













DeepMind新模型自動生成CAD草圖,網友:建筑設計要起飛了
在制造業中,CAD 的應用十分廣泛。憑借著精準、靈活、快速的特性,CAD 已經取代了紙筆畫圖,并且不再只是應用于汽車制造、航空航天等領域,哪怕小到一個咖啡杯,生活中幾乎每個物件都由 CAD 畫圖建模。
CAD 模型中最難制作的部件之一就是高度結構化的 2D 草圖,即每一個 3D 構造的核心。盡管時代不同了,但 CAD 工程師仍然需要多年的培訓和經驗,并且像紙筆畫圖設計的前輩們一樣關注所有的設計細節。下一步,CAD 技術將融合機器學習技術來自動化可預測的設計任務,使工程師可以專注于更大層面的任務,以更少的精力來打造更好的設計。
在最近的一項研究中,DeepMind 提出了一種機器學習模型,能夠自動生成此類草圖,且結合了通用語言建模技術以及現成的數據序列化協議,具有足夠的靈活性來適應各領域的復雜性,并且對于無條件合成和圖像到草圖的轉換都表現良好。
論文鏈接:
https://arxiv.org/pdf/2105.02769.pdf
具體而言,研究者開展了以下工作:
使用 PB(Protocol Buffer)設計了一種描述結構化對象的方法,并展示了其在自然 CAD 草圖領域的靈活性;
從最近的語言建模消除冗余數據中吸取靈感,提出了幾種捕捉序列化 PB 對象分布的技術;
使用超過 470 萬精心預處理的參數化 CAD 草圖作為數據集,并使用此數據集來驗證提出的生成模型。事實上,無論是在訓練數據量還是模型能力方面,實際的實驗規模都比這更多。
