













北大、字節跳動等利用增量學習提出超像素分割模型LNSNet
為解決在線學習所帶來的災難性遺忘問題,北大等研究機構提出了采用梯度調節模塊(GRM),通過訓練權重在特征重建時的作用效果及像素的空間位置先驗,調節反向傳播時各權重的梯度,以增強模型的記憶性的超像素分割模型 LNSNet。
該研究已被 CVPR 2021 接收,主要由朱磊和佘琪參與討論和開發,北京大學分子影像實驗室盧閆曄老師給予指導。

論文鏈接:
https://arxiv.org/abs/2103.10681
項目開源代碼:
https://github.com/zh460045050/LNSNet
實驗室鏈接:http://www.milab.wiki
一、簡介
圖像分割是計算機視覺的基本任務之一,在自動駕駛、安防安保、智能診療等任務中都有著重要應用。超像素分割作為圖像分割中的一個分支,旨在依賴于圖像的顏色信息及空間關系信息,將圖像高效的分割為遠超于目標個數的超像素塊,達到盡可能保留圖像中所有目標的邊緣信息的目的,從而更好的輔助后續視覺任務(如目標檢測、目標跟蹤、語義分割等)。
基于傳統機器學習的超像素分割方法會將超像素分割看作像素聚類問題,并通過限制搜索空間的策略,提高超像素的生成效率(如 SLIC、SNIC、MSLIC、IMSLIC 等方法)。然而,這些方法大多依賴 RGB 或 LAB 顏色空間信息對像素進行聚類,而缺乏對高層信息的考量。
