













北大、KAUST、字節聯合提出“可逆擴散模型”賦能圖像重建,代碼已開源!
本篇文章來自公眾號粉絲投稿,論文提出了一種可逆擴散模型(Invertible Diffusion Models,IDM)。這一方法通過引入(1)端到端的訓練框架與(2)可逆網絡設計,有效提升了圖像重建的性能與效率。
一、論文信息
- 論文標題:Invertible Diffusion Models for Compressed Sensing
- 論文作者:Bin Chen(陳斌), Zhenyu Zhang(張振宇), Weiqi Li(李瑋琦), Chen Zhao(趙琛), Jiwen Yu(余濟聞), Shijie Zhao(趙世杰), Jie Chen(陳杰) and Jian Zhang(張健)
- 作者單位:北京大學信息工程學院、阿卜杜拉國王科技大學、字節跳動
- 發表刊物:IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
- 發表時間:2025年2月5日
- 正式版本:https://ieeexplore.ieee.org/document/10874182
- ArXiv版本:https://arxiv.org/abs/2403.17006
- 開源代碼:https://github.com/Guaishou74851/IDM
二、任務背景
擴散模型作為當前非常知名且強大的生成模型之一,已在圖像重建任務中展現出極大的潛力。擴散模型的基本實現方式是在訓練階段構建一個噪聲估計網絡(通常是一個UNet),并在推理階段通過迭代的去噪和加噪過程完成圖像生成與重建。然而,如何進一步提升擴散模型在圖像重建中的性能與效率,仍然是業界探索的重點問題。
當我們將擴散模型應用于圖像重建任務時,面臨兩個關鍵挑戰:
- 挑戰一:“噪聲估計”任務與“圖像重建”任務之間的偏差。擴散模型中的深度神經網絡主要針對“噪聲估計”任務(即,從當前變量中估計出噪聲)得到最優化,而非“圖像重建”任務(即,從低質量的觀測數據中預測原始圖像)本身。這可能導致其圖像重建性能存在進一步提升的空間。
- 挑戰二:推理速度慢、效率低。盡管擴散模型能夠生成較為真實的圖像,但其推理過程往往需要大量的迭代步驟,運行時間長,計算開銷大,不利于實際應用。
針對這兩個挑戰,本文提出了一種可逆擴散模型(Invertible Diffusion Models,IDM)。這一方法通過引入(1)端到端的訓練框架與(2)可逆網絡設計,有效提升了圖像重建的性能與效率。
三、主要貢獻
我們的方法在圖像重建任務中帶來了兩個主要創新:
1.端到端的擴散采樣圖像重建學習框架
傳統擴散模型在訓練階段的目標任務是“噪聲估計”,而實際的目標任務是“圖像重建”。為了提升擴散模型的圖像重建性能,我們將它的迭代采樣過程重新定義為一個整體的圖像重建網絡,對該網絡進行端到端的訓練,突破了傳統噪聲估計學習范式所帶來的局限。如圖所示,通過這種方式,模型的所有參數都針對“圖像重建”任務進行了最優化,重建性能得到大幅提升。實驗結果表明,基于Stable Diffusion的預訓練權重與這一端到端學習框架,在圖像壓縮感知重建任務中,相比其他模型,我們的方法在PSNR(峰值信噪比)指標上提升了2dB,采樣步數從原本的100步降到了3步,推理速度提升了約15倍。
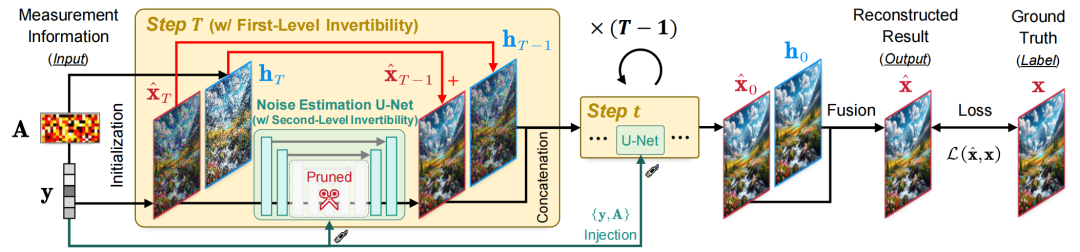
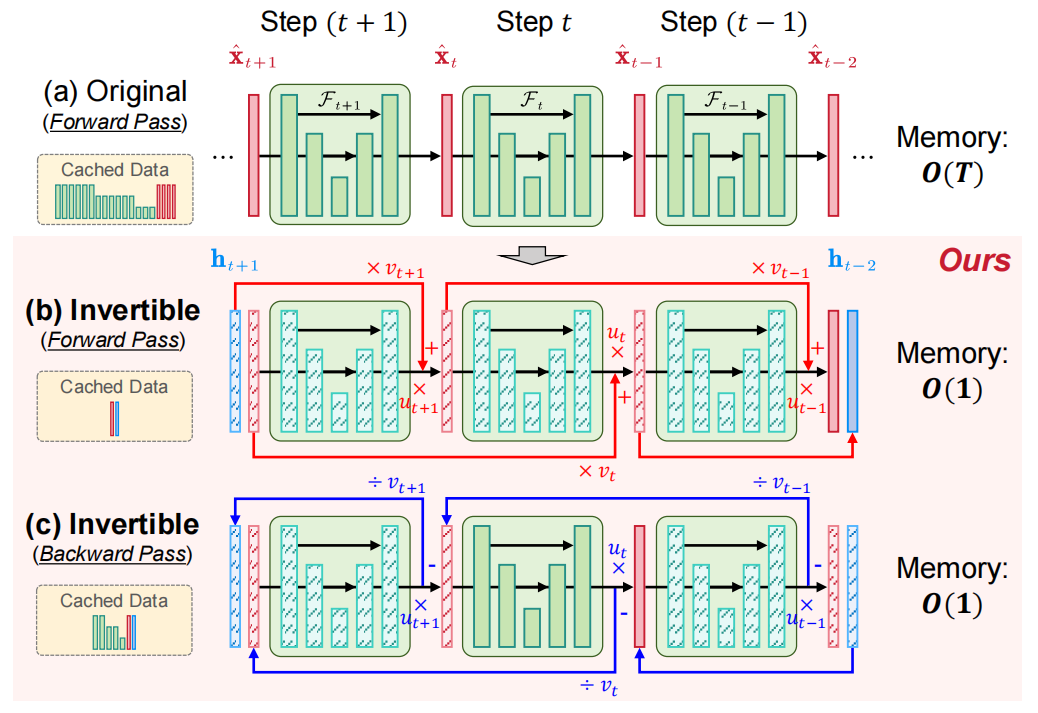
2.雙層可逆網絡設計:減少內存開銷
大型擴散模型(如Stable Diffusion)采樣過程的端到端訓練需要占用很大的GPU內存,這對于其實際應用來說是一個嚴重的瓶頸。為了減少內存開銷,我們提出了一種雙層可逆網絡。可逆網絡的核心思想是通過設計特殊的網絡結構,讓網絡每一層的輸出可以反向計算得到輸入。在實踐中,我們將可逆網絡應用到(1)所有擴散采樣步驟和(2)噪聲估計網絡的內部,通過“布線”技術將每個采樣步驟與其前后模塊連接,形成一個雙層可逆網絡。這一設計使得整個訓練過程中,程序無需存儲完整的特征圖數據,只需存儲較少的中間變量,顯著降低了訓練模型的GPU內存需求。最終,這使得我們可以在顯存有限的GPU(如1080Ti)上對該模型進行端到端訓練。
四、實驗結果
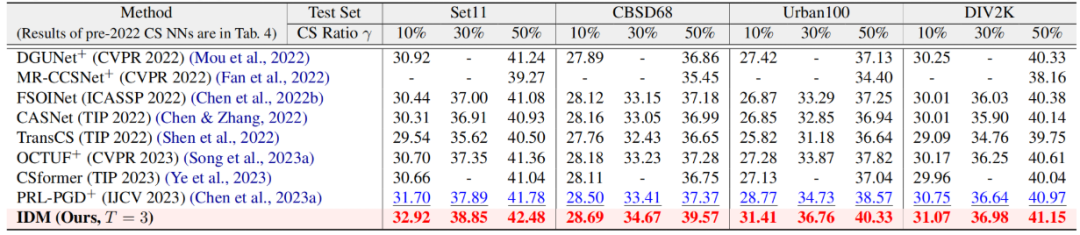
圖像壓縮感知重建
在圖像壓縮感知重建任務中,我們的方法IDM與現有基于端到端網絡和擴散模型的重建方法進行了對比。實驗結果顯示,IDM在PSNR、SSIM、FID和LPIPS等指標上取得明顯提升。