CAD 草圖展示效果圖如下:
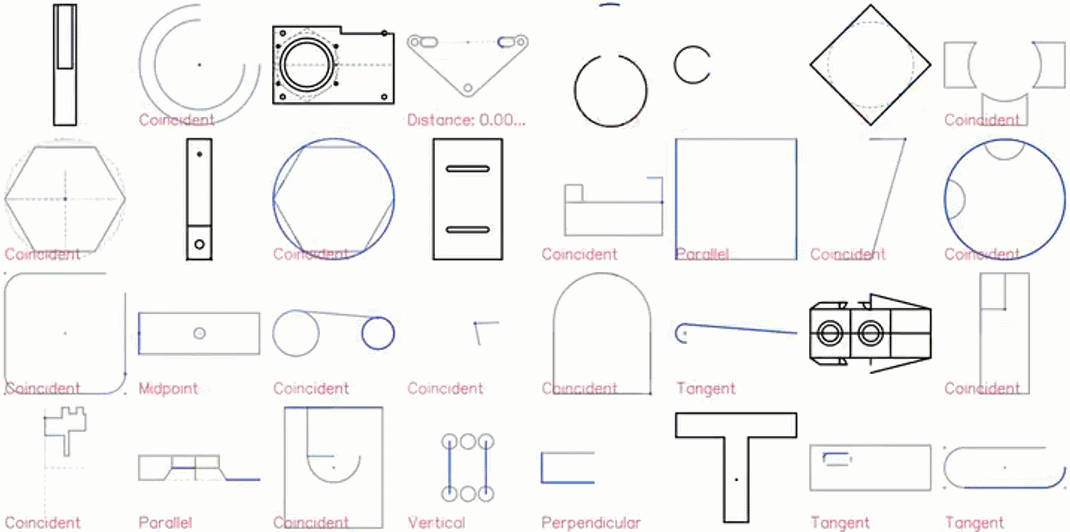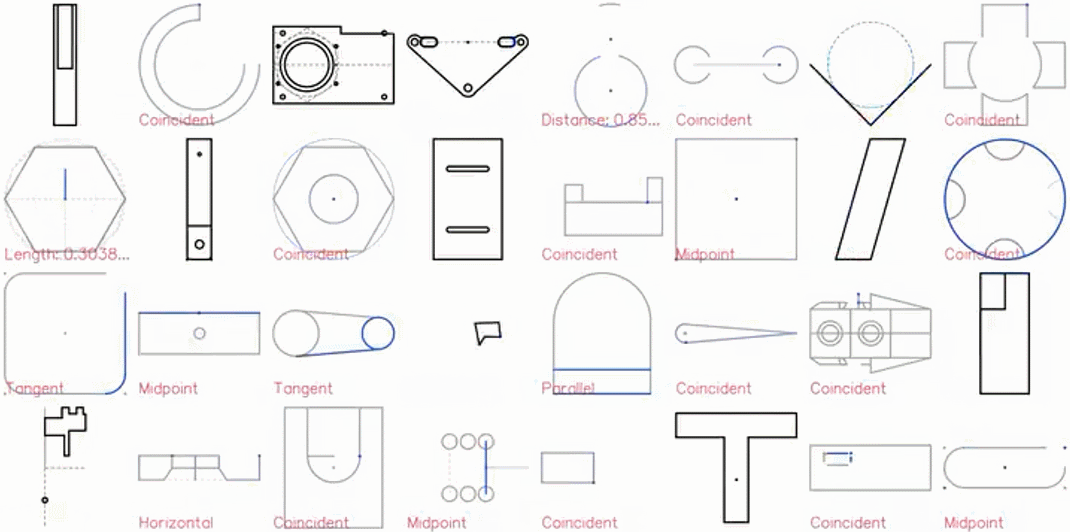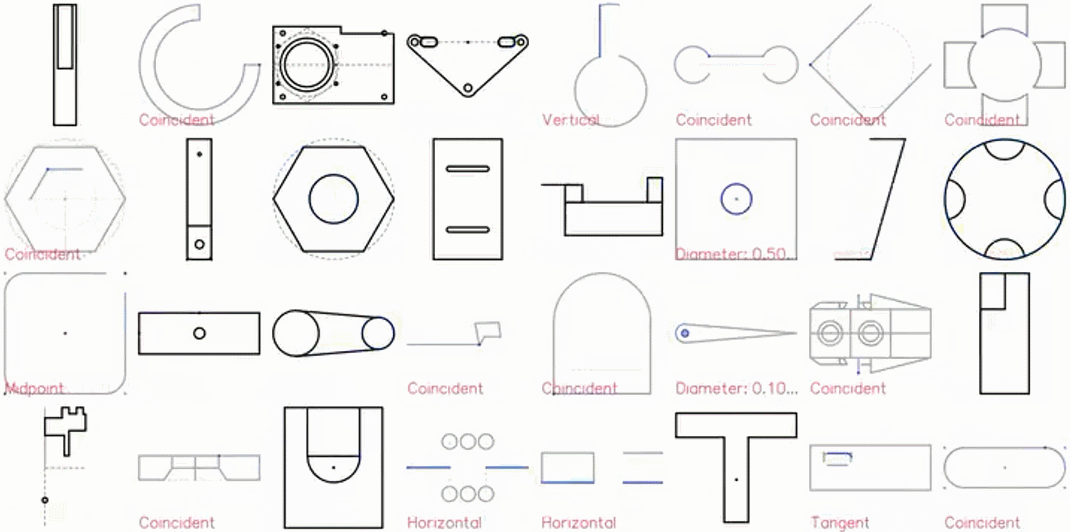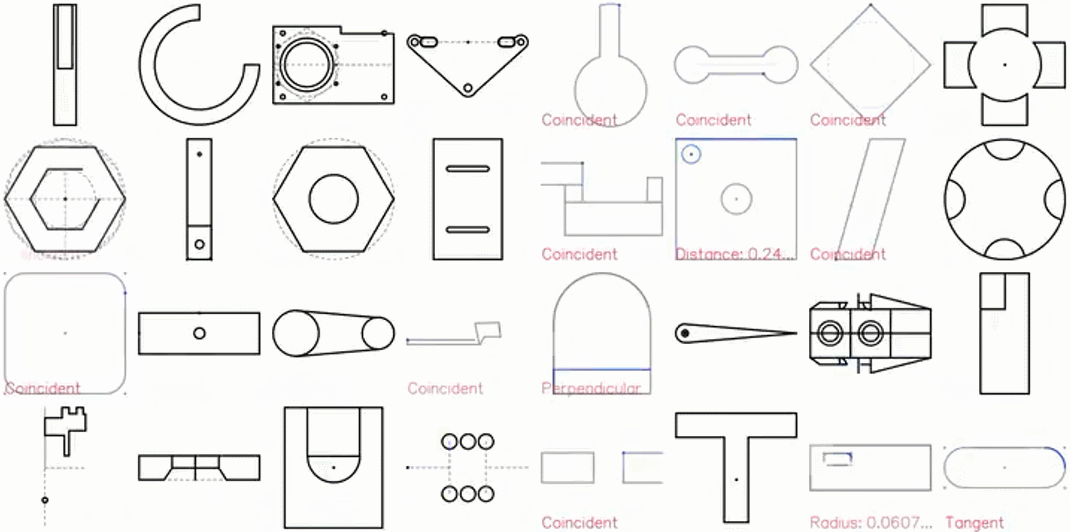
特寫鏡頭展示:

對于 DeepMind 的這項研究,網友的評價非常高。用戶 @Theodore Galanos 表示:「非常棒的解決方案。我曾使用 SketchGraphs 作為多模態模型的候選方案,但序列的格式和長度太不容易處理了。等不及在建筑設計中也使用這種方法了。」
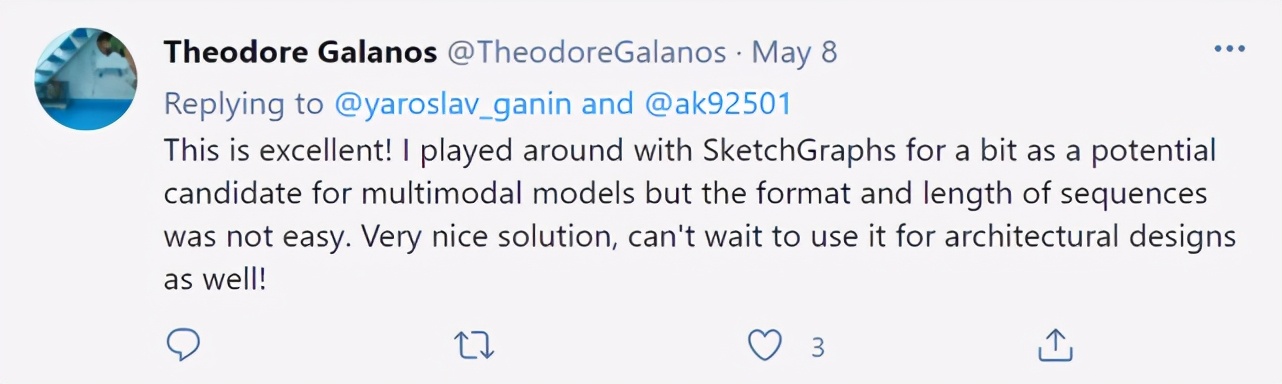
草圖之于 CAD
2D 草圖是機械 CAD 的核心,是構成三維形式的骨架。草圖由通過特定的約束(例如正切、垂直和對稱)相關聯的各種線、弧、樣條線和圓組成。這些約束旨在傳達設計意圖,并定義在實體的各種變換下,形狀應該如何發生變化。下圖說明了約束是如何將不同的線、弧等幾何圖形組合創建成特定的形狀的。虛線顯示了丟失約束時的另一個有效的解決方案。所有的幾何實體都位于一個草圖平面上,共同形成封閉的區域,供后續操作(例如放樣和拉伸)使用,以生成復雜的 3D 幾何。
約束:草圖逃不開的問題
