













NLP模型「可理解分析+評價排行榜」,CMU最新工具助你找到好idea
CMU 聯(lián)合復(fù)旦、俄亥俄州立大學(xué)的研究者推出了一個將模型可理解分析和模型評價排行榜結(jié)合起來的科研輔助工具 ExplainaBoard,能夠完成單系統(tǒng)診斷、數(shù)據(jù)集分析以及可信度分析等任務(wù),有效提升科研人員的學(xué)術(shù)體驗。
你是否在讀論文的時候覺得別人的 idea 很有道理,可自己設(shè)計 idea 時卻無從下手?你是否經(jīng)常因為「模型效果好,但是沒有給出有深度且全面的解釋」而被審稿人給低分?
當你厭倦了挖掘新的模型結(jié)構(gòu)時,是否對數(shù)據(jù)集特性的挖掘感興趣,從而引領(lǐng)一個更加健康的領(lǐng)域發(fā)展方向?在剛接觸一個新領(lǐng)域時,如何做到:既能快速了解該領(lǐng)域目前發(fā)展的狀況,又能快速了解它的瓶頸?
還記得不久前引起網(wǎng)絡(luò)熱議的自動審稿系統(tǒng)么?這支來自 CMU 的 團隊日前又發(fā)布了一個可解釋的系統(tǒng)排行榜(ExplainaBoard),它被定位成一個科研輔助產(chǎn)品,巧妙地把「模型可理解分析」和「模型評價排行榜」兩個看似無關(guān)的元素結(jié)合,將平時科研中很多被我們忽略卻很重要的部分轉(zhuǎn)化成「一鍵式」操作,從而提升科研人員做學(xué)術(shù)的體驗。

系統(tǒng)鏈接:
http://explainaboard.nlpedia.ai/
論文鏈接:
https://arxiv.org/pdf/2104.06387.pdf
目前,ExplainaBoard 在單任務(wù)上支持分類、抽取、生成在內(nèi)的9個主流 NLP 任務(wù),涉及40多個數(shù)據(jù)集、300多個模型;在多任務(wù)上,支持多語言評價基準,包含40多種語言和9個跨語言任務(wù)。
技術(shù)解讀
隨著深度學(xué)習(xí)模型的快速發(fā)展,排行榜(Leaderboard)已經(jīng)成為一種用來追蹤各種系統(tǒng)性能的主流工具。然而,由于在排行榜上排名靠前的模型所具有的聲望,很多研究人員只關(guān)注提高評估指標的數(shù)字,而忽略了對模型特性更深入的科學(xué)理解。
