













MySQL不香嗎,為啥還要Elasticsearch?
近年來公司業(yè)務(wù)迅猛發(fā)展,數(shù)據(jù)量爆炸式增長(zhǎng),隨之而來的的是海量數(shù)據(jù)查詢等帶來的挑戰(zhàn),我們需要數(shù)據(jù)量在十億,甚至百億級(jí)別的規(guī)模時(shí)依然能以秒級(jí)甚至毫秒級(jí)的速度返回。
這樣的話顯然離不開搜索引擎的幫助,在搜索引擎中,ES(ElasticSearch)毫無疑問是其中的佼佼者,連續(xù)多年在 DBRanking 的搜索引擎中評(píng)測(cè)中排名第一,也是絕大多數(shù)大公司的首選。
圖片來自 Pexels
那么它與傳統(tǒng)的 DB 如 MySQL 相比有啥優(yōu)勢(shì)呢,ES 的數(shù)據(jù)又是如何生成的,數(shù)據(jù)達(dá)到 PB 時(shí)又是如何保證 ES 索引數(shù)據(jù)的實(shí)時(shí)性以更好地滿足業(yè)務(wù)的需求的呢。
本文會(huì)結(jié)合我司在 ES 上的實(shí)踐經(jīng)驗(yàn)與大家談?wù)勅绾螛?gòu)建準(zhǔn)實(shí)時(shí)索引的一些思路,希望對(duì)大家有所啟發(fā)。
本文目錄如下:
- 為什么要用搜索引擎,MySQL 不香嗎
- ES 索引數(shù)據(jù)構(gòu)建
- PB 級(jí)的 ES 準(zhǔn)實(shí)時(shí)索引數(shù)據(jù)構(gòu)建之道
為什么要用搜索引擎,MySQL 不香嗎
MySQL 的不足
MySQL 架構(gòu)天生不適合海量數(shù)據(jù)查詢,它只適合海量數(shù)據(jù)存儲(chǔ),但無法應(yīng)對(duì)海量數(shù)據(jù)下各種復(fù)雜條件的查詢。
有人說加索引不是可以避免全表掃描,提升查詢速度嗎,為啥說它不適合海量數(shù)據(jù)查詢呢?
有兩個(gè)原因:
①加索引確實(shí)可以提升查詢速度,但在 MySQL 中加多個(gè)索引最終在執(zhí)行 SQL 的時(shí)候它只會(huì)選擇成本最低的那個(gè)索引如。
果沒有索引滿足搜索條件,就會(huì)觸發(fā)全表掃描,而且即便你使用了組合索引,也要符合最左前綴原則才能命中索引。
但在海量數(shù)據(jù)多種查詢條件下很有可能不符合最左前綴原則而導(dǎo)致索引失效,而且我們知道存儲(chǔ)都是需要成本的。
如果你針對(duì)每一種情況都加索引,以 innoDB 為例,每加一個(gè)索引,就會(huì)創(chuàng)建一顆 B+ 樹。
如果是海量數(shù)據(jù),將會(huì)增加很大的存儲(chǔ)成本,之前就有人反饋說他們公司的某個(gè)表實(shí)際內(nèi)容的大小才 10G, 而索引大小卻有 30G!這是多么巨大的成本!所以千萬不要覺得索引建得越多越好。
②有些查詢條件是 MySQL 加索引都解決不了的,比如我要查詢商品中所有 title 帶有「格力空調(diào)」的關(guān)鍵詞,如果你用 MySQL 寫,會(huì)寫出如下代碼:
- SELECT * FROM product WHERE title like '%格力空調(diào)%'
這樣的話無法命中任何索引,會(huì)觸發(fā)全表掃描,而且你不能指望所有人都能輸對(duì)他想要的商品,是人就會(huì)犯錯(cuò)誤,我們經(jīng)常會(huì)犯類似把「格力空調(diào)」記成「格空間」的錯(cuò)誤。
那么 SQL 語句就會(huì)變成:
- SELECT * FROM product WHERE title like '%格空調(diào)%'
這種情況下就算你觸發(fā)了全表掃描也無法查詢到任何商品,綜上所述,MySQL 的查詢確實(shí)能力有限。
ES 簡(jiǎn)介
與其說上面列的這些點(diǎn)是 MySQL 的不足,倒不如說 MySQL 本身就不是為海量數(shù)據(jù)查詢而設(shè)計(jì)的。
術(shù)業(yè)有專攻,海量數(shù)據(jù)查詢還得用專門的搜索引擎,這其中 ES 是其中當(dāng)之無愧的王者。
它是基于 Lucene 引擎構(gòu)建的開源分布式搜索分析引擎,可以提供針對(duì) PB 數(shù)據(jù)的近實(shí)時(shí)查詢,廣泛用在全文檢索、日志分析、監(jiān)控分析等場(chǎng)景。
它主要有以下三個(gè)特點(diǎn):
- 輕松支持各種復(fù)雜的查詢條件:它是分布式實(shí)時(shí)文件存儲(chǔ),會(huì)把每一個(gè)字段都編入索引(倒排索引),利用高效的倒排索引,以及自定義打分、排序能力與豐富的分詞插件等,能實(shí)現(xiàn)任意復(fù)雜查詢條件下的全文檢索需求。
- 可擴(kuò)展性強(qiáng):天然支持分布式存儲(chǔ),通過極其簡(jiǎn)單的配置實(shí)現(xiàn)幾百上千臺(tái)服務(wù)器的分布式橫向擴(kuò)容,輕松處理 PB 級(jí)別的結(jié)構(gòu)化或非結(jié)構(gòu)化數(shù)據(jù)。
- 高可用,容災(zāi)性能好:通過使用主備節(jié)點(diǎn),以及故障的自動(dòng)探測(cè)與恢復(fù),有力地保障了高可用。
我們先用與 MySQL 類比的形式來理解 ES 的一些重要概念:

通過類比的形式不難看出 ES 的以下幾個(gè)概念:
- MySQL 的數(shù)據(jù)庫(kù)(DataBase)相當(dāng)于 Index(索引),數(shù)據(jù)的邏輯集合,ES 的工作主要也是創(chuàng)建索引,查詢索引。
- 一個(gè)數(shù)據(jù)庫(kù)里會(huì)有多個(gè)表,同樣的一個(gè) Index 也會(huì)有多個(gè) type。
- 一個(gè)表會(huì)有多行(Row),同樣的一個(gè) Type 也會(huì)有多個(gè) Document。
- Schema 指定表名,表字段,是否建立索引等,同樣的 Mapping 也指定了 Type 字段的處理規(guī)則,即索引如何建立,是否分詞,分詞規(guī)則等。
- 在 MySQL 中索引是需要手動(dòng)創(chuàng)建的,而在 ES 一切字段皆可被索引,只要在 Mapping 在指定即可。
那么 ES 中的索引為何如此高效,能在海量數(shù)據(jù)下達(dá)到秒級(jí)的效果呢?
它采用了多種優(yōu)化手段,最主要的原因是它采用了一種叫做倒排索引的方式來生成索引,避免了全文檔掃描。
那么什么是倒排索引呢,通過文檔來查找關(guān)鍵詞等數(shù)據(jù)的我們稱為正排索引,返之,通過關(guān)鍵詞來查找文檔的形式我們稱之為倒排索引。
假設(shè)有以下三個(gè)文檔(Document):
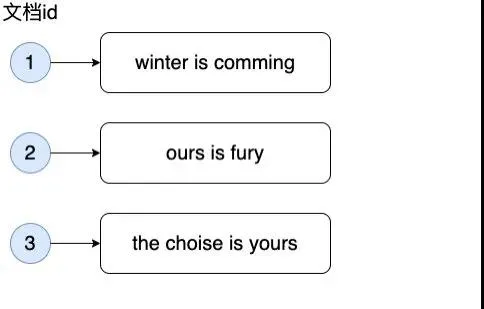
要在其中找到含有 comming 的文檔,如果要正排索引,那么要把每個(gè)文檔的內(nèi)容拿出來查找是否有此單詞,毫無疑問這樣的話會(huì)導(dǎo)致全表掃描,那么用倒排索引會(huì)怎么查找呢?
