緩存穿透問(wèn)題導(dǎo)致Facebook史上嚴(yán)重事故之一
2010年9月23,這個(gè)世界上最大的社交平臺(tái)項(xiàng)目facebook,遭遇了最嚴(yán)重宕機(jī)故障之一,以至于facebook網(wǎng)站4個(gè)小時(shí)后才恢復(fù)運(yùn)行。而且這次事故非常極端,工程師不得不先讓facebook下線,才能恢復(fù)。雖然10年前的facebook遠(yuǎn)沒(méi)有現(xiàn)在這么大,不過(guò)仍然有超過(guò)10億用戶,人們?nèi)witter上抱怨或者取笑這次故障。
那么,導(dǎo)致是什么原因?qū)е逻@次facebook宕機(jī)呢?
Today we made a change to the persistent copy of a configuration value that was interpreted as invalid. This meant that every single client saw the invalid value and attempted to fix it. Because the fix involves making a query to a cluster of databases, that cluster was quickly overwhelmed by hundreds of thousands of queries a second.
一個(gè)錯(cuò)誤的配置變更,導(dǎo)致大量的請(qǐng)求擊穿緩存,直達(dá)數(shù)據(jù)庫(kù)。我們把這種現(xiàn)象稱之為cache stampede,wiki地址:https://en.wikipedia.org/wiki/Cache_stampede。這在技術(shù)行業(yè)是一個(gè)非常普遍的問(wèn)題,很多公司都出現(xiàn)過(guò)類似的事故,無(wú)數(shù)工程師為了不讓自己的項(xiàng)目遭遇這樣的問(wèn)題做了大量的工作。
1、什么是緩存踩踏
cache stampede是指很多線程嘗試并行訪問(wèn)緩存,如果緩存中不存在要訪問(wèn)的數(shù)據(jù),那么這時(shí)候,線程一般會(huì)請(qǐng)求數(shù)據(jù)庫(kù)獲取它們需要的數(shù)據(jù)(所以cache stampede可以翻譯成緩存踩踏。和緩存穿透有點(diǎn)不一樣,Cache Stampede的重點(diǎn)是很多的線程穿透緩存)。
緩存踩踏破壞性這么大的主要原因是,它可能會(huì)導(dǎo)致故障雪崩,也就是說(shuō)一個(gè)故障接著一個(gè)故障:
- 大量線程并發(fā)請(qǐng)求沒(méi)有從緩存中獲取到數(shù)據(jù),導(dǎo)致這些請(qǐng)求都會(huì)落到數(shù)據(jù)庫(kù)上。
- 數(shù)據(jù)庫(kù)由于恐怖的CPU毛刺而宕機(jī),從而導(dǎo)致大量的超時(shí)錯(cuò)誤。
