開發 | 再見了,公司的“爛系統”
圖片來自 Pexels
為什么要拆分?
先看一段對話:

從上面對話可以看出拆分的理由:
- 應用間耦合嚴重。系統內各個應用之間不通,同樣一個功能在各個應用中都有實現,后果就是改一處功能,需要同時改系統中的所有應用。
- 這種情況多存在于歷史較長的系統,因各種原因,系統內的各個應用都形成了自己的業務小閉環。
- 業務擴展性差。數據模型從設計之初就只支持某一類的業務,來了新類型的業務后又得重新寫代碼實現,結果就是項目延期,大大影響業務的接入速度。
- 代碼老舊,難以維護。各種隨意的 if else、寫死邏輯散落在應用的各個角落,處處是坑,開發維護起來戰戰兢兢。
- 系統擴展性差。系統支撐現有業務已是顫顫巍巍,不論是應用還是DB都已經無法承受業務快速發展帶來的壓力。
- 新坑越挖越多,惡性循環。不改變的話,最終的結果就是把系統做死了。
拆前準備什么?
多維度把握業務復雜度
一個老生常談的問題,系統與業務的關系?
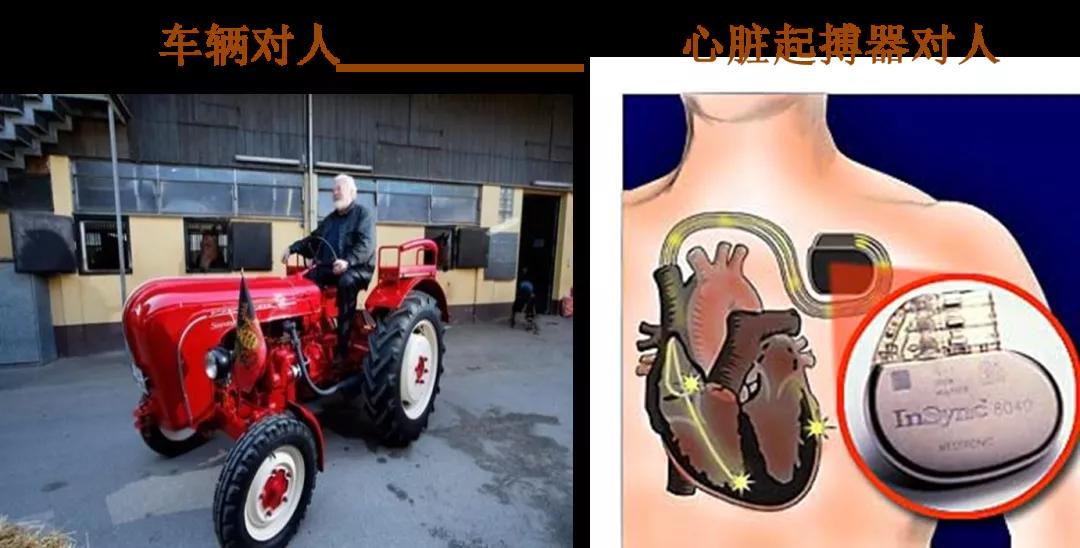
我們最期望的理想情況是第一種關系(車輛與人),業務覺得不合適,可以馬上換一輛新的。
但現實的情況是更像心臟起搏器與人之間的關系,不是說換就能換。一個系統接的業務越多,耦合越緊密。
如果在沒有真正把握住業務復雜度之前貿然行動,最終的結局就是把心臟帶飛。
如何把握住業務復雜度?需要多維度的思考、實踐。
一個是技術層面,通過與 PD 以及開發的討論,熟悉現有各個應用的領域模型,以及優缺點,這種討論只能讓人有個大概,更多的細節如代碼、架構等需要通過做需求、改造、優化這些實踐來掌握。
各個應用熟悉之后,需要從系統層面來構思,我們想打造平臺型的產品,那么最重要也是最難的一點就是功能集中管控,打破各個應用的業務小閉環,統一收攏。
這個決心更多的是開發、產品、業務方、各個團隊之間達成的共識,“按照業務或者客戶需求組織資源”。
此外也要與業務方保持功能溝通、計劃溝通,確保應用拆分出來后符合使用需求、擴展需求,獲取他們的支持。
定義邊界,原則:高內聚,低耦合,單一職責
業務復雜度把握后,需要開始定義各個應用的服務邊界。怎么才算是好的邊界?像葫蘆娃兄弟一樣的應用就是好的!