它首先會(huì)將每個(gè)文檔內(nèi)容進(jìn)行分詞,小寫化等,然后建立每個(gè)分詞與包含有此分詞的文檔之前的映射關(guān)系。
如果有多個(gè)文檔包含此分詞,那么就會(huì)按重要程度即文檔的權(quán)重(通常是用 TF-IDF 給文檔打分)將文檔進(jìn)行排序。
于是我們可以得到如下關(guān)系:
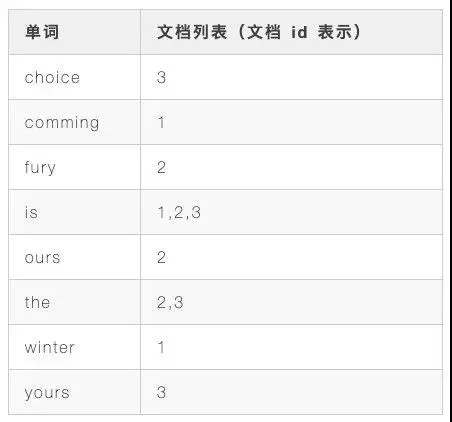
這樣的話我們我要查找所有帶有 comming 的文檔,就只需查一次,而且這種情況下查詢多個(gè)單詞性能也是很好的,只要查詢多個(gè)條件對(duì)應(yīng)的文檔列表,再取交集即可,極大地提升了查詢效率。
畫外音:這里簡(jiǎn)化了一些流程,實(shí)際上還要先根據(jù)單詞表來定位單詞等,不過這些流程都很快,可以忽略,有興趣的讀者可以查閱相關(guān)資料了解。
除了倒排索引外,ES 的分布式架構(gòu)也天然適合海量數(shù)據(jù)查詢,來看下 ES 的架構(gòu):
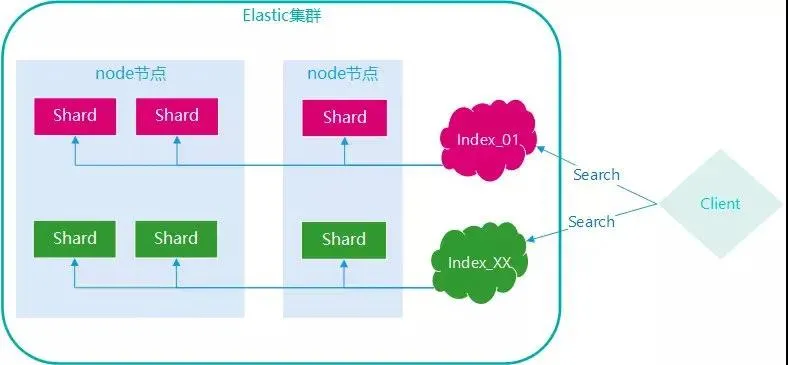
一個(gè) ES 集群由多個(gè) node 節(jié)點(diǎn)組成,每個(gè) index 是以分片(Shard,index 子集)的數(shù)據(jù)存在于多個(gè) node 節(jié)點(diǎn)上的。
這樣的話當(dāng)一個(gè)查詢請(qǐng)求進(jìn)來,分別在各個(gè) node 查詢相應(yīng)的結(jié)果并整合后即可,將查詢壓力分散到多個(gè)節(jié)點(diǎn),避免了單個(gè)節(jié)點(diǎn) CPU,磁盤,內(nèi)存等處理能力的不足。
另外當(dāng)新節(jié)點(diǎn)加入后,會(huì)自動(dòng)遷移部分分片至新節(jié)點(diǎn),實(shí)現(xiàn)負(fù)載均衡,這個(gè)功能是 ES 自動(dòng)完成的,對(duì)比一個(gè)下 MySQL 的分庫(kù)分表需要開發(fā)人員引入 Mycat 等中間件并指定分庫(kù)分表規(guī)則等繁瑣的流程是不是一個(gè)巨大的進(jìn)步?
這也就意味著 ES 有非常強(qiáng)大的水平擴(kuò)展的能力,集群可輕松擴(kuò)展致幾百上千個(gè)節(jié)點(diǎn),輕松支持 PB 級(jí)的數(shù)據(jù)查詢。
當(dāng)然 ES 的強(qiáng)大不止于此,它還采用了比如主備分片提升搜索吞率,使用節(jié)點(diǎn)故障探測(cè),Raft 選主機(jī)制等提升了容災(zāi)能力等等。
這些不是本文重點(diǎn),讀者可自行查閱,總之經(jīng)過上面的簡(jiǎn)單總結(jié)大家只需要明白一點(diǎn):ES 的分布式架構(gòu)設(shè)計(jì)天生支持海量數(shù)據(jù)查詢。
那么 ES 的索引數(shù)據(jù)(index)如何生成的呢,接下來我們一起來看看本文的重點(diǎn)。
如何構(gòu)建 ES 索引
要構(gòu)建 ES 索引數(shù)據(jù),首先得有數(shù)據(jù)源,一般我們會(huì)使用 MySQL 作為數(shù)據(jù)源,你可以直接從 MySQL 中取數(shù)據(jù)然后再寫入 ES,但這種方式由于直接調(diào)用了線上的數(shù)據(jù)庫(kù)查詢,可能會(huì)對(duì)線上業(yè)務(wù)造成影響。
比如考慮這樣的一個(gè)場(chǎng)景:在電商 APP 里用的最多的業(yè)務(wù)場(chǎng)景想必是用戶輸入關(guān)鍵詞來查詢相對(duì)應(yīng)的商品了,那么商品會(huì)有哪些信息呢?