- 請(qǐng)求線程接收到超時(shí)后,又不斷重試請(qǐng)求,從而又導(dǎo)致新一輪的災(zāi)難。
- 反反復(fù)復(fù),無(wú)窮無(wú)盡。
需要說(shuō)明的是,即使你沒(méi)有 Facebook 那樣的規(guī)模,也會(huì)遇到這個(gè)問(wèn)題,因?yàn)樗c規(guī)模無(wú)關(guān)。這個(gè)問(wèn)題一直困擾著初創(chuàng)公司和科技巨頭。
2、如何阻止緩存踩踏
這是個(gè)很好的問(wèn)題,在這篇文章中,我們將探索不同的策略來(lái)緩解甚至阻止緩存踩踏的出現(xiàn)。畢竟,你也不想等到你自己的服務(wù)出現(xiàn)問(wèn)題后,才想到要學(xué)習(xí)如何預(yù)防。
2.1 增加更多的緩存
一個(gè)很簡(jiǎn)單的方法就是增加更多的緩存,它的原理有點(diǎn)類似操作系統(tǒng)的多級(jí)緩存。操作系統(tǒng)使用了一個(gè)緩存層次結(jié)構(gòu)(L1、L2、L3),為了更快速的訪問(wèn)。參考操作系統(tǒng),你也能在你的應(yīng)用中引入多級(jí)緩存。比如本地內(nèi)存緩存叫做L1緩存(例如Guava Cache,Caffeine),遠(yuǎn)程緩存叫做L2緩存(例如Redis,memcached):
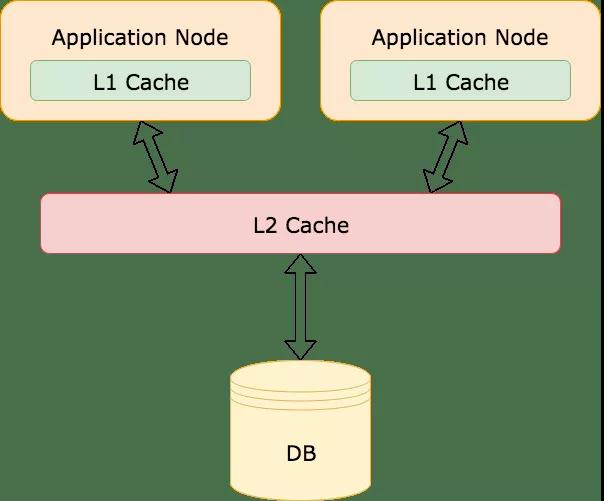
這個(gè)策略對(duì)那些頻繁訪問(wèn)的數(shù)據(jù)來(lái)說(shuō)是非常有用的。即使L2緩存中的Key失效了,L1緩存中仍然有值,能夠擋住大量請(qǐng)求不會(huì)打到數(shù)據(jù)庫(kù)上。
然后,這種方法需要做一些取舍,在應(yīng)用服務(wù)器本地緩存中緩存數(shù)據(jù)可能會(huì)導(dǎo)致OOM。在使用本地緩存的時(shí)候要非常小心,尤其當(dāng)你會(huì)緩存一些大量數(shù)據(jù)的時(shí)候。
另外,這個(gè)策略在接下來(lái)我要說(shuō)的這種情況下仍然沒(méi)有作用。例如,當(dāng)一個(gè)有很多粉絲的大V上傳了一個(gè)新的照片或者視頻到他們的社交賬號(hào)上,這時(shí)候大量粉絲被提醒大V有新的內(nèi)容發(fā)布,這時(shí)候粉絲會(huì)集中在相同的時(shí)間點(diǎn)上登陸社交平臺(tái)查看新的內(nèi)容。但是可能大V發(fā)送的新內(nèi)容數(shù)據(jù)還沒(méi)有加載到緩存中,這就會(huì)導(dǎo)致可怕的緩存踩踏。那么,我們還能做什么呢?
2.2 鎖和Promise
緩存踩踏的核心問(wèn)題是競(jìng)態(tài)條件(race condition),即很多的線程爭(zhēng)奪共享資源。只不過(guò)這里爭(zhēng)奪的共享資源是緩存。
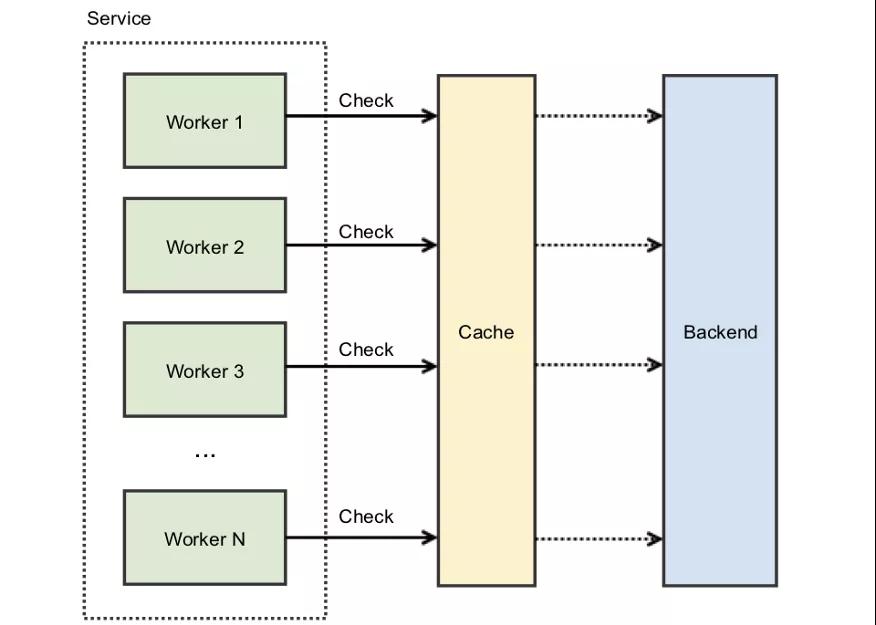
