













2020年入門數據分析選擇Python還是SQL?七個常用操作對比!
SQL和Python幾乎是當前數據分析師必須要了解的兩門語言,它們在處理數據時有什么區別?本文將分別用MySQL和pandas來展示七個在數據分析中常用的操作,希望可以幫助掌握其中一種語言的讀者快速了解另一種方法!
在閱讀本文前,你可以訪問下方網站下載本文使用的示例數據,并導入MySQL與pandas中,一邊敲代碼一邊閱讀!
https://raw.githubusercontent.com/pandas-dev/pandas/master/pandas/tests/io/data/csv/tips.csv
一、選擇
在SQL中,我們可以使用SELECT語句從表選擇數據,結果被存儲在一個結果表中,語法如下:
- SELECT column_name,column_name
- FROM table_name;
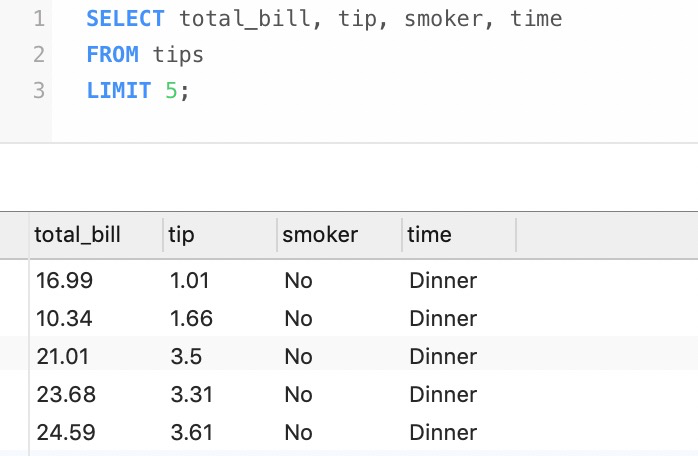
