聯(lián)邦學(xué)習(xí)也不安全?英偉達(dá)研究用「沒有隱私」的數(shù)據(jù)直接重建原圖
聯(lián)邦學(xué)習(xí)因?yàn)閿?shù)據(jù)不出本地的隱私保護(hù)策略,一直被人們認(rèn)為是高效解決 AI 計(jì)算問題,并保護(hù)個(gè)人數(shù)據(jù)的重要方向,目前已經(jīng)出現(xiàn)了大量相關(guān)的研究和應(yīng)用。然而,隨著目前法律法規(guī)對于數(shù)據(jù)限制的加深,從梯度、模型參數(shù)中反推出用戶數(shù)據(jù)的方法正在顯現(xiàn)。
在不少情況下,利用被模糊的數(shù)據(jù),以及機(jī)器學(xué)習(xí)處理過程中的參數(shù),我們能夠重建出一個(gè)人的基本信息。而最近,英偉達(dá)的研究人員更進(jìn)一步,甚至直接通過機(jī)器學(xué)習(xí)中的梯度數(shù)據(jù)重建了圖像。新的研究讓人們不禁懷疑:聯(lián)邦學(xué)習(xí)難道實(shí)際上并不安全?
具體地,研究者提出了一種 GradInversion 方法,通過反轉(zhuǎn)給定的批平均梯度(batch-averaged gradients)從隨機(jī)噪聲中恢復(fù)隱藏的原始圖像。該研究已被計(jì)算機(jī)視覺頂會(huì) CVPR 2021 接收。
