













SQL、Pandas和Spark:常用數(shù)據(jù)查詢操作對比
本文首先介紹SQL查詢操作的一般流程,對標(biāo)SQL查詢語句的各個關(guān)鍵字,重點針對Pandas和Spark進行介紹,主要包括10個常用算子操作。
01 SQL標(biāo)準(zhǔn)查詢
談到數(shù)據(jù),必會提及數(shù)據(jù)庫;而提及數(shù)據(jù)庫,則一般指代關(guān)系型數(shù)據(jù)庫(RMDB),操作關(guān)系型數(shù)據(jù)庫的語言則是SQL(Structured Query Language)。SQL本質(zhì)上仍然屬于一種編程語言,并且有著相當(dāng)悠久的歷史,不過其語法特性卻幾乎沒怎么變更過,從某種意義上講這也體現(xiàn)了SQL語言的過人之處。
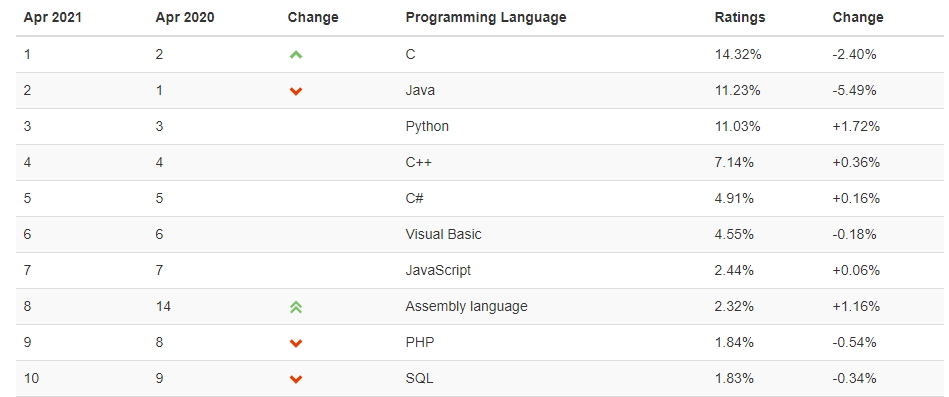
在最新TIOBE排行榜中,SQL位居第10位
一般而言,一句標(biāo)準(zhǔn)的SQL語句按照書寫順序通常含有如下關(guān)鍵詞:
- select:指定查詢字段
- distinct:對查詢結(jié)果字段進行去重
- from:明確查詢的數(shù)據(jù)庫和表
- join on:指定查詢數(shù)據(jù)源自多表連接及條件
- where:設(shè)置查詢結(jié)果過濾條件
- group by:設(shè)置分組聚合統(tǒng)計的字段
- having:依據(jù)聚合統(tǒng)計后的字段進一步過濾
- order by:設(shè)置返回結(jié)果排序依據(jù)
- limit:限定返回結(jié)果條數(shù)
這是一條SQL查詢語句中所能涉及的主要關(guān)鍵字,經(jīng)過解析器和優(yōu)化器之后,最后的執(zhí)行過程則又與之差別很大,執(zhí)行順序如下:
- from:首先找到待查詢的表
- join on:如果目標(biāo)數(shù)據(jù)表不止一個,則對多表建立連接關(guān)系
- where:根據(jù)查詢條件過濾數(shù)據(jù)記錄
- group by:對過濾結(jié)果進行分組聚合
- having:對分組聚合結(jié)果進行二次過濾
- select:對二次過濾結(jié)果抽取目標(biāo)字段
- distinct:根據(jù)條件進行去重處理
- order by:對去重結(jié)果進行排序
- limit:僅返回排序后的指定條數(shù)記錄
曾經(jīng),個人一度好奇為何不將SQL語句的書寫順序調(diào)整為與執(zhí)行順序一致,那樣更易于理解其中的一些技術(shù)原理,但查詢資料未果后,就放棄了……
當(dāng)然,本文的目的不是介紹SQL查詢的執(zhí)行原理或者優(yōu)化技巧,而僅僅是對標(biāo)SQL查詢的幾個關(guān)鍵字,重點講解在Pandas和Spark中的實現(xiàn)。
02 Pandas和Spark實現(xiàn)SQL對應(yīng)操作
以下按照SQL執(zhí)行順序講解SQL各關(guān)鍵字在Pandas和Spark中的實現(xiàn),其中Pandas是Python中的數(shù)據(jù)分析工具包,而Spark作為集Java、Scala、Python和R四種語言的通用分布式計算框架,本文默認(rèn)以Scala語言進行講述。
1)from。由于Python和Scala均為面向?qū)ο笤O(shè)計語言,所以Pandas和Spark中無需from,執(zhí)行df.xxx操作的過程本身就蘊含著from的含義。
2)join on。join on在SQL多表查詢中是很重要的一類操作,常用的連接方式有inner join、left join、right join、outer join以及cross join五種,在Pandas和Spark中也都有相應(yīng)關(guān)鍵字。
Pandas:Pandas實現(xiàn)join操作有兩個主要的API:merge和join。其中merge是Pandas的頂層接口(即可直接調(diào)用pd.merge方法),也是DataFrame的API,支持豐富的參數(shù)設(shè)置,主要介紹如下:
- def merge(
- left, # 左表
- right, # 右表
- how: str = "inner", # 默認(rèn)連接方式:inner
- on=None, # SQL中on連接一段,要求左表和右表中 公共字段
- left_on=None, # 設(shè)置左表連接字段
- right_on=None, # 設(shè)置右表連接字段