舉個例子,葫蘆娃兄弟(應用)間的技能是相互獨立的,遵循單一職責原則,比如水娃只能噴水,火娃只會噴火,隱形娃不會噴水噴火但能隱身。
更為關鍵的是,葫蘆娃兄弟最終可以合體為金剛葫蘆娃,即這些應用雖然功能彼此獨立,但又相互打通,最后合體在一起就成了我們的平臺。
這里很多人會有疑惑,拆分粒度怎么控制?很難有一個明確的結論,只能說是結合業務場景、目標、進度的一個折中。
但總體的原則是先從一個大的服務邊界開始,不要太細,因為隨著架構、業務的演進,應用自然而然會再次拆分,讓正確的事情自然發生才最合理。
確定拆分后的應用目標
一旦系統的宏觀應用拆分圖出來后,就要落實到某一具體的應用拆分上了。
首先要確定的就是某一應用拆分后的目標。拆分優化是沒有底的,可能越做越深,越做越沒結果,繼而又影響自己和團隊的士氣。
比如說可以定這期的目標就是將 DB、應用分拆出去,數據模型的重新設計可以在第二期。
確定當前要拆分應用的架構狀態
例如,代碼情況、依賴狀況,并推演可能的各種異常。
動手前的思考成本遠遠低于動手后遇到問題的解決成本。應用拆分最怕的是中途說“他*的,這塊不能動,原來當時這樣設計是有原因的,得想別的路子!”
這時的壓力可想而知,整個節奏不符合預期后,很可能會接二連三遇到同樣的問題,這時不僅同事們士氣下降,自己也會喪失信心,繼而可能導致拆分失敗。
給自己留個錦囊,“有備無患”
錦囊就四個字“有備無患”,可以貼在桌面或者手機上。
在以后具體實施過程中,多思考下“方案是否有多種可以選擇?復雜問題能否拆解?實際操作時是否有預案?”,應用拆分在具體實踐過程中比拼得就是細致二字,多一份方案,多一份預案,不僅能提升成功概率,更給自己信心。
放松心情,緩解壓力
收拾下心情,開干!
改造實踐
DB 拆分實踐
DB 拆分在整個應用拆分環節里最復雜,分為垂直拆分和水平拆分兩種場景,我們都遇到了。垂直拆分是將庫里的各個表拆分到合適的數據庫中。
比如一個庫中既有消息表,又有人員組織結構表,那么將這兩個表拆分到獨立的數據庫中更合適。
水平拆分:以消息表為例好了,單表突破了千萬行記錄,查詢效率較低,這時候就要將其分庫分表。
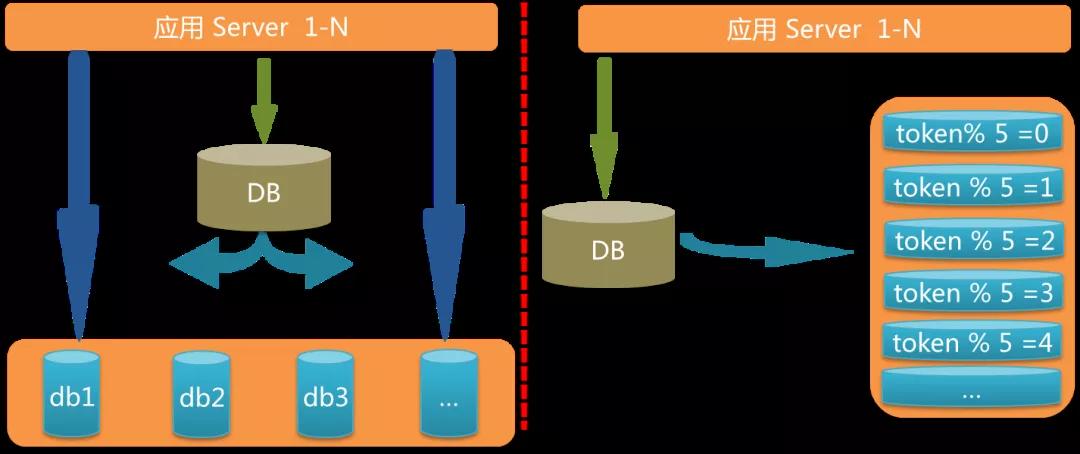
①主鍵 id 接入全局 id 發生器
DB 拆分的第一件事情就是使用全局id發生器來生成各個表的主鍵 id。為什么?