通常在高并發(fā)的系統(tǒng)中,一種阻止共享資源競(jìng)態(tài)的方法是加鎖。一般來(lái)講,鎖是用在相同機(jī)器上的不同線程,不過(guò)也可以使用分布式鎖來(lái)應(yīng)對(duì)不同機(jī)器對(duì)共享資源的競(jìng)爭(zhēng)(參考redis分布式鎖:http://redis.cn/topics/distlock.html)。
通過(guò)給緩存KEY加鎖,就會(huì)在同一時(shí)間只有一個(gè)調(diào)用者能訪問(wèn)爭(zhēng)奪的緩存。如果KEY不存在或者已經(jīng)過(guò)期,調(diào)用者就會(huì)拿到鎖。這時(shí)候其他爭(zhēng)奪的處理線程必須等待直到這個(gè)鎖被釋放。
用鎖來(lái)解決這個(gè)問(wèn)題,它也會(huì)引入另一個(gè)問(wèn)題:系統(tǒng)如何處理所有正在等待鎖釋放的那些線程?
你想嘗試自旋鎖(spinlock),讓這些線程持續(xù)不斷的輪詢?nèi)カ@取鎖?這就會(huì)導(dǎo)致出現(xiàn)非常busy的場(chǎng)景,消耗大量的CPU。或者讓線程在檢查鎖是否可用之前隨機(jī)等待一段時(shí)間?這樣的話,你又會(huì)碰到驚群效應(yīng)問(wèn)題(thundering herd problem)。
引入退避和抖動(dòng)機(jī)制來(lái)防止驚群效應(yīng)?這可能行得通,但還有另外一個(gè)問(wèn)題。持有鎖的線程必須重新計(jì)算值,并在釋放鎖之前更新緩存鍵。這個(gè)過(guò)程可能需要耗費(fèi)一點(diǎn)時(shí)間,特別是當(dāng)計(jì)算成本很高或存在網(wǎng)絡(luò)問(wèn)題時(shí),如果因?yàn)橛?jì)算緩存而耗盡了可用的連接池,仍然可能導(dǎo)致宕機(jī)。
- backoff-and-jitter
幸運(yùn)的是,一些大公司也碰到過(guò)這樣的問(wèn)題,他們使用promises來(lái)解決這樣的問(wèn)題。
2.3 Promises如何防止自旋
引用instagram工程師博客(Thundering Herds & Promises)中的內(nèi)容:
在instagram, 當(dāng)我們啟用一個(gè)新的集群,并且因?yàn)榧褐械木彺媸强盏模覀兙蜁?huì)碰到緩存stampede問(wèn)題。這時(shí)候,我們就會(huì)用promises來(lái)解決這個(gè)問(wèn)題。它的核心思想是:不緩存實(shí)際的值,而是緩存一個(gè)promise,這個(gè)promise最終會(huì)提供我們需要的值。當(dāng)我們使用緩存時(shí),如果碰到一個(gè)不存在的KEY,我們不立即去數(shù)據(jù)庫(kù)中查詢,而是創(chuàng)建一個(gè)promise然后放到緩存中,這個(gè)緩存中的promise會(huì)去查詢數(shù)據(jù)庫(kù),其他的并發(fā)請(qǐng)求發(fā)現(xiàn)這個(gè)promise就不會(huì)把請(qǐng)求打到數(shù)據(jù)庫(kù)上,它們都會(huì)等待第一個(gè)線程放進(jìn)去的promise去數(shù)據(jù)庫(kù)中查詢結(jié)果。