如果不想顯示全部的記錄,可以使用TOP或LIMIT來限制行數。因此選擇tips表中的部分列可以使用下面的語句
- SELECT total_bill, tip, smoker, time
- FROM tips
- LIMIT 5;
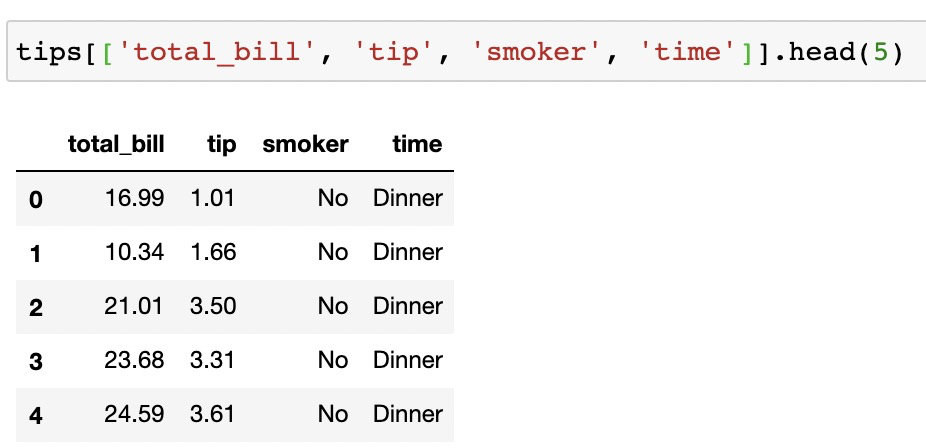
而在pandas中,我們可以通過將列名列表傳遞給DataFrame來完成列選擇
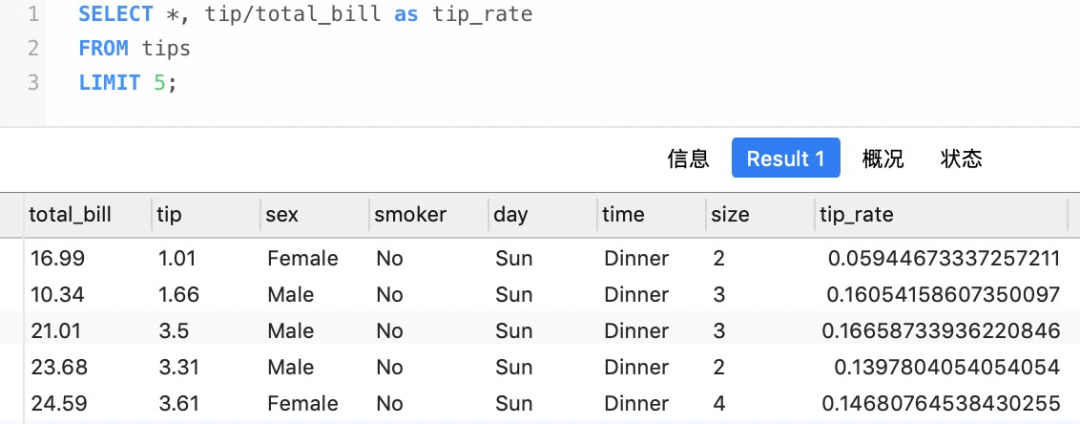
在SQL中,進行選擇的同時還可以進行計算,比如添加一列
- SELECT *, tip/total_bill as tip_rate
- FROM tips
- LIMIT 5;
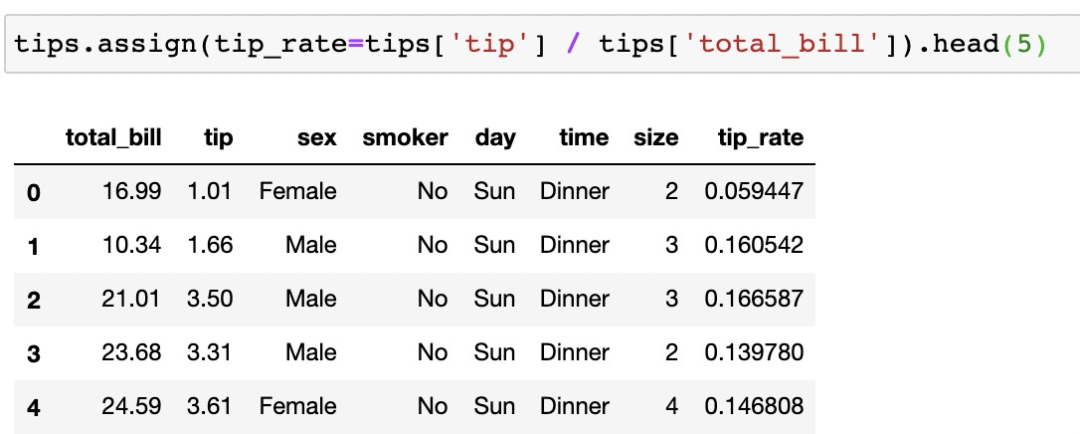
在pandas中使用DataFrame.assign()同樣可以完成這個操作
二、查找
1. 單條件查找