論文鏈接:
https://arxiv.org/pdf/2104.07586.pdf
研究者提出了一種標(biāo)簽修復(fù)方法,利用最后的全連接層梯度來恢復(fù)真值標(biāo)簽。他們還提出了一種群體一致性正則化項(xiàng),它是基于多種子優(yōu)化和圖像配準(zhǔn),用于提升圖像重建質(zhì)量。實(shí)驗(yàn)表明,對于 ResNet-50 這樣的深度網(wǎng)絡(luò),利用批平均梯度完全恢復(fù)細(xì)節(jié)豐富的單個(gè)圖像是可行的。
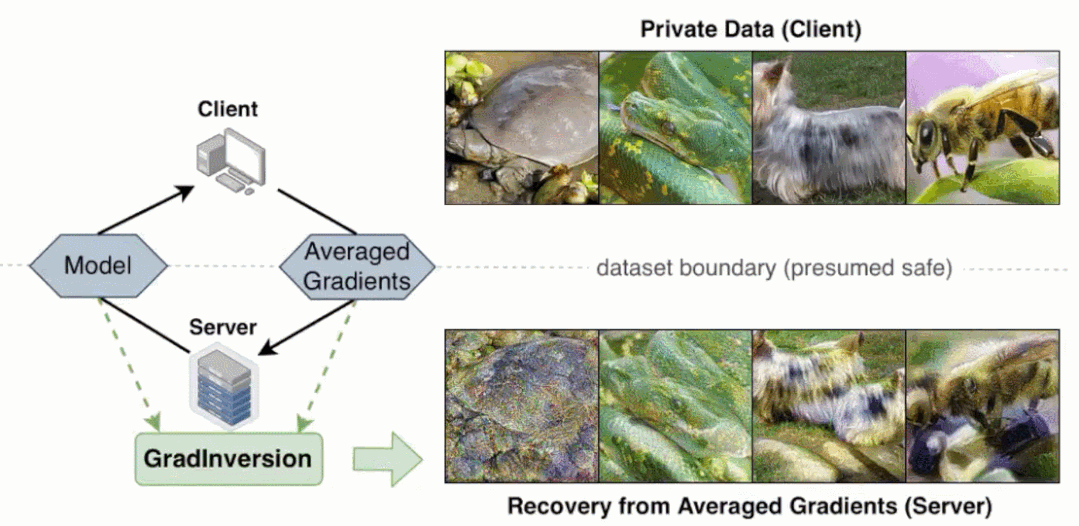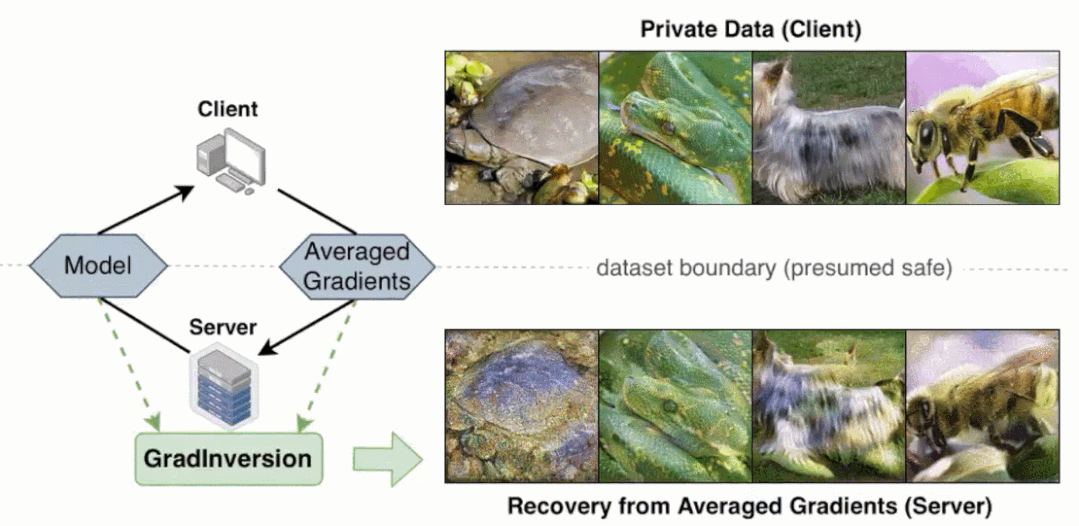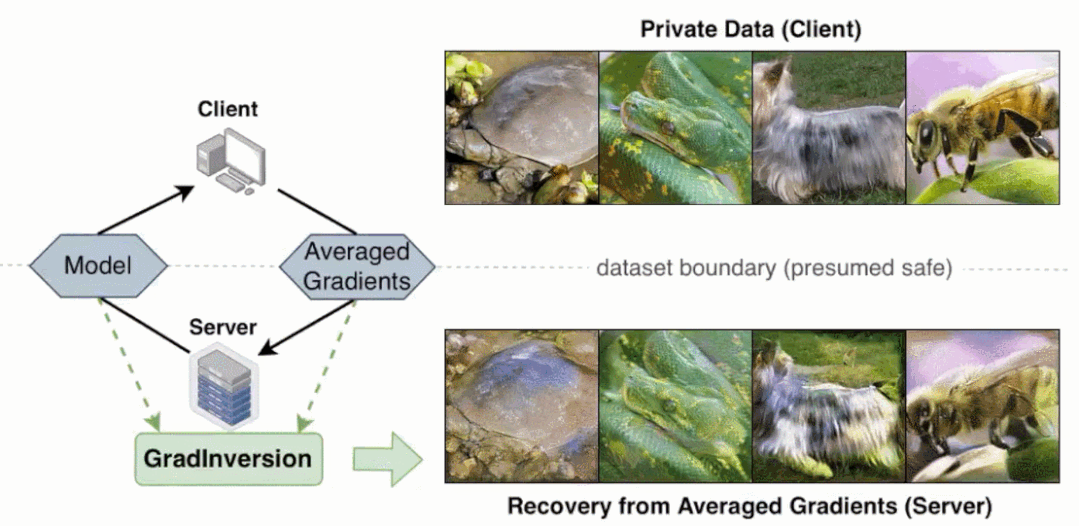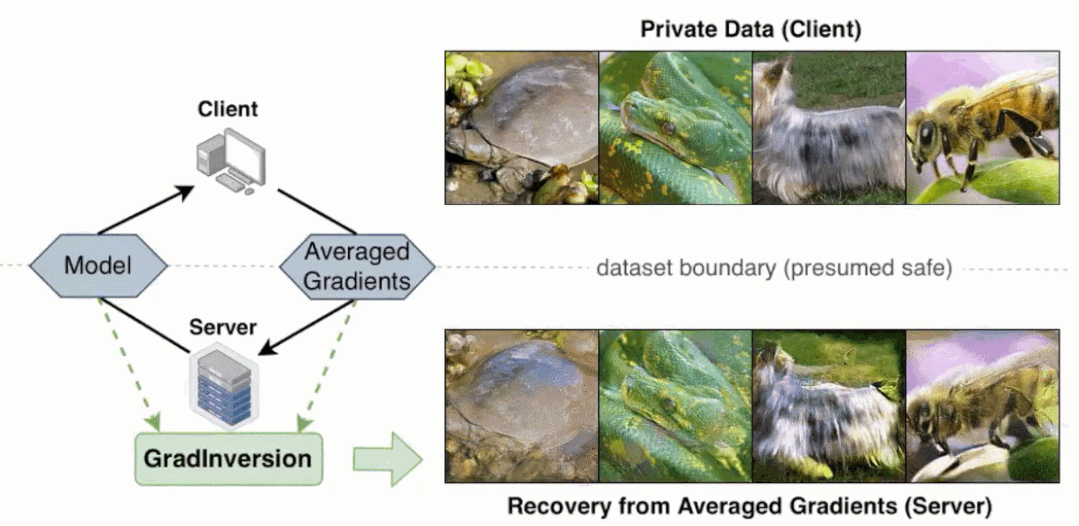
研究者在論文中表示,與 BigGAN 等 SOTA 生成對抗網(wǎng)絡(luò)相比,他們提出的非學(xué)習(xí)(non-learning)圖像恢復(fù)方法可以恢復(fù)隱藏輸入數(shù)據(jù)的更豐富細(xì)節(jié)。
