小白入門大數據,這一篇就夠了
大數據、人工智能( Artificial Intelligence )像當年的石油、電力一樣, 正以前所未有的廣度和深度影響所有的行業, 現在及未來公司的核心壁壘是數據, 核心競爭力來自基于大數據的人工智能的競爭。所以不論是計算機專業的程序員,還是非計算機專業準備轉行計算機的跨行人員都想學習大數據,從事大數據開發工作。
但是當你站在一個行業門外的時候,你更多的是看到他的價值和前景,這會促使你義無反顧地往里沖。但當你想要跨越這道門檻入門的時候,你開始考慮技術層面的困難,什么困難呢?那就是我對這個行業知之甚少,這個行業是否與我的想象相符?是否和我的發展方向一致?我應該從哪里開始?應該如何快速入門?
大數據這個行業也是一樣,好像這個互聯網時代,不知道大數據就落伍了一樣,但很多一部分人也只限于了解了大數據這個詞,并加上自己想象的定義。
那么大數據到底是什么?用來做什么?如何開始大數據的學習呢?今天我們從技術的角度來深入淺出聊一聊。
首先,大數據到底是什么?大數據只是一個統稱。廣義上,像大數據開發、大數據分析、大數據挖掘等對大數據的操作都可以統稱為大數據。狹義上:大數據是指在一定時間范圍內無法用常規的軟件分析工具進行處理的數據集。所以從定義可以看出來,大數據最原始的本質其實就是數據集,只是數據集的規模、體量很大,大到我們無法接受使用常規軟件處理所花費的時間。
大數據用來做什么?我們已經明確了大數據就是數據集,那么數據集用來做什么,當然是通過對數據集進行處理、分析,提取有用的信息用于各種業務之中。所以大數據的作用也是如此,通過提取大數據中有價值的信息,再利用這些信息進行業務賦能,促進智慧城市建設、企業用戶畫像、人工智能仿生、醫療疾病診斷等政、企、研、醫行業的發展,為行業領域帶來新的價值空間。
既然大數據有如此多的應用場景、廣闊想象空間的發展前景,那么如何開始接觸學習大數據呢?
為了大家能夠真正明白,也為了能夠達到深入淺出的效果,我們在下面說明大數據的各種處理手段時會經常拿常規數據和大數據來對比解釋。
首先大數據的數據屬性就決定了他的操作空間(處理流程),無外乎數據采集→數據存儲→數據計算→數據應用。這些操作的背后幾乎涵蓋了當前大數據行業的所有產業鏈。
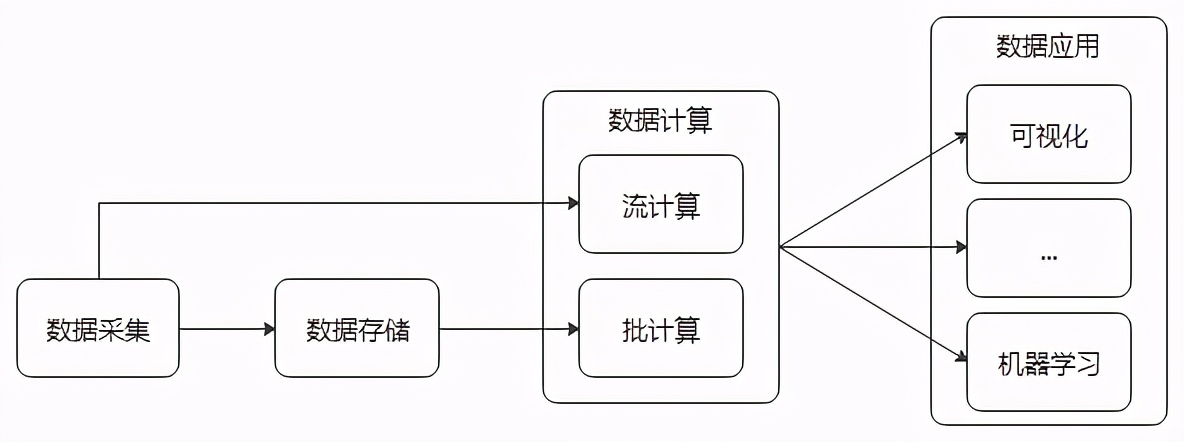
大數據處理流程
大數據采集是大數據整個體系的起始端。我們首先需要獲取數據,傳統數據的獲取方式,比如學生信息的獲取,我們可以采用Excel手寫輸入的方式獲取。但是在這個互聯網時代,動輒百萬條、千萬條數據,又有各種各樣的數據源,比
