華人小哥的“黑話”數據集,AI:你連dbq都不懂
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
提到“007”,你一定會想到詹姆斯·邦德。
這樣具有隱藏含義的詞,可以統稱為Cant,包括暗語、隱語、行話等。
常見的,比如“666”,還有zqsg、xswl等網絡“暗語”……
對這些詞的理解,在日常生活、廣告和喜劇中都十分重要。
那么,怎么能讓AI理解它們?
最近,來自USCD和北航的研究者,就一邊“玩游戲”,一邊為Cant開發了一個數據集——DogWhistle,并且已經開源。
用游戲收集數據
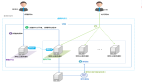
研究團隊根據經典桌游「Decrypto(截碼戰)」進行改編,設計了「Decrypto Online」,利用其中的記錄收集數據。

△Decrypto Online玩家界面
概括而言,Decrypto游戲就是將4個玩家分為2隊,隊長提供線索詞B,以便讓隊友把它和初始詞A關聯起來,同時要避免對手推斷出A詞。
具體來說,每個隊伍有序號1-4的四個初始詞,只有本隊成員可以知道這些詞。

每一回合由隊長抽取密碼卡,根據卡上的3個數字,給出對應序號詞的線索(Cant)。比如:初始詞1是“黑色”,那么1對應的線索詞可以用“夜晚”。
第一回合中,隊友根據線索詞,推斷卡上的數字,并由隊長公開是否正確。與此同時,對方將會記錄這些信息。
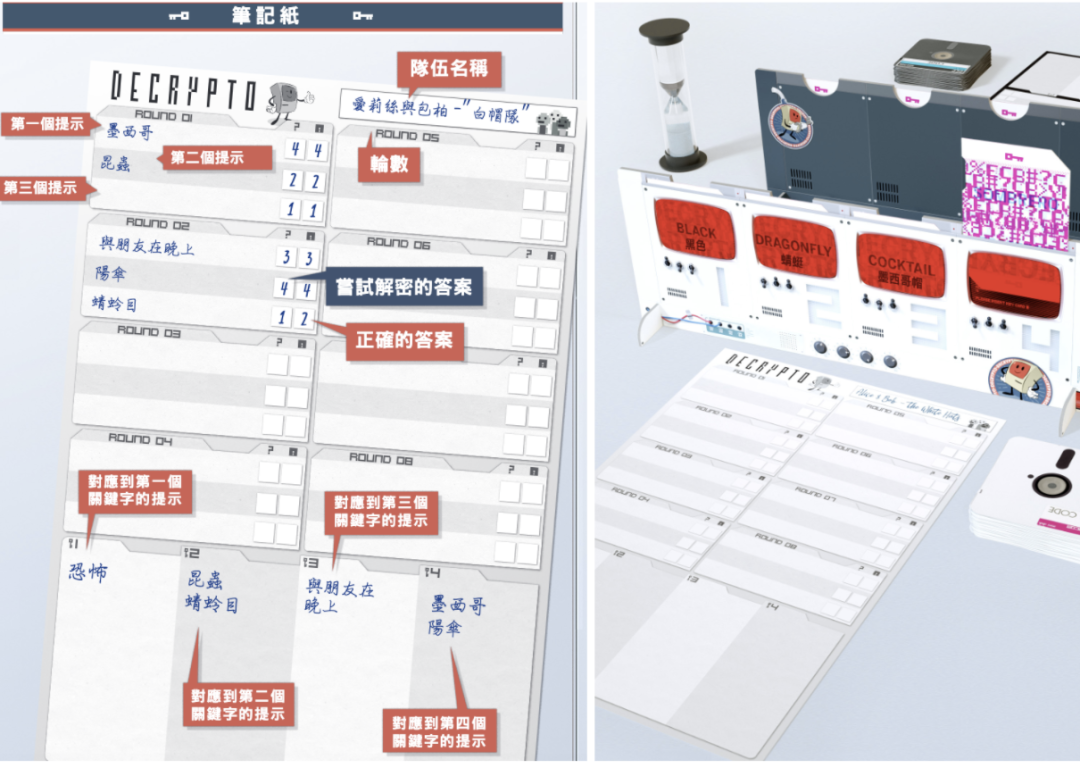