- left_index: bool = False, # 利用左表索引作為連接字段
- right_index: bool = False, # 利用右表索引作為連接字段
- sort: bool = False, # join結(jié)果排序
- suffixes=("_x", "_y"), # 非連接字段有重名時,可s何止后綴
- copy: bool = True,
- indicator: bool = False,
- validate=None,
- ) -> "DataFrame":
上述參數(shù)中,可以設(shè)置on連接條件的方式主要有3種:即若連接字段為兩表共有字段,則可直接用on設(shè)置;否則可分別通過left_on和right_on設(shè)置;當(dāng)一個表的連接字段是索引時,可設(shè)置left_index為True。
與merge操作類似,join可看做是merge的一個簡化版本,默認(rèn)以索引作為連接字段,且僅可通過DataFrame來調(diào)用,不是Pandas的頂級接口(即不存在pd.join方法)。
另外,concat也可通過設(shè)置axis=1參數(shù)實現(xiàn)橫向兩表的橫向拼接,但更常用于縱向的union操作。
Spark:相較于Pandas中有多種實現(xiàn)兩個DataFrame連接的方式,Spark中接口則要單一許多,僅有join一個關(guān)鍵字,但也實現(xiàn)了多種重載方法,主要有如下3種用法:
- // 1、兩個DataFrame有公共字段,且連接條件只有1個,直接傳入連接列名
- df1.join(df2, "col")
- // 2、有多個字段,可通過Seq傳入多個字段
- df1.join(df2, Seq("col1", "col2")
- // 3、兩個DataFrame中連接字段不同名,此時需傳入判斷連接條件
- df1.join(df2, df1("col1")===df2("col2"))
- // 注意,上述連接條件中,等于用===,不等于用=!=
3)where。數(shù)據(jù)過濾在所有數(shù)據(jù)處理流程中都是重要的一環(huán),在SQL中用關(guān)鍵字where實現(xiàn),在Pandas和Spark中也有相應(yīng)的接口。
Pandas。Pandas中實現(xiàn)數(shù)據(jù)過濾的方法有多種,個人常用的主要是如下3類:
- 通過loc定位操作符+邏輯判斷條件實現(xiàn)篩選過濾。loc是用于數(shù)據(jù)讀取的方法,由于其也支持傳入邏輯判斷條件,所以自然也可用于實現(xiàn)數(shù)據(jù)過濾,這也是日常使用中最為頻繁一種;
- 通過query接口實現(xiàn),提起query,首先可能想到的便是SQL中Q,實際上pandas中的query實現(xiàn)的正是對標(biāo)SQL中的where語法,在實現(xiàn)鏈?zhǔn)胶Y選查詢中非常好用,具體可參考Pandas用了一年,這3個函數(shù)是我的最愛……
- where語句,Pandas以API豐富而著稱,所以自然是不會放過where關(guān)鍵字的,不過遺憾的是Pandas中的where和Numpy中的where一樣,都是用于對所有列的所有元素執(zhí)行相同的邏輯判斷,可定制性較差。
Spark。Spark中實現(xiàn)數(shù)據(jù)過濾的接口更為單一,有where和filter兩個關(guān)鍵字,且二者的底層實現(xiàn)是一致的,所以實際上就只有一種用法。但在具體使用中,where也支持兩種語法形式,一種是以字符串形式傳入一個類SQL的條件表達(dá)式,類似于Pandas中query;另一種是顯示的以各列對象執(zhí)行邏輯判斷,得到一組布爾結(jié)果,類似于Pandas中l(wèi)oc操作。
4)group by。group by關(guān)鍵字用于分組聚合,實際上包括了分組和聚合兩個階段,由于這一操作屬于比較規(guī)范化的操作,所以Pandas和Spark中也都提供了同名關(guān)鍵字,不同的是group by之后所接的操作算子不盡相同。
Pandas:Pandas中g(shù)roupby操作,后面可接多個關(guān)鍵字,常用的其實包括如下4類:
- 直接接聚合函數(shù),如sum、mean等;
- 接agg函數(shù),并傳入多個聚合函數(shù);
- 接transform,并傳入聚合函數(shù),但不聚合結(jié)果,即聚合前有N條記錄,聚合后仍然有N條記錄,類似SQL中窗口函數(shù)功能,具體參考Pandas中g(shù)roupby的這些用法你都知道嗎?
