













這些線程安全的坑,你在工作中踩了么?
我們知道多線程能并發(fā)的處理多個任務,有效地提高復雜應用程序的性能,在實際開發(fā)中扮演著十分重要的角色
但是使用多線程也帶來了很多風險,并且由線程引起的問題往往在測試中難以發(fā)現(xiàn),到了線上就會造成重大的故障和損失
下面我會結合幾個實際案例,幫助大家在工作做規(guī)避這些問題
多線程問題
首先介紹下使用的多線程會有哪些問題
使用多線程的問題很大程度上源于多個線程對同一變量的操作權,以及不同線程之間執(zhí)行順序的不確定性
《Java并發(fā)編程實戰(zhàn)》這本書中提到了三種多線程的問題:安全性問題、活躍性問題和性能問題
安全性問題
例如有一段很簡單的扣庫存功能操作,如下:
- public int decrement(){
- return --count;//count初始庫存為10
- }
在單線程環(huán)境下,這個方法能正確工作,但在多線程環(huán)境下,就會導致錯誤的結果
--count看上去是一個操作,但實際上它包含三步(讀取-修改-寫入):
- 讀取count的值
- 將值減一
- 最后把計算結果賦值給count
如下圖展示了一種錯誤的執(zhí)行過程,當有兩個線程1、2同時執(zhí)行該方法時,它們讀取到count的值都是10,最后返回結果都是9;意味著可能有兩個人購買了商品,但庫存卻只減了1,這對于真實的生產環(huán)境是不可接受的
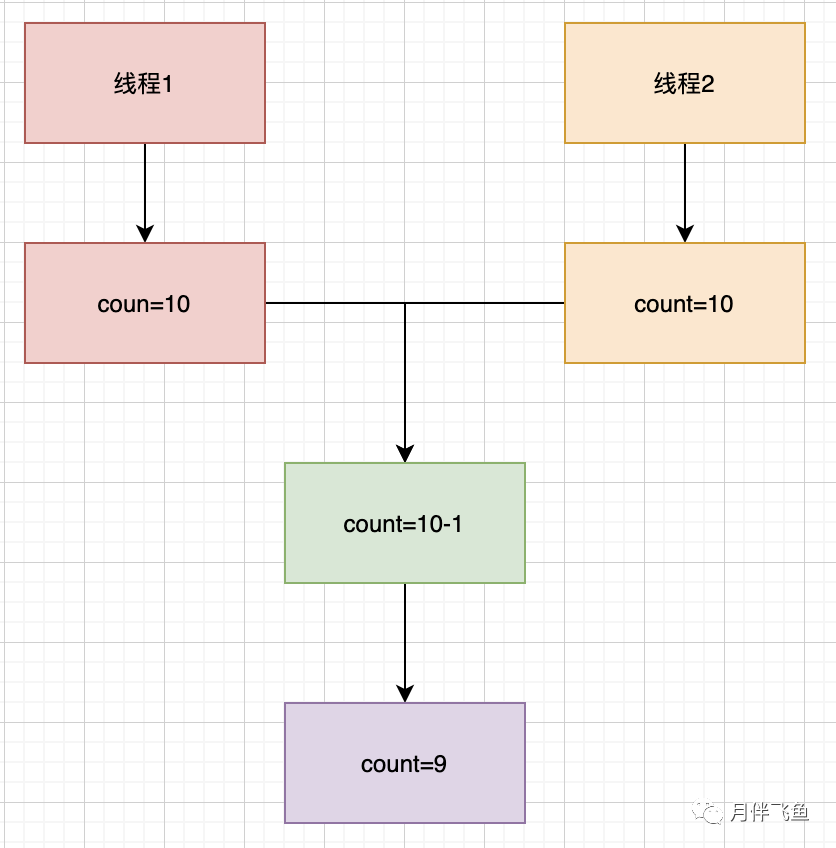
像上面例子這樣由于不恰當?shù)膱?zhí)行時序導致不正確結果的情況,是一種很常見的并發(fā)安全問題,被稱為競態(tài)條件
decrement()方法這個導致發(fā)生競態(tài)條件的代碼區(qū)被稱為臨界區(qū)
避免這種問題,需要保證讀取-修改-寫入這樣復合操作的原子性
在Java中,有很多方式可以實現(xiàn),比如使用synchronize內置鎖或ReentrantLock顯式鎖的加鎖機制、使用線程安全的原子類、以及采用CAS的方式等
活躍性問題
活躍性問題指的是,某個操作因為阻塞或循環(huán),無法繼續(xù)執(zhí)行下去
最典型的有三種,分別為死鎖、活鎖和饑餓
死鎖
最常見的活躍性問題是死鎖
死鎖是指多個線程之間相互等待獲取對方的鎖,又不會釋放自己占有的鎖,而導致阻塞使得這些線程無法運行下去就是死鎖,它往往是不正確的使用加鎖機制以及線程間執(zhí)行順序的不可預料性引起的

如何預防死鎖
1.盡量保證加鎖順序是一樣的
例如有A,B,C三把鎖。
- Thread 1的加鎖順序為A、B、C這樣的。
- Thread 2的加鎖順序為A、C,這樣就不會死鎖。
如果Thread2的加鎖順序為B、A或者C、A這樣順序就不一致了,就會出現(xiàn)死鎖問題。
2.盡量用超時放棄機制