一個(gè)商品會(huì)有多個(gè) sku(sku 即同一個(gè)商品下不同規(guī)格的品類,比如蘋果手機(jī)有 iPhone 6,iPhone 6s 等),會(huì)有其基本屬性如價(jià)格,標(biāo)題等,商品會(huì)有分類(居家,服飾等),品牌,庫(kù)存等。
為了保證表設(shè)計(jì)的合理性,我們會(huì)設(shè)計(jì)幾張表來存儲(chǔ)這些屬性。
假設(shè)有 product_sku(sku 表),product_property(基本屬性表),sku_stock(庫(kù)存表),product_category(分類表)這幾張表。
那么為了在商品展示列表中展示所有這些信息,就必須把這些表進(jìn)行 join,然后再寫入 ES,這樣查詢的時(shí)候就會(huì)在 ES 中獲取所有的商品信息了。
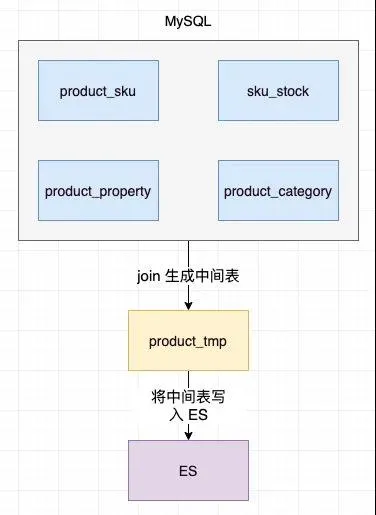
這種方案由于直接在 MySQL 中執(zhí)行 join 操作,在商品達(dá)到千萬級(jí)時(shí)會(huì)對(duì)線上的 DB 服務(wù)產(chǎn)生極大的性能影響,所以顯然不可行,那該怎么生成中間表呢?
既然直接在 MySQL 中操作不可行,能否把 MySQL 中的數(shù)據(jù)同步到另一個(gè)地方再做生成中間表的操作呢?
也就是加一個(gè)中間層進(jìn)行處理,這樣就避免了對(duì)線上 DB 的直接操作,說到這相信大家又會(huì)對(duì)計(jì)算機(jī)界的名言有進(jìn)一步的體會(huì):沒有什么是加一個(gè)中間層不能解決的,如果有,那就再加一層。
這個(gè)中間層就是 Hive。
什么是 Hive
Hive 是基于 Hadoop 的一個(gè)數(shù)據(jù)倉(cāng)庫(kù)工具,用來進(jìn)行數(shù)據(jù)提取、轉(zhuǎn)化、加載,這是一種可以存儲(chǔ)、查詢和分析存儲(chǔ)在 Hadoop 中的大規(guī)模數(shù)據(jù)的機(jī)制。
它的意義就是把好寫的 Hive 的 SQL 轉(zhuǎn)換為復(fù)雜難寫的 map-reduce 程序(map-reduce 是專門用于用于大規(guī)模數(shù)據(jù)集(大于 1TB)的并行運(yùn)算編程模型)。
也就是說如果數(shù)據(jù)量大的話通過把 MySQL 的數(shù)據(jù)同步到 Hive,再由 Hive 來生成上述的 product_tmp 中間表,能極大的提升性能。
Hive 生成臨時(shí)表存儲(chǔ)在 HBase(一個(gè)分布式的、面向列的開源數(shù)據(jù)庫(kù)) 中,生成后會(huì)定時(shí)觸發(fā) dump task 調(diào)用索引程序,然后索引程序主要從 HBase 中讀入全量數(shù)據(jù),進(jìn)行業(yè)務(wù)數(shù)據(jù)處理,并刷新到 ES 索引中。
