MySQL三種日志有啥用?如何提高MySQL并發度?
MySQL數據存儲和查詢流程
假如說現在我們建了如下一張表
- CREATE TABLE `student` (
- `id` int(11) NOT NULL AUTO_INCREMENT COMMENT '學號',
- `name` varchar(10) NOT NULL COMMENT '學生姓名',
- `age` int(11) NOT NULL COMMENT '學生年齡',
- PRIMARY KEY (`id`),
- KEY `idx_name` (`name`)
- ) ENGINE=InnoDB;
插入如下sql
- insert into student (`name`, `age`) value('a', 10);
- insert into student (`name`, `age`) value('c', 12);
- insert into student (`name`, `age`) value('b', 9);
- insert into student (`name`, `age`) value('d', 15);
- insert into student (`name`, `age`) value('h', 17);
- insert into student (`name`, `age`) value('l', 13);
- insert into student (`name`, `age`) value('k', 12);
- insert into student (`name`, `age`) value('x', 9);
數據如下
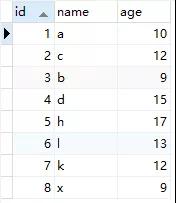
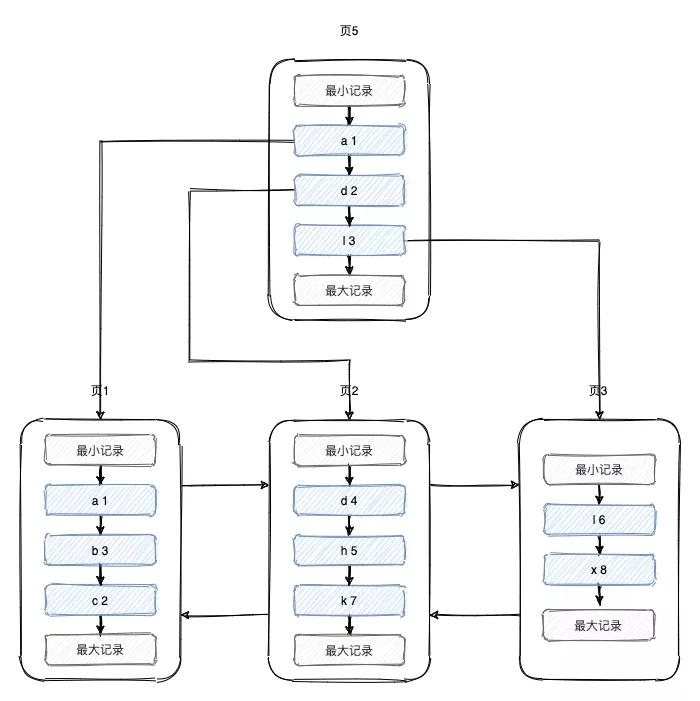
這些數據最終會持久化到文件中,那么這些數據在文件中是如何組織的?難道是一行一行追加到文件中的?其實并不是,「數據其實是存到頁中的,一頁的大小為16k,一個表由很多頁組成,這些頁組成了B+樹」,最終的組織形式如下所示,具體的構建過程我就不詳細介紹了,可以看我之前的文章《10張圖,搞懂索引為什么會失效?》
那么SQL語句是如何執行的呢?MySQL的邏輯架構圖如下所示
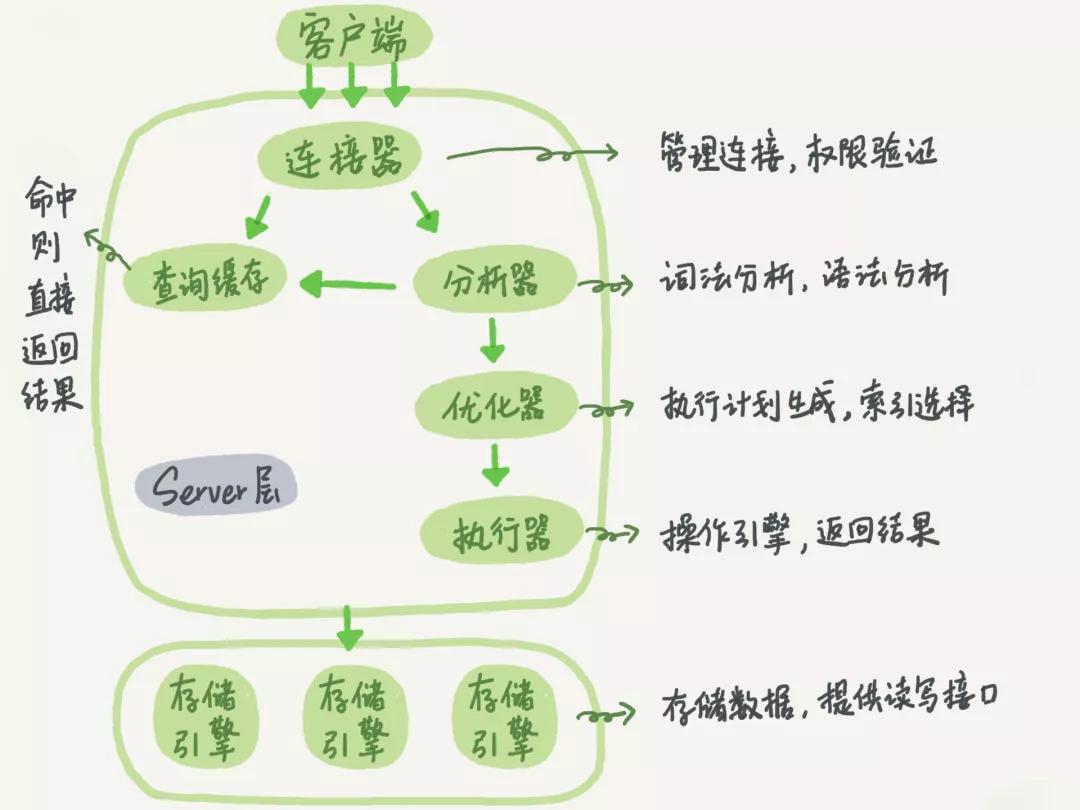
詳細結構如為
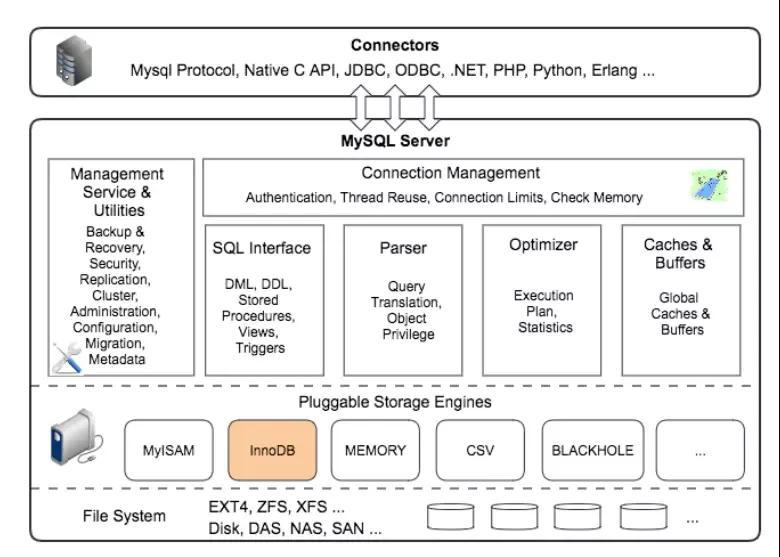
「當我們想更新某條數據的時候,難道是從磁盤中加載出來這條數據,更新后再持久化到磁盤中嗎?」
如果這樣搞的話,那一條sql的執行過程可太慢了,因為對一個大磁盤文件的讀寫操作是要耗費幾百萬毫秒的
真實的執行過程是,當我們想更新或者讀取某條數據的時候,會把對應的頁加載到內存中的Buffer Pool緩沖池中(默認為128m,當然為了提高系統的并發度,你可以把這個值設大一點)
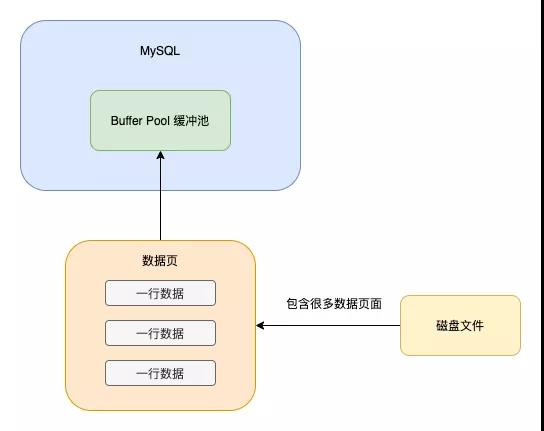