雖然一些超像素分割方法(LRW、DRW、ERS、LSC)通過構建圖模型的方式,將原本 5 維的顏色及空間信息依據四鄰域或八鄰域節點的相似性關系豐富至 N 維,來獲取更好的特征表達。進而使用隨機游走或譜聚類等方式進行超像素分割,但這些方法運行效率較差。
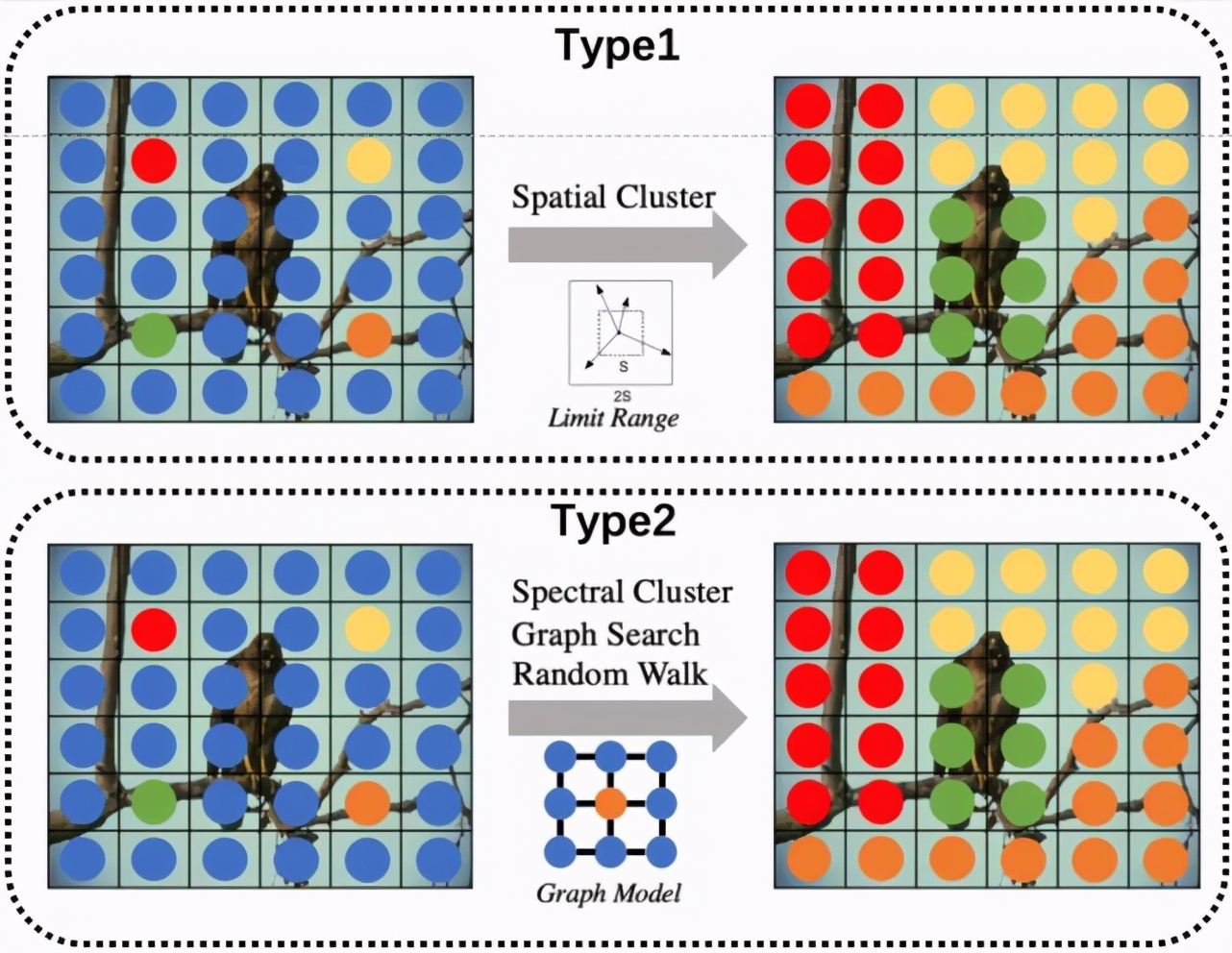
采用卷積神經網絡進行超像素分割(SEAL、SSN、S-FCN)大多拋棄了傳統超像素方法的無監督的廣義分割模式,轉而采用大量的區域級的分割標注對卷積神經網絡進行離線訓練指導超像素的生成。這種基于標注的訓練模式導致生成的超像素通常包含較多了高層語義信息,因此限制了超像素分割方法的泛化性及靈活性。
此外,這種超像素分割模式也無法較好的應用于缺乏分割標注的視覺任務,如目標跟蹤、弱監督圖像分割等。近期已有工作(RIM)借鑒深度聚類的模式無監督地運用神經網絡進行廣義超像素分割,然而該方法需要依據每一張輸入圖像訓練一個特定的卷積神經網絡進行像素聚類,因此極大地增加了超像素分割的運算時間。
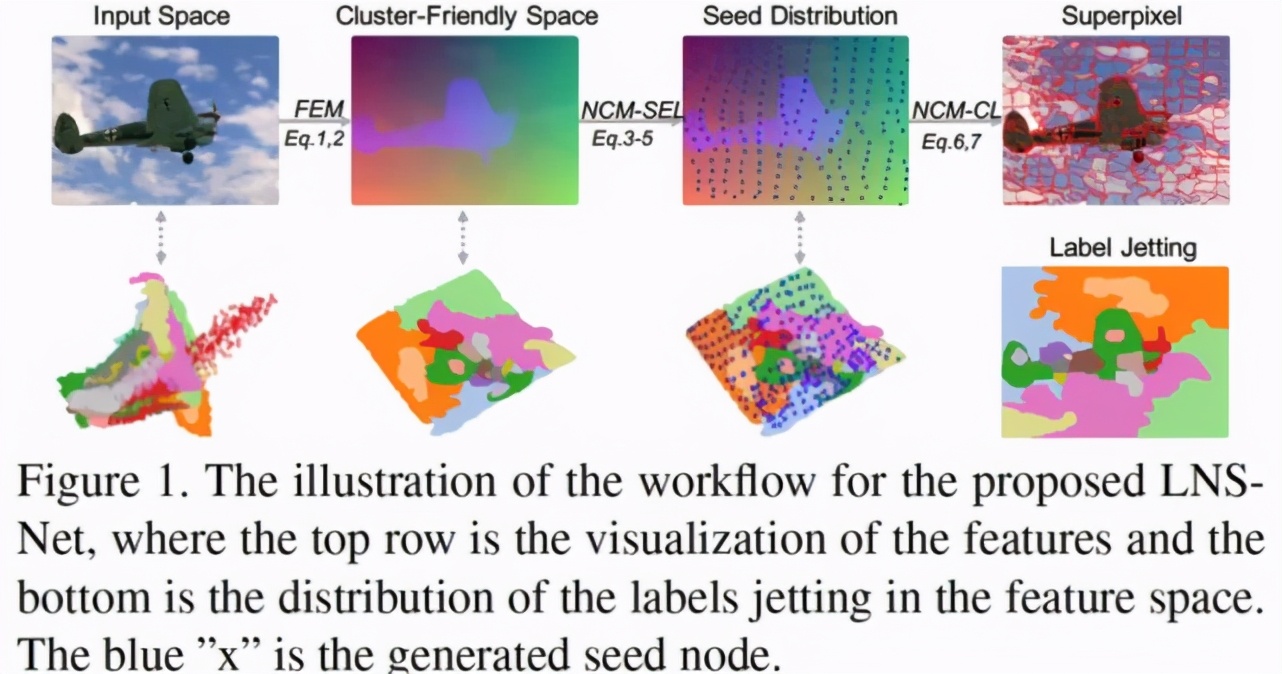
