從源碼到實踐:徹底剖析Linux進程負載均衡機制
在當今的計算機領域,多核CPU早已成為主流配置。從早期的單核處理器到如今的 8 核、16 核甚至更多核心的CPU,硬件性能得到了極大提升。這種多核架構為計算機系統帶來了強大的并行處理能力,使得多個任務可以同時高效運行。然而,多核 CPU 的性能優勢并非能自動實現,如何充分利用這些核心資源,讓各個進程在不同核心上合理分配與運行,成為了操作系統必須解決的關鍵問題。
在眾多操作系統中,Linux 以其開源、穩定和高效等特點,被廣泛應用于服務器、嵌入式設備以及超級計算機等領域。而 Linux 內核進程 CPU 負載均衡機制,就是其充分發揮多核 CPU 性能的核心技術之一。這一機制就像是一位智能的調度大師,時刻監控著系統中各個進程的運行狀態以及各個 CPU 核心的負載情況,然后巧妙地將進程分配到最合適的 CPU 核心上運行,確保系統資源得到充分利用,避免出現某些核心忙得不可開交,而另一些核心卻閑置無事的尷尬局面。
接下來,就讓我們一起深入探索 Linux 內核進程 CPU 負載均衡機制,揭開它神秘的面紗,了解它是如何在幕后默默工作,為我們帶來高效穩定的系統體驗的。
一、CPU負載均衡機制
1.1什么是 CPU 負載
在深入探討 Linux 內核進程 CPU 負載均衡機制之前,我們先來明確一個關鍵概念 ——CPU 負載。CPU 負載常常容易與 CPU 使用率、利用率混淆 ,這里我們來詳細區分一下。CPU 利用率是指 CPU 處于忙碌狀態的時間占總時間的比例。比如在 1000ms 的時間窗口內,如果 CPU 執行任務的時間為 500ms,處于空閑(idle)狀態的時間也是 500ms,那么該時間段內 CPU 的利用率就是 50%。在 CPU 利用率未達到 100% 時,利用率與負載大致相等。
但當 CPU 利用率達到 100% 時,利用率就無法準確反映 CPU 負載狀況了。因為此時不同 CPU 上的運行隊列(runqueue)中等待執行的任務數目可能不同,直觀來說,runqueue 中掛著 10 個任務的 CPU,其負載明顯要比掛著 5 個任務的 CPU 更重。
早期,CPU 負載是用 runqueue 深度來描述的,也就是運行隊列中等待執行的任務數量。不過這種方式比較粗略,例如 CPU A 和 CPU B 上都掛了 1 個任務,但 A 上的任務是重載任務,B 上的是經常處于睡眠(sleep)狀態的輕載任務,僅依據 runqueue 深度來判斷 CPU 負載就不準確了。
現代調度器通常使用 CPU runqueue 上所有任務負載之和來表示 CPU 負載 ,這樣一來,對 CPU 負載的跟蹤就轉變為對任務負載的跟蹤。在 3.8 版本的 Linux 內核中,引入了 PELT(per entity load tracking)算法,該算法能夠跟蹤每一個調度實體(sched entity)的負載,將負載跟蹤算法從基于每個 CPU(per-CPU)進化到基于每個調度實體(per-entity)。PELT 算法不僅能知曉 CPU 的負載情況,還能明確負載來自哪個調度實體,從而實現更精準的負載均衡。
1.2何為均衡
明確了 CPU 負載的概念后,我們再來談談 “均衡”。負載均衡并非簡單地將系統的總負載平均分配到各個 CPU 上。實際上,我們必須充分考慮系統中各個 CPU 的算力,使每個 CPU 所承擔的負載與其算力相匹配。例如,在一個擁有 6 個小核和 2 個大核的系統中,假設系統總負載為 800,如果簡單地給每個 CPU 分配 100 的負載,這其實是不均衡的,因為大核 CPU 能夠提供更強的計算能力。
那么,什么是 CPU 算力(capacity)呢?算力是用來描述 CPU 能夠提供的計算能力。在相同頻率下,微架構為 A77 的 CPU 算力顯然大于 A57 的 CPU。如果 CPU 的微架構相同,那么最大頻率為 2.2GHz 的 CPU 算力肯定大于最大頻率為 1.1GHz 的 CPU。通常,確定了微架構和最大頻率,一個 CPU 的算力就基本確定了。雖然 Cpufreq 系統會根據當前的 CPU 利用率來調節 CPU 的運行頻率,但這并不會改變 CPU 的算力,只有當 CPU 的最大運行頻率發生變化時(比如觸發溫控,限制了 CPU 的最大頻率),CPU 的算力才會隨之改變。
在考慮 CFS(Completely Fair Scheduler,完全公平調度器)任務的均衡時,還需要把 CPU 用于執行實時任務(RT,Real - Time)和中斷請求(irq)的算力去掉,使用該 CPU 可用于 CFS 的算力 。所以,CFS 任務均衡中使用的 CPU 算力是一個不斷變化的值,需要經常更新。為了便于對比 CPU 算力和任務負載,我們采用歸一化的方式,將系統中處理能力最強且運行在最高頻率的 CPU 算力設定為 1024,其他 CPU 的算力則根據其微架構和運行頻率進行相應調整。