之所以加載頁到Buffer Pool中,是考慮到當你使用這個頁的數據時,這個頁的其他數據使用到的概率頁很大,隨機IO的耗時很長,所以多加載一點數據到Buffer Pool
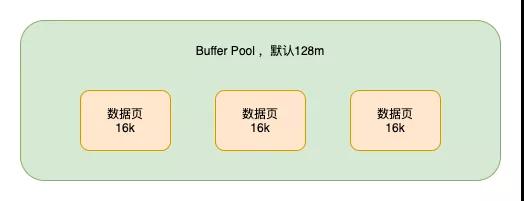
當更新數據的時候,如果對應的頁在Buffer Pool中,則直接更新Buffer Pool中的頁即可,對應的頁不在Buffer Pool中時,才會從磁盤加載對應的頁到Buffer Pool,然后再更新,「此時Buffer Pool中的頁和磁盤中的頁數據是不一致的,被稱為臟頁」。這些臟頁是要被刷回到磁盤中的
「這些臟頁是多會刷回到磁盤中的?」 有如下幾個時機
- Buffer Pool不夠用了,要給新加載的頁騰位置了,所以會利用改進的后的LRU算法,將一些臟頁刷回磁盤
- 后臺線程會在MySQL不繁忙的時候,將臟頁刷到磁盤中
- redolog寫滿時(redolog的作用后面會提到)
- 數據庫關閉時會將所有臟頁刷回到磁盤
這樣搞,效率是不是高很多了?
當需要更新的數據所在的頁已經在Buffer Pool中時,只需要操作內存即可,效率不是一般的高
「看到這小伙伴們可能會有一個疑問?如果對應的臟頁還沒有被刷到磁盤中,數據庫就宕機了,那我們的更改不就丟失了?」
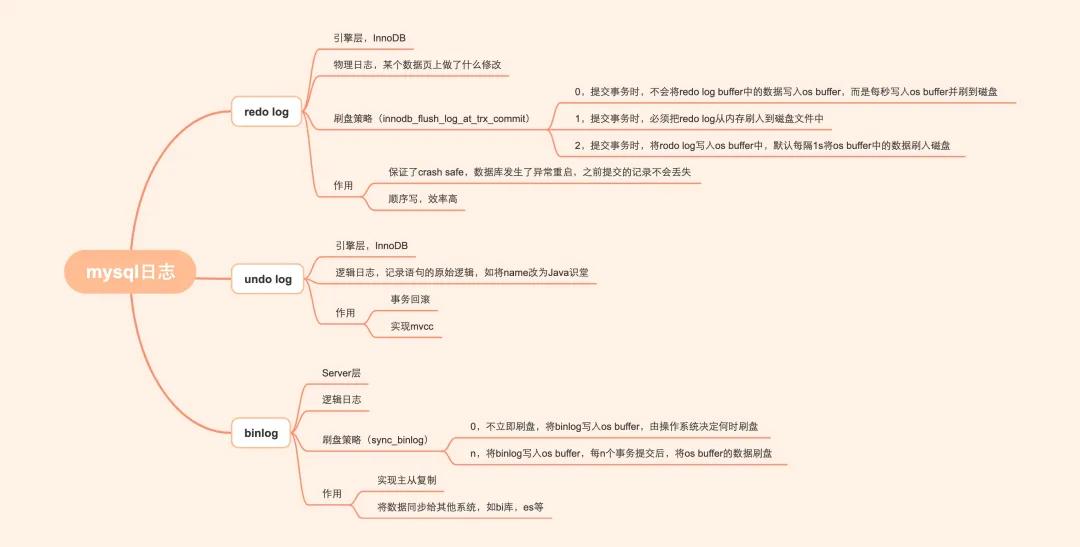
要解決這個問題,就不得不提到rodolog了。既然都打算說rodolog了,索性一塊說說mysql中的三種日志undolog,rodolog,binlog
undolog:如何讓更新的數據可以回滾?
