一文學會注解的正確使用姿勢
前言
日志作為排查問題的重要手段,可以說是應用集成中必不可少的一環,但在日志中,又不宜暴露像電話,身份證,地址等個人敏感信息,去年 Q4 我司就開展了對 ELK 日志脫敏的全面要求。那么怎樣快速又有效地實現日志脫敏呢。相信讀者看完標題已經猜到了,沒錯,用注解!那么用注解該怎么實現日志脫敏呢,除了日志脫敏,注解還能用在哪些場景呢,注解的實現原理又是怎樣的呢。本文將會為你詳細介紹。
本文將會從以下幾個方面來介紹注解。
- 日志脫敏場景簡介
- 巧用注解解決這兩類問題
- 注解的定義與實現原理
- 使用注解解決日志脫敏
- 注解高級用法-解決銀行中參數傳遞順序要求
相信大家看了肯定有收獲!
日志脫敏場景簡介
在日志里我們的日志一般打印的是 model 的 Json string,比如有以下 model 類
- public class Request {
- /**
- * 用戶姓名
- */
- private String name;
- /**
- * 身份證
- */
- private String idcard;
- /**
- * 手機號
- */
- private String phone;
- /**
- * 圖片的 base64
- */
- private String imgBase64;
- }
有以下類實例
- Request request = new Request();
- request.setName("愛新覺羅");
- request.setIdcard("450111112222");
- request.setPhone("18611111767");
- request.setImgBase64("xxx");
我們一般使用 fastJson 來打印此 Request 的 json string:
- log.info(JSON.toJSONString(request));
這樣就能把 Request 的所有屬性值給打印出來,日志如下:
- {"idcard":"450111112222","imgBase64":"xxx","name":"張三","phone":"17120227942"}
這里的日志有兩個問題
- 安全性: name,phone, idcard 這些個人信息極其敏感,不應以明文的形式打印出來,我們希望這些敏感信息是以脫敏的形式輸出的
- 字段冗余:imgBase64 是圖片的 base64,是一串非常長的字符串,在生產上,圖片 base64 數據對排查問題幫助不大,反而會增大存儲成本,而且這個字段是身份證正反面的 base64,也屬于敏感信息,所以這個字段在日志中需要把它去掉。我們希望經過脫敏和瘦身(移除 imgBase64 字段)后的日志如下:
- {"idcard":"450******222","name":"愛**羅","phone":"186****1767","imgBase64":""}
可以看到各個字段最后都脫敏了,不過需要注意的這幾個字段的脫敏規則是不一樣的
- 身份證(idcard),保留前三位,后三位,其余打碼
- 姓名(name)保留前后兩位,其余打碼
- 電話號碼(phone)保持前三位,后四位,其余打碼
- 圖片的 base64(imgBase64)直接展示空字符串
該怎么實現呢,首先我們需要知道一個知識點,即 JSON.toJSONString 方法指定了一個參數 ValueFilter,可以定制要轉化的屬性。我們可以利用此 Filter 讓最終的 JSON string 不展示或展示脫敏后的 value。大概邏輯如下
- public class Util {
- public static String toJSONString(Object object) {
- try {
- return JSON.toJSONString(object, getValueFilter());
- } catch (Exception e) {
- return ToStringBuilder.reflectionToString(object);
- }
- }
- private static ValueFilter getValueFilter() {
- return (obj, key, value) -> {
- // obj-對象 key-字段名 value-字段值
- return 格式化后的value
- };
- }
如上圖示,我們只要在 getValueFilter 方法中對 value 作相關的脫敏操作,即可在最終的日志中展示脫敏后的日志。現在問題來了,該怎么處理字段的脫敏問題,我們知道有些字段需要脫敏,有些字段不需要脫敏,所以有人可能會根據 key 的名稱來判斷是否脫敏,代碼如下:
- private static ValueFilter getValueFilter() {
- return (obj, key, value) -> {
- // obj-對象 key-字段名 value-字段值
- if (Objects.equal(key, "phone")) {
- return 脫敏后的phone
- }
- if (Objects.equal(key, "idcard")) {
- return 脫敏后的idcard
- }