通過(guò)緩存promise而不是實(shí)際的值,就不會(huì)自旋鎖了。第一個(gè)線程發(fā)現(xiàn)緩存中沒(méi)有數(shù)據(jù),就會(huì)用原子性的操作創(chuàng)建并緩存一個(gè)異步的promise,所有后續(xù)的請(qǐng)求都能立即返回這個(gè)promise:
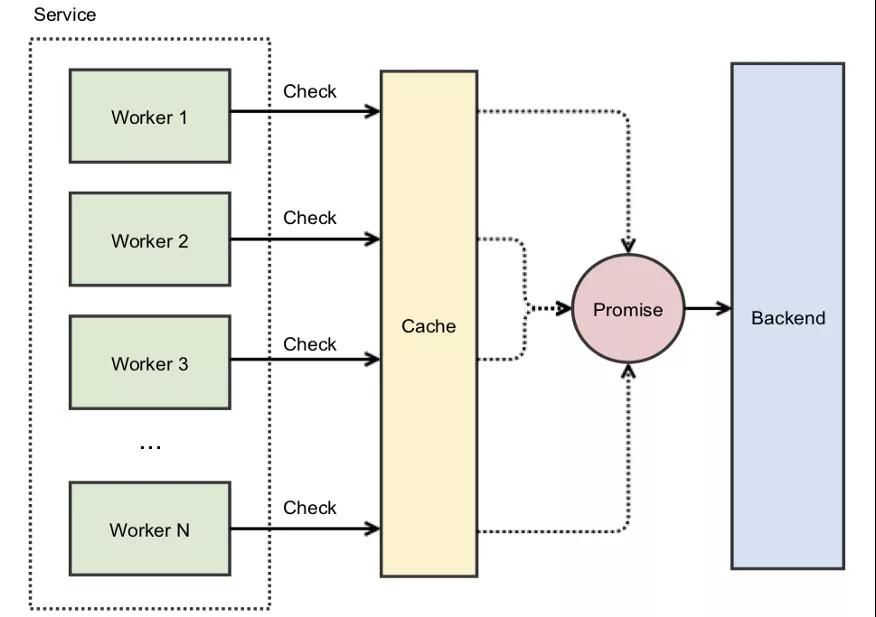
你仍然需要使用鎖來(lái)防止多個(gè)線程訪問(wèn)緩存KEY,假設(shè)創(chuàng)建 Promise 是一個(gè)近乎即時(shí)的操作,那么線程停留在自旋鎖中的時(shí)間長(zhǎng)度就可以忽略不計(jì)了。但是,如果重新計(jì)算緩存數(shù)據(jù)需要相當(dāng)長(zhǎng)的時(shí)間,那該怎么辦?即使線程能夠立即獲取到緩存的 Promise,它們?nèi)匀恍枰却惒竭M(jìn)程完成后才能將數(shù)據(jù)返回。雖然這種場(chǎng)景不一定會(huì)導(dǎo)致宕機(jī),但仍然會(huì)導(dǎo)致尾部延遲和影響整體用戶體驗(yàn)。如果保持較低的尾部延遲對(duì)于應(yīng)用程序來(lái)說(shuō)很重要,那么就需要考慮另外一種策略。
2.4 預(yù)先重新計(jì)算
預(yù)先重新計(jì)算(也被稱為提前過(guò)期)原理很簡(jiǎn)單:在緩存KEY失效發(fā)生前,重新計(jì)算緩存的值然后延長(zhǎng)失效時(shí)間,這就能確保緩存總是最新的,緩存缺失的問(wèn)題也永遠(yuǎn)不會(huì)發(fā)生。
最簡(jiǎn)單的實(shí)現(xiàn)方式就是開(kāi)啟一個(gè)后臺(tái)處理線程,或者一個(gè)定時(shí)任務(wù)。例如。假設(shè)緩存KEY過(guò)期時(shí)間時(shí)一個(gè)小時(shí),它需要花兩分鐘來(lái)計(jì)算值。那么,定時(shí)任務(wù)可以在過(guò)期時(shí)間到來(lái)之前的5分鐘運(yùn)行,更新緩存的值并延長(zhǎng)失效時(shí)間一個(gè)小時(shí)。
雖然原理非常簡(jiǎn)單,但是有一個(gè)明顯的缺點(diǎn),除非你很清楚哪個(gè)緩存KEY會(huì)被使用,否則你需要重新計(jì)算緩存中每個(gè)KEY的值,這將是一個(gè)非常耗時(shí)的過(guò)程。而且如果考慮到高可用,某個(gè)節(jié)點(diǎn)上計(jì)算任務(wù)失敗了,還需要轉(zhuǎn)移到另一個(gè)可用的節(jié)點(diǎn)上繼續(xù)計(jì)算。
基于這個(gè)原因,生產(chǎn)環(huán)境上很少有這么做的。當(dāng)然,也有一個(gè)例外。
2.5 概率性重新計(jì)算