以上面的student表為例,當我們想把id=1的name從a變為abc時,會把原來的值id=1,name=a寫入到undo log中。當這條更新語句在事務中執行,當事務回滾時,就可以通過undolog將數據恢復為原來的模樣。
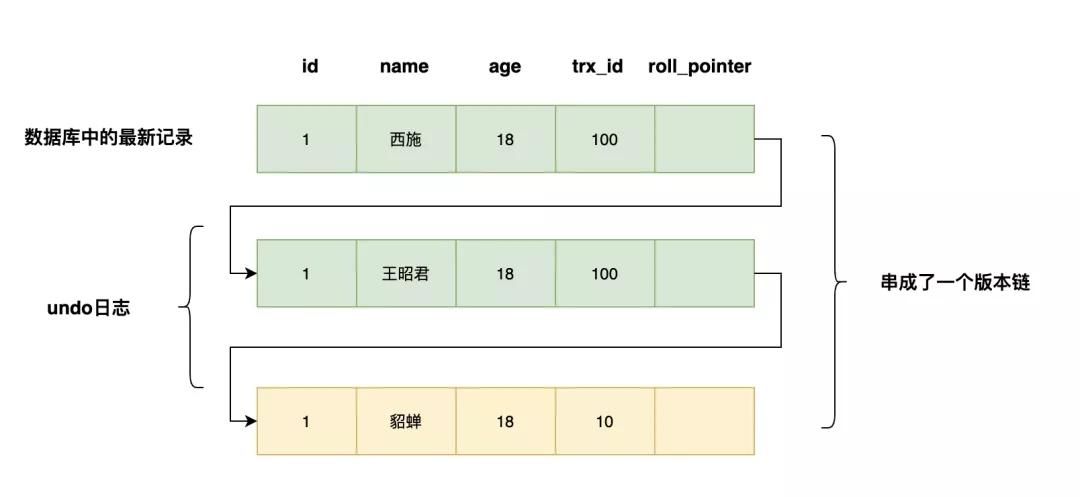
此外,undo log在mvcc的實現中也扮演了重要的作用,看我之前寫的文章《面試官:MVCC是如何實現的?》
rodolog:系統宕機了,如何避免數據丟失?
接著我們上面的問題,如果對應的臟頁還沒有被刷到磁盤中,數據庫就宕機了,那我們的更改不久丟失了?
為了解決這個問題,我們需要把內存所做的修改寫入到 redo log buffer中,這是內存里的一個緩沖區,用來存在redo日志。
rodo log記錄了你對數據所做的修改,如“將id=1這條數據的name從a變為abc”,物理日志哈,后面會再提一下。「redo log是順序寫所以比隨機寫效率高」
「InnoDB的redo log是固定大小的」,比如可以配置為一組 4 個文件,每個文件的大小是 1GB,那么總大小為4GB。從頭開始寫,寫到末尾就又回到開頭循環寫,如下面這個圖所示。
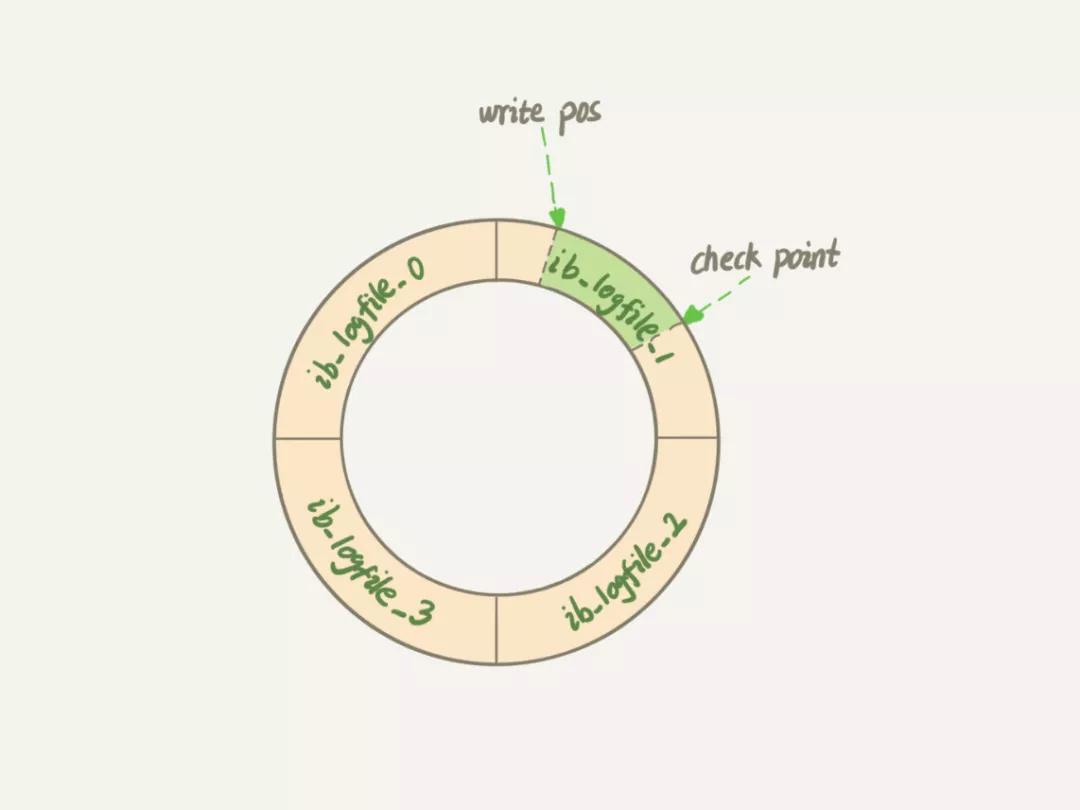
write pos是當前要寫的位置,checkpoint是要擦除的位置,擦除前要把對應的臟頁刷回到磁盤中。write pos和checkpoint中間的位置是可以寫的位置。
當我們的系統能支持的并發比較低時,可以看看對應的redo log是不是設置的太小了。太小的話會導致頻繁的刷臟頁,影響并發,可以通過工具監控redo log的大小