在SQL中,WHERE子句用于提取那些滿足指定條件的記錄,語法如下
- SELECT column_name,column_name
- FROM table_name
- WHERE column_name operator value;
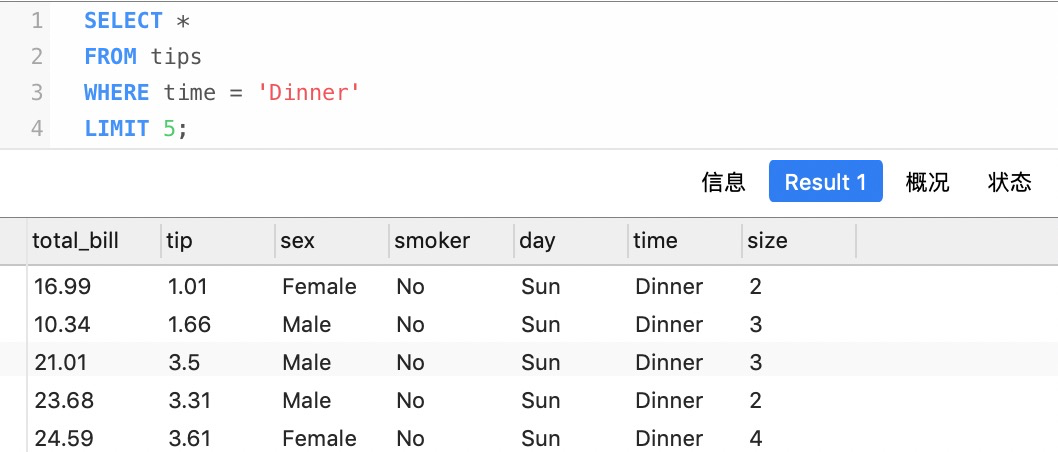
比如查找示例數據中time = dinner的記錄
- SELECT *
- FROM tips
- WHERE time = 'Dinner'
- LIMIT 5;
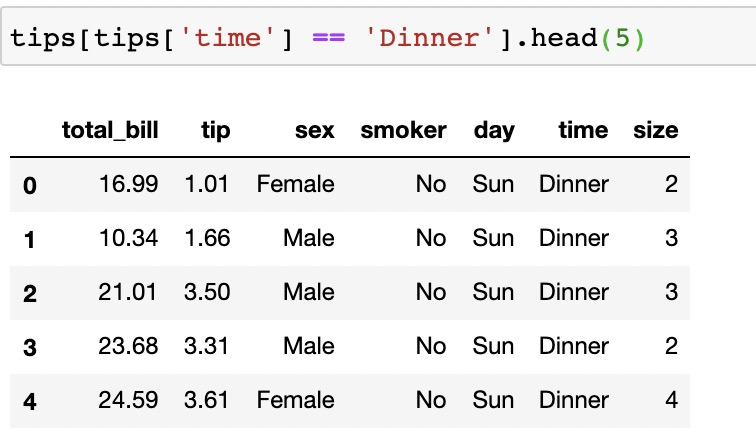
而在pandas中,按照條件進行查找則可以有多種形式,比如可以將含有True/False的Series對象傳遞給DataFrame,并返回所有帶有True的行
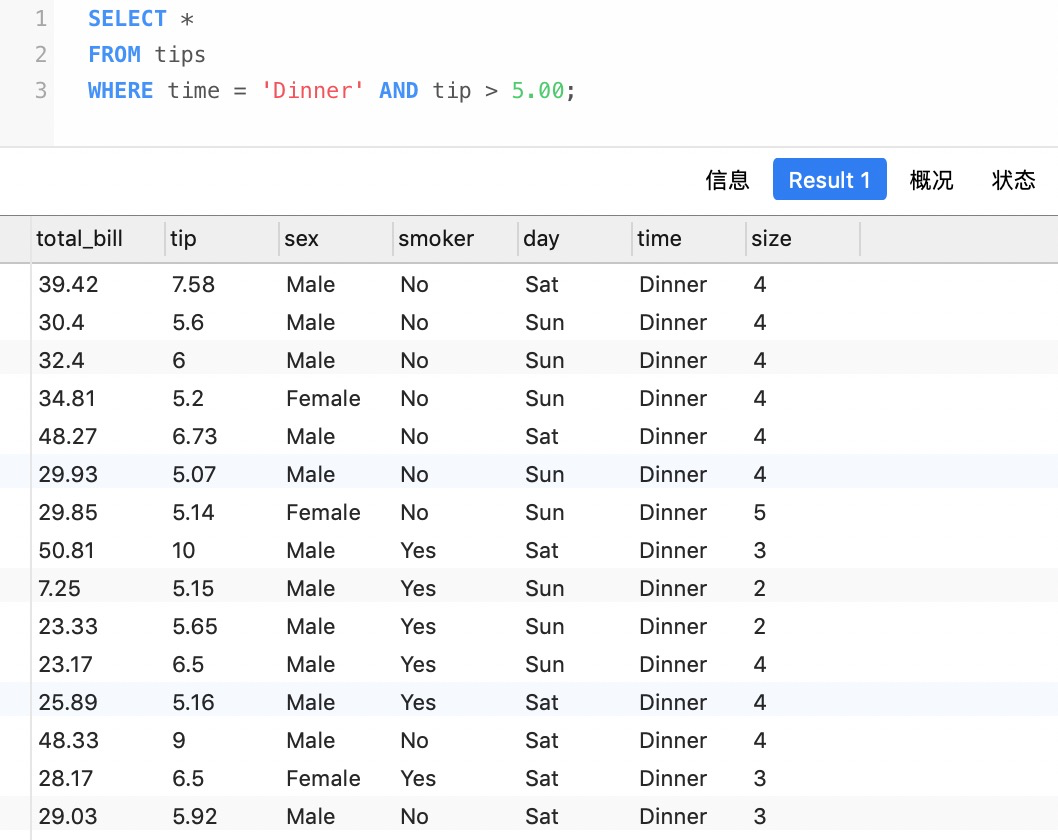
2. 多條件查找
在SQL中,進行多條件查找可以使用AND/OR來完成