舉個例子,假如我們有一張表,兩個字段 id 和 token,id 是自增主鍵生成,要以 token 維度來分庫分表,這時繼續使用自增主鍵會出現問題。

正向遷移擴容中,通過自增的主鍵,到了新的分庫分表里一定是唯一的,但是,我們要考慮遷移失敗的場景,如下圖所示,新的表里假設已經插入了一條新的記錄,主鍵 id 也是 2。
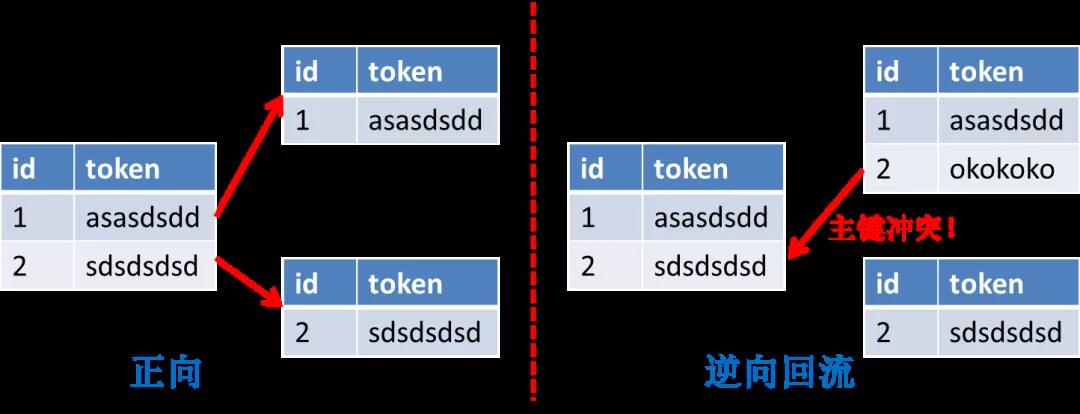
這個時候假設開始回滾,需要將兩張表的數據合并成一張表(逆向回流),就會產生主鍵沖突!
因此在遷移之前,先要用全局唯一 id 發生器生成的 id 來替代主鍵自增 id。
這里有幾種全局唯一 id 生成方法可以選擇:
- Snowflake:非全局遞增。
- MySQL 新建一張表用來專門生成全局唯一 id(利用 auto_increment 功能)(全局遞增)。
- 有人說只有一張表怎么保證高可用?那兩張表好了(在兩個不同 db),一張表產生奇數,一張表產生偶數。或者是 n 張表,每張表的負責的步長區間不同(非全局遞增)
- ……
我們使用的是阿里巴巴內部的 tddl-sequence(MySQL+內存),保證全局唯一但非遞增。
在使用上遇到一些坑:
- 對按主鍵 id 排序的 SQL 要提前改造。因為 id 已經不保證遞增,可能會出現亂序場景,這時候可以改造為按 gmt_create 排序。
- 報主鍵沖突問題。這里往往是代碼改造不徹底或者改錯造成的,比如忘記給某一 insert sql 的 id 添加 #{},導致繼續使用自增,從而造成沖突。

②建新表&遷移數據&binlog 同步
新表字符集建議是 utf8mb4,支持表情符。新表建好后索引不要漏掉,否則可能會導致慢 SQL!