- if (Objects.equal(key, "name")) {
- return 脫敏后的name
- }
- // 其余不需要脫敏的按原值返回
- return value
- };
- }
這樣看起來確實實現了需求,但僅僅實現了需求就夠了嗎,這樣的實現有個比較嚴重的問題:
脫敏規則與具體的屬性名緊藕合,需要在 valueFilter 里寫大量的 if else 判斷邏輯,可擴展性不高,通用性不強,舉個簡單的例子,由于業務原因,在我們的工程中電話有些字段名叫 phone, 有些叫 tel,有些叫 telephone,它們的脫敏規則是一樣的,但你不得不在上面的方法中寫出如下丑陋的代碼。
- private static ValueFilter getValueFilter() {
- return (obj, key, value) -> {
- // obj-對象 key-字段名 value-字段值
- if (Objects.equal(key, "phone") || Objects.equal(key, "tel") || Objects.equal(key, "telephone") || ) {
- return 脫敏后的phone
- }
- // 其余不需要脫敏的按原值返回
- return value
- };
- }
那么能否用一種通用的,可擴展性好的方法來解決呢,相信你看到文章的標題已經心中有數了,沒錯,就是用的注解,接下來我們來看看什么是注解以及如何自定義注解
注解的定義與實現原理
注解(Annotation)又稱 Java 標注,是 JDK 5.0 引入的一種注釋機制,如果說代碼的注釋是給程序員看的,那么注解就是給程序看的,程序看到注解后就可以在運行時拿到注解,根據注解來增強運行時的能力,常見的應用在代碼中的注解有如下三個
- @Override 檢查該方法是否重寫了父類方法,如果發現父類或實現的接口中沒有此方法,則報編譯錯誤
- @Deprecated 標記過時的類,方法,屬性等
- @SuppressWarnings - 指示編譯器去忽略注解中聲明的警告。
那這些注解是怎么實現的呢,我們打開 @Override 這個注解看看
- @Documented
- @Retention(RetentionPolicy.RUNTIME)
- @Target(value={CONSTRUCTOR, FIELD, LOCAL_VARIABLE, METHOD, PACKAGE, PARAMETER, TYPE})
- public @interface Deprecated {
- }
可以看到 Deprecated 注解上又有 @Documented, @Retention, @Target 這些注解,這些注解又叫元注解,即注解 Deprecated 或其他自定義注解的注解,其他注解的行為由這些注解來規范和定義,這些元注解的類型及作用如下
- @Documented 表明它會被 javadoc 之類的工具處理, 這樣最終注解類型信息也會被包括在生成的文檔中
- @Retention 注解的保存策略,主要有以下三種
- RetentionPolicy.SOURCE 源代碼級別的注解,表示指定的注解只在編譯期可見,并不會寫入字節碼文件,Override, SuppressWarnings 就屬于此類型,這類注解對于程序員來說主要起到在編譯時提醒的作用,在運行保存意義并不大,所以最終并不會被編譯入字節碼文件中
- RetentionPolicy.RUNTIME 表示注解會被編譯入最終的字符碼文件中,JVM 啟動后也會讀入注解,這樣我們在運行時就可以通過反射來獲取這些注解,根據這些注解來做相關的操作,這是多數自定義注解使用的保存策略,這里可能大家有個疑問,為啥 Deprecated 被標為 RUNTIME 呢,對于程序員來說,理論上來說只關心調用的類,方法等是否 Deprecated 就夠了,運行時獲取有啥意義呢,考慮這樣一種場景,假設你想在生產上統計過時的方法被調用的頻率以評估你工程的壞味道或作為重構參考,此時這個注解是不是派上用場了。
- RetentionPolicy.CLASS 注解會被編譯入最終的字符碼文件,但并不會載入 JVM 中(在類加載的時候注解會被丟棄),這種保存策略不常用,主要用在字節碼文件的處理中。
- @Target 表示該注解可以用在什么地方,默認情況下可以用在任何地方,該注解的作用域主要通過 value 來指定,這里列舉幾個比較常見的類型:
- FIELD 作用于屬性
- METHOD 作用于方法
- ElementType.TYPE: 作用于類、接口(包括注解類型) 或 enum 聲明
@Inherited - 標記這個注解是繼承于哪個注解類(默認 注解并沒有繼承于任何子類)
再來看 @interface, 這個是干啥用的,其實如果你反編譯之后就會發現在字節碼中編譯器將其編碼成了如下內容。
- public interface Override extends Annotation {
- }
Annotation 是啥

我們可以看出注解的本質其實是繼承了 Annotation 這個接口的接口,并且輔以 Retention,Target 這些規范注解運行時行為,作用域等的元注解。