因此為保證超像素分割既可以更好的借助深度學習進行有效的特征提取,又可以同時兼顧傳統超像素分割方法高效、靈活、遷移性強的特點,本研究從持續學習的視角看待超像素分割問題,并提出了一種新型的超像素分割模型可以更好的支持無監督的在線訓練模式 (online training)。考慮到超像素分割作為廣義分割問題需要更關注圖像的細節信息,本模型摒棄了其他超像素分割網絡中采用的較深而復雜的卷積神經網絡結構,而選用了較為輕量級的特征提取模塊(FEM),并提出了非迭代聚類模塊(NCM)通過自動選取種子節點,避免了超像素分割方法中的聚類中心的迭代更新,極大地降低了超像素分割的空間復雜度與時間復雜度(相比SSN參數量降低近20倍同時運算時間加快了近 4倍)。
為解決在線學習所帶來的災難性遺忘問題,本模型采用了梯度調節模塊(GRM),通過訓練權重在特征重建時的作用效果及像素的空間位置先驗,調節反向傳播時各權重的梯度,以增強模型的記憶性及泛化性。
二、訓練框架設計
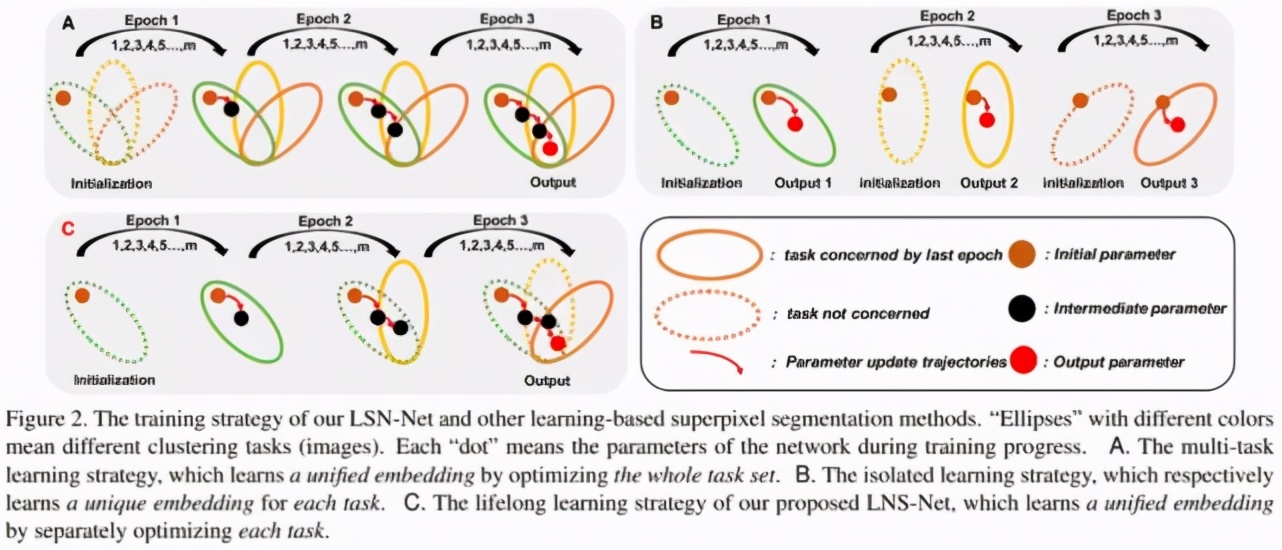
總的來看,在特定圖像 Ii 上進行廣義超像素分割的本質,可以看作在該圖像域中的進行像素聚類任務 Ti。因此,對于包含 n 張圖像的圖像集 I=,在該圖像集上的超像素分割任務可以看作任務集 T=。在此條件下,我們可以將當前基于深度學習的超像素分割方法看作以下兩種策略:
① 基于深度聚類模式的 RIM 超像素分割方法可以看作是一種單任務學習策略。如圖 2B 所示,該策略針對任務集中每一個特定任務 Ti 找到一個最優的參數空間,因此整個任務集 T 來說,該任務需要訓練得到 n 個各不相同的參數空間用以提取聚類特征。這種做法極大地增加了模型訓練及存儲的消耗,導致其運算效率極低。
② 其他超像素分割網絡的訓練模式(SEAL、SSN、S-FCN)則可以看作一種多任務學習策略。如圖 2A 所示,該策略在分割標注的指導下得到一個對于整個任務集 T 通用參數空間。雖然這種策略僅需要得到一個參數空間,但該方式仍需要離線的進行模型訓練,且訓練過程都需要維護整個圖像集 I。此外,這些方法對于分割標簽的需求也導致其過于關注提取更高層語義特征,而非關注對于廣義超像素分割來說更重要的低層顏色特征與空間特征的融合,限制了卷積神經網絡的遷移性及靈活性。
與這兩種方式不同,本文希望利用持續學習策略,保證超像素分割方法既可以既借助卷積神經進行更為有效的特征提取,又同時兼顧傳統超像素分割方法高效、靈活、遷移性強的特點。
如圖 2C 所示,本文所采用的持續學習策略通過逐一針對特定圖像 Ii 進行訓練,保證最終可以得到一個適用于整個任務集 T 的通用參數空間,這要求了卷積神經網絡需要具備記憶歷史任務的能力,也就是解決持續學習中的災難性遺忘問題。本模型的具體訓練流程如圖 3 所示,在第 i 輪的訓練過程中,我們僅考慮單一的任務 Ti 對模型進行擬合。