













呦呦,這些代碼有點臭,重構大法帶你秀(SPI接口化)
本文轉載自微信公眾號「狼王編程」,作者狼王。轉載本文請聯系狼王編程公眾號。
如果說 正常的重構是為了消除代碼的壞味道, 那么高層次的重構就是消除架構的壞味道
最近由于需要將公司基礎架構的組件進行各種兼容,適配以及二開,所以很多時候就需要對組件進行重構,大家是不是在拿到公司老項目老代碼,又需要二開或者重構的時候,會頭很大,無從下手,我之前也一直是這樣的狀態,不過在慢慢熟悉了一些重構的思想和方法之后,就能稍微的得心應手一些,下面我就開始講下重構,然后會著重講下重構中的SPI接口化。
先給大家看看最近通過使用SPI接口化,重構的一個組件-分布式存儲。
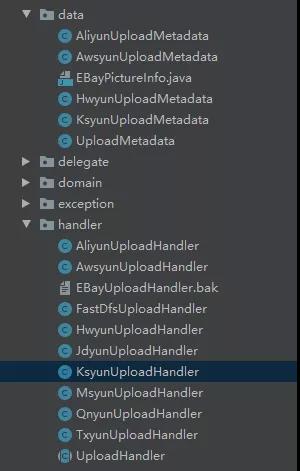
重構前的代碼結構
好家伙,所有的第三方存儲都是寫在一個模塊中的,各種阿里云,騰訊云,華為云等等,這樣的代碼架構在前期可能在不需要經常擴展,二開的時候,還是能用的。
但是當某個新需求來的時候,比如我遇到的:需要支持多個云的多個賬號上傳下載功能,這個是因為在不同的云上,不同賬號的權限,安全認證等都是不太一樣的,所以在某一刻,這個需求就被提出來了,也就是你想上傳到哪個云的哪個賬號都可以。
然后拿到這個代碼,看了下這樣的架構,可能在這樣的基礎上完成需求也是沒有問題的,但是擴展很麻煩,而且代碼會越來越繁重,架構會越來越復雜,不清晰。
所以我索性趁著這個機會,就重構一把,和其他同事也商量了下,決定分模塊,SPI化,好處就是根據你想使用的引入對應的依賴,讓代碼架構更加清晰,后續更加容易擴展了!下面就是重構后的大體架構:
是不是清楚多了,之后哪怕某個云存儲需要增加新功能,或者需要兼容更多的云也是比較容易的了。
好了,下面就讓我們開始講講重構大法~
重構
重構是什么?
重構(Refactoring)就是通過調整程序代碼改善軟件的質量、性能,使其程序的設計模式和架構更趨合理,提高軟件的擴展性和維護性。
重構最重要的思想就是讓普通程序員也能寫出優秀的程序。
把優化代碼質量的過程拆解成一個個小的步驟,這樣重構一個項目的巨大工作量就變成比如修改變量名、提取函數、抽取接口等等簡單的工作目標。
作為一個普通的程序員就可以通過實現這些易完成的工作目標來提升自己的編碼能力,加深自己的項目認識,從而為最高層次的重構打下基礎。
而且高層次的重構依然是由無數個小目標構成,而不是長時間、大規模地去實現。
重構本質是極限編程的一部分,完整地實現極限編程才能最大化地發揮重構的價值。而極限編程本身就提倡擁抱變化,增強適應性,因此分解極限編程中的功能去適應項目的需求、適應團隊的現狀才是最好的操作模式。
重構的重點
重復代碼,過長函數,過大的類,過長參數列,發散式變化,霰彈式修改,依戀情結,數據泥團,基本類型偏執,平行繼承體系,冗余類等
下面舉一些常用的或者比較基礎的例子:
一些基本的原則我覺得還是需要了解的
- 盡量避免過多過長的創建Java對象
- 盡量使用局部變量
- 盡量使用StringBuilder和StringBuffer進行字符串連接
- 盡量減少對變量的重復計算
- 盡量在finally塊中釋放資源
- 盡量緩存經常使用的對象
- 不使用的對象及時設置為null
- 盡量考慮使用靜態方法
- 盡量在合適的場合使用單例
- 盡量使用final修飾符
下面是關于類和方法優化:
- 重復代碼的提取
- 冗長方法的分割
- 嵌套條件分支或者循環遞歸的優化
- 提取類或繼承體系中的常量
- 提取繼承體系中重復的屬性與方法到父類
這里先簡單介紹這些比較常規的重構思想和原則,方法,畢竟今天的主角是SPI,下面有請SPI登場!
SPI
什么是SPI?
