一文學(xué)會(huì)效率提升技巧
之前跟大家分享過SQL和EXCEL效率提升的小技巧,鏈接放在了文章末尾,今天跟大家分享一下多年來一直用的python效率提升的方法。這個(gè)方法是某位上古大神傳授于我?guī)煾担瑤煾涤謧魇谟谖摇?/p>
我們平時(shí)在跑數(shù)據(jù)的時(shí)候可能會(huì)將數(shù)據(jù)結(jié)果存儲(chǔ)在txt文件中,不知道大家平時(shí)是怎么處理txt文件中的數(shù)據(jù)的,相信各位同學(xué)都有自己的方法,用python的pandas包或者把數(shù)據(jù)塞進(jìn)數(shù)據(jù)庫(kù)再用sql等等。無論是用哪種方法在處理數(shù)據(jù)的時(shí)候有很多方法是通用的,比如where,join等等,可以先將這些常用方法寫成python腳本,需要對(duì)txt文件的數(shù)據(jù)進(jìn)行處理時(shí)直接用腳本來處理txt文件。優(yōu)點(diǎn)在于省掉了txt和數(shù)據(jù)庫(kù)之間來回倒騰數(shù)據(jù)的時(shí)間,也省掉了用pandas讀取數(shù)據(jù)寫腳本的時(shí)間,能夠快速方便地驗(yàn)證和處理數(shù)據(jù)。
在舉例子之前要先介紹一個(gè)linux中“管道” 的概念,熟悉linux的人應(yīng)該對(duì)這個(gè)概念不陌生,符號(hào)為“|” ,管道的作用在于連接多條命令比如命令:cat data.txt|wc -l 的含義就是查看data中數(shù)據(jù)條數(shù),其中“|”就是管道,將cat data.txt的輸出作為wc -l的輸入。總結(jié)來說只要第一個(gè)命令向標(biāo)準(zhǔn)輸出寫入,而第二個(gè)命令是從標(biāo)準(zhǔn)輸入讀取,那么這兩個(gè)命令就可以形成一個(gè)管道。同樣我們可以用將輸出傳遞給python腳本。
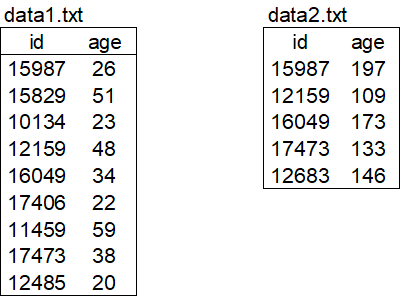
明白了管道的概念,那我們開始吧,案例數(shù)據(jù)如下:
data1.txt記錄用戶的id以及年齡,data2.txt記錄用戶的消費(fèi)信息
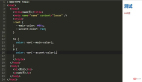
首先我們寫一個(gè)實(shí)現(xiàn)where功能的python腳本,腳本如下:
where.py
- #!/usr/bin/env python
- # -*- encoding:utf-8 -*-
- import sys
- import re
- import cutmode
- def where(col, cmpexpr, val, cmptype):
- sw ={
- '>': lambda y, x: y > x,
- '>=': lambda y, x: y >= x,
- '<': lambda y, x: y < x,
- '<=': lambda y, x: y <= x,
- '==': lambda y, x: y == x,
- '!=': lambda y, x: y != x,
- }
- for line in sys.stdin:
- line = line.strip()
- #data= re.split('\s+',line)
- data = line.split('\t')
- if len(data) <= col : continue
- if cmptype == 'int':
- number = int(data[col])
- val = int(val)
- elif cmptype == 'float':
- number = float(data[col])
- val = float(val)
- else:
- number = data[col]
- if sw[cmpexpr](number,val):
- print line.strip()
- if __name__ == '__main__':
- col = int(sys.argv[1])
- cmpexpr = sys.argv[2]
- val = sys.argv[3]
- cmptype = sys.argv[4]
- where(col, cmpexpr, val, cmptype)
程序就不一行行解釋了,簡(jiǎn)單來說一下幾個(gè)參數(shù),其中 python 程序的四個(gè)參數(shù)
- col 表示第幾列
- cmpexpr 表示比較運(yùn)算符(>,>=,<,<=,=,!=)
- val表示要比較的數(shù)字
- cmptype表示數(shù)據(jù)類型
我們篩選年齡大于24歲的用戶,指令和結(jié)果如下:
- cat data.txt|python where.py 1 '>=' 25 int

join.py
- #!/usr/bin/env python
- # -*- encoding:utf-8 -*-
- import sys
- import re
- def makeJoin(joinfields, file_list=[]):
- dict = {}
- file_last = open(file_list[-1])
- k, v = joinfields[-1].split(':')
- k, v = int(k),int(v)
- for line in file_last:
- sps = re.split('\s+', line)
- if len(sps) >= max(k,v):
- val = sps[v] if v >= 0 else ''
- dict.setdefault(sps[k], val)
- file_last.close()
- for i in xrange(len(file_list)-1):
- fd = open(file_list[i], 'r')
- field = joinfields[i].split(':')[0]
- for data in fd.readlines():
- attr = re.split('\t', data.strip())
- if len(attr) <= int(field):continue
- joinid = attr[int(field)]
- appendix = dict[joinid] if joinid in dict else 'noright'
- print data.strip() + '\t' + appendix
- fd.close()
- if __name__ == '__main__':
- joinfields = sys.argv[1].split(',')
- file_list = sys.argv[2:]
- makeJoin(joinfields, file_list)
下面將兩個(gè)數(shù)據(jù)進(jìn)行join,計(jì)算出每個(gè)用戶的年齡以及對(duì)應(yīng)的花費(fèi)。
指令如下:python join.py '0:1,0:1' 'data1.txt' 'data2.txt'
- 第一個(gè)0:1 表示data1.txt的鏈接主鍵為0列,值為1列
- 第二個(gè)0:1 表示data2.txt的鏈接主鍵為0列,值為1列
- data1.txt 和data2.txt 分別為需要鏈接的文件

select.py
- #!/usr/bin/env python
- # -*- encoding:utf-8 -*-
- import sys
- import re
- def cut(files,col1,col2):
- col1=int(col1)
- col2=int(col2)
- f=open
- for line in sys.stdin:
- line_list=line.split()
- if(len(line_list)>=max(col1,col2)):
- if col1>=0 and col2>=0 and col1<=col2:
- print("\t".join(line_list[col1:col2]))
- else:
- print("參數(shù)輸入錯(cuò)誤")
- else:
- print("參數(shù)超出范圍")
- if __name__=="__main__":
- col1=sys.argv[1]
- col2=sys.argv[2]
- cut(col1,col2)
取出有花費(fèi)的用戶id,指令如下:
- col1:開始列
- col2:結(jié)束列
python select.py 0 1 data2.txt
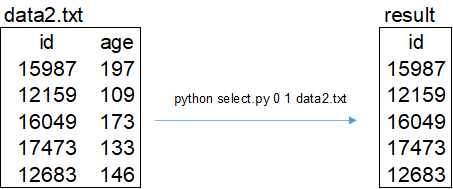
綜合使用
選出data1中付過費(fèi),且年齡大于35歲的用戶id
- python join.py '0:1,0:1' 'data1.txt' 'data2.txt'|python where.py 2 '!=' null string|python where.py 1 '>' 35 int|python select.py 0 1
- 12159
- 17473