其中,特征提取模塊 FCM 用于生成聚類所需的聚類特征,無迭代聚類模塊 NCM 進而利用聚類特征進行聚類得到超像素分割結果。梯度調節模塊 GRM 則用以調節反向傳播時 FCM 參數的梯度,保證模型可以更好的記憶歷史任務 Ti-1,Ti-2,….. , T1。
三、模型結構及損失函數設計
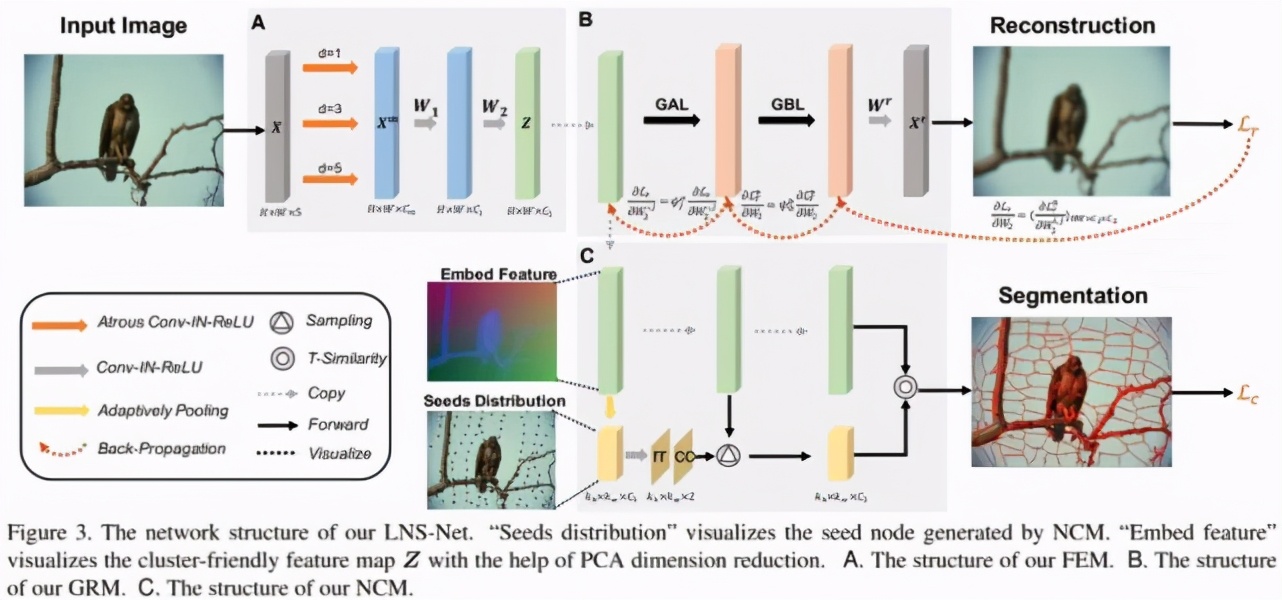
本文提出的模型結構如圖 3 所示,其中考慮到超像素分割作為廣義分割問題更為關注圖像的細節信息與空間信息的融合。因此本模型在特征提取模塊 FEM(圖 3A)部分摒棄了其他超像素分割網絡中采用的較深而復雜的卷積神經網絡結構,轉而使用較為輕量級的特征提取模塊,以減少在特征提取過程中圖像細節信息的損失。具體來看,我們首先將輸入圖像顏色信息 RGB/LAB 及空間信息 XY 進行 Concat 得到 5 維的輸入張量 X。隨后我們使用三個不同空洞率 (d=1,3,5) 的空洞卷積進行多尺度的特征提取,并采用兩個 3x3 卷積模塊進行多尺度特征融合,進而得到用以進行聚類的輸出特征圖 Z:
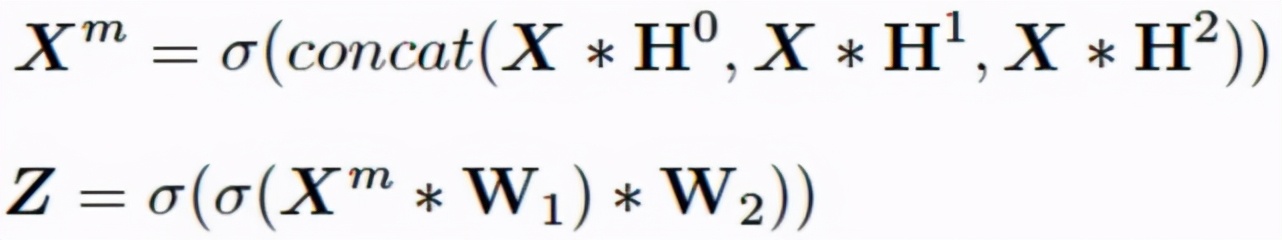
接著,進一步增加過程的運算效率,我們提出了無迭代聚類模塊 NCM(圖 3C)通過生成種子節點相對于網格中心的橫縱坐標偏移量,保證種子節點在具有較強空間緊湊程度的前提下,預測相應超像塊的種子節點,并依據其與各像素聚類特征間的 T 相似性進行像素聚類。