Deprecated 注解中沒有定義屬性,其實如果需要注解是可以定義屬性的,比如 Deprecated 注解可以定義一個 value 的屬性,在聲明注解的時候可以指定此注解的 value 值
- @Documented
- @Retention(RetentionPolicy.RUNTIME)
- @Target(value={CONSTRUCTOR, FIELD, LOCAL_VARIABLE, METHOD, PACKAGE, PARAMETER, TYPE})
- public @interface Deprecated {
- String value() default "";
- }
這樣我將此注解應用于屬性等地方時,可以指定此 value 值,如下所示
- public class Person {
- @Deprecated(value = "xxx")
- private String tail;
- }
如果注解的保存策略為 RetentionPolicy.RUNTIME,我們就可以用如下方式在運行時獲取注解,進而獲取注解的屬性值等
- field.getAnnotation(Deprecated.class);
巧用注解解決日志脫敏問題
上文簡述了注解的原理與寫法,接下來我們來看看如何用注解來實現我們的日志脫敏。
首先我們要定義一下脫敏的注解,由于此注解需要在運行時被取到,所以保存策略要為 RetentionPolicy.RUNTIME,另外此注解要應用于 phone,idcard 這些字段,所以@Target 的值為 ElementType.FIELD,另外我們注意到,像電話號碼,身份證這些字段雖然都要脫敏,但是它們的脫敏策略不一樣,所以我們需要為此注解定義一個屬性,這樣可以指定它的屬性屬于哪種脫敏類型,我們定義的脫敏注解如下:
- // 敏感信息類型
- public enum SensitiveType {
- ID_CARD, PHONE, NAME, IMG_BASE64
- }
- @Target({ ElementType.FIELD })
- @Retention(RetentionPolicy.RUNTIME)
- public @interface SensitiveInfo {
- SensitiveType type();
- }
定義好了注解,現在就可以為我們的敏感字段指定注解及其敏感信息類型了,如下
- public class Request {
- @SensitiveInfo(type = SensitiveType.NAME)
- private String name;
- @SensitiveInfo(type = SensitiveType.ID_CARD)
- private String idcard;
- @SensitiveInfo(type = SensitiveType.PHONE)
- private String phone;
- @SensitiveInfo(type = SensitiveType.IMG_BASE64)
- private String imgBase64;
- }
為屬性指定好了注解,該怎么根據注解來實現相應敏感字段類型的脫敏呢,可以用反射,先用反射獲取類的每一個 Field,再判定 Field 上是否有相應的注解,若有,再判斷此注解是針對哪種敏感類型的注解,再針對相應字段做相應的脫敏操作,直接上代碼,注釋寫得很清楚了,相信大家應該能看懂
- private static ValueFilter getValueFilter() {
- return (obj, key, value) -> {
- // obj-對象 key-字段名 value-字段值
- try {
- // 通過反射獲取獲取每個類的屬性
- Field[] fields = obj.getClass().getDeclaredFields();
- for (Field field : fields) {
- if (!field.getName().equals(key)) {
- continue;
- }
- // 判定屬性是否有相應的 SensitiveInfo 注解
- SensitiveInfo annotation = field.getAnnotation(SensitiveInfo.class);
- // 若有,則執行相應字段的脫敏方法
- if (null != annotation) {
- switch (annotation.type()) {
- case PHONE:
- return 電話脫敏;
- case ID_CARD:
- return 身份證脫敏;
- case NAME:
- return 姓名脫敏;
- case IMG_BASE64:
- return ""; // 圖片的 base 64 不展示,直接返回空
- default:
- // 這里可以拋異常
- }
- }
- }
- }
- } catch (Exception e) {
- log.error("To JSON String fail", e);
- }
- return value;
- };
- }