如數據庫、日志、物聯網傳感器等等,我們不可能再通過人工或常規Excel的方式去實時獲取、匯總數據,這時候就需要針對這種超過普通數據集定義的超大數據集采用專門的采集工具,來提高數據采集效率,使每秒產生的成千上萬數據能夠及時被采集到指定的存儲介質上,不產生數據積壓,避免造成數據丟失。使用專門采集工具高效采集數據的過程就被叫做大數據采集。大數據采集,根據采集的數據源不同(數據庫、日志、物聯網信號...),采集的數據類型不同(結構化數據、半結構化數據、非結構化數據),會用到諸多適應于各自場景的采集工具,比如:Flume、Sqoop、Nifi...
Flume是Cloudera提供的(后來成為Apache開源項目)一個高可用,高可靠的,分布式的海量日志采集、聚合和傳輸的工具。主要用于采集日志類數據,由于Flume可以通過配置采集端采集模式(spooldir、exec)從而可以做到文件目錄內新增文件的增量采集、文件內新增文件內容的增量采集。Flume還可以通過配置自定義攔截器,過濾不需要的字段,并對指定字段加密處理,將源數據進行預處理,實現數據脫敏。
Sqoop是在Hadoop(后面會介紹)生態體系和RDBMS體系之間傳送數據的一種工具。最常用的還是通過Sqoop將RDBMS體系(Mysql、Oracle、DB2等)中的結構化數據采集并存儲到Hadoop體系(HDFS、Hive、Hbase等)的數據倉庫中。
Nifi,由于Nifi可以對來自多種數據源的流數據進行處理,因此廣泛被應用于物聯網(IoAT)的數據處理。
通過上面的主流工具,我們基本上能解決99%種場景下的數據采集工作,數據采集完之后,就要面臨一個不得不考慮的問題:采集的數據存在哪里?
常規數據可以存在硬盤、存在傳統單機數據庫。但大數據時代呢?由于數據量爆炸式的增長,單塊硬盤或單機數據庫已經滿足不了我們的存儲要求了,我們需要更大的存儲空間,要能夠隨著數據的增長而增加空間,使我們的數據全部存下不溢出。這樣就有兩個方向:一個是堆硬件,提升硬件質量,開發更大存儲能力的硬盤或存儲介質;一個是堆數量,找更多塊硬盤來把數據按塊存放在不同的硬盤上。
大數據的存儲解決方案就是第二種,選擇更加廉價、高效、可擴展的橫向擴展方式來滿足數據存儲。既然選擇堆數量的方式來存儲大數量級的數據,那就還要解決一個問題,那就是查詢問題。數據可以分批放入不同的硬盤中,我獲取的時候如何準確快速的找到想要的那一條數據,放在哪個盤、哪個文件的第幾行呢?這就需要專業的大數據存儲工具來解決這些問題,實現分布式存儲情況下每臺節點數據量的平衡、數據冗余備份防止數據丟失、數據建立索引實現快速查詢等。目前大數據中用到的主流存儲系統有哪些呢?比如:HDFS、HBase、Alluxio...
