深度|數據湖分析算力隔離技術剖析
一、背景介紹
根據MarketsandMarkets市場調研顯示,預計數據湖市場規模在2024年將從2019年的79億美金增長到201億美金。隨著數據湖的規模增長,基于交互式查詢引擎Presto的數據湖分析負載也隨著增加。在共享的Presto集群里,大查詢之間非常容易相互影響,在此背景下對查詢進行算力隔離也就迫在眉睫。本文主要介紹數據湖分析引擎Presto如何解決多租戶算力隔離的技術。
二、數據湖分析 Presto 算力隔離遇到的挑戰
1、數據湖分析 Presto 方案架構
Presto是一個定位大數據分析領域的分布式SQL查詢引擎,適合GB到PB級別的數據的交互式分析查詢。與Hive、Spark等其他查詢引擎不同,它是一個全內存計算的MPP引擎,能快速獲取查詢結果,因此它特別適合進行adhoc查詢、數據探索、BI報表、輕量ETL等多種業務場景。下圖以阿里云數據湖分析(簡稱DLA)的Presto架構為例說明。
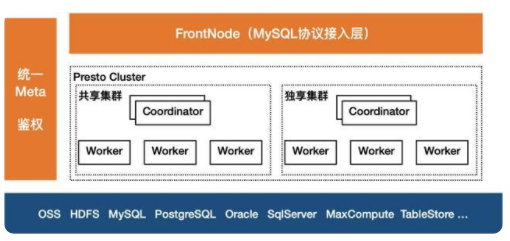
FrontNode:整個架構的接入層FrontNode,它通過MySQL協議提供服務,只要兼容MySQL協議的客戶端、BI工具可以直接連接并提交查詢,它接收到SQL后,會對SQL做解析,轉換為Presto風格的SQL,并調度到相應的Presto集群。Presto引擎:中間的Presto計算引擎,適合交互查詢,用戶可以根據業務特點,如果是頻繁類型的查詢,適合選擇獨享集群;若是偶發類型的查詢,適合Serverless類型的共享集群。元數據:左側是統一元數據,相對Presto原生的元數據,它能統一管理所有Connector的元數據,并支持多租戶的權限控制;并提供了MySQL風格的GRANT/REVOKE機制,便于租戶內的子賬戶權限管理。存儲層:底層是存儲層,Presto并不自帶存儲,但它支持許多的數據源,并支持不同數據源之間的關聯查詢。
2、數據湖分析 Presto 算力隔離遇到的挑戰
社區原生的Presto在多租戶隔離場景考慮的比較少,主要通過ResourceGroup機制限制每個資源組的資源(包括CPU和內存)上限,它最大的問題是只能限制新的查詢,即一個Group的資源用超后,其新提交的查詢會被排隊,直到其使用的資源降到上限之下;對于正在執行的查詢如果超過資源組的資源上限,ResourceGroup不會做限制。因此在一個共享的Presto集群中,一個大查詢還是可以把整個集群的資源消耗完,從而影響其他用戶的查詢。在DLA實際生產過程中,上千用戶共享的集群,此問題尤為突出。
與Spark、Hive等其他查詢引擎可以簡單設置執行資源并發限制資源不同,Presto首先需要預先啟動所有Stage,并且所有查詢在Worker執行時共享線程和內存,因此無法通過簡單地設置執行的并發控制其資源的使用。
業界采用比較多的解決方案是:基于Presto On Yarn實現資源隔離。為每個資源組啟動一個獨立的Presto On Yarn集群,并通過Yarn的資源管理機制實現Presto集群之間的隔離。其優點是資源隔離比較好;但需要預先為每個租戶啟動一個專屬的集群,即使沒有查詢在執行也需要維護該集群,在數據湖分析Serverless服務場景,租戶較多,且他們的查詢很多都是間歇性的,其資源消耗也不穩定,無法預估。因此如果為每個用戶都啟動一個專屬集群,會導致嚴重的資源浪費。