而在第二回合,隊長再次抽數字卡,并給出線索詞,兩隊都要據此推斷數字,答案正確則記一分。
也就是說,隊長給出的線索詞,既要讓隊友對應到初始詞上,同時還要避免對手摸清其中的關聯。
任務設置
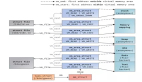
研究人員給模型設置了兩個子任務,初始詞分別為可見和不可見。
內部人員子任務模擬內部人員之間的通信,第一行的4個初始詞作為輸入內容。由于emoji表情符號在交流中起著重要的作用,因此也被允許作為有效輸入。
模型通過初始詞和線索詞進行推斷,預測并輸出初始詞對應的序號(灰色背景)。
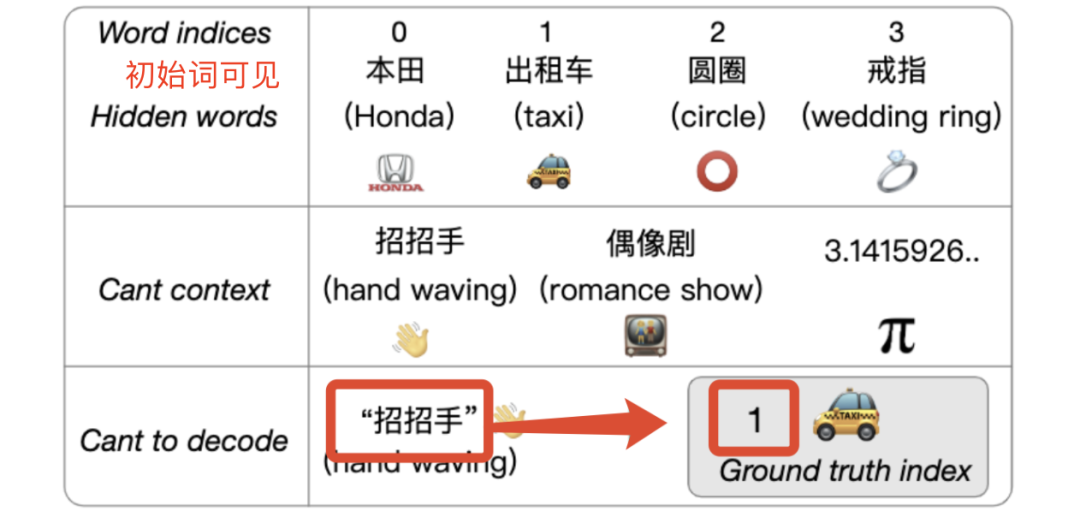
而外部人員子任務中,初始詞是不可見的。
模型通過猜詞記錄、線索詞等進行推斷,預測并輸出記錄對應的序號(灰色背景)。

定量分析
為了解不同模型對Cant的理解能力,研究人員通過兩個子任務進行了定量分析。
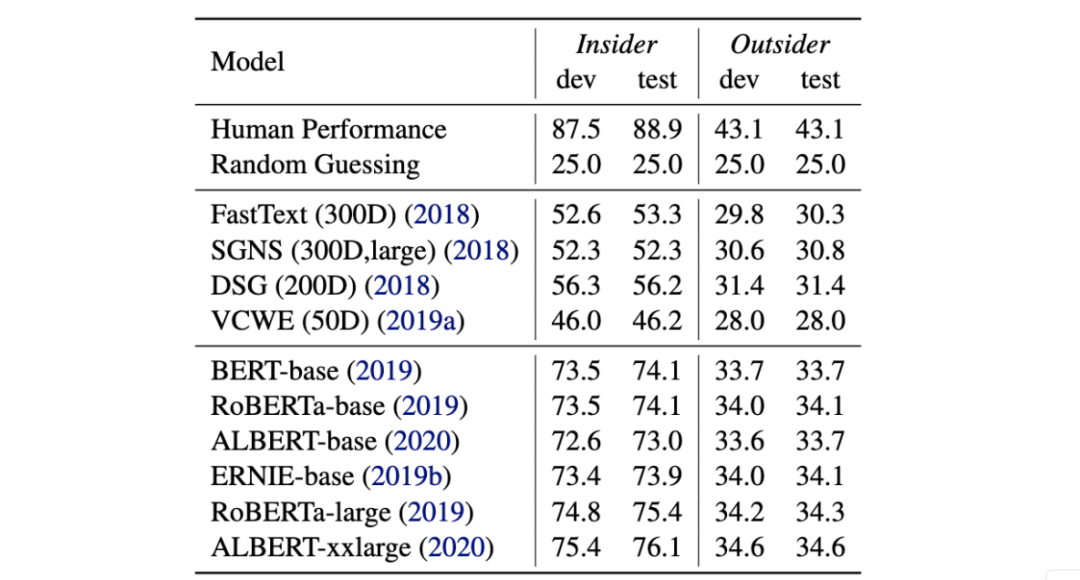
△兩個子任務的準確度得分對比
在詞嵌入相似度的測試中,用多樣化的大型數據集訓練的DSG,性能顯著優于其他模型。
而具有更強計算能力的大尺寸模型,在內部任務中的表現顯著優于基礎尺寸模型。例如,RoBERTa-base和ERNIE-base,都優于BERT-base。
此外,采用參數共享的ALBERT-base,在兩個任務上都略微低于BERT。
值得注意的是,在兩個任務中表現最好的模型,分別以12.8和8.5的較大差距,落后于人類的表現。
