Linux 進程管理之負載均衡
本文轉載自微信公眾號「人人都是極客」,作者布道師Peter。轉載本文請聯系人人都是極客公眾號。
經過前面的學習,我們知道一個 task 有如下幾種狀態,但用top時往往會以縮寫的形式展現,這里我們總結下。
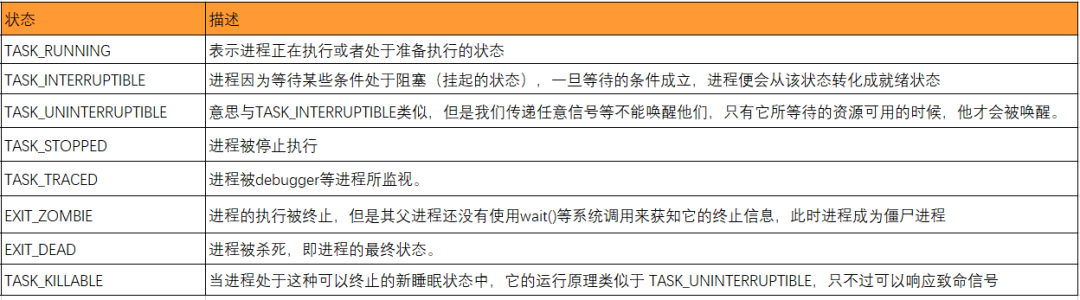
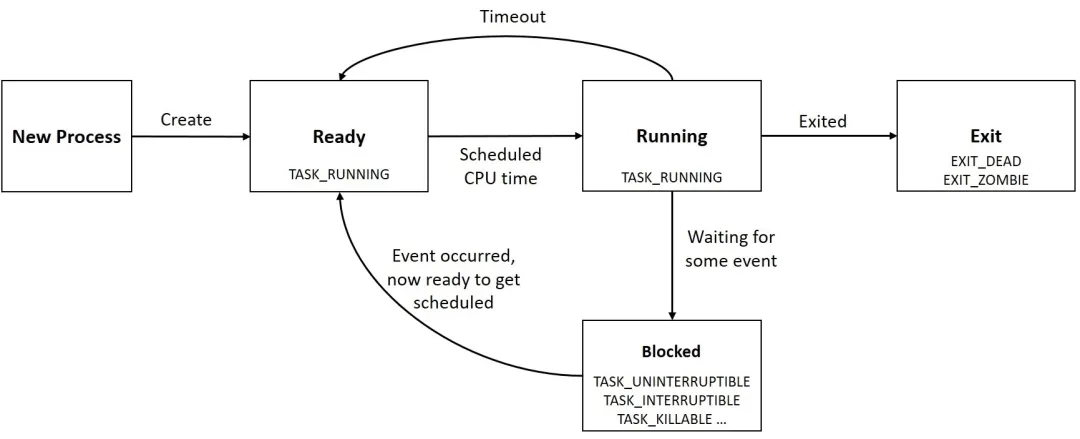
- R (TASK_RUNNING),可運行狀態。Linux中的 Ready 和 Running 對應的都是TASK_RUNNING標志位,ready 表示進程正處在隊列中,尚未被調度;running 則表示進程正在CPU上運行;
- D (TASK_UNINTERRUPTIBLE),不可中斷的睡眠狀態。是正處于內核態關鍵流程中的進程,并且這些流程是不可打斷的,比如最常見的是等待硬件設備的 I/O 響應。處于 TASK_UNINTERRUPTIBLE 狀態的進程不能被信號喚醒,只能由 wakeup 喚醒。既然 TASK_UNINTERRUPTIBLE 不能被信號喚醒,自然也不會響應 kill 命令,就算是必殺 kill -9 也不例外。
- S (TASK_INTERRUPTIBLE),可中斷的睡眠狀態。
- T (TASK_STOPPED or TASK_TRACED),暫停狀態或跟蹤狀態。
- Z (TASK_DEAD - EXIT_ZOMBIE),退出狀態,進程成為僵尸進程。
什么是平均負載?
