存儲I/O性能對比:Intel Xeon vs. AMD EPYC
本文轉載自微信公眾號「企業存儲技術」,作者唐僧 huangliang。轉載本文請聯系企業存儲技術公眾號。
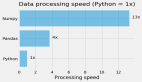
從表面上來看,單路EPYC二代(代號ROMA)處理器就能提供128 lane PCIe 4.0,如果想直連24個U.2 NVMe SSD都不難。看上去這應該是個不錯的存儲服務器方案?因為直到代號Ice Lake-SP的第三代Xeon Scalable才開始將PCIe控制器升級到64 lane PCIe 4.0,不僅推出較晚,并且只有在雙插槽時其I/O擴展性才接近AMD。
然而事實真的如此嗎?挺早之前我就聽朋友提到過,AMD服務器的SSD存儲性能沒有想象中那樣好,但一直沒拿到具體測試數字。直到最近看了Los Alamos National Laboratory(阿拉莫斯國家實驗室)Brad Settlemyer的分享《Practical Computational Storage: Performance, Value, and Limitations》——里面的幾頁內容。
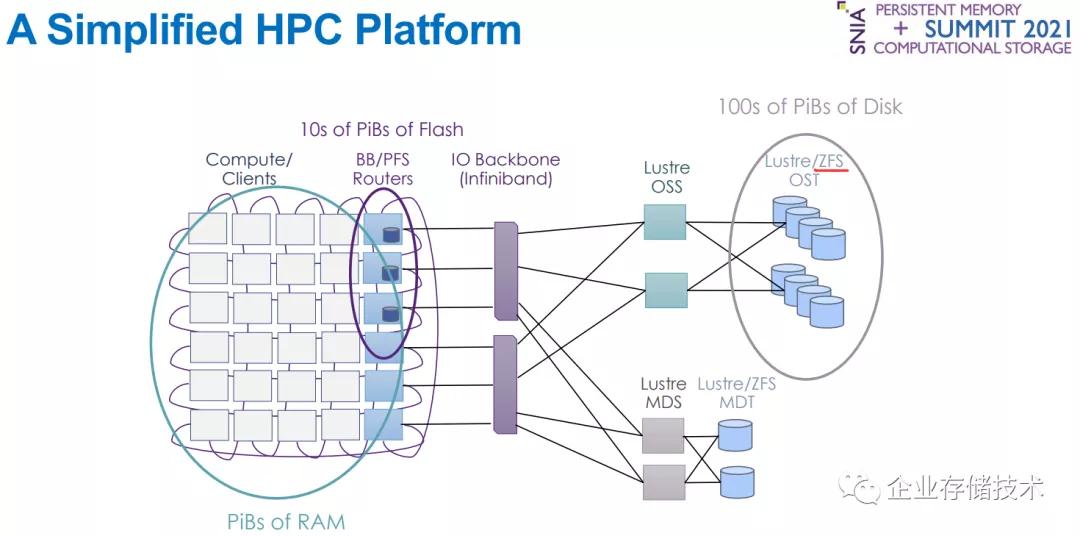
在米國能源部下屬搞HPC,使用Lustre文件系統再正常不過了。本文討論的性能對比,就是運行在Lustre OST節點底層的ZFS本地文件系統。
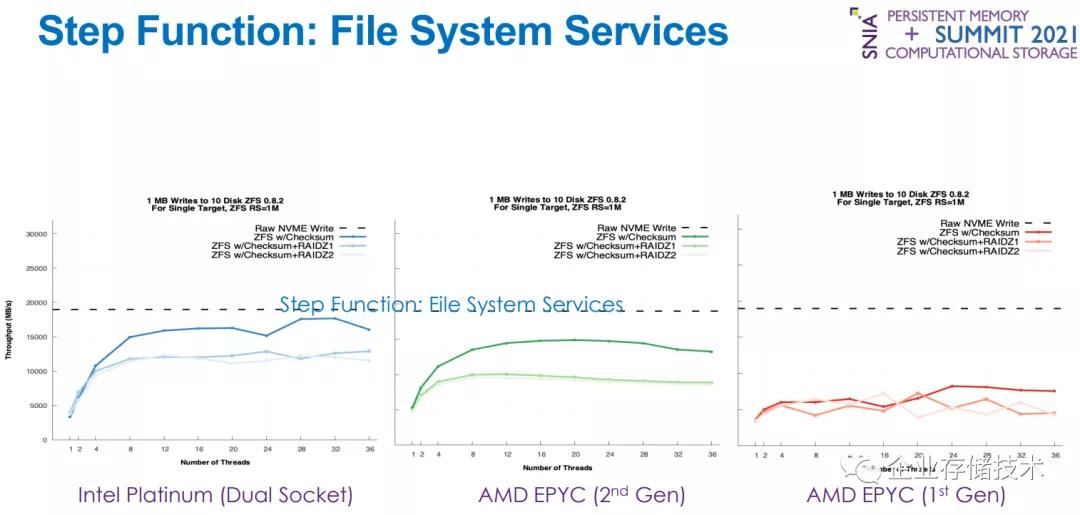
為什么上圖中只有Intel平臺標明了“雙插槽”?我理解應該是因為AMD CPU核心足夠多,并且其不跨插槽的I/O效率可能更好。
如上表,最高的虛線是RAW NVMe寫性能,AMD第一代EPYC、第二代EPYC和Intel Xeon Platinum相差無幾。
玩過ZFS的朋友可能知道,ZFS的Checksum(校驗和)對文件系統數據完整性很有幫助,同時CPU消耗也不小。當測試ZFSw/Chenksum性能時,AMD第一代EPYC只跑到不到原始RAW NVMe SSD的一半(低于10,000MB/s);AMD第二代EPYC有較大改善,不同線程數最高的表現在15,000MB/s左右;而Xeon Platinum則能跑到更接近RAW NVMe寫的水平。
然后是ZFS w/Chenksum+RAIDZ1和RAIDZ2,雖然理論上ZFS RAID的整條帶寫產生的懲罰較小,但性能有下降還在情理之中。Intel& AMD三款服務器平臺的性能次序與前面的w/Chenksum基本保持一致。總體上Xeon Platinum的RAID開銷比二代EPYC要小一點。
性能對比簡要分析
測試結果沒有列出更多硬件細節信息,我也只能粗略討論下。是什么原因導致AMD服務器在這個存儲軟件測試的效率上低一些呢?我覺得一方面可能是PCIe I/O親和作用,這一點在第一代EPYC時我曾提到過。雖然后來內存控制器和PCIe控制器都集中到I/O Die上了(如下圖),不過既然內存仍有片上NUMA效應,我想PCIe應該也是類似的情況。

聽說Intel代號Sapphire Rapids的下一代Xeon Scalable也是多Die封裝,到時有機會可以再留意下效果如何。
另一點就是Intel的軟件生態,包括ISA-L在內的各種指令集。由于AMD服務器只是在近2-3年才重新崛起,傳統存儲軟件歷年的發展中對IntelCPU優化更好也是正常的。
由于R.A.S.的需求,數據中心里跑的企業級軟件都會先求穩,寧可犧牲一些迭代速度;同時歷史代碼的傳承和經驗也非常重要。所以如今AMDEPYC還達不到桌面級ZenCPU的市場占有率,不過能看到“牙膏擠得更快”總不是個壞事情:)
參考資料https://www.snia.org/sites/default/files/PM-Summit/2021/snia-pm-cs-summit-Settlemyer-Practical-CS-2021.pdf