把「我的世界」馬賽克變成逼真大片,英偉達又出黑科技
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
先來看一張海島大片:

這可不是哪個攝影師的杰作,而是出自GANcraft之手。
原圖是「我的世界」中一個馬賽克畫質的場景:

這下「我的世界」真的變成了,我的世界!
GANcraft由英偉達和康奈爾大學合作完成,它是一個無監督3D神經渲染框架,可以將大型3D塊狀世界生成為逼真圖像。
空前的真實感
究竟有多逼真?和與其他模型對比來看。
以下是在兩個場景中,分別使用MUNIT、GauGAN用到的SPADE、wc-vid2vid,以及NSVF-W(NSVF+NeRF-W)生成的效果。

再感受下GANcraft的效果:(色彩和畫質有所壓縮)

通過對比可以看到:
諸如MUNIT和SPADE這類im2im(圖像到圖像轉換)方法,無法保持視角的一致性,這是因為模型不了解3D幾何形狀,而且每個幀是獨立生成的。
wc-vid2vid產生了視圖一致的視頻,但是由于塊狀幾何圖形和訓練測試域的誤差累積,圖像質量隨著時間迅速下降。
NSVF-W也可以產生與視圖一致的輸出,但是看起來色彩暗淡,且缺少細節。
而GANcraft生成的圖像,既保持了視圖一致性,同時具有高質量。
這是怎么做到的?
原理概述
GANcraft中神經渲染的使用保證了視圖的一致性,而創新的模型架構和訓練方案實現了空前的真實感。
具體而言,研究人員結合了3D體積渲染器和2D圖像空間渲染器,使用Hybird體素條件神經渲染方法。
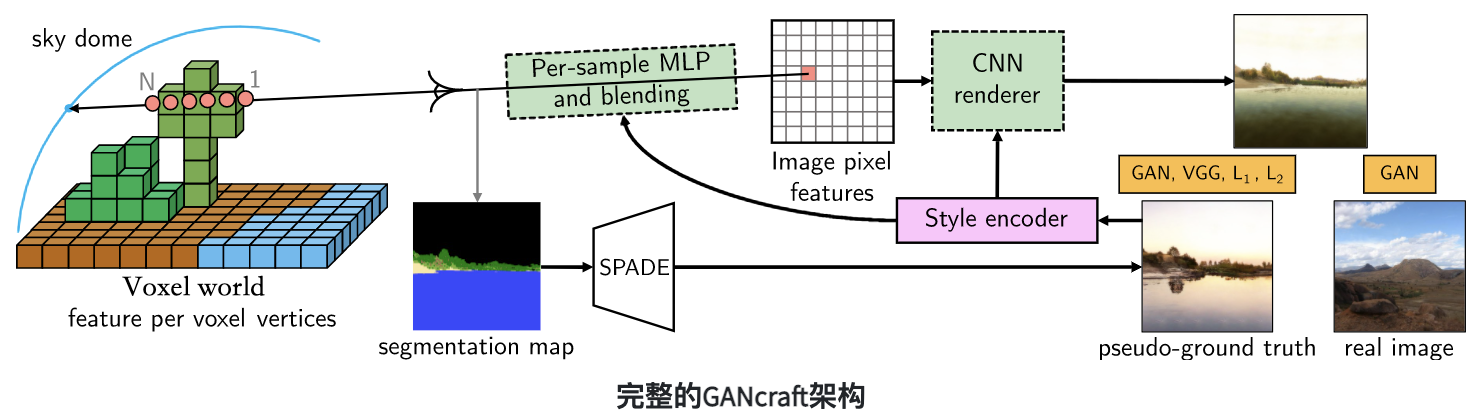
首先,定義一個以體素(即體積元素)為邊界的神經輻射場,并且為塊的每個角,分配一個可學習的特征向量;
再使用三線性插值法,在體素內的任意位置定義位置代碼,把世界表示為一個連續的體積函數;并且每個塊都被分配了一個語義標簽,如泥土、草地或水。
然后,使用MLP隱式定義輻射場,將位置代碼、語義標簽和共享的樣式代碼作為輸入,并生成點特征(類似于輻射)及其體積密度。
最后給定相機參數,通過渲染輻射場獲得2D特征圖,再利用CNN轉換為圖像。