有了任務負載和 CPU 算力,看似就能完成負載均衡工作了,但實際情況更為復雜。當負載不均衡時,任務需要在 CPU 之間遷移,而不同形態的遷移會產生不同的開銷。比如,一個任務在小核集群內的 CPU 之間遷移,其性能開銷肯定小于從小核集群的 CPU 遷移到大核集群的開銷。因此,為了更有效地執行負載均衡,調度域(scheduling domain)和調度組(scheduling group)的概念被引入。調度域是一組 CPU 的集合,這些 CPU 在拓撲結構、性能等方面具有相似性;調度組則是在調度域內,根據更細粒度的規則劃分的 CPU 集合。通過合理劃分調度域和調度組,可以更精準地控制任務在 CPU 之間的遷移,降低遷移開銷,實現更高效的負載均衡。
1.3何為負載
「負載」可不等同于 CPU 占用率,它衡量的是已經 ready,但在一段時間內得不到執行機會的任務數量。如果把CPU 比做車道的話,當有車輛排隊等著進入這個車道,那負載就大于 1,反之則小于 1,它體現的其實是一種擁塞程度。
在 Linux 系統中,使用 "top" 或者 "w" 命令可以看到最近 1 分鐘、5 分鐘和 15 分鐘的平均負載(沒有做歸一化處理,需要自己除以 CPU 的數目)。借助不同統計時段的平均負載值,還可以觀察出負載變化的趨勢。
一般認為,負載值大于 0.7 就應該引起注意,但對于 Linux 系統來說,情況可能有所不同,因為 Linux 中統計的負載值,除了處于就緒態的任務,還包括了處于 uninterruptible 狀態、等待 I/O 的任務。
for_each_possible_cpu(cpu)
nr_active += cpu_of(cpu)->nr_running + cpu_of(cpu)->nr_uninterruptible;
avenrun[n] = avenrun[0]exp_n + nr_active(1 - exp_n)所以確切地說它不僅是 CPU load,而是 system load。如果因為 uninterruptible 的任務較多造成負載值看起來偏高,實際的系統在使用上也不見得就會出現明顯的卡頓。
負載均衡有兩種方式:pull, push
- pull拉:負載輕的CPU,從負載繁重的CPU pull tasks來運行。這應該是主要的方式,因為不應該讓負載本身就繁重的CPU執行負載均衡任務。相應的為load balance。
- push推:負載重的CPU,向負載輕的CPU,推送tasks由其幫忙執行。相應的為active balance。
但是遷移是有代價的。在同一個物理CPU的兩個logical core之間遷移,因為共享cache,代價相對較小。如果是在兩個物理CPU之間遷移,代價就會增大。更進一步,對于NUMA系統,在不同node之間的遷移將帶來更大的損失;這其實形成了一個調度上的約束,在Linux中被實現為"sched domain",并以hierarchy的形式組織。處于同一內層domain的,遷移可以更頻繁地進行,越往外層,遷移則應盡可能地避免。
1.4負載均衡的作用
負載均衡在 Linux 系統中起著至關重要的作用,對系統性能和穩定性有著顯著的提升。如果沒有有效的負載均衡機制,當系統中某個 CPU 核心的負載過高,而其他核心卻閑置時,就會導致整個系統性能下降。高負載的核心可能會因為任務過多而出現響應變慢、處理延遲等問題,嚴重時甚至可能導致系統崩潰。
例如,在一個 Web 服務器中,如果所有的 HTTP 請求處理任務都集中在某一個 CPU 核心上,隨著請求量的增加,這個核心很快就會不堪重負,服務器的響應時間會大幅延長,用戶訪問網站時會感覺到明顯的卡頓,甚至無法訪問。
而通過負載均衡機制,將這些任務均勻地分配到各個 CPU 核心上,每個核心都能充分發揮其計算能力,共同承擔系統的工作負載。這樣不僅可以避免單個核心過度勞累,還能大大提高系統的整體處理能力和響應速度。以剛才的 Web 服務器為例,負載均衡機制會將 HTTP 請求合理地分發到多個 CPU 核心上進行處理,每個核心都能高效地處理一部分請求,服務器就能快速響應用戶的訪問,提升用戶體驗。
負載均衡還有助于提高系統資源的利用率。在多核 CPU 系統中,每個核心都是寶貴的資源。通過負載均衡,能夠確保這些資源得到充分利用,避免出現資源閑置浪費的情況。當一個 CPU 核心的負載過高時,負載均衡機制會將部分任務遷移到其他相對空閑的核心上,使得整個系統的資源分配更加合理,從而提高系統的整體運行效率。這就好比一個工廠里有多個工人(CPU 核心),如果所有的工作都交給一個工人做,其他工人卻閑著沒事干,那顯然是對人力資源的浪費。而通過合理的任務分配(負載均衡),讓每個工人都能承擔適量的工作,就能充分發揮整個工廠的生產能力。
1.5為何均衡
作為OS的心跳,只要不是NO_HZ的CPU,tick都會如約而至,這為判斷是否需要均衡提供了一個絕佳的時機。不過,如果在每次tick時鐘中斷都去做一次balance,那開銷太大了,所以balance的觸發是有一個周期要求的。當tick到來的時候,在scheduler_tick函數中會調用trigger_load_balance來觸發周期性負載均衡,相關的代碼如下:
void scheduler_tick(void)
{
...