redolog的大小=innodb_log_file_size*innodb_log_files_in_group(默認為2)圖片「接下來我們詳細聊聊,redolog是如何避免數據丟失的」
事務未提交,MySQL宕機,這種情況Buffer Pool中的數據丟失,并且redo log buffer中的日志也會丟失,不會影響數據
提交事務成功,redo log buffer中的數據沒有刷到磁盤,此時會導致事務提交的數據丟失。
「鑒于這種情況,我們可以通過設置innodb_flush_log_at_trx_commit來決定redo log的刷盤策略」
查看innodb_flush_log_at_trx_commit的配置
- SHOW GLOBAL VARIABLES LIKE 'innodb_flush_log_at_trx_commit'
| innodb_flush_log_at_trx_commit值 | 作用 |
|---|---|
| 0 | 提交事務時,不會將redo log buffer中的數據寫入os buffer,而是每秒寫入os buffer并刷到磁盤 |
| 1 | 提交事務時,必須把redo log從內存刷入到磁盤文件中 |
| 2 | 提交事務時,將rodo log寫入os buffer中,默認每隔1s將os buffer中的數據刷入磁盤 |
應為0和2都可能會造成事務更新丟失,所以一般系統中innodb_flush_log_at_trx_commit的值都為1,你可以看看你們的系統用的哪個值?
binlog:主從庫之間如何同步數據?