該模塊首先將圖像按照超像素個數進行網格劃分,進而對屬于同一網格的位置進行空間池化操作,得到空間尺寸等于超像素個數的低分辨特征圖作為網格的特征 Zk。隨后,我們將 Zk 輸入 out channel 為 2 的 1x1 卷積得到種子節點相對于網格中心的橫縱偏移量△r,△c,并將此疊加至網格中心坐標 Sc 最終的超像素種子節點:
隨后,我們利用 T - 分布核函數計算種子節點特征與其余像素特征的相似性,并以此為依據得到最終的像素聚類結果 L,也就是輸出超像素塊。
最后,梯度調節模塊 GRM(圖 3B)首先利用像素聚類特征進行對輸入圖像及其各像素的空間信息進行重建。其中梯度自適應層(GAL)依據重建結果計算 FEM 中各通道對于當前任務的擬合程度 g(W^r),具體來看,我們分別依據重建權重 W^r 判斷各 Z 中特征通道分別在顏色信息和空間位置復原中的重要性,并利用二者乘積表示該通道的擬合程度:
隨后,在訓練過程中 GAL 通過維護記憶矩陣 m 用以記憶各通道在前序任務中的擬合程度。
隨后在反向傳播過程中,我們對各通道所對應的 FEM 中權重矩陣依據前序任務的重要程度構建調節率φ^a,用以調節對各通道所對應權重的梯度:
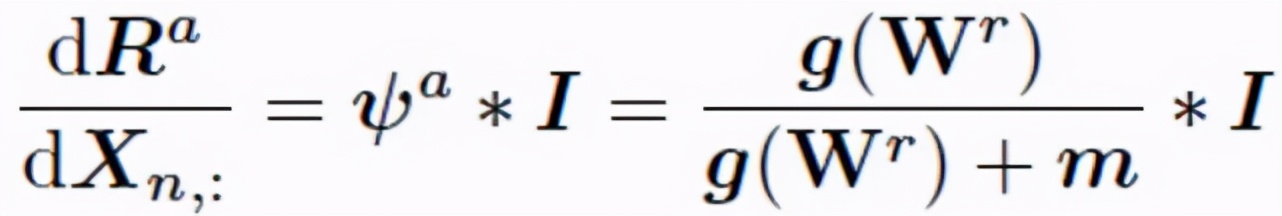