約束( constraint )使草圖比看起來要復雜得多。它們展現了可以間接影響草圖中每個實體的關系。例如,在上圖中,如果在底角保持固定的狀態下向上拖動兩個圓弧相交的點,則心形的大小會增大。這種轉變看似簡單,但實際上是所有約束共同作用的結果。
這些約束確保了當每個實體的尺寸和位置發生變化時,形狀仍保持著設計者想傳達的狀態。由于實體之間復雜的相互作用,很容易意外地指定一組約束,從而導致草圖無效。例如,同時滿足平行和垂直約束的兩條線是無法繪制的。在復雜的草圖中,約束依賴關系鏈會導致設計人員確定要添加的約束變得極為困難。此外,對于給定的一組實體,有許多等效的約束系統能產生類似的草圖。
一個高質量的草圖通常會使用一組保留設計意圖的約束,這意味著即使更改了實體參數(例如尺寸),草圖的語義也得以保留。簡而言之,無論實體尺寸如何變化,上圖中的心形永遠是心形。捕捉設計意圖與選擇一致的約束系統的復雜性使草圖生成變成極其困難的問題。
草圖與自然語言建模的相似性
草圖構造的復雜性有些類似于自然語言建模。在草圖中選擇下一個約束或實體就像生成句子中的下一個單詞,而兩者中的的選擇又必須在語法上起作用(在草圖中形成一個一致約束系統),并保留設計意圖。
在生成自然語言方面,已經有了許多成功的工具,其中表現最佳的無疑是在大量現實世界數據上進行訓練的機器學習模型。比如 2017 年的 Transformer 架構,展示了強大的連貫造句的能力。這些自然語言模型中的規律,是否可以用來繪制草圖呢?