#ifdef CONFIG_SMP
rq->idle_balance = idle_cpu(cpu);
trigger_load_balance(rq);
#endif
}
void trigger_load_balance(struct rq *rq)
{
/*
* Don't need to rebalance while attached to NULL domain or
* runqueue CPU is not active
*/
if (unlikely(on_null_domain(rq) || !cpu_active(cpu_of(rq))))
return;
/* 觸發periodic balance */
if (time_after_eq(jiffies, rq->next_balance))
raise_softirq(SCHED_SOFTIRQ);
/* -觸發nohz idle balance */
nohz_balancer_kick(rq);
}進行調度和均衡本身也是需要消耗CPU的資源,因此比較適合交給idle的CPU來完成,idle_cpu被選中的這個idle CPU被叫做"idle load balancer"。
系統中有多個idle的cpu,如何選擇執行nohz idle balance的那個CPU呢?
如果不考慮功耗,那么就從所有idle cpu中選擇一個就可以了,但是在異構的系統中,我們應該要考慮的更多,如果idle cpu中有大核也有小核,是選擇大核還是選擇小核?大核CPU雖然算力強,但是功耗高。如果選擇小核,雖然能省功耗,但是提供的算力是否足夠。標準內核選擇的最簡單的算法:隨便選擇一個idle cpu(也就是idle cpu mask中的第一個)。
1.6如何均衡
要實現多核系統的負載均衡,主要依靠 task 在不同 CPU 之間的遷移(migration),也就是將一個 task 從負載較重的 CPU 上轉移到負載相對較輕的 CPU 上去執行。從 CPU 的 runqueue 上取下來的這個動作,稱為 "pull",放到另一個 CPU 的 runqueue 上去,則稱之為 "push"。
但是遷移是有代價的,而且這個遷移的代價還不一樣。AMP 系統里每個 CPU 的 capacity 可能不同,而 SMP 系統里看起來每個 CPU 都是一樣的,按理好像應該視作一個數組,拉通來調度。但現實是:現代 SMP 的拓撲結構,決定了 CPU 之間的 cache 共享是不同的,cache 共享越多,遷移的“阻力”越小,反之就越大。
在同一個物理 core 的兩個 logical CPU 之間遷移,因為共享 L1 和 L2 cache,阻力相對較小。對于NUMA系統,如果是在同一 node 中的兩個物理 core 之間遷移,共享的是 L3 cache 和內存,損失就會增大(AMD 的 Zen 系列芯片存在同一 node 的物理 core 不共享 L3 的情況)。更進一步,在不同 node 之間的遷移將付出更大的代價。
就像一個人換工作的時候,往往會優先考慮同一個公司的內部職位,因為只是轉崗的話,公司內的各種環境都是熟悉的。再是考慮同一個城市的其他公司,因為不用搬家嘛。可能最后才是考慮其他城市/國家的,畢竟 relocate 牽扯的事情還是蠻多的。
二、CPU負載均衡機制原理
2.1相關數據結構與關鍵函數
在 Linux 內核進程 CPU 負載均衡機制中,有一些關鍵的數據結構和函數起著至關重要的作用。
runqueue 隊列是其中一個重要的數據結構。在多處理器系統中,每個 CPU 都擁有自己的 runqueue 隊列 ,這個隊列就像是一個任務等待執行的 “候診室”,里面存放著處于運行狀態(run)的進程鏈表。當一個進程準備好運行時,它就會被加入到某個 CPU 的 runqueue 隊列中。例如,當我們在系統中啟動一個新的應用程序時,該程序對應的進程就會被添加到某個 CPU 的 runqueue 隊列里,等待 CPU 的調度執行。
調度域(sched domain)和調度組(sched group)
負載均衡的復雜性主要和復雜的系統拓撲有關。由于當前CPU很忙,我們把之前運行在該CPU上的一個任務遷移到新的CPU上的時候,如果遷移到新的CPU是和原來的CPU在不同的cluster中,性能會受影響(因為會cache會變冷)。但是對于超線程架構,cpu共享cache,這時候超線程之間的任務遷移將不會有特別明顯的性能影響。
NUMA上任務遷移的影響又不同,我們應該盡量避免不同NUMA node之間的任務遷移,除非NUMA node之間的均衡達到非常嚴重的程度。總之,一個好的負載均衡算法必須適配各種cpu拓撲結構。為了解決這些問題,linux內核引入了sched_domain的概念。
調度組: 調度組是組成調度域的基本單位,在最小的調度域中一個cpu core是一個調度組,在最大的調度域中,一個NUMA結點內的所有cpu core成一個調度組。
sched_domain(調度域)也是一個核心數據結構。為了適應多種多處理器模型,Linux 引入了調度域及組的概念。一個調度域可以包含其他的調度域或者多個組 ,它是一組 CPU 的集合,這些 CPU 在拓撲結構、性能等方面具有相似性。通過調度域,內核能夠更好地管理和協調不同 CPU 之間的負載均衡。
例如,在一個具有多個 CPU 核心的系統中,可能會根據 CPU 的性能和拓撲關系,將某些核心劃分為一個調度域,這樣在進行負載均衡時,可以優先在這個調度域內進行任務的遷移和分配,減少跨調度域遷移帶來的開銷。
調度域的數據結構定義如下:
struct sched_domain {
struct sched_domain *parent; // 指向父調度域