ExplainaBoard 就是在這樣的背景下誕生的,它不僅可以排序不同的模型,還提供了很多與模型和數(shù)據(jù)集相關(guān)的——可理解、可交互和可信賴的分析機制(如下圖所示):
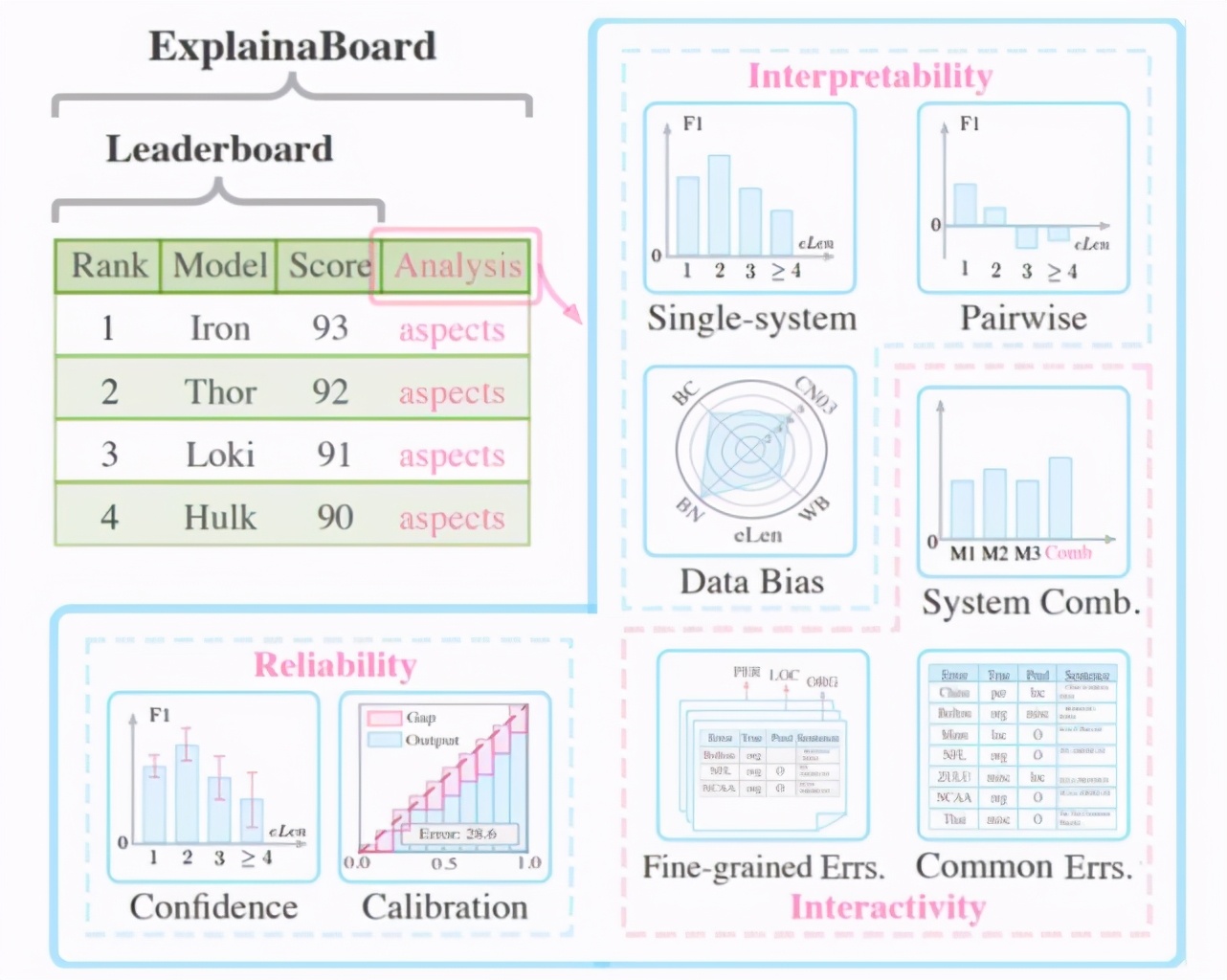
具體說來,它可以完成以下功能:
單系統(tǒng)診斷
可以解決的問題:「我設(shè)計的模型擅長 / 不擅長做什么?」

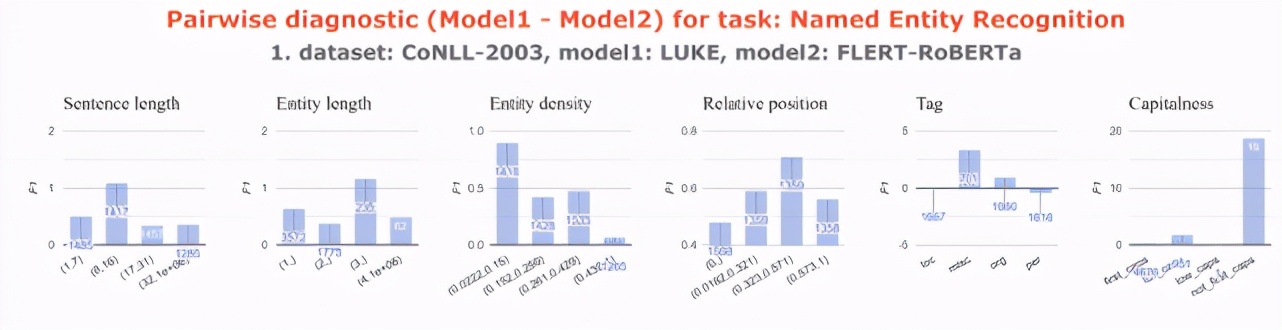
系統(tǒng)對診斷
可以解決的問題:「我設(shè)計的模型比別人的好在哪里?」
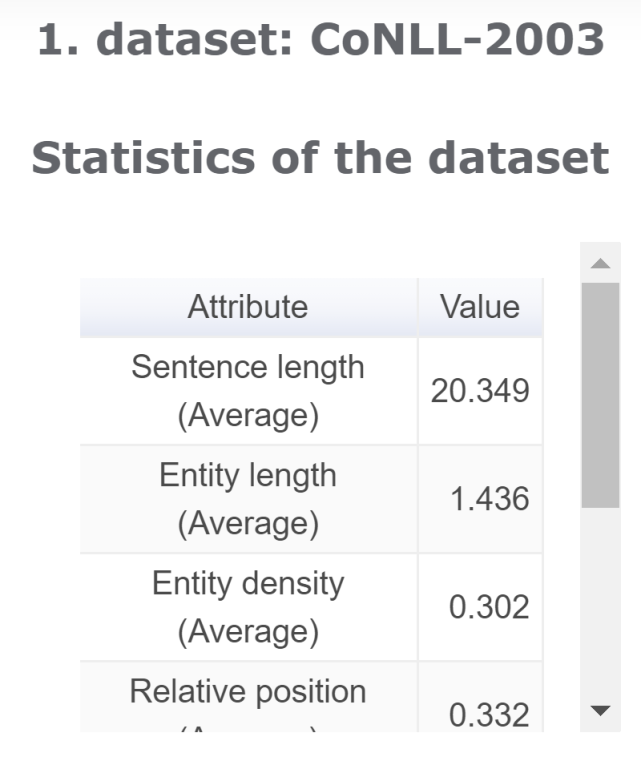
數(shù)據(jù)集分析
可以解決的問題:「數(shù)據(jù)集的特點是什么?」
共有錯誤分析
可以解決的問題:「排名 Top-5 的系統(tǒng)共同錯誤預(yù)測是什么?」

細粒度錯誤分析
可以解決的問題:「模型錯誤預(yù)測主要發(fā)生在哪兒,以及具體是哪些錯誤?」

