













只需2層線性層,就能超越自注意力機制,清華計圖團隊又有新突破
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
5月4日,谷歌團隊在arXiv上提交了一篇論文“MLP-Mixer: An all-MLP Architecture for Vision”[1],引起了廣大計算機視覺的研究人員的熱烈討論:MLP究竟有多大的潛力?
5月5日,清華大學圖形學實驗室Jittor團隊在arXiv上提交論文“Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks”[2], 提出了一種新的注意機制,稱之為“External Attention”。
基于兩個外部的、小的、可學習的和共享的存儲器,只用兩個級聯的線性層和歸一化層就可以取代了現有流行的學習架構中的“Self-attention”,揭示了線性層和注意力機制之間的關系。
同日,清華大學軟件學院丁貴廣團隊在arXiv上提交了論文“RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition”[3],展示了結合重參數化技術的MLP也取得了非常不錯的效果。
5月6日牛津大學的學者提交了一篇名為”Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet”的論文[4],也提出了Transformer中的attention是不必要的,僅僅使用Feed forward就可以在ImageNet上實現非常高的結果。
從Self-attention到External-attention
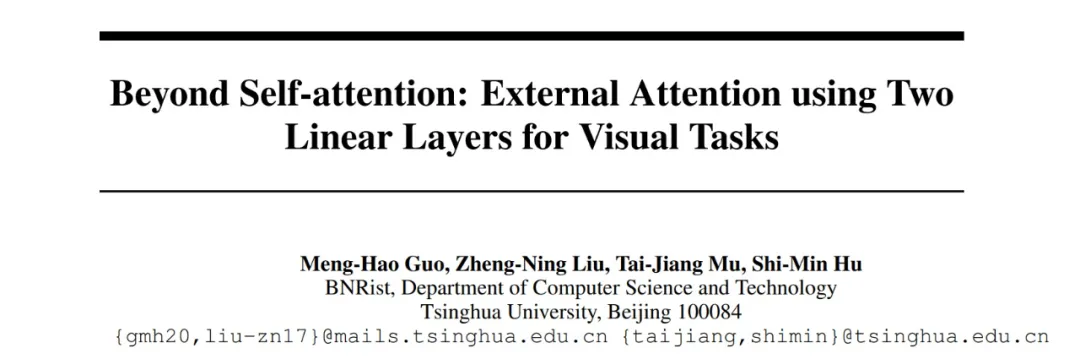
自注意力機制在自然語言處理和計算機視覺領域中起到了越來越重要的作用。對于輸入的Nxd維空間的特征向量F,自注意力機制使用基于自身線性變換的Query,Key和Value特征去計算自身樣本內的注意力,并據此更新特征:
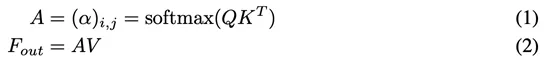
由于QKV是F的線性變換,簡單起見,我們可以將自注意力計算公式簡記如下:

這是F對F的注意力,也就是所謂的Self-attention。如果希望注意力機制可以考慮到來自其他樣本的影響,那么就需要一個所有樣本共享的特征。為此,我們引入一個外部的Sxd維空間的記憶單元M,來刻畫所有樣本最本質的特征,并用M來表示輸入特征。
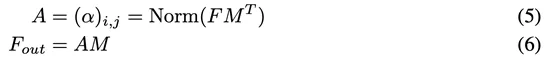
我們稱這種新的注意力機制為External-attention。我們可以發現,公式(5)(6)中的計算主要是矩陣乘法,就是常見的線性變換,一個自注意力機制就這樣被兩層線性層和歸一化層代替了。我們還使用了之前工作[5]中提出的Norm方式來避免某一個特征向量的過大而引起的注意力失效問題。
為了增強External-attention的表達能力,與自注意力機制類似,我們采用兩個不同的記憶單元。

下圖形象地展示了External-attention與Self-attention的區別。
△圖1 Self Attention和External Attention的區別
為什么兩層線性層可以超越Self-attention?