整個(gè)流程如下:
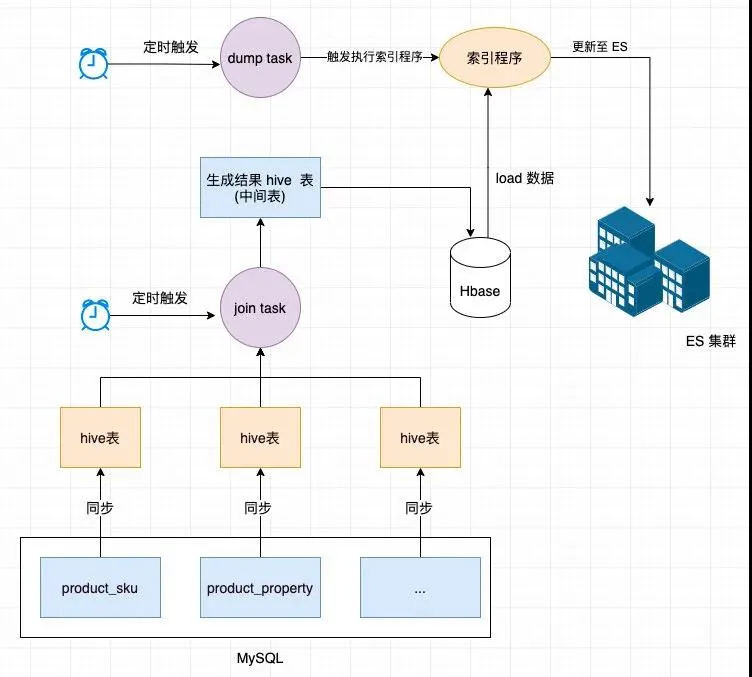
這樣構(gòu)建索引看似很美好,但我們需要知道的是首先 Hive 執(zhí)行 join 任務(wù)是非常耗時(shí)的。
在我們的生產(chǎn)場(chǎng)景上,由于數(shù)據(jù)量高達(dá)幾千萬,執(zhí)行 join 任務(wù)通常需要幾十分鐘,從執(zhí)行 join 任務(wù)到最終更新至 ES 整個(gè)流程常常需要至少半小時(shí)以上。
如果這期間商品的價(jià)格,庫(kù)存,上線狀態(tài)(如被下架)等重要字段發(fā)生了變更,索引是無法更新的,這樣會(huì)對(duì)用戶體驗(yàn)產(chǎn)生極大影響。
優(yōu)化前我們經(jīng)常會(huì)看到通過 ES 搜索出的中有狀態(tài)是上線但實(shí)際是下架的產(chǎn)品,嚴(yán)重影響用戶體驗(yàn),那么怎么解決呢,有一種可行的方案:建立寬表。
既然我們發(fā)現(xiàn) hive join 是性能的主要瓶頸,那么能否規(guī)避掉這個(gè)流程呢,能否在 MySQL 中將 product_sku,product_property,sku_stock 等表組合成一個(gè)大表(我們稱其為寬表)。
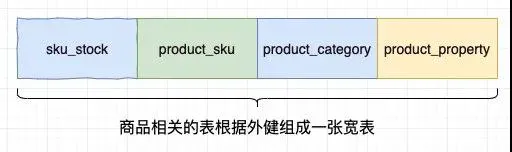
這樣在每一行中商品涉及到的的數(shù)據(jù)都有了,所以將 MySQL 同步到 Hive 后,Hive 就不需要再執(zhí)行耗時(shí)的 join 操作了,極大的提升了整體的處理時(shí)間。
從 Hive 同步 MySQL 再到 dump 到 ES 索引中從原來的半小時(shí)以上降低到了幾分鐘以內(nèi),看起來確實(shí)不錯(cuò),但幾分鐘的索引延遲依然是無法接受的。
為什么 Hive 無法做到實(shí)時(shí)導(dǎo)入索引
因?yàn)?Hive 構(gòu)建在基于靜態(tài)批處理的 Hadoop 之上,Hadoop 通常都有較高的延遲并且在作業(yè)提交和調(diào)度的時(shí)候需要大量的開銷。
因此,Hive 并不能夠在大規(guī)模數(shù)據(jù)集上實(shí)現(xiàn)低延遲快速的查詢等操作,再且千萬級(jí)別的數(shù)據(jù)全量從索引程序?qū)氲?ES 集群至少也是分鐘級(jí)。
另外引入了寬表,它的維護(hù)也成了一個(gè)新問題,設(shè)想 sku 庫(kù)存變了,產(chǎn)品下架了,價(jià)格調(diào)整了。
那么除了修改原表(sku_stock,product_categry 等表)記錄之外,還要將所有原表變更到的記錄對(duì)應(yīng)到寬表中的所有記錄也都更新一遍。
這對(duì)代碼的維護(hù)是個(gè)噩夢(mèng),因?yàn)槟阈枰谒猩唐废嚓P(guān)的表變更的地方緊接著著變更寬表的邏輯,與寬表的變更邏輯變更緊藕合!