數據
Onshape 是維度驅動設計的一個參數化實體建模軟件。但為了存儲和處理草圖,研究者使用 PB,而不是 Onshape API 提供的原始 JSON 格式。使用 PB 具有雙重的優勢:由于移除了不必要的信息,結果數據占用的空間更少;使用 PB 語言可以輕松地為結構各異的復雜物體定義精準的規格。
一旦設定好所有必要的對象類型,就需要將數據轉換為可以通過機器學習模型來處理的表格。研究者選擇將草圖表示為 tokens 序列,以便使用語言建模生成草圖。文本格式包含了結構和數據的內容,這樣使用的優勢是可以應用任何現成的文本數據建模方法。不過,即使對于現代語言建模技術,這樣做也是有代價的:模型為了生成有效的語法,將額外占用模型容量的一部分。
解決的手段就是避免使用字節格式 PB 定義的通用解析器,利用草圖格式的結構來自定義構建設計解釋器,即輸入一系列代表草圖創建過程中各個決策步驟有效選擇的 tokens。在這種 tokens 序列的格式下設計解釋器會導致 PB 消息有效。
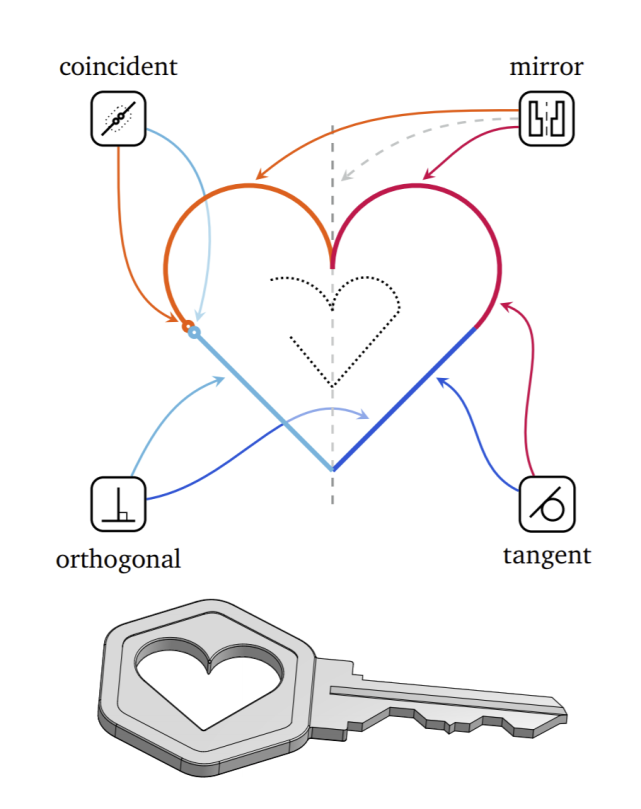
在這種格式下,研究者將消息表示為 triplets 序列(,,),其中是 token 的索引。給定一系列這樣的 triplets,推斷每個 token 對應的確切字段是可能的。實際上,第一個 token(,,)始終與 objects.kind 相關聯,因為它是創建一個草圖消息的首選。第二個字段取決于1 的具體值。如果1= 0,那么第一個對象是一個實體,這意味著第二個 token 對應于 entity.kind。該序列的其余部分以類似的方式關聯。字段標識符及其在對象中的位置構成了 token 的上下文。因為它使解釋 triplets 值的含義以及了解整體數據結構更容易,研究者將此信息用作機器學習模型的其他輸入。

如上圖所示,草圖包含了一條線實體和一個點實體。在左列的每個 triplet 中,實際使用的值以粗體顯示。右列顯示了 triplet 與對象的哪個字段有關聯。