認識一下:
- cat /proc/loadavg
- 0.18 0.94 0.72 1/486 3569
查看當前系統的平均負載,前三個數分別是 1分鐘、5分鐘、15分鐘的平均進程數。第四個的分子是正在運行的進程數,分母是進程總數;最后一個最近運行的進程ID號。
也可以:
- uptime
- 22:32:31 up 9 min, 1 user, load average: 0.18, 0.94, 0.72
22:32:31 up 9 min, 1 user, load average: 0.18, 0.94, 0.72
load average: 0.18, 0.94, 0.72 //分別是 1分鐘、5分鐘、15分鐘的平均進程數。
我這里的PC是2個cpu,所以這里的負載是比較低的(如果平均負載高于2.0的話說明過載,平均負載低于2.0就是比較正常的。)
平均負載是指單位時間內,系統處于可運行狀態和不可中斷狀態的平均進程數(即上面的R,D兩個狀態的平均進程數,很容易忽略D狀態的進程),也就是平均活躍進程數,它和 CPU 使用率并沒有直接關系。實際的計算比較復雜,感興趣的同學可以查看源碼 https://github.com/torvalds/linux/blob/master/kernel/sched/loadavg.c 。
平均負載不等于CPU使用率
通過上面的介紹我們知道:
平均負載不僅包括了正在使用 CPU 的進程,還包括等待 CPU 和等待 I/O 的進程。
CPU使用率,是單位時間內 CPU 繁忙情況的統計,跟平均負載并不一定完全對應。
比如:
CPU 密集型進程,使用大量 CPU 會導致平均負載升高,此時這兩者是一致的;I/O 密集型進程,等待 I/O 也會導致平均負載升高,但 CPU 使用率不一定很高;大量等待 CPU 的進程調度也會導致平均負載升高,此時的 CPU 使用率也會比較高。
所以這就是有時通過top發現cpu使用率不是很高,但是cat /proc/loadavg時負載又很大的原因。
常用命令
top
可以查看系統CPU的狀態,以百分比的形式顯示出來。
- Tasks: 251 total, 1 running, 243 sleeping, 0 stopped, 1 zombie
- Mem: 2007724k total, 862108k used, 1145616k free, 18560k buffers
- Swap: 1505788k total, 0k used, 1505788k free, 415260k cached
- 400%cpu 16%user 0%nice 6%sys 377%idle 0%iow 0%irq 0%sirq 0%host
- PID USER PR NI VIRT RES SHR S[%CPU] %MEM TIME+ ARGS
- 5628 root 20 0 5.9M 3.1M 2.7M R 19.3 0.1 0:00.07 top
- 5614 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [kworker/u9:0]
- 5609 root 20 0 0 0 0 S 0.0 0.0 0:00.00 [kworker/3:2]
- 5607 root 20 0 0 0 0 S 0.0 0.0 0:00.00 [kworker/u8:2]
- 5590 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [kworker/u9:4]
- 5585 root 20 0 0 0 0 S 0.0 0.0 0:00.00 [kworker/u8:3]
- 5577 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 [kworker/u9:2]
- 5571 root 20 0 0 0 0 S 0.0 0.0 0:00.00 [kworker/3:0]
- 5537 root 20 0 0 0 0 S 0.0 0.0 0:00.05 [kworker/u8:1]
- 5448 root 20 0 0 0 0 S 0.0 0.0 0:00.67 [kworker/3:1]
us(user cpu time):用戶態使用的cpu時間比。該值較高時,說明用戶進程消耗的 CPU 時間比較多,比如,如果該值長期超過 50%,則需要對程序算法或代碼等進行優化。
- sy(system cpu time):系統態使用的cpu時間比。
- ni(user nice cpu time):用做nice加權的進程分配的用戶態cpu時間比
- id(idle cpu time):空閑的cpu時間比。如果該值持續為0,同時sy是us的兩倍,則通常說明系統則面臨著 CPU 資源的短缺。
- wa(wait):等待使用CPU的時間。
- hi(hardware irq):硬中斷消耗時間
- si(software irq):軟中斷消耗時間
- st(steal time):虛擬機偷取時間
vmstat
vmstat用來檢測系統的狀態,包括CPU和內存,非常方便系統調試使用。
- procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
- r b swpd free buff cache si so bi bo in cs us sy id wa
- 1 0 0 1146440 18564 415260 0 0 2 1 0 95 0 0 100 0
- 0 0 0 1146476 18564 415260 0 0 0 0 0 384 0 0 100 0
- 0 0 0 1146104 18564 415260 0 0 0 0 0 375 0 0 100 0
- 0 0 0 1146724 18564 415260 0 0 0 0 0 387 0 0 100 0
- 0 0 0 1146848 18564 415260 0 0 0 0 0 369 0 0 100 0
參考:
https://mp.weixin.qq.com/s/UzmlGu-5n25B0wNScD50Jg
https://mp.weixin.qq.com/s/E5X9U7QIGnLCd4ETn2Ldlw