struct sched_group *groups; // 該調度域所包含的組
cpumask_t span;
unsigned long min_interval; // 最小時間間隔,用于檢查負載均衡操作時機
unsigned long max_interval;
unsigned int busy_factor; // 忙碌時負載均衡時間間隔乘數
unsigned int imbalance_pct;
unsigned long long cache_hot_time;
unsigned int cache_nice_tries;
unsigned int per_cpu_gain;
int flags;
unsigned long last_balance;
unsigned int balance_interval; // 負載均衡進行的時間間隔
unsigned int nr_balance_failed; // 負載均衡遷移進程失敗的次數
};調度域并不是一個平層結構,而是根據CPU拓撲形成層級結構。相對應的,負載均衡也不是一蹴而就的,而是會在多個sched domain中展開(例如從base domain開始,一直到頂層sched domain,逐個domain進行均衡)。
內核中struct sched_domain來描述調度域,其主要的成員如下:
- Parent和child:Sched domain會形成層級結構,parent和child建立了不同層級結構的父子關系。對于base domain而言,其child等于NULL,對于top domain而言,其parent等于NULL。
- groups:一個調度域中有若干個調度組,這些調度組形成一個環形鏈表,groups成員就是鏈表頭。
- min_interval和max_interval:做均衡也是需要開銷的,我們不可能時刻去檢查調度域的均衡狀態,這兩個參數定義了檢查該sched domain均衡狀態的時間間隔范圍。
- busy_factor:正常情況下,balance_interval定義了均衡的時間間隔,如果cpu繁忙,那么均衡要時間間隔長一些,即時間間隔定義為busy_factor x balance_interval。
- imbalance_pct:調度域內的不均衡狀態達到了一定的程度之后就開始進行負載均衡的操作。imbalance_pct這個成員定義了判定不均衡的門限。
- cache_nice_tries:這個成員應該是和nr_balance_failed配合控制負載均衡過程的遷移力度。當nr_balance_failed大于cache_nice_tries的時候,負載均衡會變得更加激進。
- nohz_idle:每個cpu都有其對應的LLC sched domain,而LLC SD記錄對應cpu的idle狀態(是否tick被停掉),進一步得到該domain中busy cpu的個數,體現在(sd->shared->nr_busy_cpus)。
- flags:調度域標志,下面有表格詳細描述。
- level:該sched domain在整個調度域層級結構中的level。Base sched domain的level等于0,向上依次加一。
- last_balance:上次進行balance的時間點。通過基礎均衡時間間隔()和當前sd的狀態可以計算最終的均衡間隔時間(get_sd_balance_interval),last_balance加上這個計算得到的均衡時間間隔就是下一次均衡的時間點。
- balance_interval:定義了該sched domain均衡的基礎時間間隔
- nr_balance_failed:本sched domain中進行負載均衡失敗的次數。當失敗次數大于cache_nice_tries的時候,我們考慮遷移cache hot的任務,進行更激進的均衡操作。
- max_newidle_lb_cost:在該domain上進行newidle balance的最大時間長度(即newidle balance的開銷)。最小值是sysctl_sched_migration_cost。
- next_decay_max_lb_cost:max_newidle_lb_cost會記錄最近在該sched domain上進行newidle balance的最大時間長度,這個max cost不是一成不變的,它有一個衰減過程,每秒衰減1%,這個成員就是用來控制衰減的。
- avg_scan_cost:平均掃描成本
調度域并不是一個平層結構,而是根據CPU拓撲形成層級結構。相對應的,負載均衡也不是一蹴而就的,而是會在多個sched domain中展開(例如從base domain開始,一直到頂層sched domain,逐個domain進行均衡)。具體如何進行均衡(自底向上還是自頂向下,在哪些domain中進行均衡)是和均衡類型和各個sched domain設置的flag相關,具體細節后面會描述。
在指定調度域內進行均衡的時候不考慮系統中其他調度域的CPU負載情況,只考慮該調度域內的sched group之間的負載是否均衡。對于base doamin,其所屬的sched group中只有一個cpu,對于更高level的sched domain,其所屬的sched group中可能會有多個cpu core。
與之相關的是 sched_group(調度組),一個組通常包含一個或者多個 CPU 。組的數據結構通過cpumask_t來表示該組所包含的 CPU,還通過next指針將多個sched_group串到調度域的鏈表上面。其數據結構定義如下:
struct sched_group {