從模型中取樣
建立模型的主要目標是估計數據集 D 中的 2D 草圖 data 的分布。就像上文提到的,研究者將像 token 序列一樣處理草圖。在這項工作中,由于相關原始文本格式的序列長度挑戰,只會考慮使用用字節和 triplet 來表示。
從字節模型取樣很簡單,該過程與任何典型的基于 Transformer 的語言建模過程相同,而 Triplet 模型需要更多的定制處理。
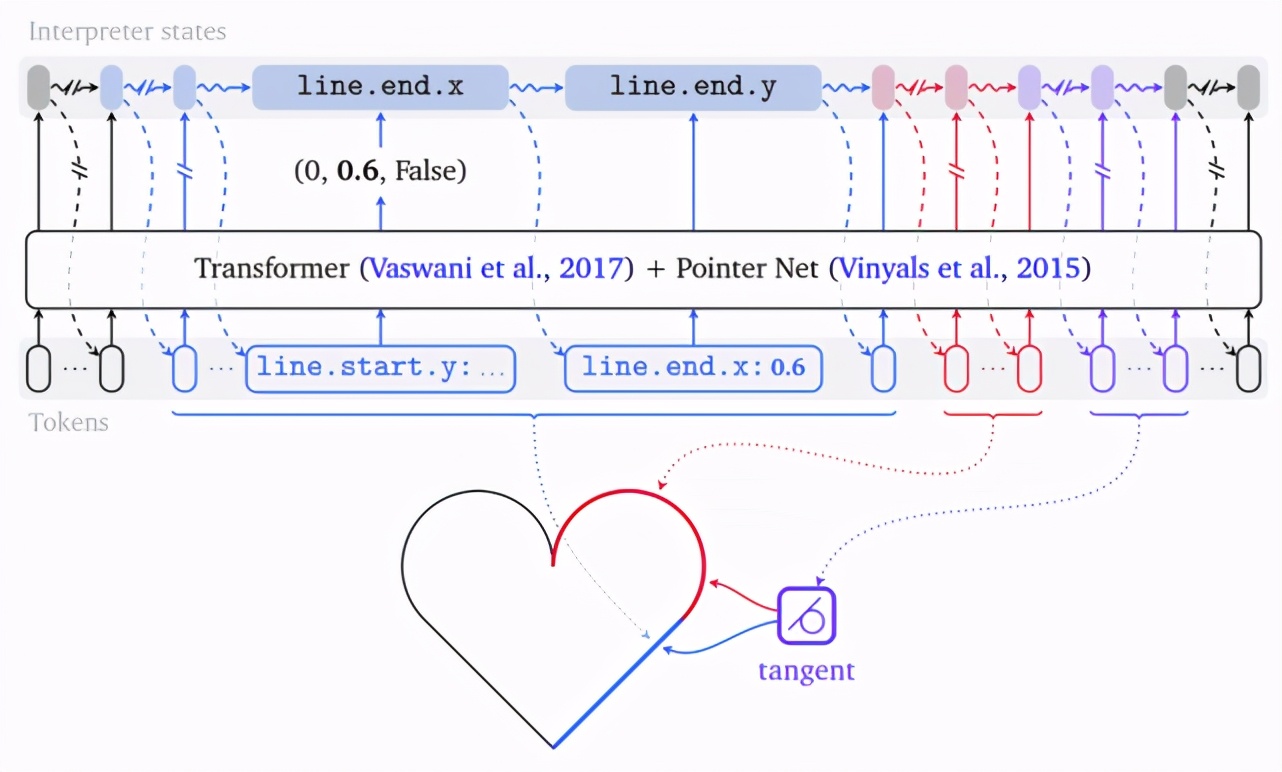
上圖展示了 Triplet 的處理過程:首先將特殊的 BOS token 嵌入并提供給 Transformer。然后,Transformer 輸出一組 triplets,每個可能的 token 組一個。為了確定具體需要發出哪個 token,應用從數據規格中自動生成的解釋器(狀態機),再選擇合適的 token 組并關聯在合成對象中具有字段的 triplet 的活動組件。