該調節率可以保證對于歷史任務擬合程度較好的權重具有較小的梯度,從而避免對于在前序任務中擬合程度高而在當前任務中擬合程度低的權重在反向傳播過程中受到污染,進而防止 FEM 過擬合當前任務造成對前序任務的造成災難性遺忘。此外,GRM 還采用了梯度雙向層(GBL)借助邊緣先驗信息使得平滑位置超像素塊可以更多的關注空間信息,而紋理豐富位置超像素塊可以更多考慮顏色信息,達到減少冗余超像素塊、增強邊緣擬合性的目的。
模型訓練的損失函數包含兩個部分,其中第一個部分為重建損失 Lr。該部分通過 MSE 損失保證聚類特征可以重建回初始圖像及各像素對應的空間位置信息,從而使得聚類特征可以更好的對空間信息及顏色信息進行融合。第二部分為聚類損失 Lc,該部分在 DEC 聚類損失的基礎上增加了空間距離約束。該約束可以在保證各超像素塊中像素類內相似性大的同時,使得每一像素更趨向于被分配到與其空間距離前 k 近的種子節點所在超像素中,從而保證分割結果中超像素塊的緊湊程度。

四、實驗
總的來看我們的方法相比于 SOTA 的超像素分割方法,具有更高的效率及可遷移性。
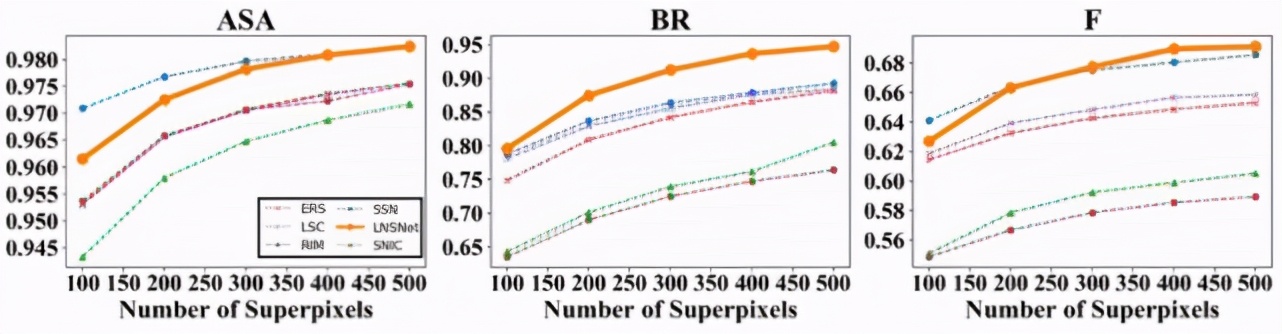
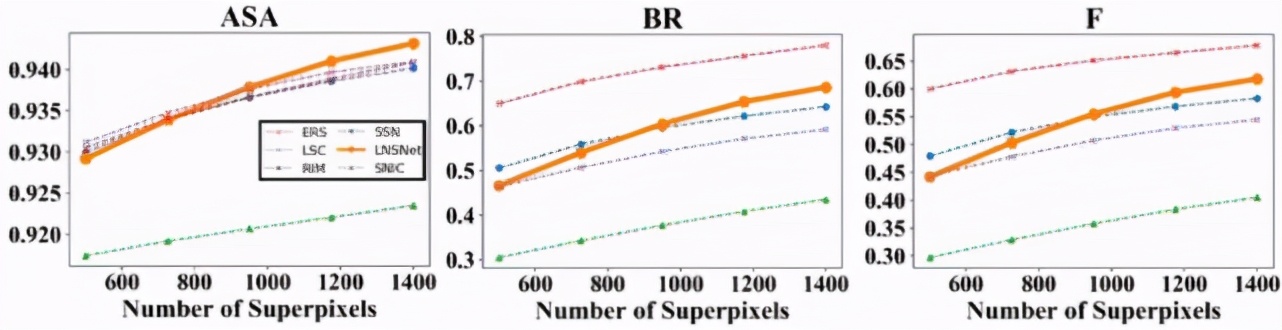
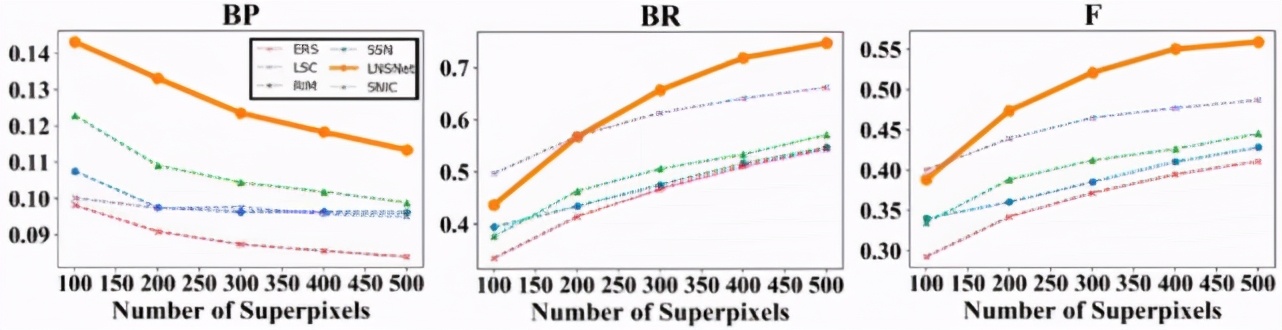