從經驗來看索引被漏掉時有發生,建議事先列計劃的時候將這些要點記下,后面逐條檢查。
使用全量同步工具或者自己寫 job 來進行全量遷移;全量數據遷移務必要在業務低峰期時操作,并根據系統情況調整并發數。
增量同步:全量遷移完成后可使用 binlog 增量同步工具來追數據,比如阿里內部使用精衛,其他企業可能有自己的增量系統,或者使用阿里開源的。
- cannal/otter:https://github.com/alibaba/canal?spm=5176.100239.blogcont11356.10.5eNr98
- https://github.com/alibaba/otter/wiki/QuickStart?spm=5176.100239.blogcont11356.21.UYMQ17
增量同步起始獲取的 binlog 位點必須在全量遷移之前,否則會丟數據,比如我中午 12 點整開始全量同步,13 點整全量遷移完畢,那么增量同步的 binlog 的位點一定要選在 12 點之前。
位點在前會不會導致重復記錄?不會!線上的 MySQL binlog 是 row 模式,如一個 delete 語句刪除了 100 條記錄,binlog 記錄的不是一條 delete 的邏輯 SQL,而是會有 100 條 binlog 記錄。
insert 語句插入一條記錄,如果主鍵沖突,插入不進去。
③聯表查詢 SQL 改造
現在主鍵已經接入全局唯一 id,新的庫表、索引已經建立,且數據也在實時追平,現在可以開始切庫了嗎?no!
考慮以下非常簡單的聯表查詢 SQL,如果將 B 表拆分到另一個庫里的話,這個 SQL 怎么辦?畢竟跨庫聯表查詢是不支持的!

因此,在切庫之前,需要將系統中上百個聯表查詢的 SQL 改造完畢。如何改造呢?
業務避免:業務上松耦合后技術才能松耦合,繼而避免聯表 SQL。但短期內不現實,需要時間沉淀。
全局表:每個應用的庫里都冗余一份表,缺點:等于沒有拆分,而且很多場景不現實,表結構變更麻煩。
冗余字段:就像訂單表一樣,冗余商品 id 字段,但是我們需要冗余的字段太多,而且要考慮字段變更后數據更新問題。
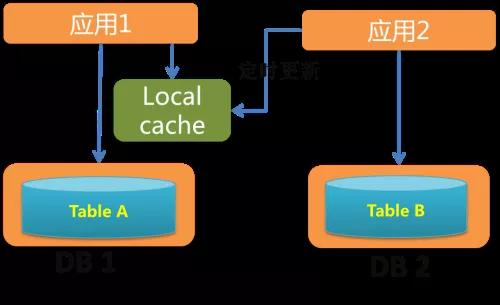
內存拼接:通過 RPC 調用來獲取另一張表的數據,然后再內存拼接。
- 適合 job 類的 SQL,或改造后 RPC 查詢量較少的 SQL。
- 不適合大數據量的實時查詢 SQL。
