direction ='backward')
- sfs_selector.fit(X, y)
- X.columns[sfs_selector.get_support()]
結論
特征選擇是機器學習模型中的一個重要方面,對于模型無用的特征,不僅影響模型的訓練速度,同時也會影響模型的效果。