struct sched_group *next; // 用于將sched_group串到調度域鏈表
cpumask_t cpumask; // 表示該group所包含的cpu
unsigned long cpu_power; // 通常是cpu的個數
};在函數方面,load_balance函數是實現負載均衡的關鍵函數之一。當系統檢測到 CPU 負載不均衡時,就會調用load_balance函數。它的主要工作是尋找最繁忙的 CPU 組中的最繁忙的 CPU ,然后將其進程遷移一部分到其他相對空閑的 CPU 上。例如,在一個四核系統中,如果發現 CPU0 的負載過高,而 CPU1、CPU2 和 CPU3 相對空閑,load_balance函數就會嘗試從 CPU0 的 runqueue 隊列中挑選一些進程,遷移到 CPU1、CPU2 或 CPU3 的 runqueue 隊列中,以實現負載的均衡。
rebalance_tick函數也在負載均衡中扮演著重要角色。每經過一次時鐘中斷,scheduler_tick函數就會調用rebalance_tick函數 。rebalance_tick函數會從最底層的調度域開始,一直到最上層的調度域進行檢查,對于每個調度域,它會查看是否到了調用load_balance函數的時間。如果到了合適的時間,就會觸發負載均衡操作。同時,它還會根據當前 CPU 的 idle 狀態和sched_domain的參數來確定調用load_balance的時間間隔。
當 CPU 處于空閑狀態時,會以較高的頻率調用load_balance(可能 1、2 個時鐘節拍) ,以便盡快將其他 CPU 上的任務遷移過來,充分利用空閑的 CPU 資源;而當 CPU 處于忙碌狀態時,則會以較低的頻率調用load_balance(可能 10 - 100ms ),避免過度頻繁的負載均衡操作影響系統性能。
2.3任務調度算法(以 CFS 為例)
在 Linux 內核中,任務調度算法是實現 CPU 負載均衡的核心部分,其中完全公平調度(CFS,Completely Fair Scheduler)算法被廣泛應用于普通進程的調度。
CFS 算法的核心思想是將任務看作紅黑樹節點進行排序和調度 ,以實現公平的 CPU 資源分配。在 CFS 中,每個進程都有一個虛擬運行時間(vruntime)的概念,這個虛擬運行時間是衡量進程已經獲得的 CPU 服務量的指標。當新創建一個任務時,會賦予其初始的 vruntime 值 ;隨著程序的執行,vruntime 會不斷累加。
對于等待更長時間未被執行過的輕載任務來說,其 vruntime 值會相對較低,這樣的任務會被放置于紅黑樹的左側位置,以便盡快得到 CPU 的服務機會。這就好比在一場比賽中,那些等待起跑時間較長的選手(任務),會被安排在更有利的起跑位置(紅黑樹左側),從而更有可能先起跑(先獲得 CPU 執行時間)。
CFS 調度器選取待運行的下一個進程時,會選擇具有最小 vruntime 的任務 ,因為這個任務的虛擬運行時間最短,也就意味著它獲得的 CPU 時間最少,最需要被調度執行。而紅黑樹這種數據結構的特性使得每次插入、刪除操作都能保持在 O (log n) 的時間復雜度 ,從而保證了在大量進程存在的情況下,依然能高效地查找和調度具有最小 vruntime 的任務。例如,在一個擁有 1000 個進程的系統中,CFS 調度器通過紅黑樹能夠快速地找到 vruntime 最小的進程,將其調度到 CPU 上執行,而不會因為進程數量的增加導致調度效率大幅下降。
在考慮 CPU 核心負載差異分配任務方面,CFS 算法會綜合多個因素。首先,它會關注每個 CPU 核心的負載情況,盡量將任務分配到負載較輕的核心上。如果某個 CPU 核心的 runqueue 隊列中任務過多,負載較重,CFS 調度器會嘗試將新的任務分配到其他負載相對較輕的核心上,以避免某個核心過度繁忙。其次,CFS 算法還會考慮進程的特性,比如進程的優先級(通過 nice 值體現) 。較高的 nice 值(較低的優先級)進程會獲得更低的處理器使用權重 ,在分配任務時,會相對優先調度 nice 值較低(優先級較高)的進程,以保證系統中重要任務能夠及時得到執行。
2.4負載均衡的觸發時機
負載均衡的觸發時機對于保證系統性能至關重要,Linux 內核主要通過以下兩種情況來觸發負載均衡。
(1)當某個 CPU 的 runqueue 為空時
當某個 CPU 的 runqueue 隊列中一個可運行進程都沒有時,就說明這個 CPU 處于空閑狀態,無事可做。這時,為了充分利用 CPU 資源,系統會從其他 CPU 的 runqueue 中獲取任務 。例如,在一個雙核系統中,假設 CPU0 上的 runqueue 隊列中有多個可運行進程,而 CPU1 的 runqueue 隊列為空。
那么,CPU1 就會調用load_balance函數,發現在 CPU0 上還有許多進程等待運行,于是它會從 CPU0 上的可運行進程里找到優先級最高的進程,將其拿到自己的 runqueue 里開始執行。這樣,原本空閑的 CPU1 就可以利用起來,分擔系統的工作負載,提高系統的整體處理能力。
(2)周期性檢查
每經過一個時鐘節拍,內核會調用scheduler_tick函數 ,這個函數會執行許多重要的任務,例如減少當前正在執行的進程的時間片,以確保每個進程都能公平地獲得 CPU 時間。在scheduler_tick函數的結尾處,則會調用rebalance_tick函數 ,rebalance_tick函數決定了以什么樣的頻率執行負載均衡。
具體來說,rebalance_tick函數會從當前 CPU 所屬的調度域開始,依次遍歷各個更高級的調度域。對于每個調度域,它會檢查是否滿足調用load_balance函數的條件。這里的條件主要基于時間間隔和負載情況。每個調度域都有一個balance_interval參數 ,表示負載均衡進行的時間間隔。同時,還會根據當前 CPU 的 idle 狀態來調整這個時間間隔。