當我們把mysql主庫的數據同步到從庫,或者其他數據源時,如es,bi庫時,只需要訂閱主庫的binlog即可。
「binlog這一節的很多內容參考了《MySQL實戰45講》的02節,有些內容在02節做了詳細的解釋,我就不多介紹了,可以結合著看本文」
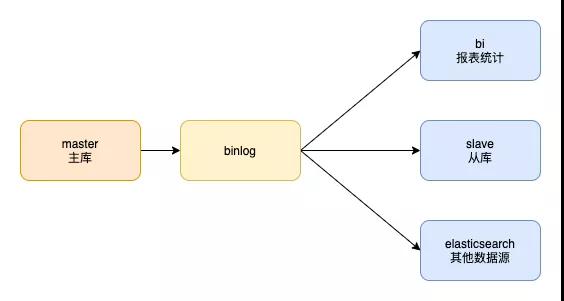
為什么要弄2種日志呢?其實這都是由歷史原因決定的
MySQL剛開始用binlog實現歸檔的功能,但是binlog沒有crash-safe的能力,所以后來InnoDB引擎加了redo log來實現crash-safe。假如MySQL中只有一個InnoDB引擎,說不定就能用redo log來實現歸檔了,此時就可以將redo log和 binlog合并到一塊了
這兩種日志的區別如下:
- redo log是InnoDB存儲引擎特有,binglog是MySQL的server層實現的,所有引擎都可以使用
- redo log是物理日志,記錄的是數據頁上的修改。binlog是邏輯日志,記錄的是語句的原始邏輯,如給id=2的這一行的c字段加1
- redo log是固定空間,循環寫。binlog是追加寫,當binlog文件寫到一定大小后會切換到下一個,并不會覆蓋以前的日志
「我們可以通過設置sync_binlog來決定binlog的刷盤策略」
| sync_binlog值 | 作用 |
|---|---|
| 0 | 不立即刷盤,將binlog寫入os buffer,由操作系統決定何時刷盤 ,有可能會丟失多個事務的數據 |
| 1 | 將binlog寫入os buffer,每n個事務提交后,將os buffer的數據刷盤 |
一般情況下將sync_binlog的值設為1即可
兩階段提交
接著我們來看一下將id=2的行c字段加1的執行流程。
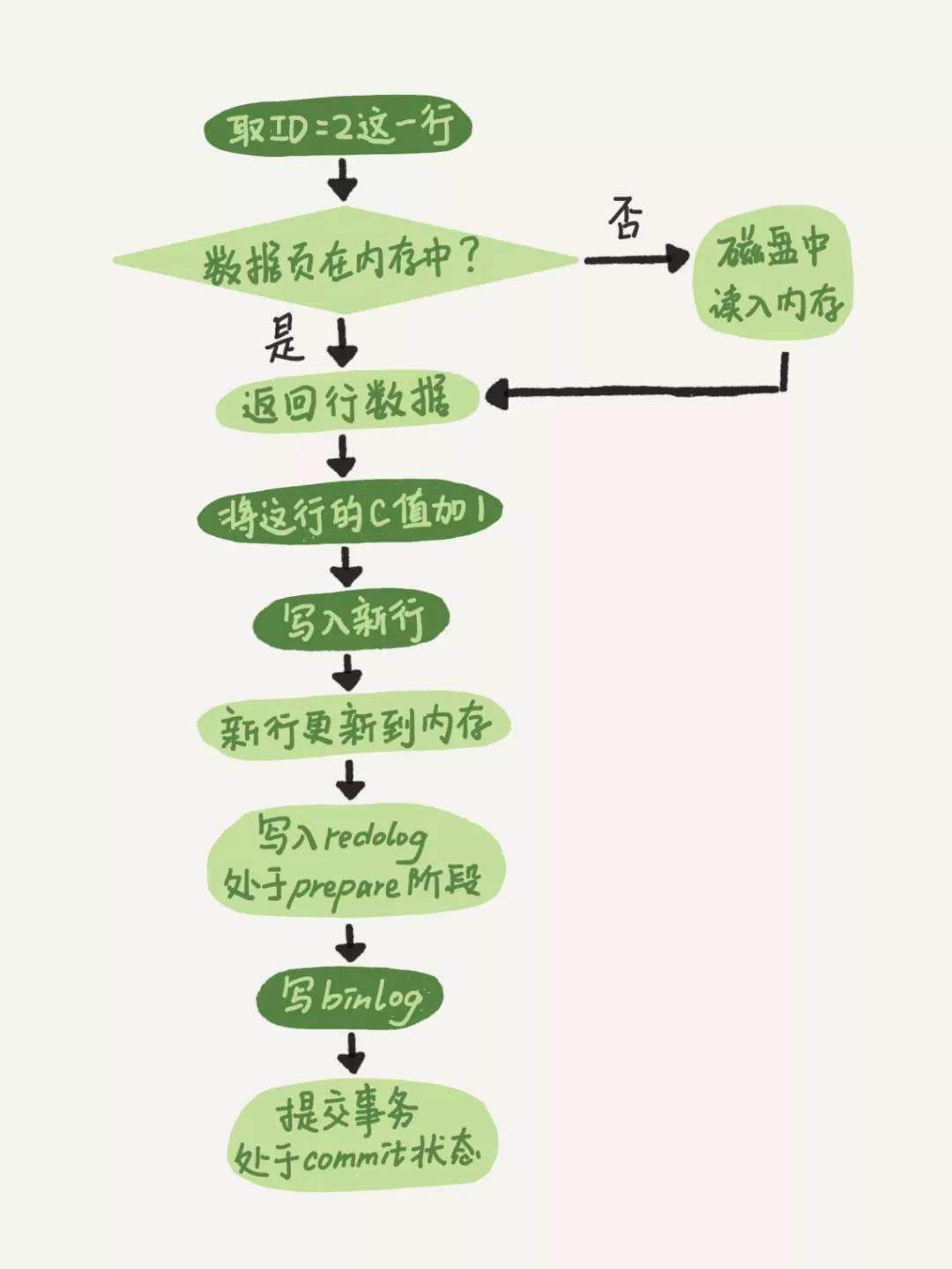
前面的這個階段大家應該都能看懂了把,沒看懂的可以看一下《MySQL實戰45講 》,重點說一下最后三個階段
引擎將新數據更新到內存中,將操作記錄到redo log中,此時redo log處于prepare狀態,然后告知執行器執行完成了,可以提交事務
執行器生成操作的binlog,并把binlog寫入磁盤
引擎將寫入的redo log改為提交狀態,更新完成
「為什么要把relog的寫入拆成2個步驟?即prepare和commit,兩階段提交」