三、基于實時懲罰機制實現DLA Presto的算力隔離技術解析
1、社區Presto的Query執行與調度原理
下面以一個聚合類型的查詢為例簡要介紹社區Presto的Query(查詢)執行原理。
Select id, sum(money) from employ where id>10000 group by id;
注:*左右滑動閱覽
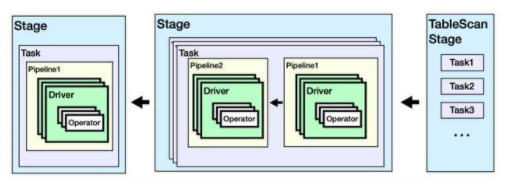
一個查詢會被解析為包含多個Stage的物理執行計劃,每個Stage包含若干Task,Task會被Coordinator調度到Worker上執行。在Worker上,每個Task會包含多個Driver,每個Driver對應一個Split(數據切片);每個Driver會包含若干操作算子Operator。
它在Presto上的調度邏輯如下圖所示,在主節點Coordinator和從節點Worker都有相應的調度邏輯。
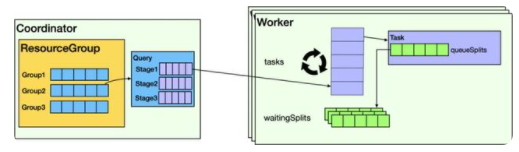
在Coordinator上,主要負責多租戶Group之間和Group內的Query調度。若Group使用的資源未達到上限,則Query會被解析并調度。Query解析后,以Task為單位,一次性把所有Stage的Task分配給Worker。
Worker會根據數據切片Split生成Driver,并放到調度隊列。Worker執行Split以時間片為單位,一次最多只執行1秒,未完成則繼續放入排隊隊列。
2、基于實時懲罰機制的核心思想
數據切片Split的執行基于CPU時間片可以做進一步的限制:實時統計每個Group消耗的CPU時間,當Group累計每秒消耗的CPU時間超過其配置的資源上限,則開始懲罰該Group,即不再執行其Split,直到其累計CPU消耗小于資源上限。
舉例的描述:GroupA的配置可使用的CPU核數上限為N,Coordinator每秒為GroupA生成N秒的CPU時間片,當GroupA的查詢執行時,實時統計GroupA的CPU消耗,其每秒的CPU消耗為cpus,累計消耗為Csum,每秒都需要讓Csum加上cpus,然后做如下的判斷邏輯:
如果 Csum <= N:下一秒不需要懲罰;并重置Csum = 0。如果 Csum >= 2N,需要懲罰1秒,下一秒GroupA的所有Split都不會被調度執行;并設置Csum = Csum - N。如果 N < Csum < 2N,下一秒不會被懲罰,但Csum-N的值會進入下一秒的判斷邏輯,下一秒被懲罰的概率會加大;并設置Csum = Csum - N。
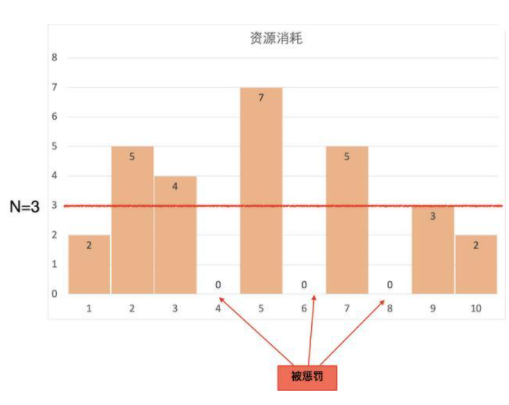
上圖以N=3為例舉例說明:
第一秒 cpus=2,Csum=2;下一秒不懲罰。第二秒 cpus=5,Csum=5;下一秒不懲罰。第三秒 cpus=4,Csum=6;下一秒懲罰。第四秒 cpus=0,Csum=3;下一秒不懲罰第五秒 cpus=7,Csum=7;下一秒懲罰。第六秒 cpus=0,Csum=4;下一秒不懲罰。第七秒 cpus=5,Csum=6;下一秒懲罰。第八秒 cpus=0,Csum=3;下一秒不懲罰。第九秒 cpus=3,Csum=3;下一秒不懲罰。