更重要的是,即使當(dāng)圖像批大小增加至 48,通過反轉(zhuǎn)批梯度,該方法依然可以完全恢復(fù) 224×224 像素大小且具有高保真度和豐富細(xì)節(jié)的圖像。
對于這項(xiàng)研究的結(jié)果,有網(wǎng)友認(rèn)為:「這就是差分隱私(differential privacy, DP)存在的理由,沒有差分隱私的聯(lián)邦學(xué)習(xí)無法保證隱私。」

研究概述
下圖 1(a)中,研究者提出 GradInversion,通過反轉(zhuǎn)批平均梯度來恢復(fù)高保真度和豐富細(xì)節(jié)的隱藏訓(xùn)練圖像;圖 1(b)展示了將噪聲變換至輸入圖像的優(yōu)化過程,首先從全連接層的梯度中恢復(fù)標(biāo)簽,然后在保真度正則化和基于注冊的群體一致性正則化條件下優(yōu)化輸入以匹配目標(biāo)梯度,從而提升重建質(zhì)量。
這種方法能夠從 ResNet-50 批梯度中恢復(fù) 224×224 像素的 ImageNet 圖像樣本,這在以前是無法實(shí)現(xiàn)的。
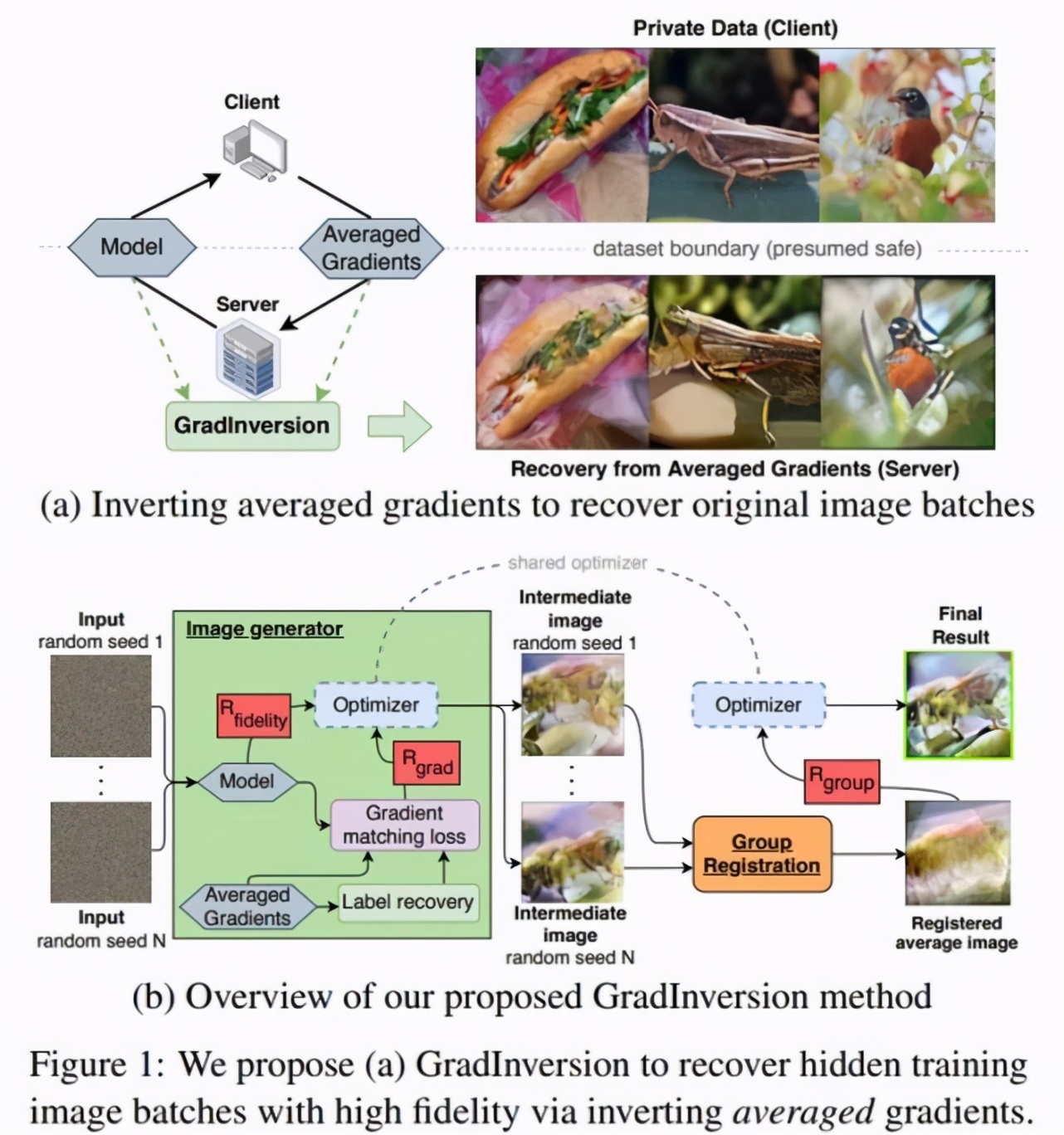
方法概覽。