Lock接口提供了tryLock(long time, TimeUnit unit)方法,該方法可以按照固定時長等待鎖,因此線程可以在獲取鎖超時以后,主動釋放之前已經獲得的所有的鎖。可以避免死鎖問題
活鎖
活鎖與死鎖非常相似,也是程序一直等不到結果,但對比于死鎖,活鎖是活的,什么意思呢?因為正在運行的線程并沒有阻塞,它始終在運行中,卻一直得不到結果
饑餓
饑餓是指線程需要某些資源時始終得不到,尤其是CPU 資源,就會導致線程一直不能運行而產生的問題。
在 Java 中有線程優(yōu)先級的概念,Java 中優(yōu)先級分為 1 到 10,1 最低,10 最高。
如果我們把某個線程的優(yōu)先級設置為 1,這是最低的優(yōu)先級,在這種情況下,這個線程就有可能始終分配不到 CPU 資源,而導致長時間無法運行。
性能問題
線程本身的創(chuàng)建、以及線程之間的切換都要消耗資源,如果頻繁的創(chuàng)建線程或者CPU在線程調度花費的時間遠大于線程運行的時間,使用線程反而得不償失,甚至造成CPU負載過高或者OOM的后果
舉例說明
線程不安全類
案例1
使用線程不安全集合(ArrayList、HashMap等)要進行同步,最好使用線程安全的并發(fā)集合
在多線程環(huán)境下,對線程不安全的集合遍歷進行操作時,可能會拋出ConcurrentModificationException的異常,也就是常說的fail-fast機制
下面例子模擬了多個線程同時對ArrayList操作,線程t1遍歷list并打印,線程t2向list添加元素
- List<Integer> list = new ArrayList<>();
- list.add(0);
- list.add(1);
- list.add(2); //list: [0,1,2]
- System.out.println(list);
- //線程t1遍歷打印list
- Thread t1 = new Thread(() -> {
- for(int i : list){
- System.out.println(i);
- }
- });
- //線程t2向list添加元素
- Thread t2 = new Thread(() -> {
- for(int i = 3; i < 6; i++){
- list.add(i);
- }
- });
- t1.start();
- t2.start();

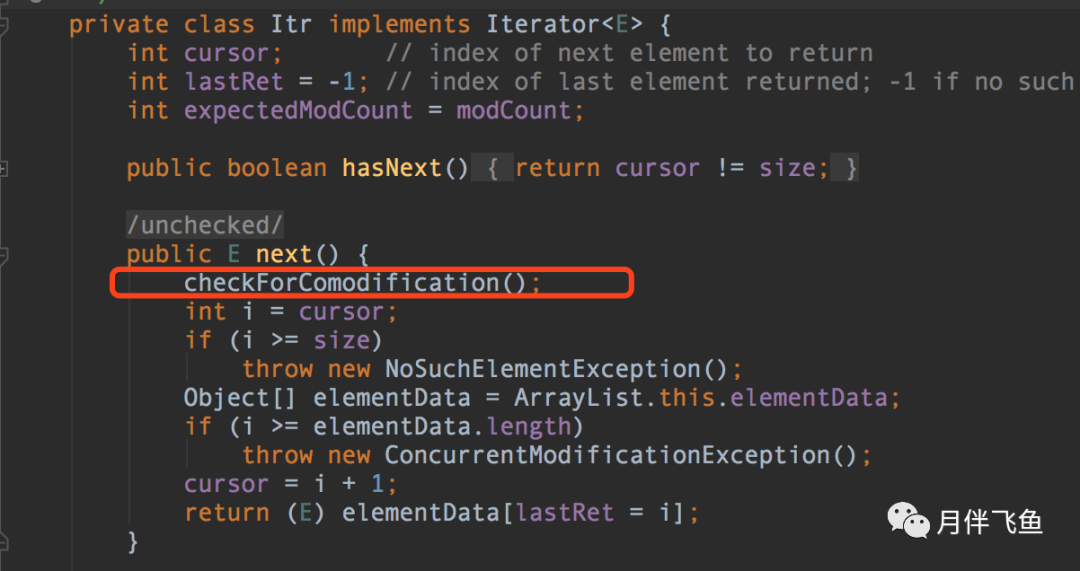
進到拋異常的ArrayList源碼中,可以看到遍歷ArrayList是通過內部實現(xiàn)的迭代器完成的
調用迭代器的next()方法獲取下一個元素時,會先通過checkForComodification()方法檢查modCount和expectedModCount是否相等,若不相等則拋出ConcurrentModificationException

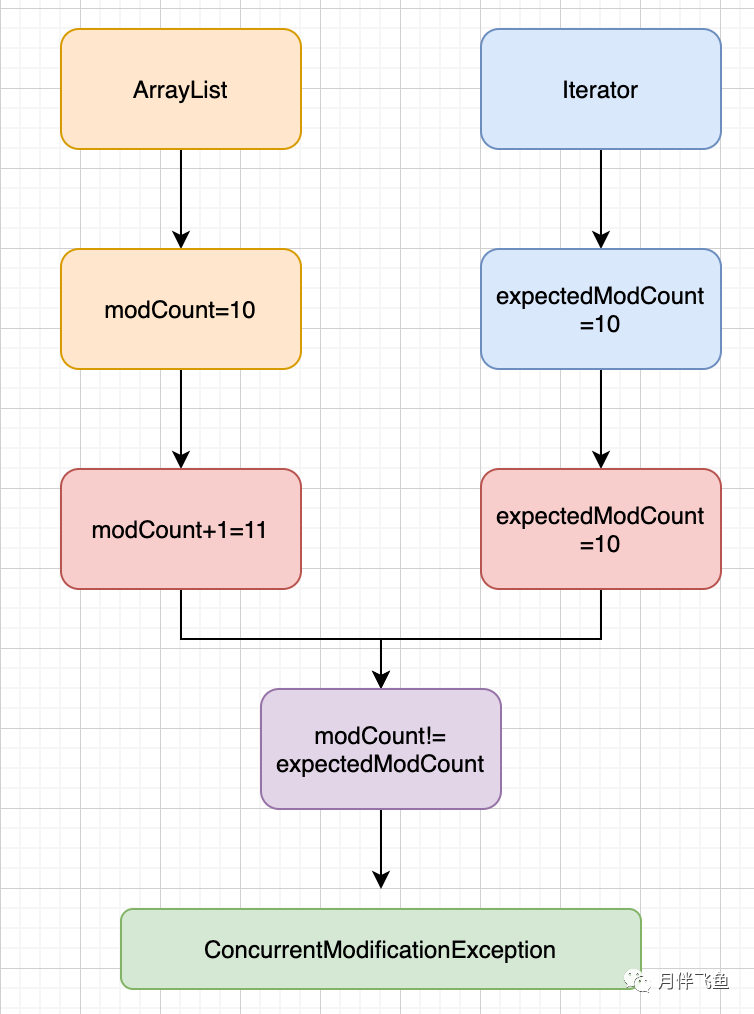