假設 10000 個 ID,分頁 RPC 查詢,每次查 100 個,需要 5ms,共需要 500ms,RT 太高。

本地緩存另一張表的數據,適合數據變化不大、數據量查詢大、接口性能穩定性要求高的 SQL。
④切庫方案設計與實現(兩種方案)
以上步驟準備完成后,就開始進入真正的切庫環節,這里提供兩種方案,我們在不同的場景下都有使用。
DB 停寫方案,如下圖:
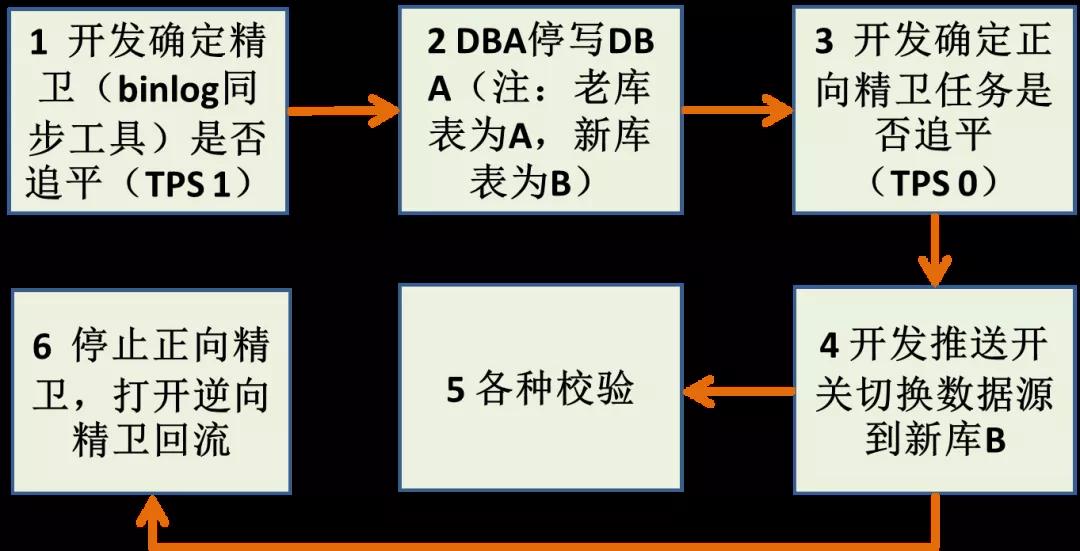
優點:快,成本低。
缺點:
- 如果要回滾得聯系 DBA 執行線上停寫操作,風險高,因為有可能在業務高峰期回滾。
- 只有一處地方校驗,出問題的概率高,回滾的概率高。
舉個例子,如果面對的是比較復雜的業務遷移,那么很可能發生如下情況導致回滾:
- SQL 聯表查詢改造不完全。
- SQL 聯表查詢改錯&性能問題。
- 索引漏加導致性能問題。
字符集問題:此外,binlog 逆向回流很可能發生字符集問題(utf8mb4 到 gbk),導致回流失敗。
這些 binlog 同步工具為了保證強最終一致性,一旦某條記錄回流失敗,就卡住不同步,繼而導致新老表的數據不同步,繼而無法回滾!
雙寫方案,如下圖:

第 2 步“打開雙寫開關,先寫老表 A 再寫新表 B”,這時候確保寫 B 表時 try catch 住,異常要用很明確的標識打出來,方便排查問題。
第 2 步雙寫持續短暫時間后(比如半分鐘后),可以關閉 binlog 同步任務。
優點:
- 將復雜任務分解為一系列可測小任務,步步為贏。
- 線上不停服,回滾容易。
- 字符集問題影響小。
缺點:
- 流程步驟多,周期長。
- 雙寫造成 RT 增加。
⑤開關要寫好
不管什么切庫方案,開關少不了,這里開關的初始值一定要設置為 null!
如果隨便設置一個默認值,比如“讀老表 A”,假設我們已經進行到讀新表 B 的環節了。
這時重啟了應用,在應用啟動的一瞬間,最新的“讀新表 B”的開關推送等可能沒有推送過來,這個時候就可能使用默認值,繼而造成臟數據!
拆分后一致性怎么保證?
以前很多表都在一個數據庫內,使用事務非常方便,現在拆分出去了,如何保證一致性?
如下:
- 分布式事務,性能較差,幾乎不考慮。
- 消息機制補償(如何用消息系統避免分布式事務?)
- 定時任務補償用得較多,實現最終一致,分為加數據補償,刪數據補償兩種。
應用拆分后穩定性怎么保證?
一句話:懷疑第三方,防備使用方,做好自己!