當 idle 標志位是SCHED_IDLE時,表示當前 CPU 處理器空閑 ,此時會以很高的頻率來調用load_balance(通常是 1、2 個時鐘節拍) ,因為空閑的 CPU 需要盡快獲取任務來執行,避免資源浪費;反之,表示當前 CPU 并不空閑,會以很低的頻率調用load_balance(一般是 10 - 100ms ),因為在 CPU 忙碌時,頻繁進行負載均衡操作可能會增加系統開銷,影響系統性能。
例如,假設一個調度域的balance_interval設置為 50ms ,當 CPU 處于忙碌狀態時,rebalance_tick函數會每隔 50ms 檢查一次是否需要進行負載均衡。如果當前時間戳與上次執行負載均衡的時間戳之差大于等于 50ms ,并且經過一系列的負載檢查和判斷,發現存在負載不均衡的情況,就會調用load_balance函數進行負載均衡操作,將任務從負載重的 CPU 遷移到負載輕的 CPU 上,以實現系統負載的均衡。
三、負載均衡的軟件架構
負載均衡模塊主要分兩個軟件層次:核心負載均衡模塊和class-specific均衡模塊。內核對不同的類型的任務有不同的均衡策略,普通的CFS(complete fair schedule)任務和RT、Deadline任務處理方式是不同的,由于篇幅原因,本文主要討論CFS任務的負載均衡。
為了更好的進行CFS任務的均衡,系統需要跟蹤CFS任務負載、各個sched group的負載及其CPU算力(可用于CFS任務運算的CPU算力)。跟蹤任務負載是主要有兩個原因:
- 判斷該任務是否適合當前CPU算力
- 如果判定需要均衡,那么需要在CPU之間遷移多少的任務才能達到平衡?有了任務負載跟蹤模塊,這個問題就比較好回答了。
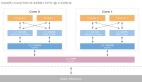
為了更好的進行高效的均衡,我們還需要構建調度域的層級結構(sched domain hierarchy),圖中顯示的是二級結構(這里給的是邏輯結構,實際內核中的各個level的sched domain是per cpu的)。手機場景多半是二級結構,支持NUMA的服務器場景可能會形成更復雜的結構。通過DTS和CPU topo子系統,我們可以構建sched domain層級結構,用于具體的均衡算法。
在手機平臺上,負載均衡會進行兩個level:MC domain的均衡和DIE domain的均衡。在MC domain上,我們會對跟蹤每個CPU負載狀態(sched group只有一個CPU)并及時更新其算力,使得每個CPU上有其匹配的負載。在DIE domain上,我們會跟蹤cluster上所有負載(每個cluster對應一個sched group)以及cluster的總算力,然后計算cluster之間負載的不均衡狀況,通過inter-cluster遷移讓整個DIE domain進入負載均衡狀態。
有了上面描述的基礎設施,那么什么時候進行負載均衡呢?這主要和調度事件相關,當發生任務喚醒、任務創建、tick到來等調度事件的時候,我們可以檢查當前系統的不均衡情況,并酌情進行任務遷移,以便讓系統負載處于平衡狀態。
首先需要了解下CPU核心之間的數據流通信原理,這樣就能大概知道CPU中的Core之間的進程遷移之間的開銷:
由于NUMA是以層次關系呈現,因此在執行進程的負載均衡也會呈現不同的成本開銷。進程在同一個物理Core上的邏輯Core之前遷移開銷最小;
如果在不同的物理Core之間遷移,如果每個物理Core擁有私有的L1 Cache,共享L2 Cache,進程遷移后就無法使用原來的L1 Cache,進程遷移到新的Core上缺失L1 Cache數據,這就需要進程的狀態數據需要在CPU Core之間進行通信獲取這些數據,根據上圖CPU的通信模式可以了解,成本代價是蠻大的。
內核采用調度域解決現代多CPU多核的問題,調度域是具有相同屬性和調度策略的處理器集合,任務進程可以在它們內部按照某種策略進行調度遷移。
進程在多CPU的負載均衡也是針對調度域的,調度域根據超線程、多核、SMP、NUMA等系統架構劃分為不同的等級,不同的等級架構通過指針鏈接在一起,從而形成樹狀結構;在進程的負載均衡過程中,從樹的葉子節點往上遍歷,直到所有的域中的負載都是平衡的。目前內核進程調度按照如下的原則進行,這些原則都是按照cpu架構以及通信路徑來進行的。
四、CPU負載均衡機制實現方式
4.1如何做負載均衡
我們以一個4小核+4大核的處理器來描述CPU的domain和group:
在上面的結構中,sched domain是分成兩個level,base domain稱為MC domain(multi core domain),頂層的domain稱為DIE domain。頂層的DIE domain覆蓋了系統中所有的CPU,小核cluster的MC domain包括所有小核cluster中的cpu,同理,大核cluster的MC domain包括所有大核cluster中的cpu。
對于小核MC domain而言,其所屬的sched group有四個,cpu0、1、2、3分別形成一個sched group,形成了MC domain的sched group環形鏈表。不同CPU的MC domain的環形鏈表首元素(即sched domain中的groups成員指向的那個sched group)是不同的,對于cpu0的MC domain,其groups環形鏈表的順序是0-1-2-3,對于cpu1的MC domain,其groups環形鏈表的順序是1-2-3-0,以此類推。大核MC domain也是類似,這里不再贅述。