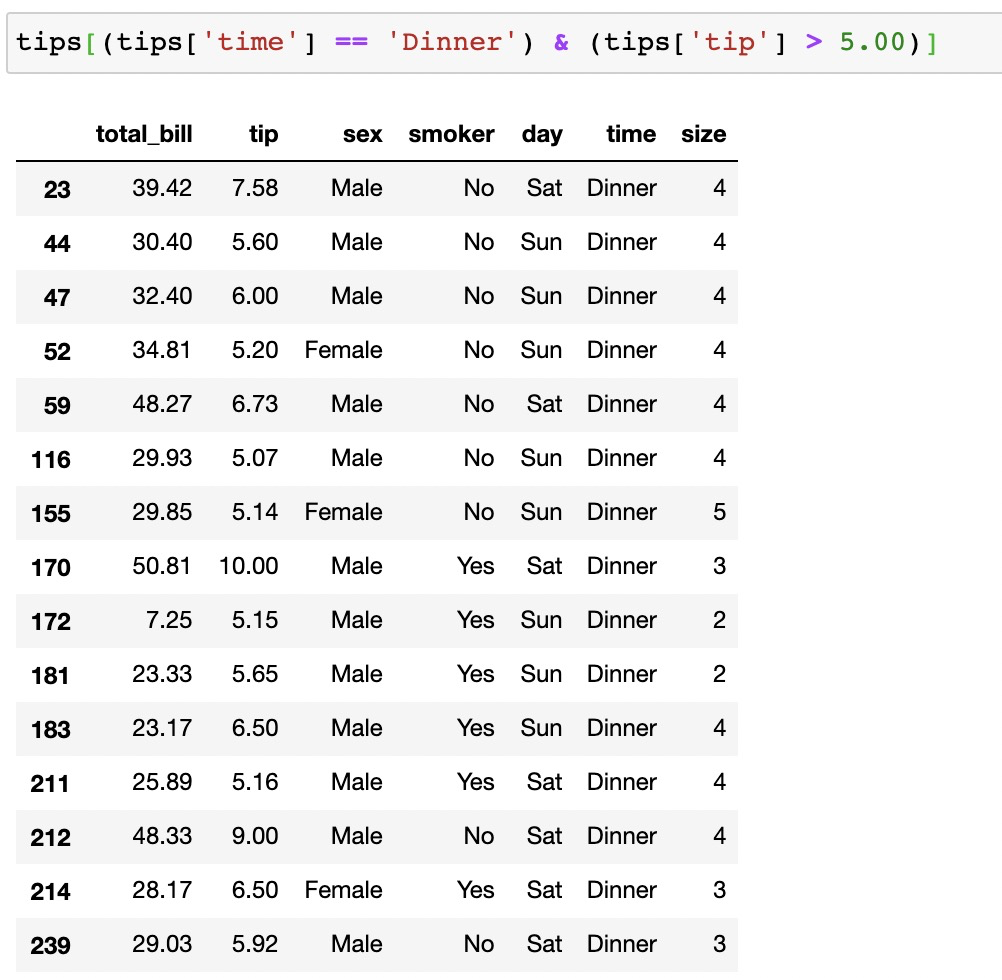
在pandas中也有類似的操作
3. 查找空值
在pandas檢查空值是使用notna()和isna()方法完成的。
- frame[frame['col1'].notna()]
在SQL中可以使用IS NULL和IS NOT NULL完成
- SELECT *
- FROM frame
- WHERE col2 IS NULL;
- SELECT *
- FROM frame
- WHERE col1 IS NOT NULL;
三、更新
在SQL中使用UPDATE
- UPDATE tips
- SET tiptip = tip*2
- WHERE tip < 2;
而在pandas中則有多種方法,比如使用loc函數
- tips.loc[tips['tip'] < 2, 'tip'] *= 2
四、刪除
在SQL中使用DELETE
- DELETE FROM tips