①懷疑第三方
防御式編程,制定好各種降級策略;比如緩存主備、推拉結合、本地緩存……
遵循快速失敗原則,一定要設置超時時間,并異常捕獲。
強依賴轉弱依賴,旁支邏輯異步化:我們對某一個核心應用的旁支邏輯異步化后,響應時間幾乎縮短了 1/3,且后面中間件、其它應用等都出現過抖動情況,而核心鏈路一切正常。
適當保護第三方,慎重選擇重試機制。
②防備使用方
設計一個好的接口,避免誤用:
- 遵循接口最少暴露原則:很多同學搭建完新應用后會隨手暴露很多接口,而這些接口由于沒人使用而缺乏維護,很容易給以后挖坑。聽到過不只一次對話,“你怎么用我這個接口啊,當時隨便寫的,性能很差的”。
- 不要讓使用方做接口可以做的事情:比如你只暴露一個 getMsgById 接口,別人如果想批量調用的話,可能就直接 for 循環 RPC 調用,如果提供 getMsgListByIdList 接口就不會出現這種情況了。
- 避免長時間執行的接口:特別是一些老系統,一個接口背后對應的可能是 for 循環 select DB 的場景。
- …
容量限制:
- 按應用優先級進行流控:不僅有總流量限流,還要區分應用,比如核心應用的配額肯定比非核心應用配額高。
- 業務容量控制:有些時候不僅僅是系統層面的限制,業務層面也需要限制。舉個例子,對 Saas 化的一些系統來說,“你這個租戶最多 1w 人使用”。
③做好自己
a)單一職責
b)及時清理歷史坑:例:例如我們改造時候發現一年前留下的坑,去掉后整個集群 CPU 使用率下降 1/3。
c)運維 SOP 化:說實話,線上出現問題,如果沒有預案,再怎么處理都會超時。
曾經遇到過一次 DB 故障導致臟數據問題,最終只能硬著頭皮寫代碼來清理臟數據,但是時間很長,只能眼睜睜看著故障不斷升級。
經歷過這個事情后,我們馬上設想出現臟數據的各種場景,然后上線了三個清理臟數據的 job,以防其它不可預知的產生臟數據的故障場景,以后只要遇到出現臟數據的故障,直接觸發這三個清理 job,先恢復再排查。
d)資源使用可預測:應用的 CPU、內存、網絡、磁盤心中有數。
- 正則匹配耗 CPU
- 耗性能的 job 優化、降級、下線(循環調用 RPC 或SQL)
- 慢 SQL 優化、降級、限流
- Tair/Redis、DB 調用量要可預測
- 例:Tair、DB
舉個例子:某一個接口類似于秒殺功能,QPS 非常高(如下圖所示),請求先到 tair,如果找不到會回源到 DB,當請求突增時候,甚至會觸發 Tair/Redis 這層緩存的限流。
此外由于緩存在一開始是沒數據的,請求會穿透到 DB,從而擊垮 DB。
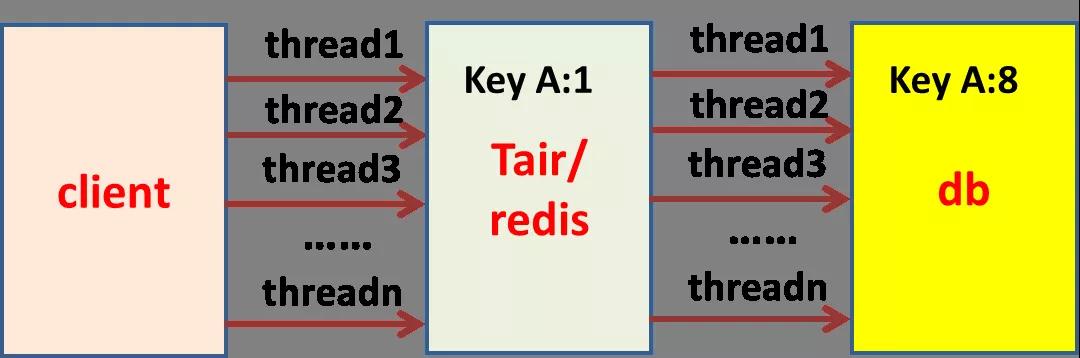
這里的核心問題就是 Tair/Redis 這層資源的使用不可預測,因為依賴于接口的 QPS,怎么讓請求變得可預測呢?