有人可能會說了,使用注解的方式來實現脫敏代碼量翻了一倍不止,看起來好像不是很值得,其實不然,之前的方式,脫敏規則與某個字段名強藕合,可維護性不好,而用注解的方式,就像工程中出現的 phone, tel,telephone 這些都屬于電話脫敏類型的,只要統一標上 **@SensitiveInfo(type = SensitiveType.PHONE) ** 這樣的注解即可,而且后續如有新的脫敏類型,只要重新加一個 SensitiveType 的類型即可,可維護性與擴展性大大增強。所以在這類場景中,使用注解是強烈推薦的。
注解的高級應用-利用注解消除重復代碼
在與銀行對接的過程中,銀行提供了一些 API 接口,對參數的序列化有點特殊,不使用 JSON,而是需要我們把參數依次拼在一起構成一個大字符串。
- 按照銀行提供的 API 文檔的順序,把所有參數構成定長的數據,然后拼接在一起作為整個字符串。
- 因為每一種參數都有固定長度,未達到長度時需要做填充處理:
- 字符串類型的參數不滿長度部分需要以下劃線右填充,也就是字符串內容靠左;
- 數字類型的參數不滿長度部分以 0 左填充,也就是實際數字靠右;
- 貨幣類型的表示需要把金額向下舍入 2 位到分,以分為單位,作為數字類型同樣進行左填充。
對所有參數做 MD5 操作作為簽名(為了方便理解,Demo 中不涉及加鹽處理)。簡單看兩個銀行的接口定義
1、創建用戶
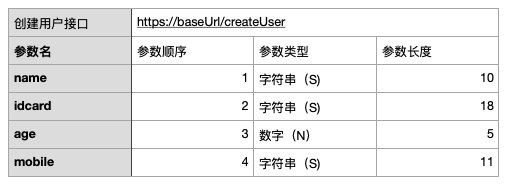
在這里插入圖片描述
2、支付接口
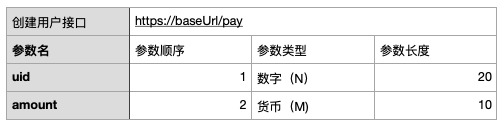
常規的做法是為每個接口都根據之前的規則填充參數,拼接,驗簽,以以上兩個接口為例,先看看常規做法
創建用戶與支付的請求如下:
- // 創建用戶 POJO
- @Data
- public class CreateUserRequest {
- private String name;
- private String identity;
- private String mobile;
- private int age;
- }
- // 支付 POJO
- @Data
- public class PayRequest {
- private long userId;
- private BigDecimal amount;
- }
- public class BankService {
- //創建用戶方法
- public static String createUser(CreateUserRequest request) throws IOException {
- StringBuilder stringBuilder = new StringBuilder();
- //字符串靠左,多余的地方填充_
- stringBuilder.append(String.format("%-10s", request.getName()).replace(' ', '_'));
- //字符串靠左,多余的地方填充_
- stringBuilder.append(String.format("%-18s", request.getIdentity()).replace(' ', '_'));
- //數字靠右,多余的地方用0填充
- stringBuilder.append(String.format("%05d", age));
- //字符串靠左,多余的地方用_填充
- stringBuilder.append(String.format("%-11s", mobile).replace(' ', '_'));
- //最后加上MD5作為簽名
- stringBuilder.append(DigestUtils.md2Hex(stringBuilder.toString()));
- return Request.Post("http://baseurl/createUser")
- .bodyString(stringBuilder.toString(), ContentType.APPLICATION_JSON)
- .execute().returnContent().asString();
- }
- //支付方法
- public static String pay(PayRequest request) throws IOException {
- StringBuilder stringBuilder = new StringBuilder();
- //數字靠右,多余的地方用0填充
- stringBuilder.append(String.format("%020d", request.getUserId()));
- //金額向下舍入2位到分,以分為單位,作為數字靠右,多余的地方用0填充
- stringBuilder.append(String.format("%010d",request.getAmount().setScale(2,RoundingMode.DOWN).multiply(new BigDecimal("100")).longValue()));
- //最后加上MD5作為簽名
- stringBuilder.append(DigestUtils.md2Hex(stringBuilder.toString()));
- return Request.Post("http://baseurl//pay")