在2015年,一組研究員發(fā)布了一份白皮書(shū) Optimal Probabilistic Cache Stampede Prevention,即最優(yōu)概率性預(yù)防緩存踩踏。在這份白皮書(shū)中,他們描述了一個(gè)算法來(lái)預(yù)測(cè)在緩存失效之前,什么時(shí)候需要重新計(jì)算緩存的值。這里涉及到很多數(shù)學(xué)理論,但是可以做一個(gè)簡(jiǎn)單的總結(jié):
currentTime - ( timeToCompute * beta * log(rand()) ) > expiry
這個(gè)公式中各變量的含義如下所示:
- currentTime 表示當(dāng)前時(shí)間;
- timeToCompute 表示重新計(jì)算緩存值需要的時(shí)間;
- beta是一個(gè)大于0的非負(fù)數(shù),默認(rèn)為1,可配置;
- rand() 一個(gè)返回0~1之間隨機(jī)數(shù)的方法;
- expiry 下一次需要設(shè)置的失效時(shí)間戳;
它的思想是,每次線程從緩存中獲取數(shù)據(jù)時(shí),它都需要運(yùn)行這個(gè)算法,如果返回true,那么這個(gè)線程將主動(dòng)去重新計(jì)算緩存值。而且離失效時(shí)間越近,這個(gè)算法返回true的概率就越大。
這個(gè)策略不是很好理解,但是實(shí)現(xiàn)非常簡(jiǎn)單,不需要考慮失敗轉(zhuǎn)移,也不需要到重新計(jì)算緩存中每一個(gè)KEY的值。當(dāng)然,預(yù)先重計(jì)算假設(shè)有一個(gè)值需要重新計(jì)算,它本身并不能防止其他線程引起緩存踩踏問(wèn)題。為此,你需要將其與鎖和 Promise 結(jié)合起來(lái)使用。
3、如何停止正在發(fā)生的緩存踩踏
facebook緩存踩踏之所以如此嚴(yán)重的原因之一是,即使當(dāng)工程師找到了解決方案,他們并不能通過(guò)部署來(lái)解決。因?yàn)椴忍と栽诶^續(xù)。事后診斷報(bào)告提到:
更糟糕的是,每次客戶端接收到數(shù)據(jù)庫(kù)查詢錯(cuò)誤時(shí),都會(huì)把它當(dāng)作一個(gè)無(wú)效的值,然后就會(huì)刪除緩存中相關(guān)的KEY,這就意味著即使原來(lái)的問(wèn)題被修復(fù)了,但是查詢還在繼續(xù)。一旦數(shù)據(jù)庫(kù)無(wú)法正確響應(yīng)某一部分請(qǐng)求,那么就會(huì)導(dǎo)致緩存KEY被刪除,從而引起更多的請(qǐng)求打到數(shù)據(jù)庫(kù)上。
所幸的是,有一種已知的模型能處理這個(gè)問(wèn)題。
熔斷器