自注意力機制一個明顯的缺陷在于計算量非常大,存在一定的計算冗余。通過控制記憶單元的大小,External-attention可以輕松實現線性的復雜度。
其次,自注意力機制僅利用了自身樣本內的信息,忽略了不同樣本之間的潛在的聯系,而這種聯系在計算機視覺中是有意義的。打個比方,對于語義分割任務,不同樣本中的相同類別的物體應該具有相似的特征。
External-attention通過引入兩個外部記憶單元,隱式地學習了整個數據集的特征。這種思想同樣在稀疏編碼和字典學習中得到了應用。
計圖團隊在Pascal VOC 的Test set上,可視化了注意力圖以及分割的結果,如圖2所示,可以發現,使用兩層線性層的External attention 的注意力圖是合理的。
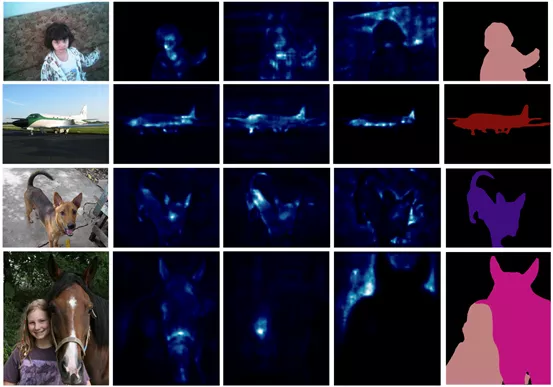
△圖2 注意力圖以及分割的結果的可視化
從實驗看External Attention的效果
為了證明方法的通用性,我們在圖像分類、分割、生成以及點云的分類和分割上均做了實驗,證明了方法的有效性,External-attention在大大減少計算量的同時,可以取得與目前最先進方法相當,甚至更好的結果。
1、圖像分類

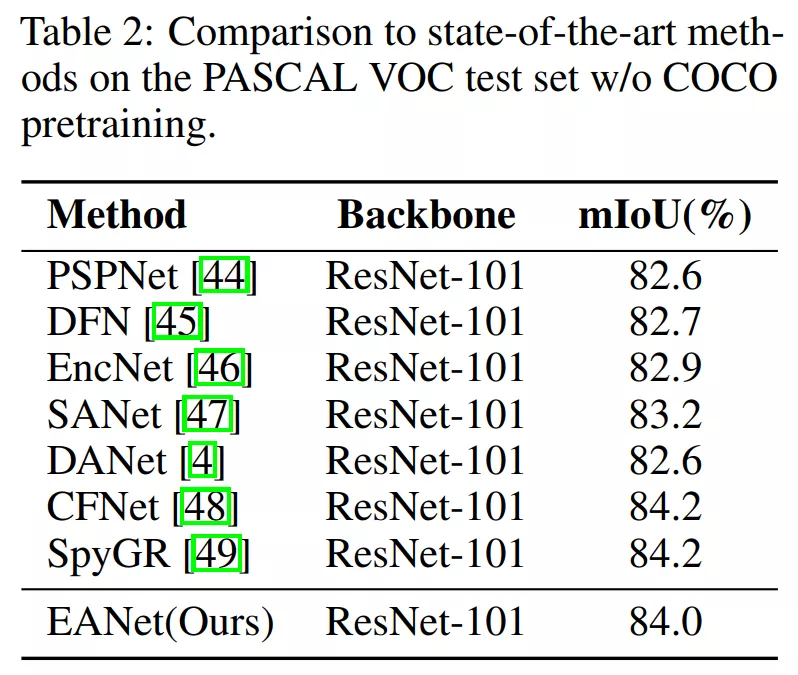
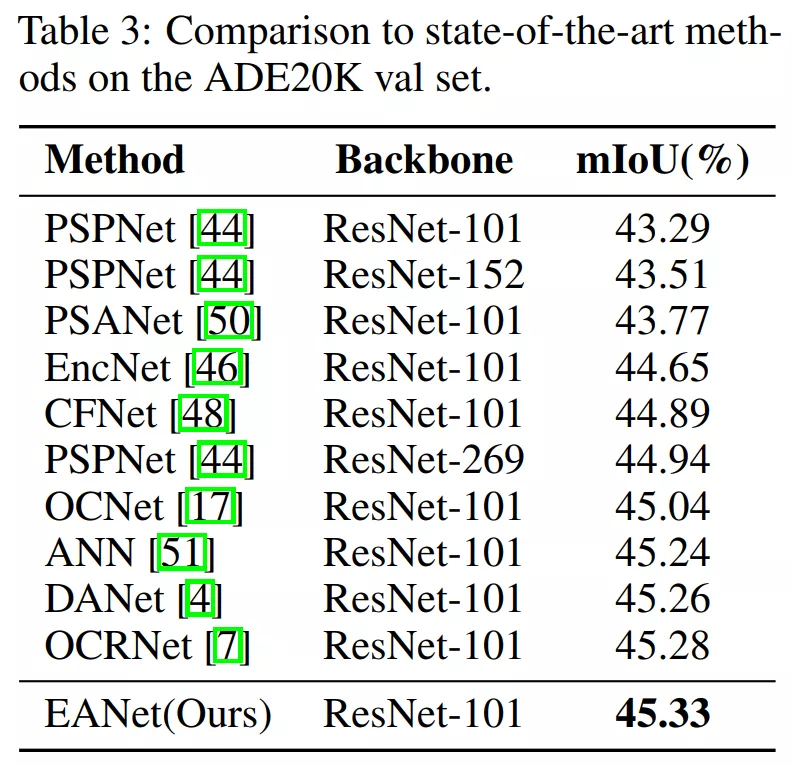
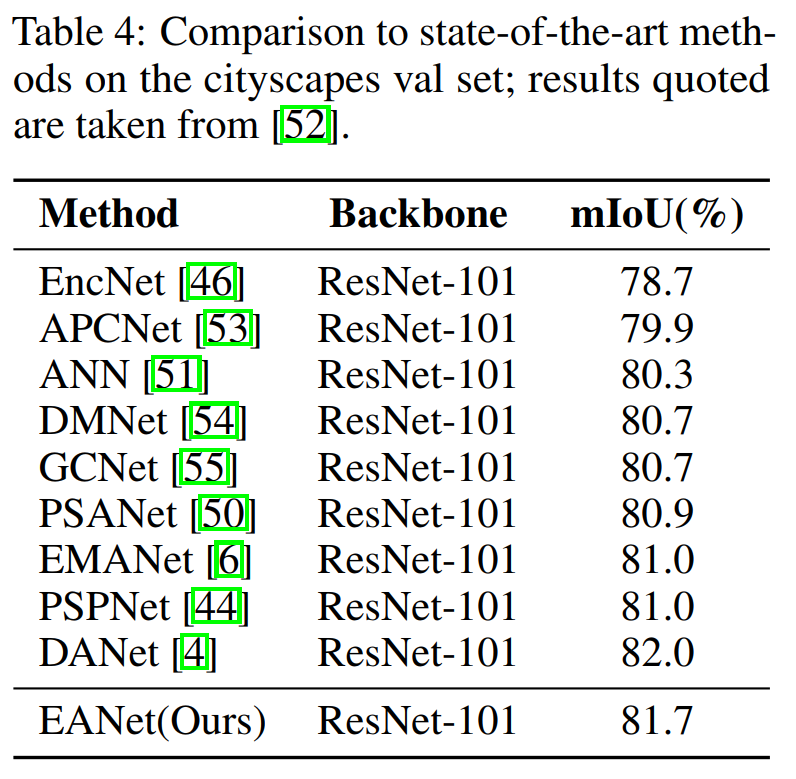
2、圖像語義分割(三個數據集上)