雖然能夠建立體素條件神經渲染模型,但是沒有圖像能用作ground truth,為此,研究人員采用了對抗訓練方式。
但是「我的世界」不同于真實世界,其街區通常具有完全不同的標簽分布,比如:場景完全被雪或水覆蓋,或是多個生物群落出現在一個區域。
在隨機采樣時,使用互聯網照片進行對抗訓練,會生成脫離實際的結果:

因此研究人員生成Pseudo-ground truth,用來進行訓練。
使用預訓練的SPADE模型,通過2D語義分割蒙版,獲得具有相同語義的Pseudo-ground truth圖像。
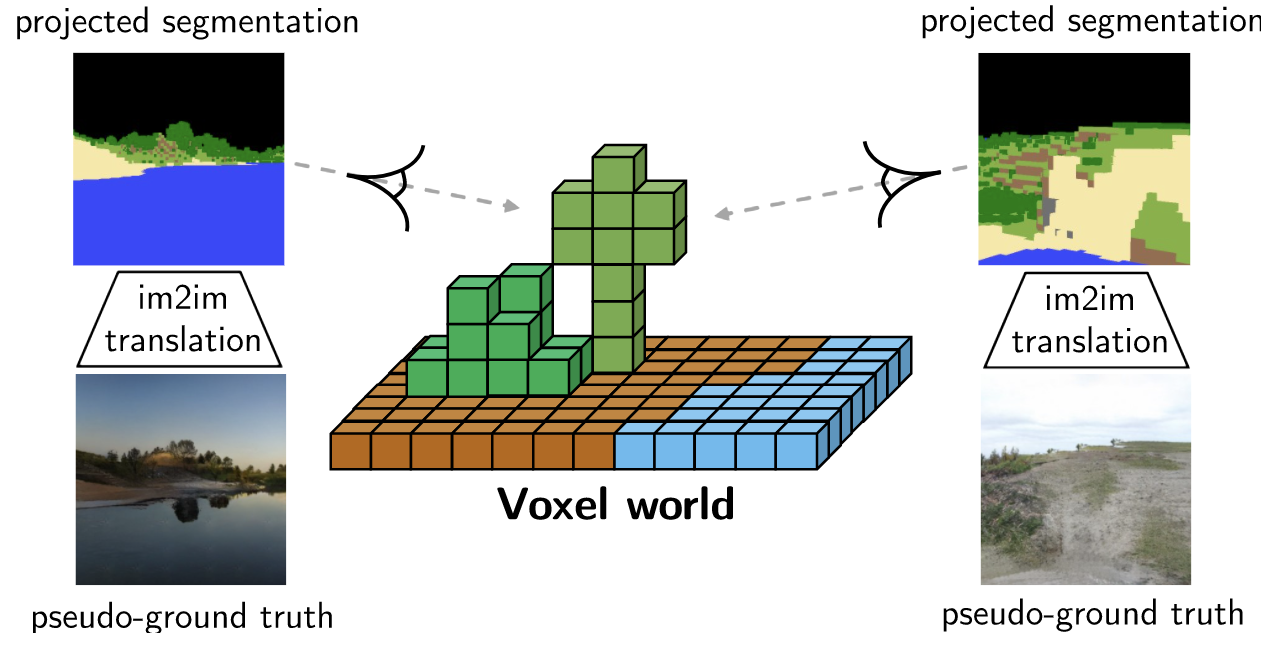
這不僅減少了標簽和圖像分配的不匹配,而且還能用更強的損失,來進行更快、更穩定的訓練。生成效果得到了顯著改善:

此外,GANcraft還允許用戶控制場景語義和輸出風格:

其介紹頁中提到:它將每個Minecraft玩家變成了3D藝術家!
并且,簡化了復雜風景場景的3D建模過程,無需多年的專業知識。
GANcraft即將開源,感興趣的讀者可戳鏈接了解詳情~
參考鏈接:
[1]https://nvlabs.github.io/GANcraft/
[2]https://arxiv.org/abs/2104.07659
[3]https://news.ycombinator.com/item?id=26833972