- WHERE tip > 9;
在pandas中,我們選擇應保留的行,而不是刪除它們
- tipstips = tips.loc[tips['tip'] <= 9]
五、分組
在pandas中,使用groupby()方法實現分組。groupby()通常是指一個過程,在該過程中,我們希望將數據集分為幾組,應用某些功能(通常是聚合),然后將各組組合在一起。
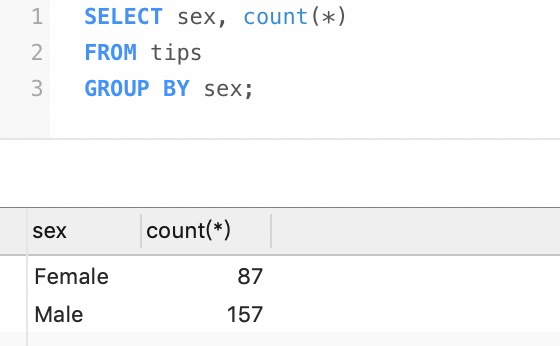
常見的SQL操作是獲取整個數據集中每個組中的記錄數。例如,通過對性別進行分組查詢
- SELECT sex, count(*)
- FROM tips
- GROUP BY sex;
在pandas中的等價操作為
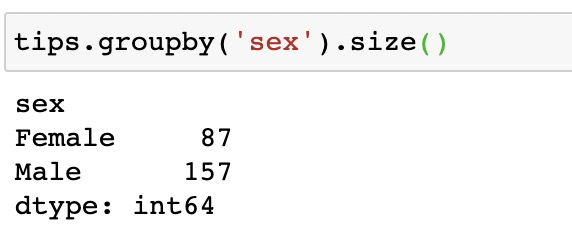
注意,在上面代碼中,我們使用size()而不是count() 這是因為count()將函數應用于每一列,并返回每一列中非空記錄的數量!
