用Python分析了1741家大褲衩數據進行分析,終于找到可以買入那一條
本文轉載自微信公眾號「志斌的python筆記」,作者志斌 。轉載本文請聯系志斌的python筆記公眾號。
大家好,我是志斌~
最近的幾天真的是太熱了,志斌翻了翻自己的衣柜,發現去年的大褲衩已經不在適合自己現在肥胖的體型,所以志斌打開淘寶,搜索了1741條大褲衩的數據,然后進行了可視化分析,最終找到一條可以入手的大褲衩。
在后臺回復[大褲衩]即可獲得數據集。
01數據采集
淘寶網站是一個動態加載的網站,我們之前可以采用解析接口或者用selenium自動化測試工具來爬取數據,但是現在淘寶對接口進行了加密,使我們很難分析出來其中的規律,同時淘寶也對selenium進行了反爬限制,所以我們要換種思路來進行數據獲取。
因為篇幅問題,數據采集的方式在這里就不在過多的講解,有興趣的小伙伴可以看看這篇文章,它詳細的介紹了淘寶商品數據的獲取方式,我們這里只展示核心代碼。
- response = requests.get('https://s.taobao.com/search', headers=headers, params=params)
- shangpinming = re.findall('"raw_title":"(.*?)"', response.text)
- jiage = re.findall('"view_price":"(.*?)"', response.text)
- fahuodi = re.findall('"item_loc":"(.*?)"', response.text)
- fukuanrenshu = re.findall('"view_sales":"(.*?)人付款"', response.text)
- dianpumingcheng = re.findall('"nick":"(.*?)"', response.text)
- for i in range(44):
- try:
- if (fukuanrenshu[i] == '1.5萬+'):
- f = 15000
- elif (fukuanrenshu[i] == '1.0萬+'):
- f = 10000
- elif ('+' in fukuanrenshu[i]):
- f = re.findall('\d+', fukuanrenshu[i])
- else:
- f = fukuanrenshu[i]
- if float(jiage[i]) > 10:
- sheet.append([dianpumingcheng[i], shangpinming[i], float(jiage[i]), f
02數據清洗
01導入商品數據
用pandas讀取爬取后的商品數據并預覽。
- df = pd.read_excel('褲衩男.xlsx',names=['店鋪名稱','商品名','價格','產地','付款人數'])
- print(df.head())

02刪除重復數據
- df.drop_duplicates()
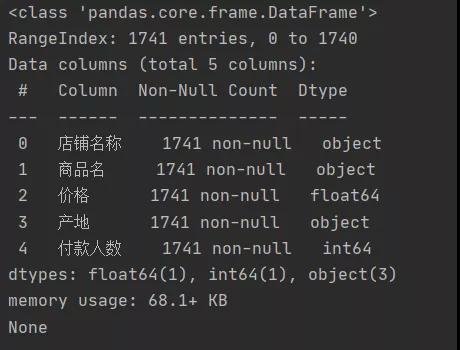
03查看數據類型
查看字段類型和缺失值情況,符合分析需要,無需另做處理。
- df.info()
03數據可視化
我們來對這1741條大褲衩的數據進行可視化分析。
01在售的大褲衩的特點。
通過對大褲衩的商品名稱進行詞云圖繪制,志斌發現,大褲衩的主要特點是寬松,其次是休閑和運動。仔細想來,夏天的時候大家的穿著確實是比較寬松和休閑的。

02各省市產量分布圖
通過對各商品的產地數據進行統計并繪制了全國地圖,我們發現福建和浙江這兩個地方盛產大褲衩。
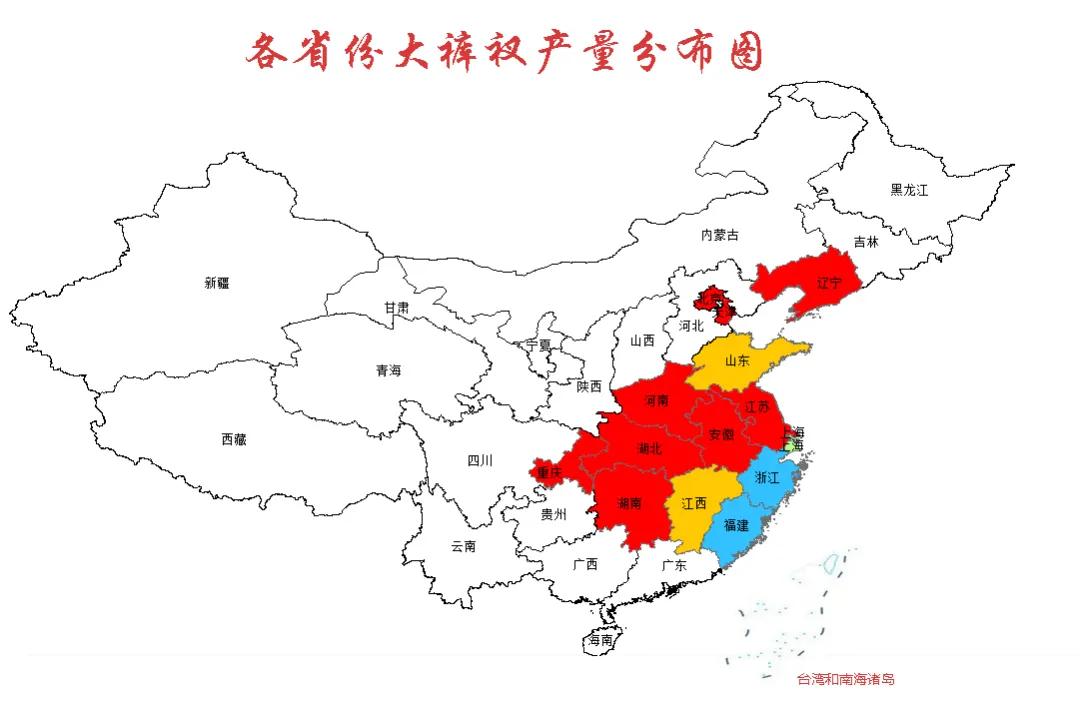
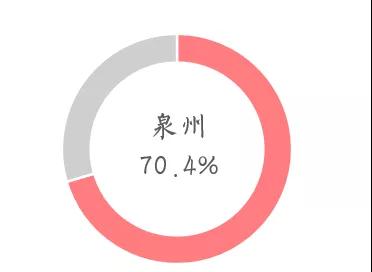
我們對這兩個省份的數據進行更一步的分析發現:福建省的大褲衩主產地在泉州,占據全省產量的70.4%
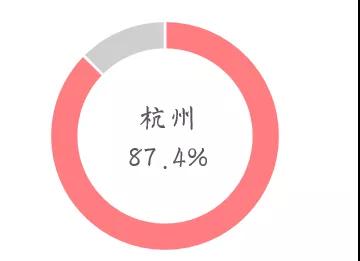
浙江省的大褲衩主產地在杭州,占據全省產量的87.4%。
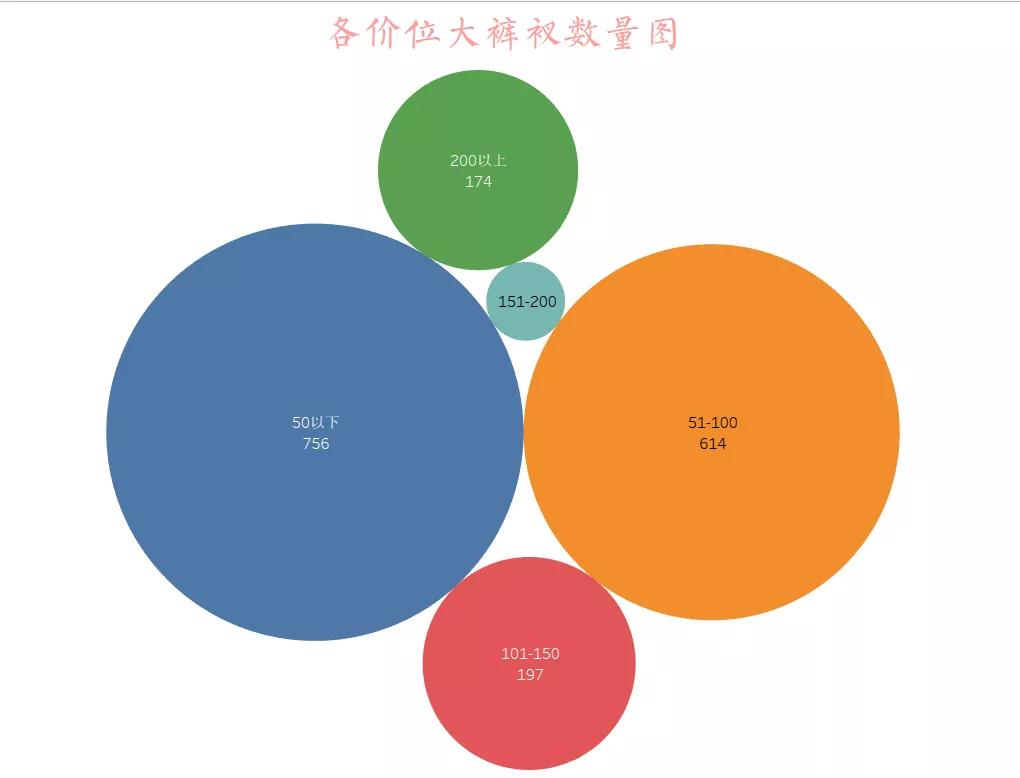
03各價位商品數量圖
通過對商品價格進行分段可視化,我們可以看出100元以下的大褲衩占據全部市場的77.4%,可見大家對大褲衩的心理價位選擇普遍較低。
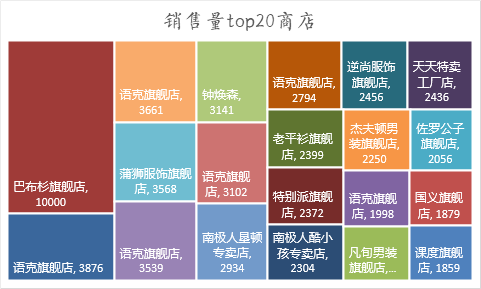
04大褲衩月銷量top20商家
通過對各商品月銷售量進行可視化分析,我們發現,巴布衫旗艦店的月銷量最多是10000。語克旗艦店的商品在月銷量top20中占據6個,top5中占據了3個,看來這個旗艦店的商品受大眾喜歡的類型更多。同時我們還能看出,用戶們更喜歡去旗艦店和專賣店進行購物。
05選擇合適的大褲衩并入手
經過以上的分析和對寶貝的評價、好評率等數據進行綜合考慮之后,志斌最終選擇購買這條大褲衩來入手。
05小結
1. 本文僅供學習研究使用,提供的評論僅供參考。如有不妥之處請及時告知作者。
2. 如需代碼,請聯系作者進行獲取。