圖像補全與醫學成像
在掩碼率90%的圖像補全任務中,我們的方法能夠準確恢復出窗戶等復雜結構,而傳統的擴散模型(如DDNM)無法做到這一點。此外,我們還將該方法應用于醫學影像領域,包括核磁共振成像(MRI)和計算機斷層掃描(CT)成像,取得了良好的效果。

計算成本與推理時間的優化
基于傳統擴散模型的圖像重建方法往往需要較長的推理時間和計算開銷,而我們的可逆擴散模型IDM顯著縮短了這一過程。在重建一張256×256大小的圖像時,推理時間從9秒縮短至0.63秒,大幅降低了計算開銷。與現有方法DDNM相比,IDM的訓練、推理效率和重建性能得到了顯著提升。

欲了解更多細節,請參考原論文。
五、作者簡介
- 陳斌:北京大學信息工程學院博士生,主要研究方向是圖像壓縮感知與超分辨率。
- 張振宇:北京大學信息工程學院碩士生,主要研究方向是圖像重建。
- 李瑋琦:北京大學信息工程學院博士生,主要研究方向是圖像壓縮感知與超分辨率。
- 趙琛:沙特阿卜杜拉國王科技大學(KAUST)的研究科學家,圖像與視頻理解實驗室(IVUL)視頻分析課題組組長。她首次提出了可逆化預訓練神經網絡方法,實現了大型預訓練模型的極低顯存微調。她在這一領域的代表工作包括Re2TAL(CVPR 2023)、Dr2Net (CVPR 2024)等。
- 個人主頁:https://zhao-chen.com/。
- 余濟聞:北京大學信息工程學院碩士生,主要研究方向是生成式擴散模型。
- 趙世杰:字節跳動多媒體實驗室研究員,負責視頻處理與增強課題組。
- 陳杰:北京大學信息工程學院副教授,主要研究方向是計算機視覺與模式識別和AI4Science。
個人主頁:https://aimia-pku.github.io
張健:北京大學信息工程學院副教授,主要研究方向是視覺內容重建與生成、AIGC內容鑒偽和版權保護。
個人主頁:https://jianzhang.tech/cn






























