一種基于機器學習的自動文檔標簽圖譜技術
本期課程重點分為以下四個方面:知識圖譜技術發展趨勢、基于機器學習的標簽圖譜技術思路、關鍵技術分析、典型應用案例分享。
一、知識圖譜技術發展趨勢
1. 知識圖譜
(1)定義
知識圖譜:是一種規模非常大的語義網絡系統,是海量文本知識挖掘最常見的手段之一。知識圖譜旨在描述真實世界中存在的各種實體或概念及其關系,一般用三元組表示。知識圖譜亦可被看作是一張巨大的圖,節點表示實體或概念,而邊則由屬性或關系構成。
(2)發展歷程
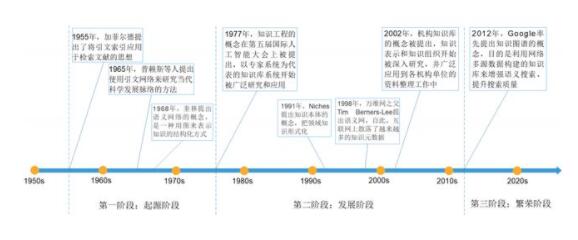
知識圖譜的發展分為起源、發展、繁榮三個階段。
(3)應用
目前,知識圖譜在金融、醫療、教育、司法等多個行業領域廣泛應用。
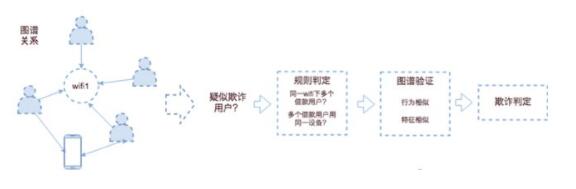
• 金融行業:反洗錢、反欺詐等
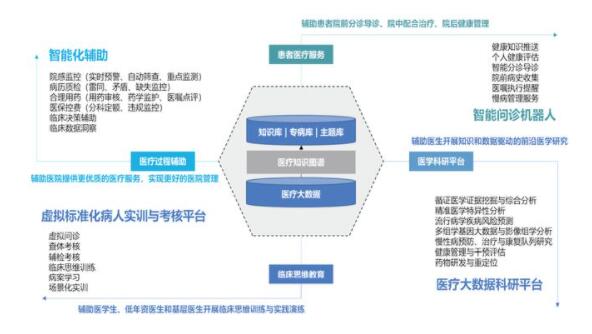
• 醫療行業
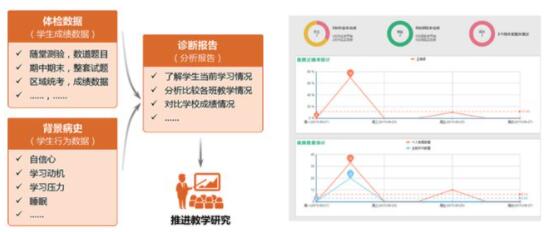
• 教育行業
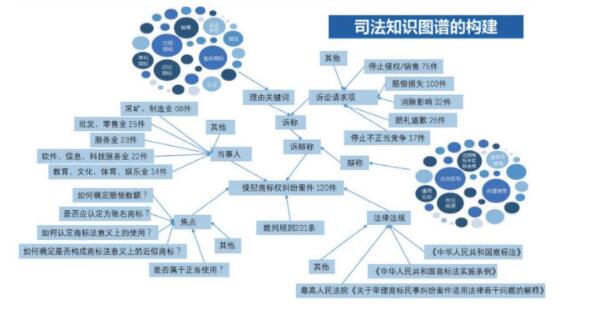
• 司法:知識圖譜在司法中能解決證據索引、類案推送、結果預判、證據分析、文書生成和智慧調解
(4)重要作用
知識圖譜具有獲取、表示和處理知識的能力,是人類心智區別于其它物種心智的重要特征,且已成為推動機器基于人類知識來獲取認知能力的重要途徑,并將逐漸成為未來智能社會的重要生產資料。
知識圖譜是人工智能的基石,包括感知層與認知層。知識圖譜推動人工智能的應用,是強人工智能發展的核心驅動力之一。
(5)知識圖譜的特點
• 特點:
√ 適用范圍:面向文本知識和數據
√ 數據方面:要求具備一定的數據量
√ 知識內容:對知識的寬度、深度有要求,視具體業務情況
√ 要求數據標注:機器學習的前提,越多越好
√ 需要業務專家評估結果的準確性
√ 通用性較差:不同行業效果差異很大
√ 技術復雜:涉及業務、信息、網絡、人工智能、算法、圖形和大數據等多個方面
2. 知識圖譜面臨多方面的挑戰
(1)數據方面的挑戰:多源數據的歧義多、噪聲大,數據關聯性不明確
(2)算法挑戰:現有算法知識抽取準確性、算法性能和算法可解釋性的挑戰(各行業不一樣)
(3)基礎知識庫的挑戰:知識庫融合、垂直領域知識庫構建、基礎知識庫不開放