3、圖像生成
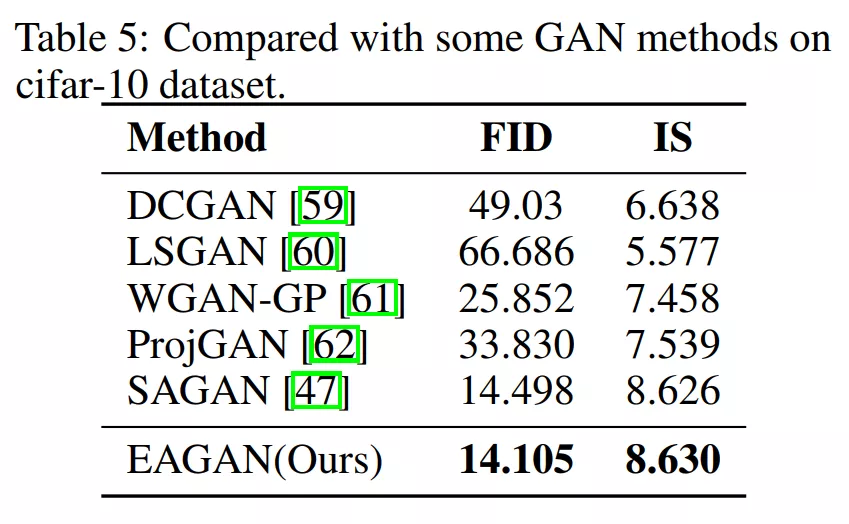
4、點云分類
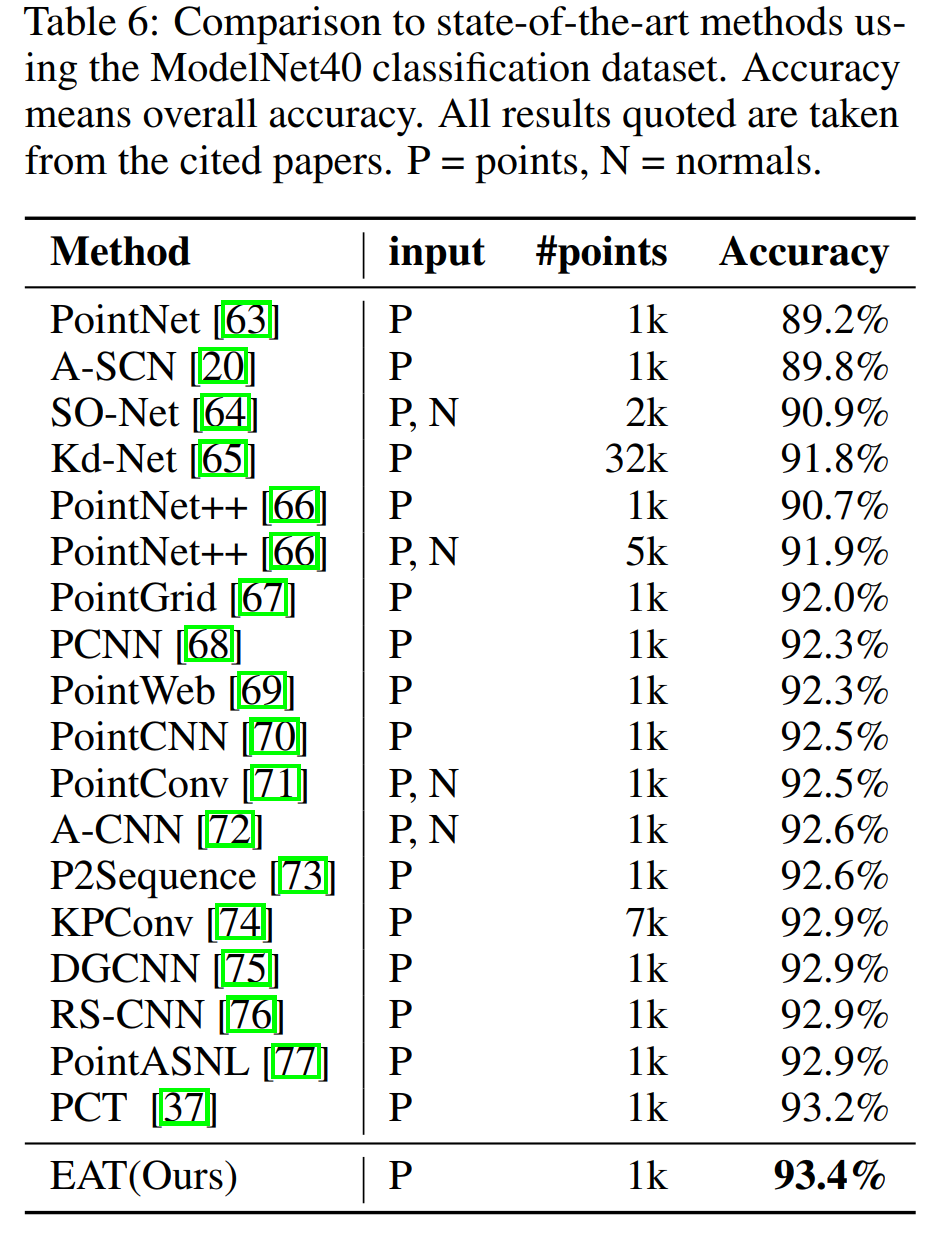
5、點云分割
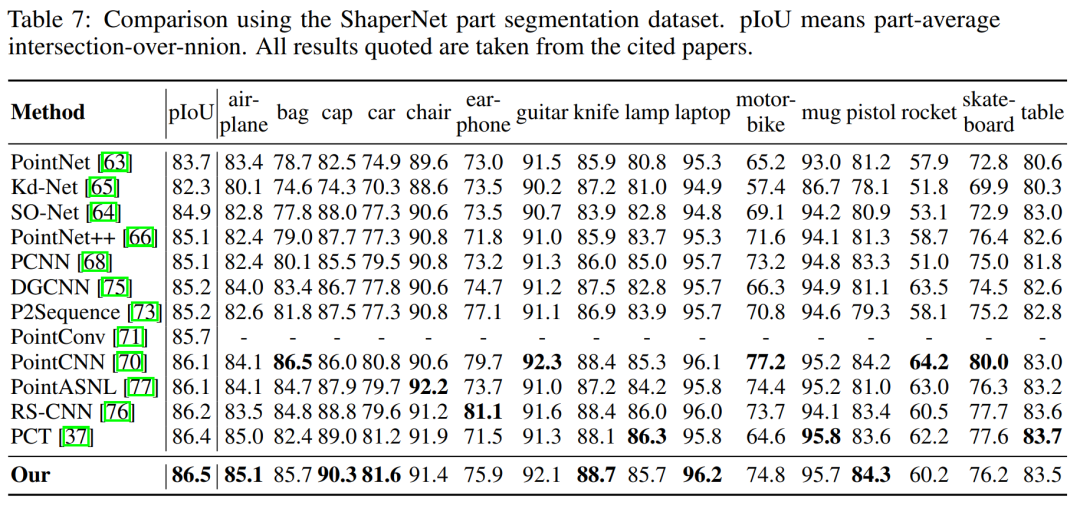
External Attention VS MLP-Mixer
谷歌的工作提出了一種小巧且好用的Mixer-Layer,然后用極其豐富的實驗,證明了僅僅通過簡單的圖像分塊和線性層的堆疊就可以實現非常好的性能,開拓了人們的想象。
清華的External Attention則揭示了線性層和注意力機制之間的內在關聯,證明了線性變換其實是一種特殊形式的注意力實現,如下公式所示:
Attention(x)=Linear(Norm(Linear(x)))
計圖團隊的工作和谷歌團隊的工作都證明了線性層的有效性。值得注意的是,如果將External-attention不斷級聯堆疊起來,也是MLP的形式,就可以實現一個純MLP的網絡結構,但External-attention使用不同的歸一化層,其更符合注意力機制。
這與谷歌團隊的工作有異曲同工之妙。
清華的External Attention的部分計圖代碼已經在Github開源。
后續將盡快開源全部計圖代碼。
External Attention的部分計圖代碼:
https://github.com/MenghaoGuo/-EANet





