HDFS是Hadoop三大組件之一(另外兩個組件分別是:資源管理組件——YARN,并行計算組件——MapReduce),是一個分布式的文件存儲系統,在大數據存儲系統中具有不可替代的作用。從各種數據源采集的數據一般都是存儲在HDFS,HDFS支持數據的增刪改查,類似于傳統數據庫,不過在大數據系統中,我們稱之為“數據倉庫”。
HBase是一個分布式的NoSql數據庫,分布式的特點以及面向列的存儲特性,使得HBase在大數據存儲領域應用廣泛,主要用于存儲一些半結構化數據和非結構化數據,并且可以結合phoenix(感興趣的朋友可以自行百度了解)來實現二級索引。
Alluxio原本叫做Tachyon,是一個基于內存的分布式文件系統。它是架構在底層分布式文件系統(比如:HDFS、Amazon S3等)和上層分布式計算框架之間(比如后面會提到的MR、Spark、Flink等)的一個中間件,主要職責是以文件形式在內存或其它存儲介質中提供數據的存取服務,減少數據IO性能消耗,加快計算引擎加載數據的速度。
如果數據采集之后,只是存儲在數據倉庫之中,那么這些數據沒有任何價值,也無法推動、促進我們的業務。所以,數據存儲之后,就是要考慮數據計算的問題了。數據如何計算呢?傳統的軟件分析軟件Excel、Mysql等無法承載海量數據的分析,因為設計之初,考慮到的數據上線就遠遠達不到大數據的入門門檻標準。我們就要尋求一些專業的大數據量的分析計算軟件來應對不同特點數據集的數據計算。數據計算從處理效率來分,可以分為:離線批處理、實時處理。如果從處理方式來分,可以分為:數據分析、數據挖掘。
我們先以離線批處理和實時處理兩個角度來了解數據計算處理工具。
大數據興起之初,人們對數據處理的時效性沒有現在要求那么高,更加注重時間和成本的平衡,基本只是面向“天”為粒度的離線計算場景,就是在第二天才開始處理前一天的數據。在這種場景下就誕生了MapReduce,Hadoop三大組件中的并行計算組件。MapReduce計算主要是利用磁盤來進行中間結果數據的暫存,這樣就造成數據的計算過程,數據不斷在內存和磁盤間IO,影響了計算效率,在一些數據量比較大的情況下,一個MR(MapReduce的簡稱)任務就能跑一天。MR計算不止慢,MR框架使用還有一定的開發入門門檻,所以后來又出現了一個數據計算工具——Hive,Hive對復雜的MR程序開發say no!開發人員只需要懂SQL語言就能夠進行數據的增刪改查,Hive會將你的SQL語句在計算機實際計算前轉換為MR計算任務,雖然速度還是一樣的慢,但是降低了程序員的開發門檻。
隨著數據應用的不斷深入,大數據體系的不斷完善,數據的價值越來越隨著時效而凸顯,所以越來越多的人對數據的時效性提出了更高的要求。在這種情況下,人們開始需求更快速的數據計算工具,這就誕生了后來的Impala、Presto等一系列基于純內存或以內存為主的計算引擎,大大縮短了數據的處理時間,提高了數據信息提取的效率,使數據產生了更多的商業附加價值。
人們在一些特定場景下,對于數據處理的效率要求是沒有上限的。比如,電商系統的實時推薦、雙十一天貓的監控大屏等,最深入人心的就是12306車票實時統計。于是,實時流計算的場景就逐漸產生了,這也催生了后來的Spark、Flink這一類實時計算引擎的發光發彩。流計算是指對持續流入的數據立即進行處理,但是誰也不能保證我上游數據一定是勻速寫入,這就需要引入一個叫消息中間件的消息緩沖組件,比如:Kafka、RocketMQ、RabbitMQ等,主要作用就是起到一個限流削峰的作用,就好像一個蓄水池,對于某一時間涌入的大量數據進行暫存,然后以一個勻速的速率傳遞將消息分批傳送到實時計算引擎進行數據實時計算。