modCount是ArrayList的屬性,表示集合結構被修改的次數(shù)(列表長度發(fā)生變化的次數(shù)),每次調用add或remove等方法都會使modCount加1
expectedModCount是迭代器的屬性,在迭代器實例創(chuàng)建時被賦與和遍歷前modCount相等的值(expectedModCount=modCount)
所以當有其他線程添加或刪除集合元素時,modCount會增加,然后集合遍歷時expectedModCount不等于modCount,就會拋出異常
使用加鎖機制操作線程不安全的集合類
- List<Integer> list = new ArrayList<>();
- list.add(0);
- list.add(1);
- list.add(2);
- System.out.println(list);
- //線程t1遍歷打印list
- Thread t1 = new Thread(() -> {
- synchronized (list){ //使用synchronized關鍵字
- for(int i : list){
- System.out.println(i);
- }
- }
- });
- //線程t2向list添加元素
- Thread t2 = new Thread(() -> {
- synchronized (list){
- for(int i = 3; i < 6; i++){
- list.add(i);
- System.out.println(list);
- }
- }
- });
- t1.start();
- t2.start();
如上面代碼,用synchronized關鍵字鎖住對list的操作,就不會拋出異常。不過用synchronized相當于把鎖住的代碼塊串行化,性能上是不占優(yōu)勢的
推薦使用線程安全的并發(fā)工具類
JDK1.5加入了很多線程安全的工具類供使用,如CopyOnWriteArrayList、ConcurrentHashMap等并發(fā)容器
日常開發(fā)中推薦使用這些工具類來實現(xiàn)多線程編程
案例2
不要將SimpleDateFormat作為全局變量使用
SimpleDateFormat實際上是一個線程不安全的類,其根本原因是SimpleDateFormat的內部實現(xiàn)對一些共享變量的操作沒有進行同步
- public static final SimpleDateFormat SDF_FORMAT = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
- public static void main(String[] args) {
- //兩個線程同時調用SimpleDateFormat.parse方法
- Thread t1 = new Thread(() -> {
- try {