這個(gè)想法不是很新的事情,2007年Michael Nygard發(fā)布了 Release It!后就慢慢流行了。熔斷器(Circuit breaking)的原理非常簡(jiǎn)單,我們會(huì)在熔斷器中封裝一個(gè)方法,當(dāng)監(jiān)測(cè)到失敗時(shí)進(jìn)行計(jì)數(shù),并且一旦失敗達(dá)到一定閾值時(shí),調(diào)用就會(huì)收到熔斷器直接返回的錯(cuò)誤碼,而不會(huì)調(diào)用到受到熔斷器保護(hù)的地方,例如數(shù)據(jù)庫(kù)等。如下圖所示,第一次supplier能正常服務(wù),但是第二次、第三次訪問(wèn)都是超時(shí)。達(dá)到熔斷器閾值后,第四次直接返回錯(cuò)誤碼,而不會(huì)將請(qǐng)求直接打給supplier:
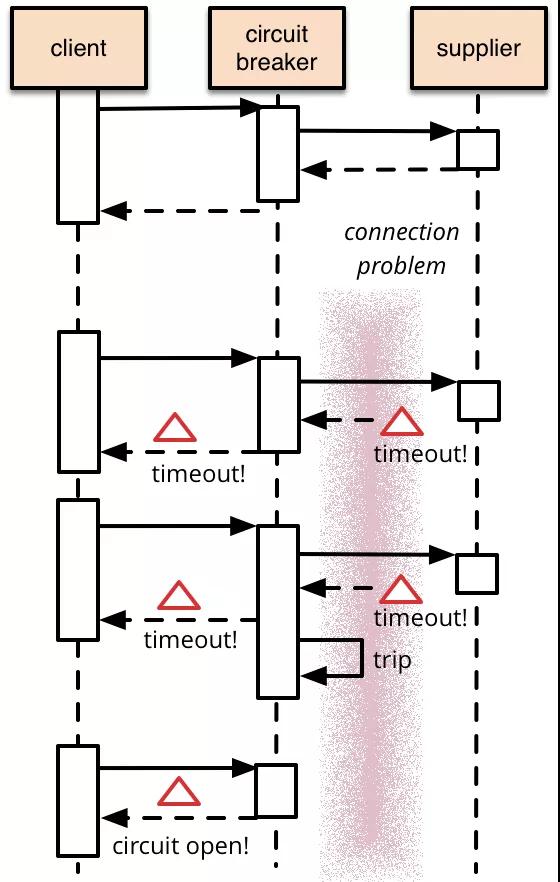
熔斷器是響應(yīng)式的,所以它不能阻止宕機(jī)。不過(guò)它可以防止連鎖故障的發(fā)生。而且它提供了一個(gè)終止開(kāi)關(guān),當(dāng)事態(tài)已經(jīng)徹底失控時(shí)可以開(kāi)啟。如果 Facebook 使用了熔斷機(jī)制,就可以避免讓整個(gè)網(wǎng)站癱瘓下線。2010年的時(shí)候熔斷器還不是很流行,不過(guò)今天已經(jīng)有很多熔斷的開(kāi)源組件,例如:Resilience4j, Istio和 Envoy。
4、學(xué)到了什么
這篇文章中談?wù)摿撕芏鄳?yīng)對(duì)緩存踩踏問(wèn)題的策略,以及其他的科技公司是如何使用這些策略的。那么facebook呢?他們從這次事故中學(xué)到了什么?以及他們采取了什么措施來(lái)防止事故再次發(fā)生?他們的工程師寫(xiě)了一篇文章:Under the hood: Broadcasting live video to millions,討論了他們對(duì)架構(gòu)所做的改進(jìn)。和本文我們提到的一樣,比如二級(jí)緩存。當(dāng)然,也提到了一些新的方法,比如 HTTP請(qǐng)求合并。總之,這篇文章非常值得一讀
5、寫(xiě)在最后
我相信理解緩存踩踏對(duì)系統(tǒng)的破壞性是非常有必要的,當(dāng)然,并不是說(shuō)每個(gè)團(tuán)隊(duì)必須馬上把這些策略用到他們的系統(tǒng)中。因?yàn)椋x擇何種策略要應(yīng)對(duì)緩存踩踏并不是一件容易的事情,它依賴你的實(shí)際用戶場(chǎng)景,架構(gòu),以及流量負(fù)載情況。但是了解緩存踩踏以及對(duì)可能的解決方案對(duì)您將來(lái)有所幫助,當(dāng)你以后面對(duì)類型問(wèn)題時(shí),能從容應(yīng)對(duì)。
原文地址:https://betterprogramming.pub/how-a-cache-stampede-caused-one-of-facebooks-biggest-outages-dbb964ffc8ed
本文轉(zhuǎn)載自微信公眾號(hào)「阿飛的博客」,可以通過(guò)以下二維碼關(guān)注。轉(zhuǎn)載本文請(qǐng)聯(lián)系阿飛的博客公眾號(hào)。