- 接apply,實現(xiàn)更為定制化的函數(shù)功能,參考Pandas中的這3個函數(shù),沒想到竟成了我數(shù)據(jù)處理的主力
Spark:Spark中的groupBy操作,常用的包括如下3類:
- 直接接聚合函數(shù),如sum、avg等;
- 接agg函數(shù),并傳入多個聚合算子,與Pandas中類似;
- 接pivot函數(shù),實現(xiàn)特定的數(shù)據(jù)透視表功能。
5)having。在SQL中,having用于實現(xiàn)對聚合統(tǒng)計后的結(jié)果進行過濾篩選,與where的核心區(qū)別在于過濾所用的條件是聚合前字段還是聚合后字段。而這在Pandas和Spark中并不存在這一區(qū)別,所以與where實現(xiàn)一致。
6)select。選擇特定查詢結(jié)果,詳見Pandas vs Spark:獲取指定列的N種方式。
7)distinct。distinct在SQL中用于對查詢結(jié)果去重,在Pandas和Spark中,實現(xiàn)這一操作的函數(shù)均為drop_duplicates/dropDuplicates。
8)order by。order by用于根據(jù)指定字段排序,在Pandas和Spark中的實現(xiàn)分別如下:
Pandas:sort_index和sort_values,其中前者根據(jù)索引排序,后者根據(jù)傳入的列名字段排序,可通過傳入ascending參數(shù)控制是升序還是降序。
Spark:orderBy和sort,二者也是相同的底層實現(xiàn),功能完全一致。也是通過傳入的字段進行排序,可分別配合asc和desc兩個函數(shù)實現(xiàn)升序和降序。
- // 1、指定列+desc
- df.orderBy(df("col").desc)
- // 2、desc函數(shù)加指定列
- df.orderBy(desc("col"))
9)limit。limit關(guān)鍵字用于限制返回結(jié)果條數(shù),這是一個功能相對單一的操作,二者的實現(xiàn)分別如下:
Pandas:可分別通過head關(guān)鍵字和iloc訪問符來提取指定條數(shù)的結(jié)果;
Spark:直接內(nèi)置了limit算子,用法更接近SQL中的limit關(guān)鍵字。
10)Union。SQL中還有另一個常用查詢關(guān)鍵字Union,在Pandas和Spark中也有相應(yīng)實現(xiàn):
Pandas:concat和append,其中concat是Pandas 中頂層方法,可用于兩個DataFrame縱向拼接,要求列名對齊,而append則相當(dāng)于一個精簡的concat實現(xiàn),與Python中列表的append方法類似,用于在一個DataFrame尾部追加另一個DataFrame;
Spark:Spark中直接模仿SQL語法,分別提供了union和unionAll兩個算子實現(xiàn)兩個DataFrame的縱向拼接,且含義與SQL中完全類似。
03 小節(jié)
對標(biāo)SQL標(biāo)準(zhǔn)查詢語句中的常用關(guān)鍵字,重點對Pandas和Spark中相應(yīng)操作進行了介紹,總體來看,兩個計算框架均可實現(xiàn)SQL中的所有操作,但Pandas實現(xiàn)的接口更為豐富,傳參更為靈活;而Spark則接口更為統(tǒng)一,但一般也支持多種形式的方法重載。另外,Spark中的算子命名與SQL更為貼近,語法習(xí)慣也與其極為相似,這對于具有扎實SQL基礎(chǔ)的人快速學(xué)習(xí)Spark來說會更加容易。




