因為不管你先寫redolog還是binlog,奔潰發生后,最終其實都有可能會造成原庫和用日志恢復出來的庫不一致
「而兩階段提交可以避免這個問題」
redolog和binlog具有關聯行,在恢復數據時,redolog用于恢復主機故障時的未更新的物理數據,binlog用于備份操作。每個階段的log操作都是記錄在磁盤的,在恢復數據時,redolog 狀態為commit則說明binlog也成功,直接恢復數據;如果redolog是prepare,則需要查詢對應的binlog事務是否成功,決定是回滾還是執行。
說說我踩過的一些坑
「1. 數據庫支持的并發度不高」
在一些并發要求高的系統中,可以調高Buffer Pool和redo log,這樣可以避免頻繁的刷臟頁,提高并發
「2. 事務提交很慢」
原來我負責的一個系統跑的挺正常的,直到上游系統每天2點瘋狂調我接口,然后我這邊都是事務方法,事務提交很慢。監控到Buffer Pool和redo log的設置都很合理,并沒有太小,所以問題出在哪了?我也不知道
「后來dba排查到原因,把復制方式從半同步復制改為異步復制解決了這個問題」
「異步復制」:MySQL默認的復制即是異步的,主庫在執行完客戶端提交的事務后會立即將結果返給給客戶端,并不關心從庫是否已經接收并處理,這樣就會有一個問題,主如果crash掉了,此時主上已經提交的事務可能并沒有傳到從庫上,如果此時,強行將從提升為主,可能導致新主上的數據不完整
「半同步復制」:是介于全同步復制與全異步復制之間的一種,主庫只需要等待至少一個從庫節點收到并且 Flush Binlog 到 Relay Log 文件即可,主庫不需要等待所有從庫給主庫反饋。同時,這里只是一個收到的反饋,而不是已經完全完成并且提交的反饋,如此,節省了很多時間
「全同步復制」:指當主庫執行完一個事務,所有的從庫都執行了該事務才返回給客戶端。因為需要等待所有從庫執行完該事務才能返回,所以全同步復制的性能必然會收到嚴重的影響
「3. 在一個方法中,我先插入了一條數據,然后過一會再查一遍,結果插入成功,卻沒有查出來」
這個比較容易排查,如果系統中采用了數據庫的讀寫分離時,寫插入的是主庫,讀的卻是從庫,binlog同步比較慢時,就會出現這種情況,此時只需要讓這個方法強制走主庫即可
本文轉載自微信公眾號「Java識堂」,可以通過以下二維碼關注。轉載本文請聯系Java識堂公眾號。