PB 級(jí)的 ES 準(zhǔn)實(shí)時(shí)索引構(gòu)建之道
該如何解決呢?仔細(xì)觀察上面兩個(gè)問題,其實(shí)都是同一個(gè)問題,如果我們能實(shí)時(shí)監(jiān)聽到 DB 的字段變更,再將變更的內(nèi)容實(shí)時(shí)同步到 ES 和寬表中不就解決了我們的問題了。
怎么才能實(shí)時(shí)監(jiān)聽到表字段的變更呢?答案:Binlog。
Binlog
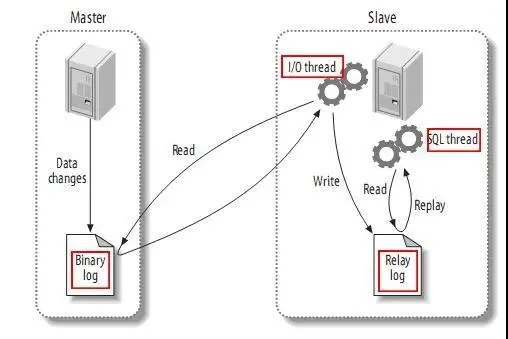
來一起復(fù)習(xí)下 MySQL 的主從同步原理:
- MySQL master 將數(shù)據(jù)變更寫入二進(jìn)制日志(binary log,其中記錄叫做二進(jìn)制日志事件 binary log events,可以通過 show binlog events 進(jìn)行查看)。
- MySQL slave 將 master 的 binary log events 拷貝到它的中繼日志(relay log)。
- MySQL slave 重放 relay log 中事件,將數(shù)據(jù)變更反映它自己的數(shù)據(jù)。
可以看到主從復(fù)制的原理關(guān)鍵是 Master 和 Slave 遵循了一套協(xié)議才能實(shí)時(shí)監(jiān)聽 binlog 日志來更新 slave 的表數(shù)據(jù)。
那我們能不能也開發(fā)一個(gè)遵循這套協(xié)議的組件,當(dāng)組件作為 Slave 來獲取 binlog 日志進(jìn)而實(shí)時(shí)監(jiān)聽表字段變更呢?
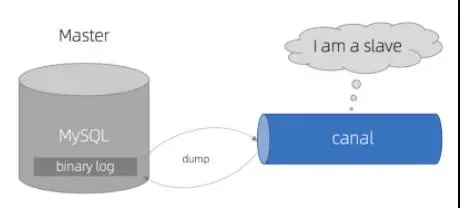
阿里的開源項(xiàng)目 Canal 就是這個(gè)干的,它的工作原理如下:
- Canal 模擬 MySQL slave 的交互協(xié)議,偽裝自己為 MySQL slave,向 MySQL master 發(fā)送 dump 協(xié)議。
- MySQL master 收到 dump 請(qǐng)求,開始推送 binary log 給 slave(即 Canal)。
- Canal 解析 binary log 對(duì)象(原始為 byte 流)。
這樣的話通過 Canal 就能獲取 binlog 日志了,當(dāng)然 Canal 只是獲取接收了 master 過來的 binlog,還要對(duì) binlog 進(jìn)行解析過濾處理等。
另外如果我們只對(duì)某些表的字段感興趣,該如何配置,獲取到 binlog 后要傳給誰? 這些都需要一個(gè)統(tǒng)一的管理組件,阿里的 Otter 就是干這件事的。
什么是 Otter
Otter 是由阿里提供的基于數(shù)據(jù)庫(kù)增量日志解析,準(zhǔn)實(shí)時(shí)同步到本機(jī)房或異地機(jī)房 MySQL 數(shù)據(jù)庫(kù)的一個(gè)分布式數(shù)據(jù)庫(kù)同步系統(tǒng)。
它的整體架構(gòu)如下:
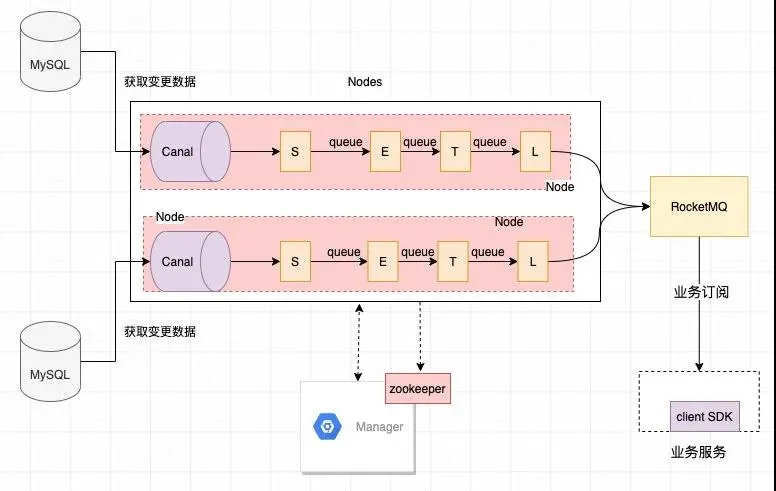
注:以上是我司根據(jù) Otter 改造后的業(yè)務(wù)架構(gòu),與原版 Otter 稍有不同,不過大同小異。
主要工作流程如下:
- 在 Manager 配置好 ZK,要監(jiān)聽的表 ,負(fù)責(zé)監(jiān)聽表的節(jié)點(diǎn),然后將配置同步到 Nodes 中。
- node 啟動(dòng)后則其 canal 會(huì)監(jiān)聽 binlog,然后經(jīng)過 S(select),E(extract),T(transform),L(load)四個(gè)階段后數(shù)據(jù)發(fā)送到 MQ。
- 然后業(yè)務(wù)就可以訂閱 MQ 消息來做相關(guān)的邏輯處理了
畫外音:Zookeeper 主要協(xié)調(diào)節(jié)點(diǎn)間的工作,如在跨機(jī)房數(shù)據(jù)同步時(shí),可能要從 A 機(jī)房的節(jié)點(diǎn)將數(shù)據(jù)同步到 B 機(jī)房的節(jié)點(diǎn),要用 Zookeeper 來協(xié)調(diào)。
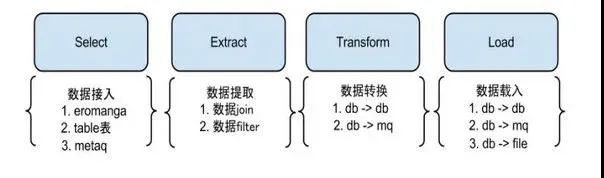
大家應(yīng)該注意到了 node 中有 S,E,T,L 四個(gè)階段,它們的主要作用如下:
- Select 階段:為解決數(shù)據(jù)來源的差異性,比如接入 canal 獲取增量數(shù)據(jù),也可以接入其他系統(tǒng)獲取其他數(shù)據(jù)等。
- Extract階段:組裝數(shù)據(jù),針對(duì)多種數(shù)據(jù)來源,mysql,oracle,store,file 等,進(jìn)行數(shù)據(jù)組裝和過濾。
- Transform 階段:數(shù)據(jù)提取轉(zhuǎn)換過程,把數(shù)據(jù)轉(zhuǎn)換成目標(biāo)數(shù)據(jù)源要求的類型。
- Load 階段:數(shù)據(jù)載入,把數(shù)據(jù)載入到目標(biāo)端,如寫入遷移后的數(shù)據(jù)庫(kù), MQ,ES 等。
以上這套基于阿里 Otter 改造后的數(shù)據(jù)服務(wù)我們將它稱為 DTS(Data Transfer Service),即數(shù)據(jù)傳輸服務(wù)。
搭建這套服務(wù)后我們就可以通過訂閱 MQ 來實(shí)時(shí)寫入 ES 讓索引實(shí)時(shí)更新了,而且也可以通過訂閱 MQ 來實(shí)現(xiàn)寬表字段的更新。
解決了上文中所說的寬表字段更新與原表緊藕合的問題,基于 DTS 服務(wù)的索引改進(jìn)架構(gòu)如下:
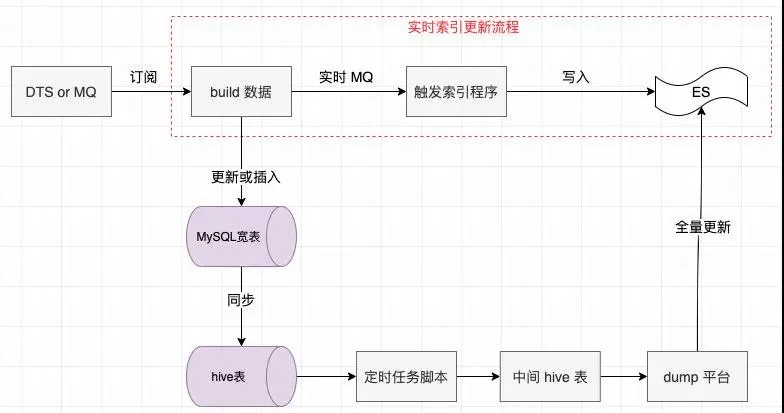
注意:「build 數(shù)據(jù)」這一模塊對(duì)實(shí)時(shí)索引更新是透明的,這個(gè)模塊主要用在更新或插入 MySQL 寬表。
