













如何做機器學習模型質量保障及模型效果評測
近年來,機器學習模型算法在越來越多的工業實踐中落地。在滴滴,大量線上策略由常規算法遷移到機器學習模型算法。如何搭建機器學習模型算法的質量保障體系成為質量團隊急需解決的問題之一。本文整體介紹了機器學習模型算法的質量保障方案,并進一步給出了滴滴質量團隊在機器學習模型效果評測方面的部分探索實踐。
1. 背景
近年來,隨著技術的發展,機器學習模型算法在越來越多的工業實踐中落地,在以深度學習為基礎的語音智能、圖像智能方面表現尤為突出。 在我司,大量線上策略由規則算法遷移到機器學習模型算法且在多個方向的實踐中取得了不錯的成績,如: 拼車排隊預估模型、司機調度控badcase模型、取消率模型等。 機器學習與傳統軟件不同,后者的行為基于不同的輸入預先確定,運算邏輯是可解釋的。 在給定輸入下,預期輸出結果是可以前置確定的。 而在機器學習模型尤其是分類模型中,模型基于大量數據訓練,輸入的是數據及相應的label,訓練過程對人黑盒,人無法預先前置的確定其結果。 總體來說模型測試的難點體現在如下幾個方面:
(1)樣本獲取,部分模型樣本相對稀疏如安全分單模型
(2)數據質量,主要體現在模型訓練及使用階段,其所涉及的數據體量一般都很大,對數據質量的把控無法做到較細粒度
(3)特征質量, 特征有效性&特征關聯性度量
(4)模型效果驗證, 業界公司質量團隊主要通過一些大的業務指標來評測,在搜索推薦領域、金融風控等領域有較好的落地。但業務指標通常是對模型效果“面”的度量。在助力模型找出迭代方向上相對乏力。
2. 模型質量保障方案
一定程度上,數據和特征決定了機器學習的上限,而模型和算法只是逼近這個上限的手段。在對模型測試之前,我們可能會有如下一些疑問
(1)模型能力達到什么樣的標準可以準出?
(2)怎樣的測試數據能很好的度量出模型的能力?
(3)如何評估特征的質量?
(4)如何更好的從用戶視角去對線上模型效果進行評測?
模型從訓練到線上應用的基本流程如下:
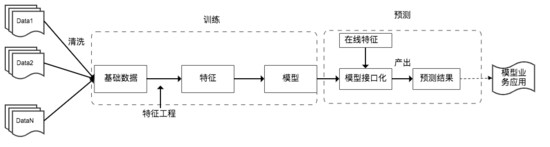
從上圖可以看出,機器學習模型的質量保障主要落在如下幾個方面:數據質量、特征質量、模型算法質量及模型效果評測。落到模型接口層還需要考慮接口的性能、穩定性。此外也需要考慮線上模型的安全性,尤其是無監督的深度神經網絡之類的模型。如:攻擊者通過精心設計的樣本來破壞模型的訓練數據或通過引入噪聲、干擾來“愚弄”模型,從而最終使模型做出錯誤的判斷。

進一步細化,得到如下模型質量保障總方案
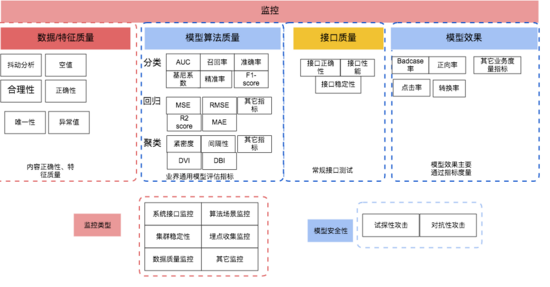
3. 我司模型質量保障現狀
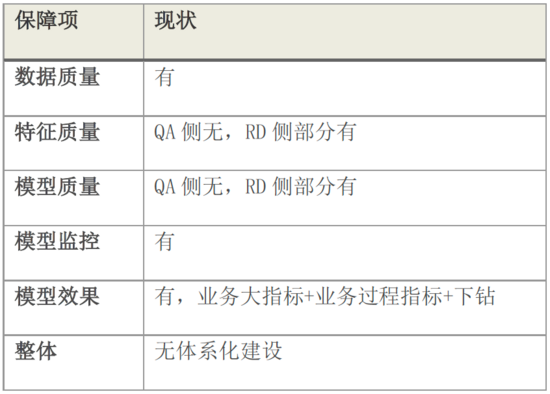