由于卷積神經(jīng)網(wǎng)絡(luò)(CNN)的平移不變性,基于梯度的反轉(zhuǎn)面臨另一項(xiàng)挑戰(zhàn)——目標(biāo)對象的精確定位。在理想場景中,優(yōu)化可以收斂至一個(gè)真值(ground truth)。
但如下圖 2 所示,研究者觀察到,當(dāng)使用不同的 seed 重復(fù)優(yōu)化過程時(shí),每個(gè)優(yōu)化過程均可以得到局部最小值。這些局部最小值在所有層級上分配語義正確的圖像特征,但彼此之間又有不同:圖像圍繞著真值變換,并專注不同的細(xì)節(jié)。

研究者提出了一種群體一致性正則化項(xiàng),它通過聯(lián)合優(yōu)化的方式同時(shí)利用多個(gè) seed,具體流程如下圖 3 所示:

實(shí)驗(yàn)結(jié)果
研究者以 224×224 像素為范例,在大規(guī)模 1000-class ImageNet ILSVRC 2012 數(shù)據(jù)集上對該方法在分類任務(wù)上的效果進(jìn)行了評估。
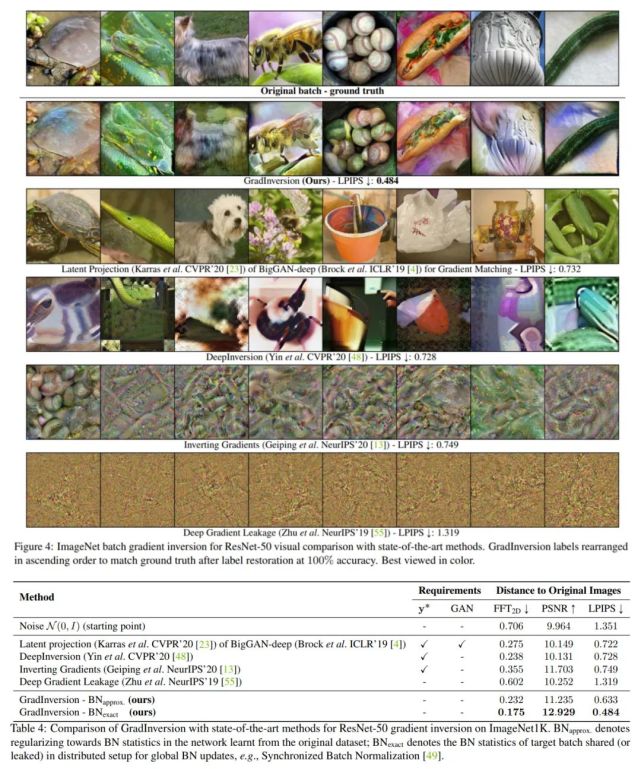