Spark是一個基于內存的計算引擎。Spark的功能組件可以細分為SparkCore、SparkSql、SparkStreaming、GraphX、MLlib。SparkCore、SparkSql主要是用來做離線數據批處理,SparkStreaming則是用來做實時流計算,GraphX是用來做圖計算,MLlib是一個機器學習庫。Spark Streaming 支持從多種數據源獲取數據,包括 Kafka、Flume、Twitter... ,從數據源獲取數據之后,可以使用諸如 map、reduce、join 和 window 等高級函數進行復雜算法的處理,最后再將計算結果存儲到文件系統、數據庫...中。
Flink認為有界數據集是無界數據流的一種特例,所以說有界數據集也是一種數據流,事件流也是一種數據流。Everything is streams,即Flink可以用來處理任何的數據,可以支持批處理、流處理、AI、MachineLearning等等。
主流數據計算工具了解之后,我們再從數據分析和數據挖掘的角度講一下數據計算。
數據分析,一般指分析的目標比較明確,比如要從一堆學生信息中篩選出來性別為男的學生數量就是一種數據分析,是明確了x和轉換函數f的情況下去獲得y值。而數據挖掘則是通過數學建模、在給定x和y的情況下,讓機器去發現使兩個值等價的若干f函數并利用其他數據集,去不斷驗證獲得最匹配的f,最終利用f去目標數據集進行分析,獲取隱藏的數據關聯。
總體來說,數據挖掘更加具有開放性,能夠用來從海量數據中找到人們沒有認識到的隱藏規則。目前比較常用的數據挖掘的機器學習庫主要有SparkML、FlinkML(這里就不展開了)。
數據計算之后需要以業務需要的方式展示出來,這樣才能使不同的決策部門利用數據進行輔助決策,所以數據展示的方式就很重要,他能影響到數據的直觀性和數據的價值體現。而大數據系統中常用的數據展示工具有ECharts、Kibana等...
Echarts是百度開源的一個基于JavaScript的數據可視化圖表庫,用于提供直觀,生動,可交互,可個性化定制的數據可視化圖表。
Kibana是ELK三件套中的展示組件(其他兩個組件為:日志收集組件——Logstash,分布式搜索引擎——Elasticsearch),提供有好的Web界面展示界面,能夠讓你對 Elasticsearch 數據進行可視化。
以上介紹了大數據的整體處理流程和對應流程使用的工具組件。其實除了以上數據處理直接相關的組件,大數據系統的穩定高效運轉還離不開一些輔助性或工具性組件,比如ZooKeeper、Oozie、Hue等...
ZooKeeper簡稱ZK,是一個分布式系統的可靠協調系統,在大數據體系中應用廣泛。HDFS、YARN、HBase、Kafka(未來可能移除ZK支持,使用內置替代方案)...等組件廣泛采用ZK實現高可用系統的主服務協調管理。
Oozie和Azkaban類似,都是一個定時任務調度組件,用來管理Hadoop作業。Oozie可以將很多不同的作業(如MR、Java程序、shell腳本、hivesql、sqoop、spark等)按照特定的順序,或串行或并行的組合成一個工作流,上流任務完成后會自動觸發下流任務的執行,達到連貫調度的目的,能夠極大的提高開發效率。
Hue是一個可視化的大數據組件集成系統,能夠集成Hive、HBase、HDFS、Spark等,實現界面可視化操作,對于數分析工程師來說不用自己實現代碼開發,直接在界面進行SQL語句操作或拖拽操作就能利用這些集成組件完成數據處理。
以上就是大數據系統的一個系統性介紹,包括了大數據推進歷程、大數據處理流程、大數據技術體系等,了解并掌握以上大數據處理流程,熟練運用各種工具進行數據采集、存儲、計算、展示,基本就可以算得上是一個合格的大數據工程師了,如果想更深層次的發展,就需要了解主流大數據組件的特性、各種處理工具的原理和調優、大數據組件接口的二次開發等等。
最后說一句,任何時候都不要忘記從官網獲取我們想要知道的關于大數據處理工具的一切特性,養成從官網學習新知識、新技術、新框架的習慣!