如果我們再增加一層本地緩存(Guava,比如超時時間設置為 1 秒),保證單機對一個 key 只有一個請求回源,那樣對 Tair/Redis 這層資源的使用就可以預知了。
假設有 500 臺 client,對一個 key 來說,一瞬間最多 500 個請求穿透到 Tair/Redis,以此類推到 DB。
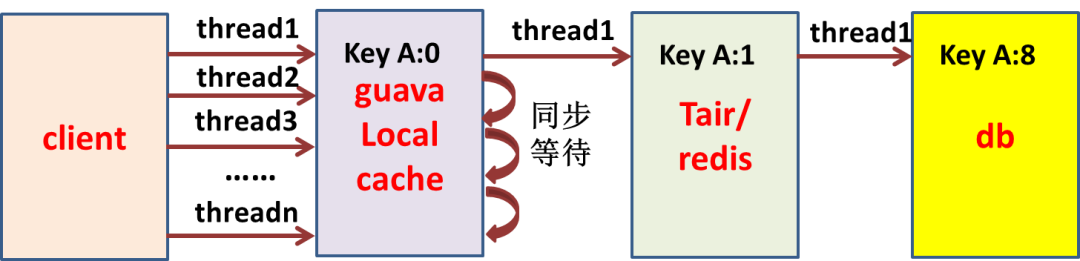
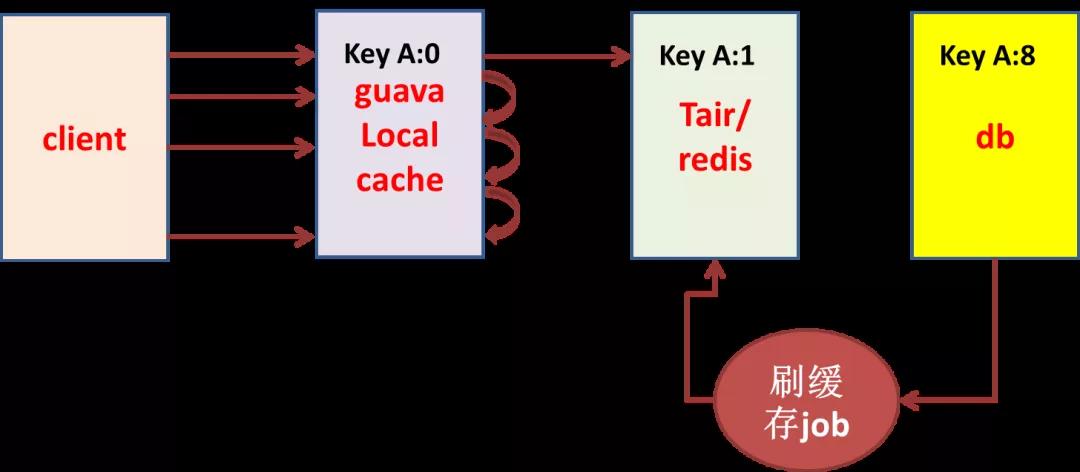
再舉個例子:比如 client 有 500 臺,對某 key 一瞬間最多有 500 個請求穿透到 DB,如果 key 有 10 個,那么請求最多可能有 5000 個到 DB,恰好這些 SQL 的 RT 有些高,怎么保護 DB 的資源?
可以通過一個定時程序不斷將數據從 DB 刷到緩存。這里就將不可控的 5000 個 QPS 的 DB 訪問變為可控的個位數 QPS 的 DB 訪問。
總結
①做好準備面對壓力!
②復雜問題要拆解為多步驟,每一步可測試可回滾!
這是應用拆分過程中的最有價值的實踐經驗!
③墨菲定律:你所擔心的事情一定會發生,而且會很快發生,所以準備好你的 SOP(標準化解決方案)!
某個周五和組里同事吃飯時討論到某一個功能存在風險,約定在下周解決,結果周一剛上班該功能就出現故障了。
以前講小概率不可能發生,但是概率再小也是有值的,比如 P=0.00001%,互聯網環境下,請求量足夠大,小概率事件就真發生了。
④借假修真
這個詞看上去有點玄乎,顧名思義,就是在借著一些事情,來提升另外一種能力,前者稱為假,后者稱為真。
在任何一個單位,對核心系統進行大規模拆分改造的機會很少,因此一旦你承擔起責任,就毫不猶豫地全力以赴吧!
不要被過程的曲折所嚇倒,心智的磨礪,才是本真。
作者:zhanlijun
編輯:陶家龍
出處:cnblogs.com/LBSer/p/6195309.html