六、連接
在pandas可以使用join()或merge()進行連接,每種方法都有參數,可讓指定要執行的聯接類型(LEFT,RIGHT,INNER,FULL)或要聯接的列。
現在讓我們重新創建兩組示例數據,分別用代碼來演示不同的連接
- df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'],
- ....: 'value': np.random.randn(4)})
- ....:
- df2 = pd.DataFrame({'key': ['B', 'D', 'D', 'E'],
- ....: 'value': np.random.randn(4)})
1. 內連接
內聯接使用比較運算符根據每個表共有的列的值匹配兩個表中的行,在SQL中實現內連接使用INNER JOIN
- SELECT *
- FROM df1
- INNER JOIN df2
- ON df1.key = df2.key;
在pandas中可以使用merge()

merge()提供了一些參數,可以將一個DataFrame的列與另一個DataFrame的索引連接在一起👇

2. 左/右外聯接
在SQL中實現左/右外連接可以使用LEFT OUTER JOIN和RIGHT OUTER JOIN
- SELECT *
- FROM df1
- LEFT OUTER JOIN df2
- ON df1.key = df2.key;
- SELECT *
- FROM df1
- RIGHT OUTER JOIN df2
- ON df1.key = df2.key;
在pandas中實現同樣可以使用merge()并指定how關鍵字為left或者right即可