- Date date1 = SDF_FORMAT.parse("2019-12-09 17:04:32");
- } catch (ParseException e) {
- e.printStackTrace();
- }
- });
- Thread t2 = new Thread(() -> {
- try {
- Date date2 = SDF_FORMAT.parse("2019-12-09 17:43:32");
- } catch (ParseException e) {
- e.printStackTrace();
- }
- });
- t1.start();
- t2.start();
- }

建議將SimpleDateFormat作為局部變量使用,或者配合ThreadLocal使用
最簡單的做法是將SimpleDateFormat作為局部變量使用即可
但如果是在for循環(huán)中使用,會創(chuàng)建很多實例,可以優(yōu)化下配合ThreadLocal使用
- //初始化
- public static final ThreadLocal<SimpleDateFormat> SDF_FORMAT = new ThreadLocal<SimpleDateFormat>(){
- @Override
- protected SimpleDateFormat initialValue() {
- return new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
- }
- };
- //調用
- Date date = SDF_FORMAT.get().parse(wedDate);
推薦使用Java8的LocalDateTime和DateTimeFormatter
LocalDateTime和DateTimeFormatter是Java 8引入的新特性,它們不僅是線程安全的,而且使用更方便
推薦在實際開發(fā)中用LocalDateTime和DateTimeFormatter替代Calendar和SimpleDateFormat
- DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
- LocalDateTime time = LocalDateTime.now();
- System.out.println(formatter.format(time));
鎖的正確釋放
假設有這樣一段偽代碼:
- Lock lock = new ReentrantLock();
- ...
- try{
- lock.tryLock(timeout, TimeUnit.MILLISECONDS)
- //業(yè)務邏輯
- }
- catch (Exception e){
- //錯誤日志
- //拋出異常或直接返回
- }
- finally {
- //業(yè)務邏輯
- lock.unlock();
- }
- ...