- .bodyString(stringBuilder.toString(), ContentType.APPLICATION_JSON)
- .execute().returnContent().asString();
- }
- }
可以看到光寫這兩個請求,邏輯就有很多重復的地方:
1、 字符串,貨幣,數字三種類型的格式化邏輯大量重復,以處理字符串為例

可以看到,格式化字符串的的處理只是每個字段的長度不同,其余格式化規則完全一樣,但在上文中我們卻為每一個字符串都整了一套相同的處理邏輯,這套拼接規則完全可以抽出來(因為只是長度不一樣,拼接規則是一樣的)
2、 處理流程中字符串拼接、加簽和發請求的邏輯,在所有方法重復。
3、 由于每個字段參與拼接的順序不一樣,這些需要我們人肉硬編碼保證這些字段的順序,維護成本極大,而且很容易出錯,想象一下如果參數達到幾十上百個,這些參數都需要按一定順序來拼接,如果要人肉來保證,很難保證正確性,而且重復工作太多,得不償失
接下來我們來看看如何用注解來極大簡化我們的代碼。
1、 首先對于每一個調用接口來說,它們底層都是需要請求網絡的,只是請求方法不一樣,針對這一點 ,我們可以搞一個如下針對接口的注解
- @Retention(RetentionPolicy.RUNTIME)
- @Target(ElementType.TYPE)
- @Documented
- @Inherited
- public @interface BankAPI {
- String url() default "";
- String desc() default "";
- }
這樣在網絡請求層即可統一通過注解獲取相應接口的方法名
2、 針對每個請求接口的 POJO,我們注意到每個屬性都有 類型(字符串/數字/貨幣),長度,順序這三個屬性,所以可以定義一個注解,包含這三個屬性,如下
- @Retention(RetentionPolicy.RUNTIME)
- @Target(ElementType.FIELD)
- @Documented
- @Inherited
- public @interface BankAPIField {
- int order() default -1;
- int length() default -1;
- String type() default ""; // M代表貨幣,S代表字符串,N代表數字
- }
接下來我們將上文中定義的注解應用到上文中的請求 POJO 中
對于創建用戶請求
- @BankAPI(url = "/createUser", desc = "創建用戶接口")
- @Data
- public class CreateUserAPI extends AbstractAPI {
- @BankAPIField(order = 1, type = "S", length = 10)
- private String name;
- @BankAPIField(order = 2, type = "S", length = 18)
- private String identity;
- @BankAPIField(order = 4, type = "S", length = 11) //注意這里的order需要按照API表格中的順序
- private String mobile;
- @BankAPIField(order = 3, type = "N", length = 5)
- private int age;
- }
對于支付接口
- @BankAPI(url = "/bank/pay", desc = "支付接口")
- @Data
- public class PayAPI extends AbstractAPI {
- @BankAPIField(order = 1, type = "N", length = 20)
- private long userId;
- @BankAPIField(order = 2, type = "M", length = 10)
- private BigDecimal amount;
- }
接下來利用注解來調用的流程如下
- 根據反射獲取類的 Field 數組,然后再根據 Field 的 BankAPIField 注解中的 order 值對 Field 進行排序
- 對排序后的 Field 依次進行遍歷,首先判斷其類型,然后根據類型再對其值格式化,如判斷為"S",則按接口要求字符串的格式對其值進行格式化,將這些格式化后的 Field 值依次拼接起來并進行簽名
- 拼接后就是發請求了,此時再拿到 POJO 類的注解,獲取注解 BankAPI 的 url 值,將其與 baseUrl 組合起來即可構成一個完整的的 url,再加上第 2 步中拼接字符串即可構造一個完全的請求
代碼如下:
- private static String remoteCall(AbstractAPI api) throws IOException {
- //從BankAPI注解獲取請求地址
- BankAPI bankAPI = api.getClass().getAnnotation(BankAPI.class);
- bankAPI.url();