(4)開發工具的挑戰:全生命周期平臺的缺失、算法工具專家間人機協同需要提升、基于文本的知識圖譜構建工具性能弱、跨語言語系的挑戰、知識圖譜中間件缺乏
(5)隱私、安全方面的挑戰
(6)測試認證方面的挑戰
(7)商業模式與人才相關的挑戰
(8)標準化方面的挑戰
3. 工業領域文檔知識特點
知識圖譜在通用領域得到廣泛的應用與發展,但在工業領域的應用卻不是很多,這與工業領域的行業特點、專業性、保密性和復雜性有關。
(1)原始文檔知識數據龐大、格式繁多:知識獲取很復雜、技術難度高、成本高、時間長
(2)年增長速度很快、存儲分散
(3)專業性太強:與具體的場景關聯很強
(4)公開的工業知識庫很少
(5)保密性強:知識傳播、共享有限制
(6)專業學科多,知識應用復雜:通用性不強,成本高
4. 工業領域知識圖譜面臨的問題
與傳統通用領域不同,工業領域的知識圖譜在知識獲取、知識應用方面存在較大的困難,總結起來主要有以下幾點:
• 工業知識獲取技術難度高、投入大、周期長
• 小批量、小樣本下的知識圖譜如何生成
• 知識圖譜的準確度問題
• 與結構化數據的知識融合問題
• 缺乏標準化的知識圖譜平臺:任意擴展算法、語種、專業學科
• 自主可控問題
二、基于機器學習的標簽圖譜技術思路
1. 標簽的定義與意義
(1)標簽定義:是知識內容高度抽象、高度概括的具現化,是知識某個維度的特征。它具有豐富的含義和內涵,內容簡單、明了。
(2)標簽作用:分類、快速查找、快速了解、用戶畫像、產品畫像……
(3)標簽在工業領域中的意義:
• 具備常規標簽功效和能力
• 專業性:專業術語、詞匯、主題……
• 是工業知識圖譜基于知識運維模式的重要方法之一:標簽可以認為是關鍵詞、主題、事件
2. 標簽應用
標簽應用:非常廣泛,比如知識分類、信息關聯、用戶畫像、產品畫像、數據統計挖掘等。以客戶管理為例,客戶管理是制定六大目標的相關標簽體系,可以實現精確客戶營銷,產生最大客戶價值。
3. 標簽體系構建方法
(1)三大原則:
• 放棄大而全的框架,以業務場景倒推標簽需求
• 標簽生成自動化,解決效率和溝通成本
• 有效的標簽管理機制
(2)建立一個完整的標簽體系需要注重四點

4. 標簽示例
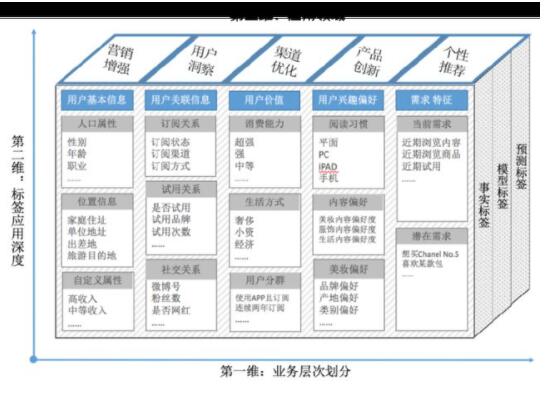
電商標簽體系示例
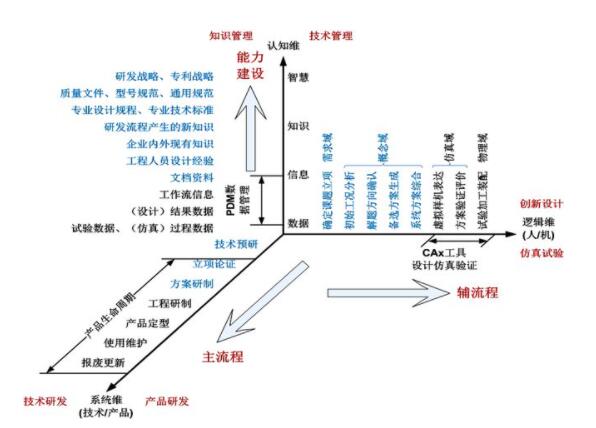