3、基于實時懲罰機制實現DLA Presto的算力隔離的實現原理
鑒于DLA的Presto已經實現了Coordinator的高可用,一個集群中包含至少兩個Coordinator,因此ResourceManager模塊首先需要實時收集所有Coordinator上所有Group的資源消耗信息,并在ResourceManager中匯總,然后計算并判斷每個Group是否需要被懲罰,最終把每個Group是否需要被懲罰的信息同步給所有Worker。如下圖所示:
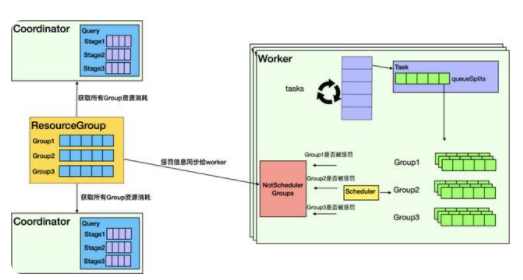
與社區Presto的Worker把所有Split放到一個waitingSplit隊列不同,DLA Presto首先在Worker上引入Group概念,每個Group都會維護一個自己的隊列。Worker在調度選擇Split時,首先會考慮Group是否被懲罰,如果被懲罰,則不會調度該Group的Split;只有未被懲罰的Group的Split會被選中執行。之后Worker會統計所有查詢的資源消耗并匯總到Coordinator,并進入到下一個判斷周期。最終達到控制Group算力的能力。
四、DLA Presto算力隔離上線效果
接下來以TPCH做測試,驗證租戶算力隔離效果。測試場景:
四臺Worker,每臺配置是4C8G;選用TPCH第20條SQL進行實驗,因為它包含5個JOIN個,需要使用大量CPU;實驗場景:四個租戶資源上限相同都為8,其中A、B、C各提交一條SQL,D同時提交5條SQL。
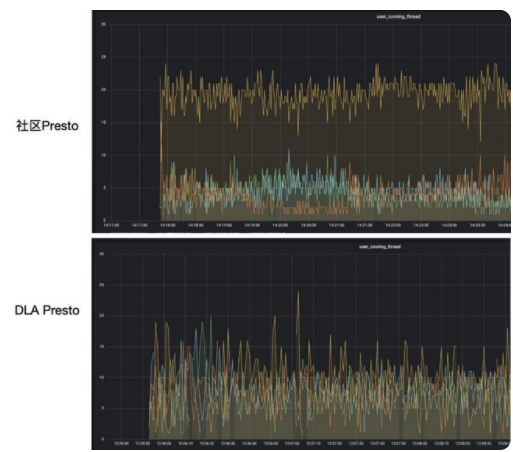
可以看到社區Presto版本由于租戶D提交查詢多,相應的Split會更多,因此他能分配更多的資源,這對其他用戶是不公平的。而在DLA版本中,由于預先為租戶D和其他用戶配置了相同的資源上限,因此租戶D使用的資源和其他用戶也是差不多的。
下圖是8條查詢的耗時對比:
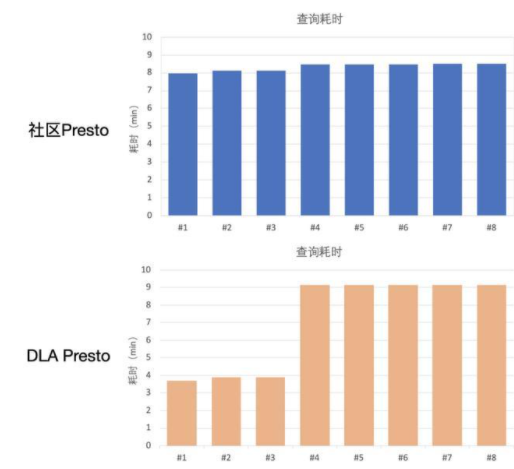
可以看到在開源Presto版本里面,所有8條查詢耗時幾乎一樣;而在DLA的版本里面租戶A、B、C的查詢耗時較短,而租戶D由于使用過多資源被懲罰,因此它的5條查詢耗時較長。
在DLA的實際生產過程中,為每個用戶設置指定的資源上限,并進行比較精準的控制,杜絕了一條或多條查詢占用大量的資源,影響其他用戶的查詢。也不再出現少量查詢就把Presto集群搞垮的情況。保證了用戶查詢時間的穩定性。另一方面,對于那些查詢量很大的用戶,DLA還提供了獨享集群模式,能讓查詢以更優的性能完成。
五、總結
隨著越來越多的企業開始做數據湖分析,數據量的持續增加,數據分析需求也會越來越多,在一個共享的數據湖分析引擎,如何防止多租戶之間的查詢相互影響是一個很通用的問題,本文以阿里云DLA Presto為例,介紹了一種基于實時懲罰機制實現算力隔離的原理,能有效使共享Presto集群解決多租戶之間查詢相互影響的問題。