首先,他們在批大小為 8 時(shí),對 224×224 像素大小的圖像進(jìn)行了效果對比。下圖 4 和表 4 分別為 GradInversion 方法與 Latent Projection、DeepInversion、Inverting Gradients 和 Deep Gradient Leakage 等 SOTA 方法的定性和定量對比,結(jié)果顯示該方法在視覺效果和數(shù)值上均勝出。
接著,研究者增加了批大小,使用 32GB 英偉達(dá) V100 GPU 將批大小增至 48。如下圖 6 所示,隨著批大小的增加,可恢復(fù)圖像的數(shù)量逐漸減少。

不過,GradInversion 方法依然可以獲取一定數(shù)量的原始視覺信息,有時(shí)還能實(shí)現(xiàn)完整的重建,具體如下圖 7 所示:
一作簡介
該論文的一作是尹洪旭(Hongxu Yin),2015 年畢業(yè)于新加坡南洋理工大學(xué)電氣與電子工程專業(yè),獲工學(xué)學(xué)士學(xué)位,在美國普林斯頓大學(xué)電氣工程系攻讀博士學(xué)位,現(xiàn)在是英偉達(dá)(硅谷)研究科學(xué)家。
他的研究集中在高效的深度神經(jīng)網(wǎng)絡(luò)、無數(shù)據(jù)模型壓縮 / 神經(jīng)結(jié)構(gòu)搜索和邊緣醫(yī)療推理。
個(gè)人主頁:
https://scholar.princeton.edu/hongxu