知識三維標簽體系示例
5. 基于標簽圖譜的技術思路
(1)思路重點:標簽代替實體
(2)影響準確度的因素:
• 預處理結果質量
• 標簽實體識別
• 關系抽取
• AI算法優化
• 業務協同程度
(3)基于知識運維的知識圖譜特點:原始數據少、通過迭代逐步豐富數據、通過迭代校正圖譜中的錯誤、逐步把專家頭腦中的知識挖掘出來,特別注重人機協同。
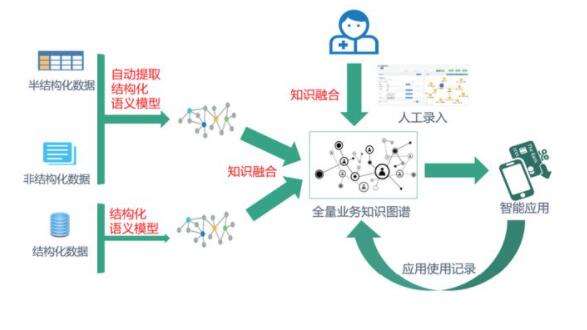
三、關鍵技術分析
1. 智能標簽技術
(1)技術要點:基于人工智能算法,從單個文檔里提取若干個內容特征詞作為文檔的內容標簽
(2)標簽目的:為下一步內容標簽實體處理、標簽實體關系和標簽應用提取做準備
(3)專業要求:
• 提供專業詞匯庫、術語庫、近義詞/同義詞庫可以提高專業性(必填項)
• 通過預設標簽和編碼,可以規范標簽名稱,縮小標簽范圍
• 通過預設關聯詞之間的關系和權重,可以精確語義理解,消除二義性
• 通過人工標注,可以提高準確性(可選項)
• 在標簽使用過程中,可以人工糾錯(類似人工標注,小樣本知識圖譜常用的手段)
2. 標簽關系抽取技術
• 常規知識圖譜要素:實體、關系、方向
• 標簽知識圖譜要素:與常規知識圖譜類似
√ 標簽=實體
√ 關系:按常規方法抽取
√ 方向:按常規方法抽取
√ 標簽圖譜類似關鍵詞圖譜、主題圖譜
√ 自動化:輔以人工標注(工作量小、簡單)
3. 標簽圖譜存儲與可視化技術
• 圖譜結構:三元關系,即對象A-關系-對象B
• 圖譜存儲:RDBMS數據庫或圖數據庫
• 圖譜檢索:以標簽為基礎,也可以是一段文字
• 可視化:ECHART圖表等,與具體的圖譜數據沒有直接關系,擴展能力強
四、典型應用案例分享
1. 基于試驗知識文檔的標簽知識圖譜需求
• 背景:
在某試驗單位試驗設計師的工作電腦上,存放著多年與試驗相關的參考文檔。雖然已對其進行初步分類,整理成多個分件夾和子文件夾,但有些文件夾下文檔比較多,而有些文件夾下僅有一個文檔,同時每年都在不停地更新,這會造成使用時的不便,我們可以將其歸納為以下幾點主要問題:
√ 麻煩:每次查找資料時不能一下全部找到,需要按文件夾逐層往下找
√ 效率低:每次查看文檔時,必須要打開文檔大概看一遍,才知道里面是否有想要的內容
√ 專業性不精確:與試驗相關的資料越來越多,專業性越來越強,文件夾命名已不能體現文檔的內容