- StringBuilder stringBuilder = new StringBuilder();
- Arrays.stream(api.getClass().getDeclaredFields()) //獲得所有字段
- .filter(field -> field.isAnnotationPresent(BankAPIField.class)) //查找標記了注解的字段
- .sorted(Comparator.comparingInt(a -> a.getAnnotation(BankAPIField.class).order())) //根據注解中的order對字段排序
- .peek(field -> field.setAccessible(true)) //設置可以訪問私有字段
- .forEach(field -> {
- //獲得注解
- BankAPIField bankAPIField = field.getAnnotation(BankAPIField.class);
- Object value = "";
- try {
- //反射獲取字段值
- value = field.get(api);
- } catch (IllegalAccessException e) {
- e.printStackTrace();
- }
- //根據字段類型以正確的填充方式格式化字符串
- switch (bankAPIField.type()) {
- case "S": {
- stringBuilder.append(String.format("%-" + bankAPIField.length() + "s", value.toString()).replace(' ', '_'));
- break;
- }
- case "N": {
- stringBuilder.append(String.format("%" + bankAPIField.length() + "s", value.toString()).replace(' ', '0'));
- break;
- }
- case "M": {
- if (!(value instanceof BigDecimal))
- throw new RuntimeException(String.format("{} 的 {} 必須是BigDecimal", api, field));
- stringBuilder.append(String.format("%0" + bankAPIField.length() + "d", ((BigDecimal) value).setScale(2, RoundingMode.DOWN).multiply(new BigDecimal("100")).longValue()));
- break;
- }
- default:
- break;
- }
- });
- //簽名邏輯
- stringBuilder.append(DigestUtils.md2Hex(stringBuilder.toString()));
- String param = stringBuilder.toString();
- long begin = System.currentTimeMillis();
- //發請求
- String result = Request.Post("http://localhost:45678/reflection" + bankAPI.url())
- .bodyString(param, ContentType.APPLICATION_JSON)
- .execute().returnContent().asString();
- log.info("調用銀行API {} url:{} 參數:{} 耗時:{}ms", bankAPI.desc(), bankAPI.url(), param, System.currentTimeMillis() - begin);
- return result;
- }
現在再來看一下創建用戶和付款的邏輯
- //創建用戶方法
- public static String createUser(CreateUserAPI request) throws IOException {
- return remoteCall(request);
- }
- //支付方法
- public static String pay(PayAPI request) throws IOException {
- return remoteCall(request);
- }
可以看到所有的請求現在都只要統一調用 remoteCall 這個方法即可,remoteCall 這個方法統一了所有請求的邏輯,省略了巨量無關的代碼,讓代碼的可維護性大大增強!使用注解和反射讓我們可以對這類結構性的問題進行通用化處理,確實 Cool!
總結
如果說反射給了我們在不知曉類結構的情況下按照固定邏輯處理類成員的能力的話,注解則是擴展補充了這些成員的元數據的能力,使用得我們在利用反射實現通用邏輯的時候,可以從外部獲取更多我們關心的數據,進而對這些數據進行通用的處理,巧用反射,確實能讓我們達到事半功倍的效果,能極大的減少重復代碼,有效解藕,使擴展性大大提升。