我司在機器學習模型質量保障方向上的落地主要體現在如下幾個方向:數據質量、接口質量、模型監控、模型效果評測等4個方向。其中模型監控的建設在各質量團隊內廣泛應用,是當前主要的兜底措施。模型算法質量當前主要由策略同學自行測算,而用戶視角的特征有效性、特征關聯性等特征質量度量尚有較大提升空間。
當前突出的問題是:模型從訓練到上線所依賴的基礎服務分散對口在各質量團隊,相互之間斷層沒有形成一個體系化的模型質量保障平臺。目前的一個利好消息是:原來分散在各團隊的機器學習模型訓練部署平臺目前正在逐漸收斂到統一的策略中臺,1.0版本已經上線。因此,接下來機器學習模型質量保障的重心將會集中在搭建體系化的模型質量保障平臺上,并在特征質量、模型效果評測上進一步深耕,抽象出通用評測能力落地平臺化。貼一張圖,來對當前我司在機器學習模型質量保障方面的現狀做個總結:
4. 模型效果評測實踐
▍ 4.1 背景
我們此前一直深耕在線上策略評測及badcase挖掘上,故對于策略線上效果的評測積累了較為豐富的經驗。 一次較為 偶然的機會開始對拼車ETD模型做效果評測。 實際演進的路線為: 線上 → 離線,線上主要從城市+業務線+場景多維度做模型效果應用指標 層評估,從而幫助策略同學更直觀的找出其主要偏 差場景, 其次我們對模型的業務鏈路進行了建模,將真實樣本數據映射到相應的節點上,從而度量出關鍵偏差路徑。 最后我們復用了此前積累的badcase下鉆能力,對模型業務鏈路上關鍵偏差節點進行了根因下鉆,從而找出了部分對模型效果有影響的一些新特征。
▍ 4.2 方案 及落地
具體方案貼圖如下:
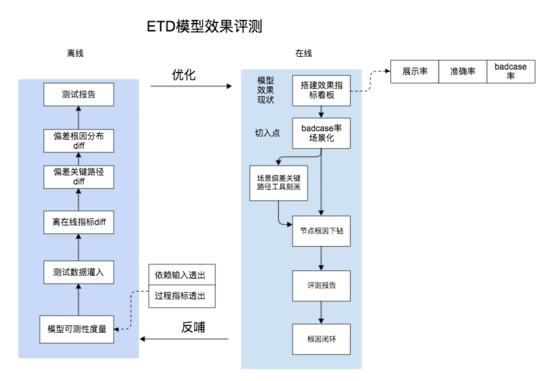
其中模型偏差關鍵路徑核心算法如下:
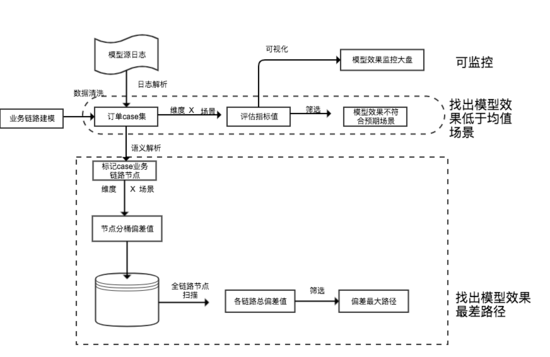
▍ 4.3 模型效果評測的價值點
總體來說,在機器學習模型效果評測方面,我們的價值點主要體現在如下幾個方面:
(1)場景化模型效果度量
(2)偏差關鍵路徑尋找
(3)模型潛在新特征的挖掘
(4)依賴對模型效果的負向影響度量
5. 總結
模型質量保障在國內外各大公司中,整體處于摸索建設階段。 主要原因為: 相對于傳統質量保障其難度大、技術要求高,模型應用背景差異大。 我司在整體模型質量保障方面,缺少體系化的建設,模型特征度量這一環無啥實際落地。 得益于長期以來,我們在線上策略評測和badcase挖掘方面的積累,在模型效果層面我們相對業界扎的更深,走在了業界前列,所做的工作對實際模型效果的提升起到了很好的輔助作用,但仍然需要進一步思考把對模型評測的通用能力抽象出來,落地平臺化,從而能更輕量的輔助策略團隊找到模型效果提升的切入點。






