因?yàn)閷?duì)于寬表來說,它是幾個(gè)表數(shù)據(jù)的并集,所以并不是監(jiān)聽到哪個(gè)字段變更就更新哪個(gè),它要把所有商品涉及到的所有表數(shù)據(jù)拉回來再更新到寬表中。
于是,通過 MySQL 寬表全量更新+基于 DTS 的實(shí)時(shí)索引更新我們很好地解決了索引延遲的問題,能達(dá)到秒級(jí)的 ES 索引更新!
這里有幾個(gè)問題可能大家比較關(guān)心,我簡(jiǎn)單列一下:
①需要訂閱哪些字段?
對(duì)于 MySQL 寬表來說由于它要保存商品的完整信息,所以它需要訂閱所有字段,但是對(duì)于紅框中的實(shí)時(shí)索引更新而言,它只需要訂閱庫(kù)存,價(jià)格等字段。
因?yàn)檫@些字段如果不及時(shí)更新,會(huì)對(duì)銷量產(chǎn)生極大的影響,所以我們實(shí)時(shí)索引只關(guān)注這些敏感字段即可。
②有了實(shí)時(shí)索引更新,還需要全量索引更新嗎?
需要,主要有兩個(gè)原因:
- 實(shí)時(shí)更新依賴消息機(jī)制,無法百分百保證數(shù)據(jù)完整性,需要全量更新來支持,這種情況很少,而且消息積壓等會(huì)有告警,所以我們一天只會(huì)執(zhí)行一次全量索引更新。
- 索引集群異常或崩潰后能快速重建索引。
③全量索引更新的數(shù)據(jù)會(huì)覆蓋實(shí)時(shí)索引嗎?
會(huì),設(shè)想這樣一種場(chǎng)景,你在某一時(shí)刻觸發(fā)了實(shí)時(shí)索引,然后此時(shí)全量索引還在執(zhí)行中,還未執(zhí)行到實(shí)時(shí)索引更新的那條記錄,這樣在的話當(dāng)全量索引執(zhí)行完之后就會(huì)把之前實(shí)時(shí)索引更新的數(shù)據(jù)給覆蓋掉。
針對(duì)這種情況一種可行的處理方式是如果全量索引是在構(gòu)建中,實(shí)時(shí)索引更新消息可以延遲處理,等全量更新結(jié)束后再消費(fèi)。
也正因?yàn)檫@個(gè)原因,全量索引我們一般會(huì)在凌晨執(zhí)行,由于是業(yè)務(wù)低峰期,最大可能規(guī)避了此類問題。
總結(jié)
本文簡(jiǎn)單總結(jié)了我司在 PB 級(jí)數(shù)據(jù)下構(gòu)建實(shí)時(shí) ES 索引的一些思路,希望對(duì)大家有所幫助。
文章只是簡(jiǎn)單提到了 ES,Canal,Otter 等阿里中間件的應(yīng)用,但未對(duì)這些中間件的詳細(xì)配置,原理等未作過多介紹。
這些中間件的設(shè)計(jì)非常值得我們好好研究下,比如 ES 為了提高搜索效率、優(yōu)化存儲(chǔ)空間做了很多工作。
再比如 Canal 如何做高可用,Otter 實(shí)現(xiàn)異地跨機(jī)房同步的原理等,建議感興趣的讀者可以之后好好研究一番,相信你會(huì)受益匪淺。
作者:空無
編輯:陶家龍
征稿:有投稿、尋求報(bào)道意向技術(shù)人請(qǐng)?zhí)砑有【幬⑿?gordonlonglong
