SPI全稱Service Provider Interface,是Java提供的一套用來被第三方實現或者擴展的API,它可以用來啟用框架擴展和替換組件。
它是一種服務發現機制,它通過在ClassPath路徑下的META-INF/services文件夾查找文件,自動加載文件里所定義的類。
這一機制為很多框架擴展提供了可能,比如在Dubbo、JDBC中都使用到了SPI機制。
下面就是SPI的機制過程

SPI實際上是基于接口的編程+策略模式+配置文件組合實現的動態加載機制。
系統設計的各個抽象,往往有很多不同的實現方案,在面向的對象的設計里,一般推薦模塊之間基于接口編程,模塊之間不對實現類進行硬編碼。
一旦代碼里涉及具體的實現類,就違反了可拔插的原則,如果需要替換一種實現,就需要修改代碼。為了實現在模塊裝配的時候能不在程序里動態指明,這就需要一種服務發現機制。
SPI就是提供這樣的一個機制:為某個接口尋找服務實現的機制。有點類似IOC的思想,就是將裝配的控制權移到程序之外,在模塊化設計中這個機制尤其重要。所以SPI的核心思想就是解耦。
SPI使用介紹
要使用Java SPI,一般需要遵循如下約定:
- 當服務提供者提供了接口的一種具體實現后,在jar包的META-INF/services目錄下創建一個以接口全限定名`為命名的文件,內容為實現類的全限定名;
- 接口實現類所在的jar包放在主程序的classpath中;
- 主程序通過java.util.ServiceLoder動態裝載實現模塊,它通過掃描META-INF/services目錄下的配置文件找到實現類的全限定名,把類加載到JVM;
- SPI的實現類必須攜帶一個不帶參數的構造方法;
SPI使用場景
概括地說,適用于:調用者根據實際使用需要,啟用、擴展、或者替換框架的實現策略
以下是比較常見的例子:
數據庫驅動加載接口實現類的加載 JDBC加載不同類型數據庫的驅動
日志門面接口實現類加載 SLF4J加載不同提供商的日志實現類
Spring Spring中大量使用了SPI,比如:對servlet3.0規范對ServletContainerInitializer的實現、自動類型轉換Type Conversion SPI(Converter SPI、Formatter SPI)等
Dubbo Dubbo中也大量使用SPI的方式實現框架的擴展, 不過它對Java提供的原生SPI做了封裝,允許用戶擴展實現Filter接口
SPI簡單例子
先定義接口類
- package com.test.spi.learn;
- import java.util.List;
- public interface Search {
- public List<String> searchDoc(String keyword);
- }
文件搜索實現
- package com.test.spi.learn;
- import java.util.List;
- public class FileSearch implements Search{
- @Override
- public List<String> searchDoc(String keyword) {
- System.out.println("文件搜索 "+keyword);
- return null;
- }
- }
數據庫搜索實現
- package com.test.spi.learn;
- import java.util.List;
- public class DBSearch implements Search{
- @Override
- public List<String> searchDoc(String keyword) {
- System.out.println("數據庫搜索 "+keyword);
- return null;
- }
- }
接下來可以在resources下新建META-INF/services/目錄,然后新建接口全限定名的文件:com.test.spi.learn.Search
里面加上我們需要用到的實現類
- com.test.spi.learn.FileSearch
- com.test.spi.learn.DBSearch
然后寫一個測試方法
- package com.test.spi.learn;
- import java.util.Iterator;
- import java.util.ServiceLoader;
- public class TestCase {
- public static void main(String[] args) {
- ServiceLoader<Search> s = ServiceLoader.load(Search.class);
- Iterator<Search> iterator = s.iterator();
- while (iterator.hasNext()) {
- Search search = iterator.next();
- search.searchDoc("hello world");
- }
- }
- }
可以看到輸出結果:
- 文件搜索 hello world
- 數據庫搜索 hello world
SPI原理解析
通過查看ServiceLoader的源碼,梳理了一下,實現的流程如下:
應用程序調用ServiceLoader.load方法 ServiceLoader.load方法內先創建一個新的ServiceLoader,并實例化該類中的成員變量,包括以下:
loader(ClassLoader類型,類加載器) acc(AccessControlContext類型,訪問控制器) providers(LinkedHashMap
應用程序通過迭代器接口獲取對象實例 ServiceLoader先判斷成員變量providers對象中(LinkedHashMap
如果有緩存,直接返回。如果沒有緩存,執行類的裝載,實現如下:
(1) 讀取META-INF/services/下的配置文件,獲得所有能被實例化的類的名稱,值得注意的是,ServiceLoader可以跨越jar包獲取META-INF下的配置文件
(2) 通過反射方法Class.forName()加載類對象,并用instance()方法將類實例化。
(3) 把實例化后的類緩存到providers對象中,(LinkedHashMap
總結
優點
使用SPI機制的優勢是實現解耦,使得接口的定義與具體業務實現分離,而不是耦合在一起。應用進程可以根據實際業務情況啟用或替換具體組件。
缺點
不能按需加載。雖然ServiceLoader做了延遲載入,但是基本只能通過遍歷全部獲取,也就是接口的實現類得全部載入并實例化一遍。如果你并不想用某些實現類,或者某些類實例化很耗時,它也被載入并實例化了,這就造成了浪費。
獲取某個實現類的方式不夠靈活,只能通過 Iterator 形式獲取,不能根據某個參數來獲取對應的實現類。
多個并發多線程使用 ServiceLoader 類的實例是不安全的。
加載不到實現類時拋出并不是真正原因的異常,錯誤很難定位。
看到上面這么多的缺點,你肯定會想,有這些弊端為什么還要使用呢,沒錯,在重構的過程中,SPI接口化是一個非常有用的方式,當你需要擴展的時候,適配的時候,越早的使用你就會受利越早,在一個合適的時間,恰當的機會的時候,就鼓起勇氣,重構吧!
好了。今天就說到這了,我還會不斷分享自己的所學所想,希望我們一起走在成功的道路上!






