√ 信息孤島現象嚴重:想要的內容分散在不同的文檔里,不能在多個文檔中快速找到想要的內容
• 需求:提供一個工具或方法,能快速解決上述問題
2. 試驗參考文檔分析
(1)源文檔分析
• 文檔總數:3500多篇
• 目錄個數:82個
• 二三級目錄有不少
• 多種文件格式:WORD、PDF、TXT
• 涉及專業比較寬:試驗、大數據、云計算、試驗件、試驗方案和試驗報告等
• 試驗相關的文獻占一半左右
(2)試驗類文檔分析
• 業務類:31個目錄,647個文獻
• 數據類:11個目錄,982個文獻
• 文檔分布不均:有的多,有的少
(3)技術思路
• 總體思路:采用基于機器學習的自動文檔標簽圖譜技術來解決
• 理由:
√ 文檔覆蓋面比較寬,但細分類的文檔數量太少,最少的僅有一篇文檔,不適合大規模知識圖譜技術
√ 文檔在不斷更新,但更新的數量不會很多
√ 使用者是業務專家,有足夠的資歷、能力來協助工人智能自動打標簽、生成知識圖譜
√ 使用者可以隨時糾正圖譜中的錯誤
• 主要步驟:
√ 文本預處理
√ 知識文檔語義化
√ 智能自動打標簽
√ 校正智能標簽準確性
√ 自動標簽圖譜
√ 校正標簽圖譜的準確性
• 預處理要點與結果展示:
√ 必須把文檔里的圖片、表格單獨抽取出來做特殊處理
√ 注意論文豎排版面格式
√ 表格里的數據需要單獨處理
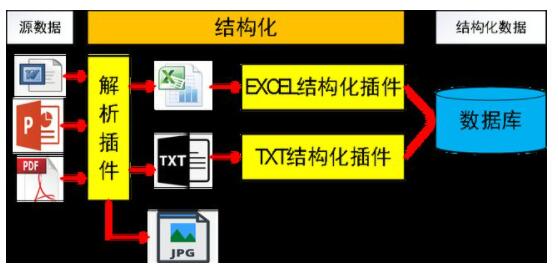
3. 試驗知識文檔智能標簽
智能自動標簽:預設標準化的試驗標簽與編碼,由人工智能根據文檔內容來決定對標預設的標簽,通過多種標簽提取算法綜合分析來決定合適的標簽(默認前10個)。在試驗專業術語、詞匯、同近義詞輔助下,準確率高達90%以上。
4. 試驗標簽知識圖譜
(1)圖譜生成
基于中文語法、詞性和句子成分,采用先進、成熟的標簽實體關系抽取算法來抽取關系,標簽實體構成圖譜“三元”關系。
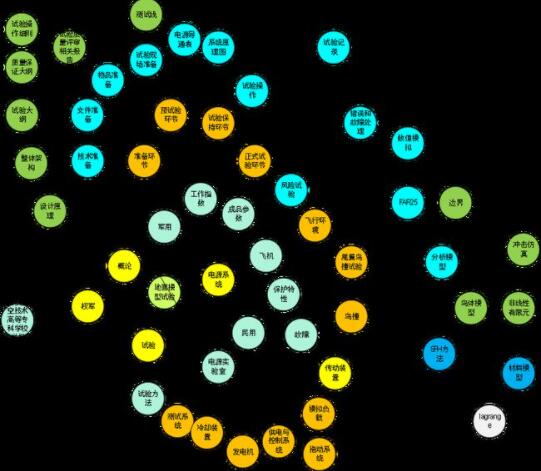
地面模型試驗圖譜示例
(2)準確性提升
• 試驗數據方面:
√ 試驗輔助詞庫:專業術語、同義詞、近義詞、關聯詞
√ 二義性消除:通過關聯詞權重規則
√ 擴大關聯詞范圍:人工給出小部分,大部分由人工智能給出,然后由人工確定是否選用為關聯詞
√ 通過專業工具對兩豎排排版的文獻進行單獨處理
• 技術方面:
√ 選用多種算法綜合比較分析,擇優選擇標簽并排序
√ 輔助人工標注、學習,提升準確性