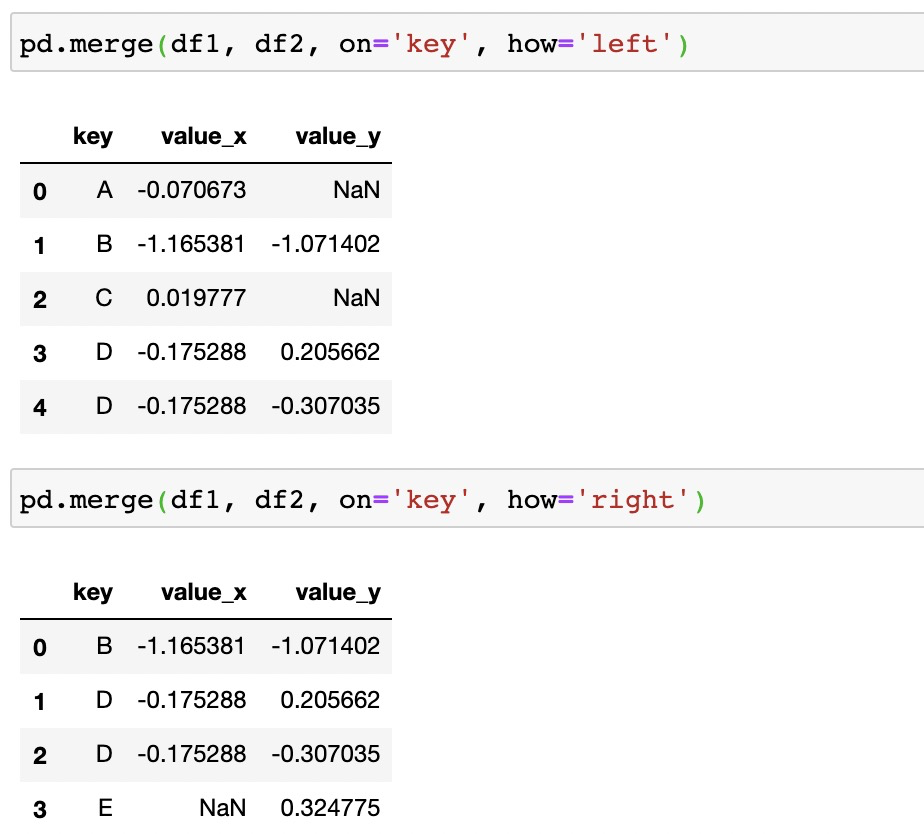
3. 全連接
全連接返回左表和右表中的所有行,無論是否匹配,但并不是所有的數據庫都支持,比如mysql就不支持,在SQL中實現全連接可以使用FULL OUTER JOIN
- SELECT *
- FROM df1
- FULL OUTER JOIN df2
- ON df1.key = df2.key;
在pandas中實現同樣可以使用merge()并指定how關鍵字為outer
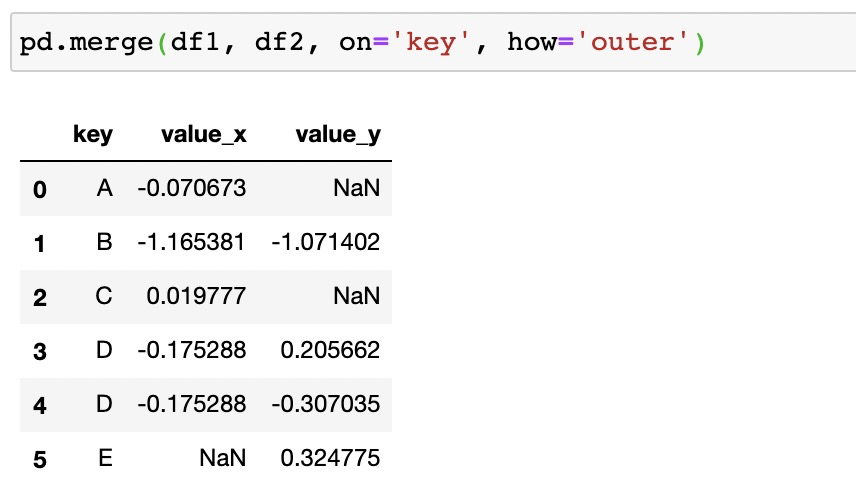
七、合并
SQL中UNION操作用于合并兩個或多個SELECT語句的結果集,UNION與UNION ALL類似,但是UNION將刪除重復的行。示例代碼如下
- SELECT city, rank
- FROM df1
- UNION ALL
- SELECT city, rank
- FROM df2;
- /*
- city rank
- Chicago 1
- San Francisco 2
- New York City 3
- Chicago 1
- Boston 4
- Los Angeles 5
- */
在pandas中可以使用concat()實現UNION ALL
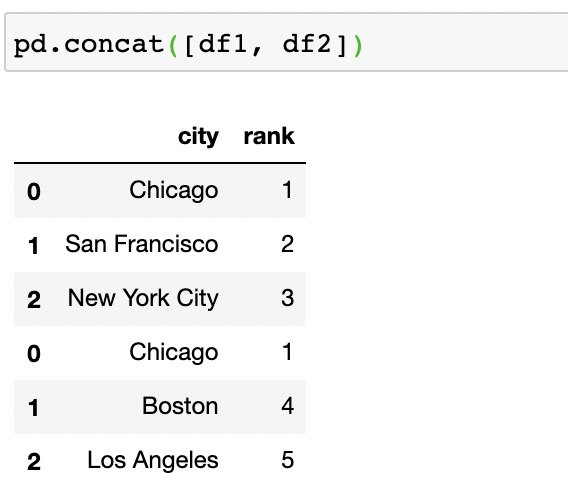
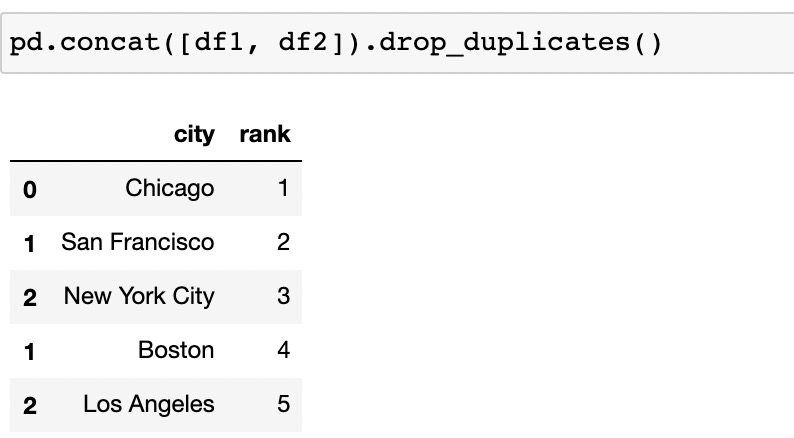
上面是UNION ALL保留重復值,如果希望刪除可以使用 drop_duplicates()
以上就是本文的全部內容,可以看到在不同的場景下不同的語言有著不同的特性,如果你想深入學習了解可以進一步查閱官方文檔并多加練習!

