對于非base domain而言,其sched group有多個cpu,覆蓋其child domain的所有cpu。例如上面圖例中的DIE domain,它有兩個child domain,分別是大核domain和小核domian,因此,DIE domain的groups環形鏈表有兩個元素,分別是小核group和大核group。不同CPU的DIE domain的環形鏈表首元素(即鏈表頭)是不同的,對于cpu0的DIE domain,其groups環形鏈表的順序是(0,1,2,3)--(4,5,6,7),對于cpu6的MC domain,其groups環形鏈表的順序是(4,5,6,7)--(0,1,2,3),以此類推。
為了減少鎖的競爭,每一個cpu都有自己的MC domain和DIE domain,并且形成了sched domain之間的層級結構。在MC domain,其所屬cpu形成sched group的環形鏈表結構,各個cpu對應的MC domain的groups成員指向環形鏈表中的自己的cpu group。在DIE domain,cluster形成sched group的環形鏈表結構,各個cpu對應的DIE domain的groups成員指向環形鏈表中的自己的cluster group。
4.2負載均衡的基本過程
負載均衡不是一個全局CPU之間的均衡,實際上那樣做也不現實,當系統的CPU數量較大的時候,很難一次性的完成所有CPU之間的均衡,這也是提出sched domain的原因之一。我們以周期性均衡為例來描述負載均衡的基本過程。當一個CPU上進行周期性負載均衡的時候,我們總是從base domain開始(對于上面的例子,base domain就是MC domain),檢查其所屬sched group之間(即各個cpu之間)的負載均衡情況,如果有不均衡情況,那么會在該cpu所屬cluster之間進行遷移,以便維護cluster內各個cpu core的任務負載均衡。
有了各個CPU上的負載統計以及CPU的算力信息,我們很容易知道MC domain上的不均衡情況。為了讓算法更加簡單,Linux內核的負載均衡算法只允許CPU拉任務,這樣,MC domain的均衡大致需要下面幾個步驟:
- 找到MC domain中最繁忙的sched group
- 找到最繁忙sched group中最繁忙的CPU(對于MC domain而言,這一步不存在,畢竟其sched group只有一個cpu)
- 從選中的那個繁忙的cpu上拉取任務,具體拉取多少的任務到本CPU runqueue上是和不均衡的程度相關,越是不均衡,拉取的任務越多。
完成MC domain均衡之后,繼續沿著sched domain層級結構向上檢查,進入DIE domain,在這個level的domain上,我們仍然檢查其所屬sched group之間(即各個cluster之間)的負載均衡情況,如果有不均衡的情況,那么會進行inter-cluster的任務遷移。基本方法和MC domain類似,只不過在計算均衡的時候,DIE domain不再考慮單個CPU的負載和算力,它考慮的是:
- 該sched group的負載,即sched group中所有CPU負載之和
- 該sched group的算力,即sched group中所有CPU算力之和
4.3線程的負載均衡
在 Linux 內核進程 CPU 負載均衡機制中,線程的負載均衡是確保系統高效運行的關鍵環節,它主要針對實時(RT,Real - Time)任務和普通任務采取不同的策略。
⑴RT 任務
RT 任務對時間的要求極為嚴格,需要確保能夠及時響應和執行。在 Linux 系統中,對于 RT 任務的負載均衡,采用了一種高效的分配方式,即把 n 個優先級最高的 RT 任務自動分配到 n 個核上 。這是因為 RT 任務的實時性要求決定了它們需要盡快得到 CPU 的執行機會,將這些高優先級的 RT 任務分散到多個核心上,可以避免任務之間的競爭和延遲,確保每個任務都能在最短的時間內得到處理。
在實際實現過程中,主要通過pull_rt_task和push_rt_task這兩個函數來完成任務的遷移操作 。當系統中出現新的高優先級 RT 任務時,會調用push_rt_task函數,將任務推送到相對空閑的 CPU 核心上,以確保任務能夠及時執行;而當某個 CPU 核心上的 RT 任務執行完畢,或者負載過高需要調整時,則會調用pull_rt_task函數,從其他核心上拉取合適的 RT 任務到當前核心,從而實現負載的均衡。這種基于任務優先級的分配方式,能夠充分利用多核 CPU 的并行處理能力,保證 RT 任務的實時性需求,使得系統在處理對時間敏感的任務時,能夠保持高效穩定的運行狀態。
⑵普通任務
普通任務的負載均衡則主要通過周期性負載均衡、idle 時負載均衡以及 fork 和 exec 時負載均衡這幾種方式來實現。
周期性負載均衡是在時鐘 tick 到來時進行的 。每當時鐘 tick 發生,系統就會檢查各個核的負載情況,優先讓空閑核工作。如果發現某個核處于空閑狀態,而其他核負載較重,就會從負載重的核中pull任務到空閑核,或者將空閑核的任務push給負載較輕的核 。例如,在一個四核系統中,假設 CPU0 和 CPU1 負載較高,而 CPU2 和 CPU3 處于空閑狀態。當時鐘 tick 到來時,系統會檢測到這種負載不均衡的情況,然后從 CPU0 和 CPU1 的 runqueue 隊列中挑選一些普通任務,遷移到 CPU2 和 CPU3 上執行,這樣就能讓各個核都能參與到任務處理中,避免出現部分核過度忙碌,而部分核閑置的情況,從而實現系統負載的均衡。