這表明DogWhistle是一個非常具有挑戰性的數據集,為下一代預訓練語言模型提供了新的競技場。
定性分析
研究人員還給出了在內部任務中,BERT未能預測,但人類可以正確預測的代表性樣本。

“Dancing Pallbearers(黑人抬棺舞)” 在模型發布后才出現,以至于模型可能對該話題的認識不多。
對“007”(指詹姆斯·邦德電影)的推理,需要模式對各種知識有高度理解,而不是過度擬合淺層的詞匯特征,這也被認為是自然語言推理的主要缺陷。
還有“孩子都可以打醬油了”,也要求模型具有廣泛的語言知識才能理解。
研究人員將DogWhistle數據集作為中間任務,通過中間任務遷移學習來提高模型的性能。
首先,在內部子任務上對模型進行微調,然后在螞蟻金融問題匹配語料庫(AFQMC)和大型中文問題匹配語料庫(LCQMC)上,再次微調模型。
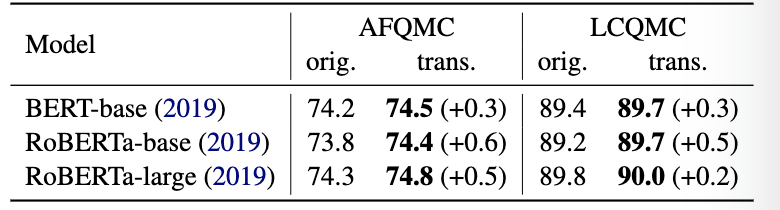
△原始任務和中間任務中準確度得分
結果顯示,在兩個數據集上,DogWhistle都幫助模型獲得了更好的性能。
作者簡介
論文一作許燦文,曾在武漢大學就讀,目前是加州大學圣地亞哥分校(UCSD)的博士研究生。
他曾在微軟亞洲研究院實習,現在Hugging Face工作。主要研究方向包括:NLP中的深度學習、自然語言生成和社交媒體分析。
論文二作周王春澍,是北京航空航天大學計算機科學碩士,在微軟亞洲研究院實習,致力于NLP研究。
據作者介紹,這篇論文已經被NAACL 2021接收,數據集在GitHub上開源。