這段代碼中在finally代碼塊釋放鎖之前,執(zhí)行了一段業(yè)務邏輯
假如不巧這段邏輯中依賴服務不可用導致占用鎖的線程不能成功釋放鎖,會造成其他線程因無法獲取鎖而阻塞,最終線程池被打滿的問題
所以在釋放鎖之前;finally子句中應該只有對當前線程占有的資源(如鎖、IO流等)進行釋放的一些處理
還有就是獲取鎖時設置合理的超時時間
為了避免線程因獲取不到鎖而一直阻塞,可以設置一個超時時間,當獲取鎖超時后,線程可以拋出異常或返回一個錯誤的狀態(tài)碼。其中超時時間的設置也要合理,不應過長,并且應該大于鎖住的業(yè)務邏輯的執(zhí)行時間。
正確使用線程池
案例1
不要將線程池作為局部變量使用
- public void request(List<Id> ids) {
- for (int i = 0; i < ids.size(); i++) {
- ExecutorService threadPool = Executors.newSingleThreadExecutor();
- }
- }
在for循環(huán)中創(chuàng)建線程池,那么每次執(zhí)行該方法時,入參的list長度有多大就會創(chuàng)建多少個線程池,并且方法執(zhí)行完后也沒有及時調用shutdown()方法將線程池銷毀
這樣的話,隨著不斷有請求進來,線程池占用的內存會越來越多,就會導致頻繁fullGC甚至OOM。每次方法調用都創(chuàng)建線程池是很不合理的,因為這和自己頻繁創(chuàng)建、銷毀線程沒有區(qū)別,不僅沒有利用線程池的優(yōu)勢,反而還會耗費線程池所需的更多資源
所以盡量將線程池作為全局變量使用
案例2
謹慎使用默認的線程池靜態(tài)方法
- Executors.newFixedThreadPool(int); //創(chuàng)建固定容量大小的線程池
- Executors.newSingleThreadExecutor(); //創(chuàng)建容量為1的線程池
- Executors.newCachedThreadPool(); //創(chuàng)建一個線程池,線程池容量大小為Integer.MAX_VALUE
上述三個默認線程池的風險點:
newFixedThreadPool創(chuàng)建的線程池corePoolSize和maximumPoolSize值是相等的,使用的阻塞隊列是LinkedBlockingQueue。
newSingleThreadExecutor將corePoolSize和maximumPoolSize都設置為1,也使用的LinkedBlockingQueue
LinkedBlockingQueue默認容量為Integer.MAX_VALUE=2147483647,對于真正的機器來說,可以被認為是無界隊列
- newFixedThreadPool和newSingleThreadExecutor在運行的線程數(shù)超過corePoolSize時,后來的請求會都被放到阻塞隊列中等待,因為阻塞隊列設置的過大,后來請求不能快速失敗而長時間阻塞,就可能造成請求端的線程池被打滿,拖垮整個服務。
newCachedThreadPool將corePoolSize設置為0,將maximumPoolSize設置為Integer.MAX_VALUE,阻塞隊列使用的SynchronousQueue,SynchronousQueue不會保存等待執(zhí)行的任務
- 所以newCachedThreadPool是來了任務就創(chuàng)建線程運行,而maximumPoolSize相當于無限的設置,使得創(chuàng)建的線程數(shù)可能會將機器內存占滿。
所以需要根據(jù)自身業(yè)務和硬件配置創(chuàng)建自定義線程池
線程數(shù)建議
線程池corePoolSize數(shù)量設置建議:
1.CPU密集型應用
CPU密集的意思是任務需要進行大量復雜的運算,幾乎沒有阻塞,需要CPU長時間高速運行。
一般公式:corePoolSize=CPU核數(shù)+1個線程。JVM可運行的CPU核數(shù)可以通過Runtime.getRuntime().availableProcessors()查看。
2.IO密集型應用
IO密集型任務會涉及到很多的磁盤讀寫或網絡傳輸,線程花費更多的時間在IO阻塞上,而不是CPU運算。一般的業(yè)務應用都屬于IO密集型。
參考公式:最佳線程數(shù)=CPU數(shù)/(1-阻塞系數(shù)); 阻塞系數(shù)=線程等待時間/(線程等待時間+CPU處理時間) 。
IO密集型任務的CPU處理時間往往遠小于線程等待時間,所以阻塞系數(shù)一般認為在0.8-0.9之間,以4核單槽CPU為例,corePoolSize可設置為 4/(1-0.9)=40。當然具體的設置還是要根據(jù)機器實際運行中的各項指標而定。
本文轉載自微信公眾號「月伴飛魚」,作者日常加油站。轉載本文請聯(lián)系月伴飛魚公眾號。






