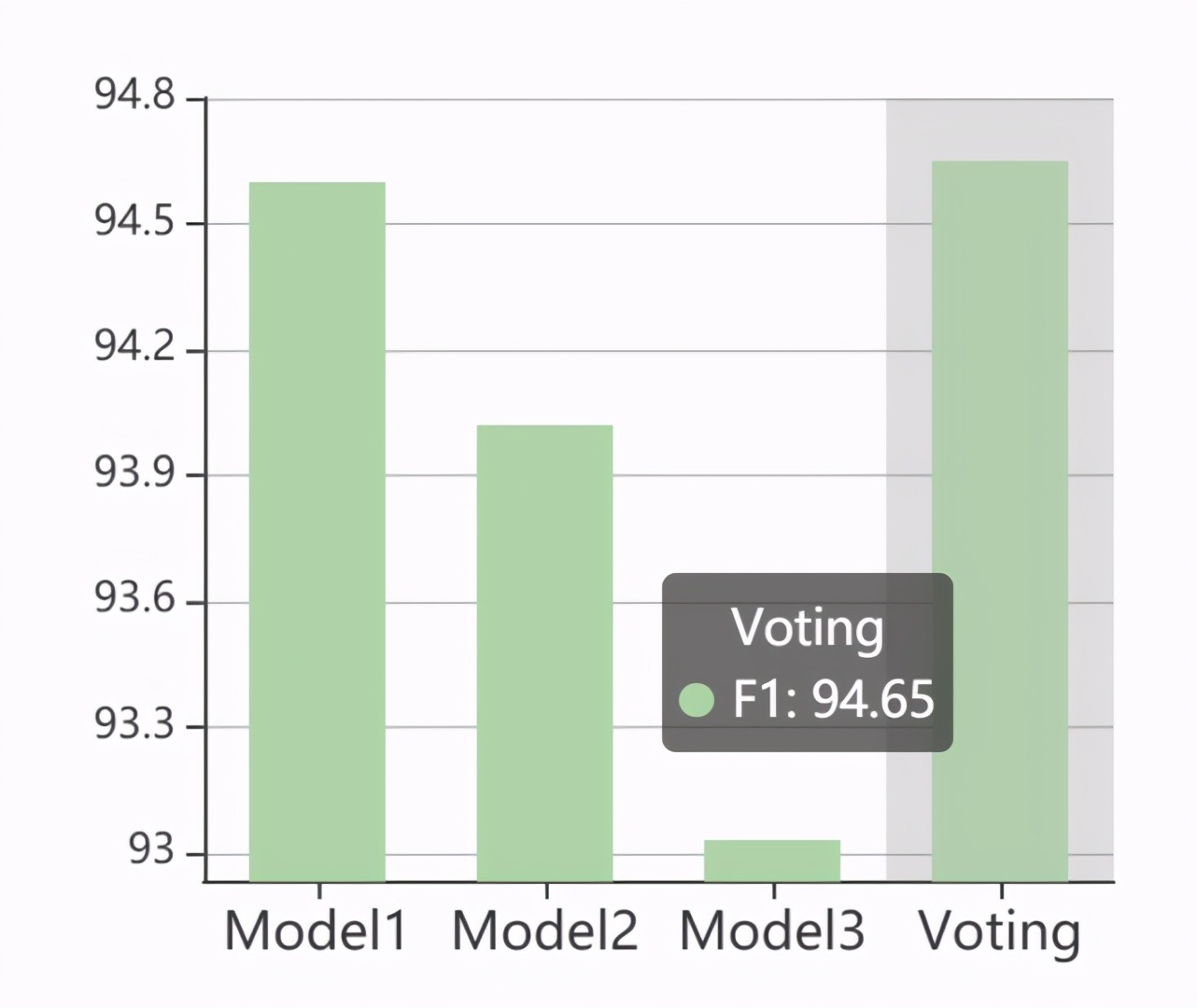
系統(tǒng)組合
可以解決的問題:「將排名 Top-5 的系統(tǒng)組合在一起,會得到一個更強大的系統(tǒng)么?」

可信度分析
可以解決的問題:「模型預(yù)測結(jié)果的可信程度有多高?」
校準分析
可以解決的問題:「預(yù)測的可信度是如何校準其正確性的?」
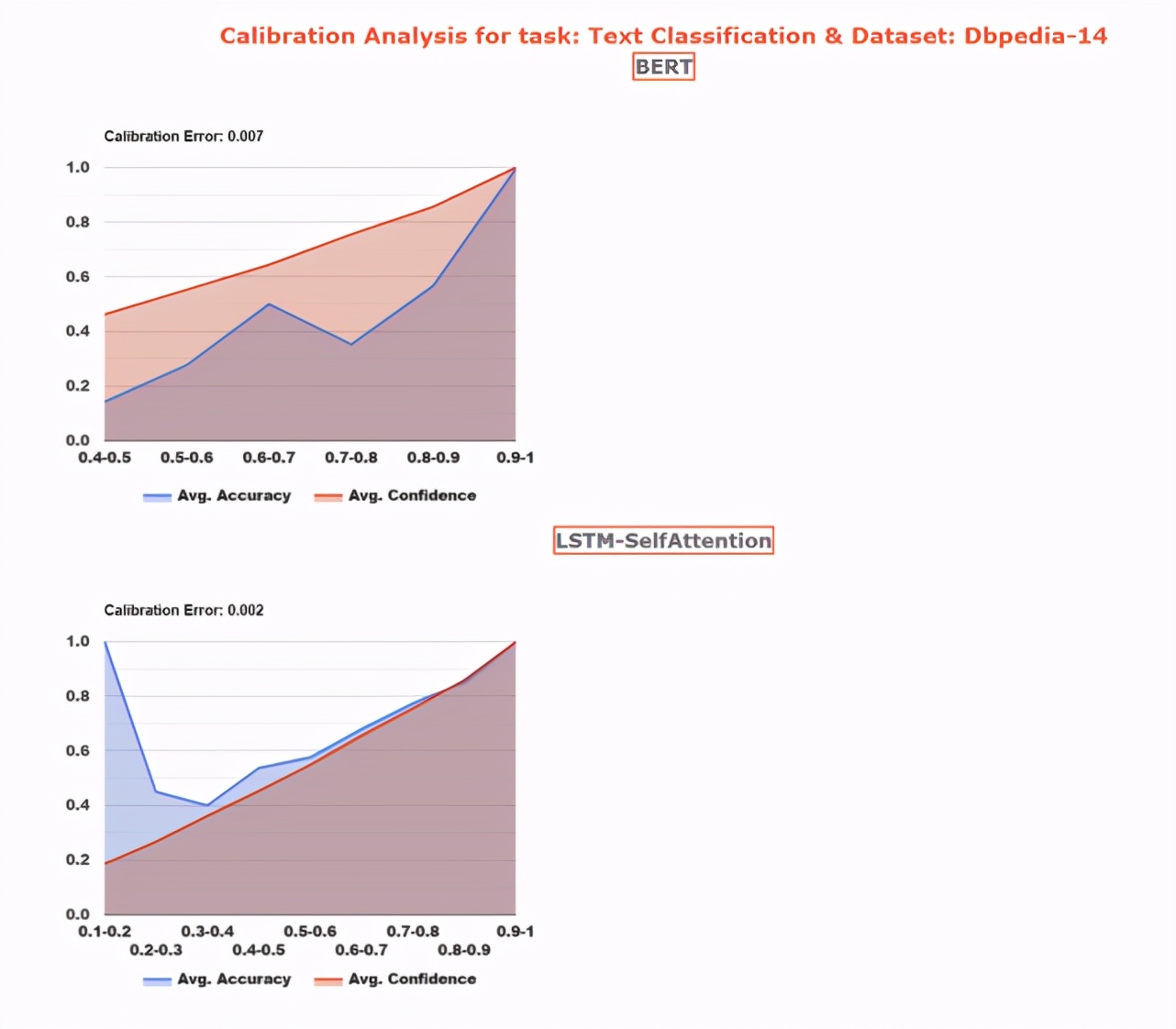
應(yīng)用前景
在應(yīng)用上,據(jù)該項目負責(zé)人劉鵬飛博士介紹,ExplainaBoard 目前收到了 DeepMind、Google、Huggingface 和 Paperswithcode 等多家企業(yè)的合作邀請以及投資人的青睞。
比如,Google & Deepmind 最新 arXiv 工作 XTREME-R: Towards More Challenging and Nuanced Multilingual Evaluation 使用 ExplainaBoard 升級了他們的多語言評測基準。






