idle 時負載均衡是當某個核進入 idle 狀態時觸發的 。當一個核進入 idle 狀態,說明它當前沒有可執行的任務,處于空閑狀態。此時,這個核會主動去檢查其他核的負載情況,如果發現其他核有任務在運行,就會主動從其他核pull任務過來執行 。例如,在一個八核系統中,假設 CPU5 進入 idle 狀態,它會查看其他七個核的 runqueue 隊列,發現 CPU3 上有較多的普通任務在等待執行,那么 CPU5 就會從 CPU3 的 runqueue 隊列中選取一些任務,將其遷移到自己的隊列中并開始執行,這樣可以充分利用空閑的 CPU 資源,提高系統的整體處理能力。
fork 和 exec 時負載均衡則與新進程的創建和執行密切相關 。當系統執行 fork 操作創建一個新進程,或者通過 exec 函數族執行新的程序時,會把新創建的進程放到最閑的核上去運行 。這是因為新進程在啟動階段可能需要進行一些初始化操作,將其分配到最閑的核上,可以避免對其他正在忙碌執行任務的核造成額外的負擔,同時也能讓新進程盡快獲得 CPU 資源,順利完成初始化和后續的執行操作。例如,當我們在系統中啟動一個新的應用程序時,系統會根據各個核的負載情況,將這個新程序對應的進程分配到當前負載最輕的核上運行,確保新進程能夠高效啟動和運行。
4.4中斷負載均衡
在 Linux 系統中,負載不僅來源于進程,中斷也是重要的負載來源之一。中斷分為硬件中斷和軟中斷,它們在系統運行中起著不同但又緊密相關的作用。
硬件中斷通常是由外部設備(如網卡、硬盤、鍵盤等)引發的信號,用于通知 CPU 有需要立即處理的事件 。例如,當網卡接收到數據時,會產生一個硬件中斷,通知 CPU 有新的數據到達需要處理。硬件中斷的處理時間一般較短,在 Linux 2.6.34 版本之后,內核不再支持中斷嵌套 。
當硬件中斷發生并完成數據接收等操作后,通常會調用軟中斷來進行后續的處理,比如處理 TCP/IP 包 。軟中斷可以嵌套,它主要負責處理那些可以稍微延遲處理的任務,是對硬件中斷未完成工作的一種推后執行機制。在top命令中,hi表示硬中斷時間(isr,屏蔽中斷),si表示軟中斷 。當網絡流量較大時,CPU 花在硬中斷和軟中斷上的時間會比較多,此時就需要進行中斷的負載均衡,以確保系統的高效運行。
在新網卡多隊列的情況下,實現中斷負載均衡可以通過設置中斷親和性來完成 。例如,在一個 4 核的系統中,如果網卡有 4 個隊列,每個隊列都可以單獨產生中斷,并且硬件支持負載均衡 。那么可以將一個隊列綁定到一個核上,通過將每個中斷號分別設置 affinity,綁定到指定 CPU,就能讓所有 CPU 都參與到網卡發送包服務中 。
比如,通過查看/proc/interrupts文件找到與網卡相關的中斷號,然后使用命令sudo sh -c “echo 3 > /proc/irq/124/smp_affinity”,就可以將中斷號為 124 的中斷綁定到 CPU3 上 。這樣,當網卡的不同隊列產生中斷時,就會被分配到不同的 CPU 核心上進行處理,避免了所有中斷都集中在一個核心上,從而實現了中斷的負載均衡,提高了系統處理網絡數據的能力。
然而,有些網卡只有一個隊列,這種情況下,單個核拋出的軟中斷只能在這個核上運行,導致一個隊列拋出的軟中斷(如 TCP/IP 層處理)只能在這一個核執行,其他核會處于空閑狀態,無法充分利用多核 CPU 的優勢。為了解決這個問題,Google 推出了 RPS(Receive Packet Steering)補丁 。RPS 補丁的原理是由單一 CPU 核響應硬件中斷,然后將大量網絡接收包通過多核間中斷方式分發給其他空閑核 。
例如,在一個單核網卡隊列收包的系統中,默認情況下收包操作只在 CPU0 上執行。通過設置 RPS,如echo 3 > /sys/class/net/eth0/queues/rx-0/rps_cpus,可以將收包操作均衡到 CPU0 和 CPU1 上 。這樣,當大量網絡數據包到達時,原本只能由一個核處理的任務,現在可以由多個核共同處理,大大提高了系統處理網絡數據的效率,實現了軟中斷的負載均衡,充分發揮了多核 CPU 的性能優勢。
4.5其他需要考慮的事項
之所以要進行負載均衡主要是為了系統整體的throughput,避免出現一核有難,七核圍觀的狀況。然而,進行負載均衡本身需要額外的算力開銷,為了降低開銷,我們為不同level的sched domain定義了時間間隔,不能太密集的進行負載均衡。之外,我們還定義了不均衡的門限值,也就是說domain的group之間如果有較小的不均衡,我們也是可以允許的,超過了門限值才發起負載均衡的操作。很顯然,越高level的sched domain其不均衡的threashhold越高,越高level的均衡會帶來更大的性能開銷。
在引入異構計算系統之后,任務在placement的時候可以有所選擇。如果負載比較輕,或者該任務對延遲要求不高,我們可以放置在小核CPU執行,如果負載比較重或者該該任務和用戶體驗相關,那么我們傾向于讓它在算力更高的CPU上執行。為了應對這種狀況,內核引入了misfit task的概念。一旦任務被標記了misfit task,那么負載均衡算法要考慮及時的將該任務進行upmigration,從而讓重載任務盡快完成,或者提升該任務的執行速度,從而提升用戶體驗。
除了性能,負載均衡也會帶來功耗的收益。例如系統有4個CPU,共計8個進入執行態的任務(負載相同)。這些任務在4個CPU上的排布有兩種選擇:
(1)全部放到一個CPU上
(2)每個CPU runqueue掛2個任務
負載均衡算法會讓任務均布,從而帶來功耗的收益。雖然方案一中有三個CPU是處于idle狀態的,但是那個繁忙CPU運行在更高的頻率上。而方案二中,由于任務均布,CPU處于較低的頻率運行,功耗會比方案一更低。