首先,我們在 BSDS 數據集上進行了實驗,可以看到我們提出的超像素分割策略在 ASA、BR、F 等常用超像素評價指標中都遠高于其余無監督的超像素分割方法(包括傳統方法 SLIC、LSC、ERS,RIM)。此外,相比于依賴分割標簽的有監督超像素分割方法 SSN,由于我們的方法在訓練過程中無法感知到高層語義信息,導致分割結果會產生相對較多的冗余超像素塊,這點造成了我們的方法的分割精確性較低,因此在 ASA 及 F 指標中略低于 SSN。然而這一特點也使得我們的模型具有更好的分割召回率,對于一些復雜場景中的模糊邊緣的擬合性更好,因此我們的方法可以取得更高的 BR 指標
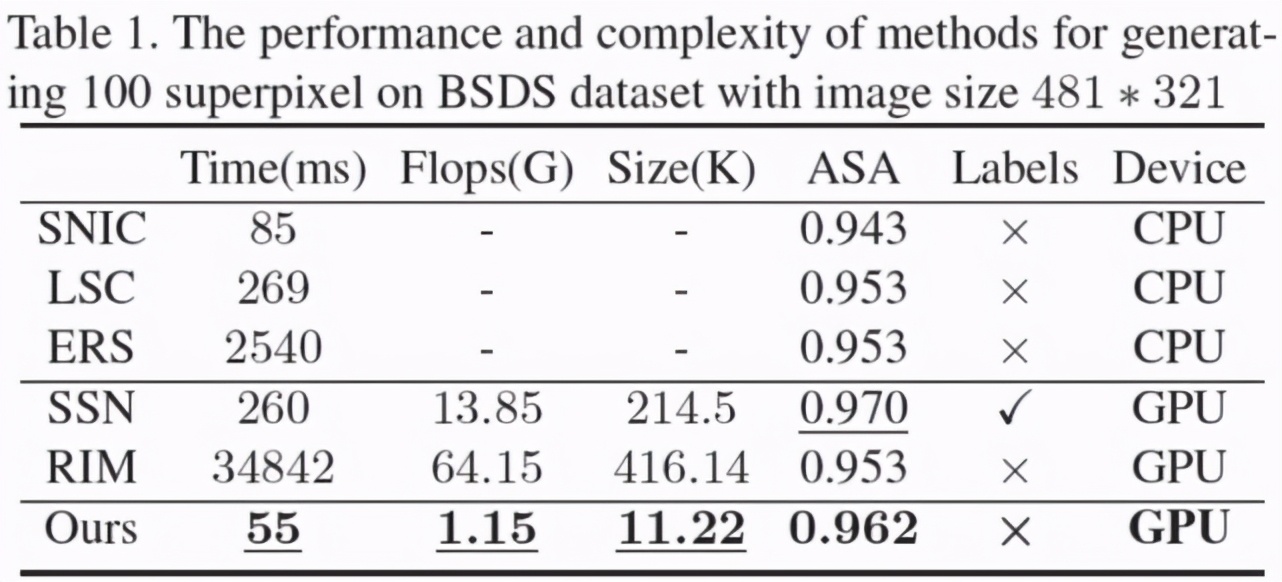
此外,由于使用了更為輕量級的特征提取器,并采用無迭代的聚類模式,我們模型在時間、空間復雜度上遠低于其余基于卷積神經網絡的超像素分割方法。此外,我們也將 BSDS 數據集中訓練好的超像素分割模型應用在醫學影像中進行實驗,以測試各超像素分割模型的遷移性。可以看到,無論是對于眼底熒光造影中眼底血管分割數據集(DRIVE)還是 OCT 影像中視網膜層分割數據集(DME),我們的模型都比其他基于卷積神經網絡分割模型具有更好的遷移性。
【責任編輯:張燕妮 TEL:(010)68476606】




