填入適當的字段后,解釋器轉換到下一個狀態并生成一個輸出 token,然后將其反饋到該模型。當狀態機收到最外層重復字段(即 object.kind)的 “end” triplet 時,停止該過程。
實驗
研究者使用了從 Onshape 平臺上公開可用的文檔庫中獲得的數據對方法進行驗證。遵循自回歸生成模型的標準評估方法,研究者使用對數可能性作為主要的定量指標。此外,研究者還提供了各種隨機和選定的模型樣本以進行定性分析評估。
訓練細節
研究者使用 128 個通道的批次訓練模型以進行 10^6 個權重更新。每個通道都可以在 triplet 設置中容納 1024 個 tokens 的序列,在字節設置中容納 1990 個 tokens。為了提高占用率并減少計算浪費,研究者動態地填滿了通道,在繼續前進到下一條道之前將盡可能多的例子打包。每個批次由 32 個 TPU 內核并行處理。
此外,研究者還使用了 Adam 優化器,學習率為 10^−4,梯度范數為 1.0,所有實驗均采用 0.1 的失活率。
實驗結果
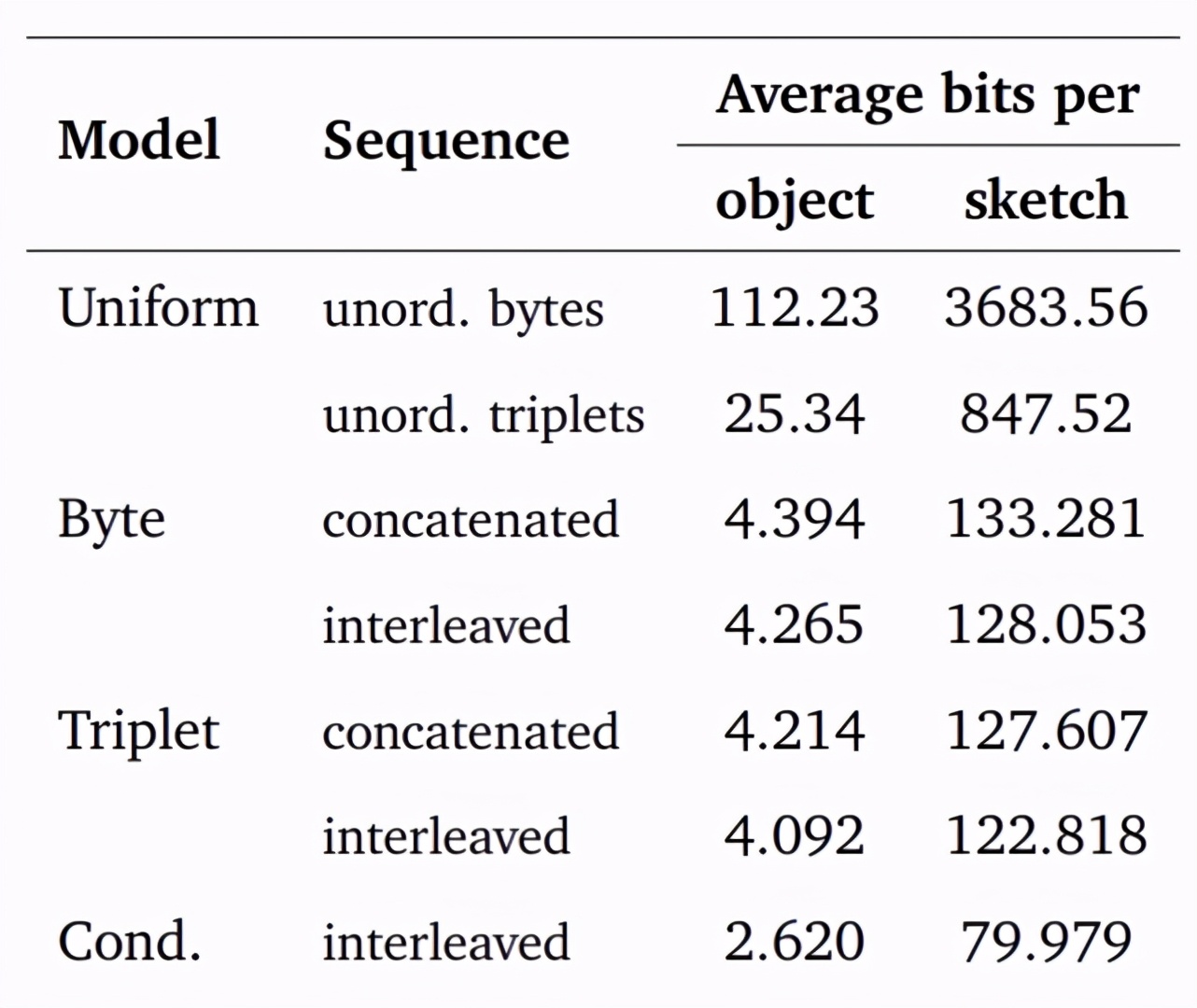
如上圖所示,各種模型的可能性都被測試到了。第三列是草圖測試樣本中每個對象的平均字節數,第四列是第三列乘以對象數。
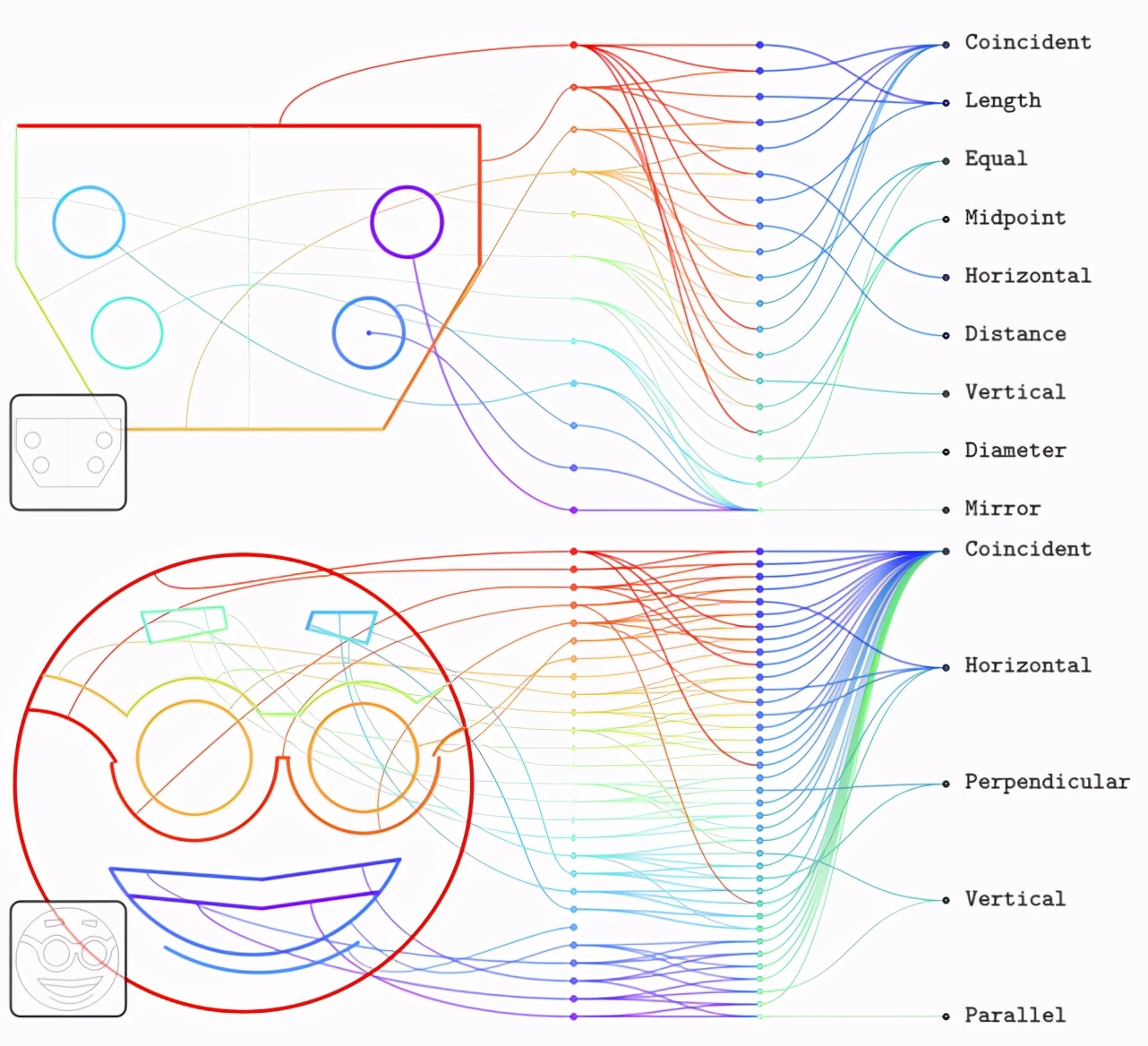
下圖是從 triplet 模型中取樣的實體與約束。第一列節點代表了不同的實體,節點從上至下遵循生成的順序。第二列代表著不同的約束,按照序列索引排序。第三列是從頻率最高到最低的約束類型。

下圖是條件模型的實體和約束。左下角是輸入位圖,下例說明了模型在分布外輸入時的表現。
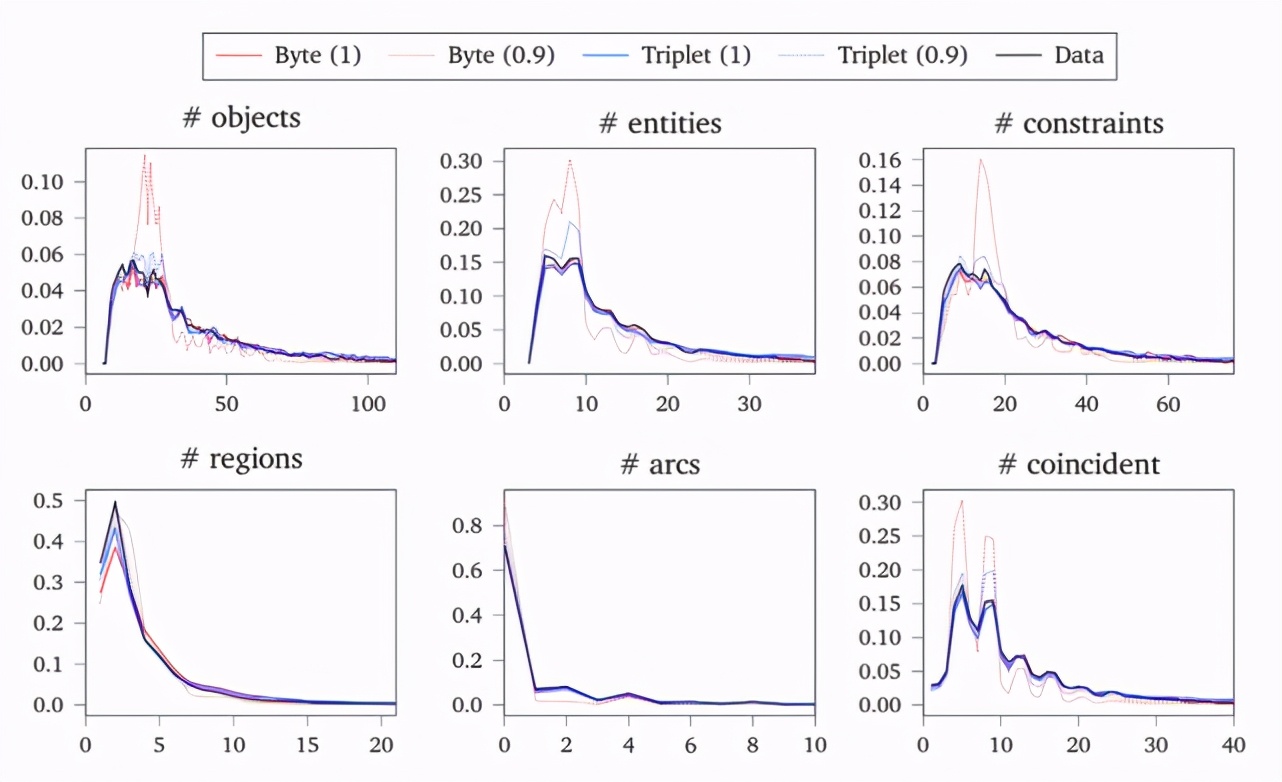
下圖顯示了從非條件模型取樣的各種草圖數據分布統計,而括號中的是 Nucleus 取樣的 top-p 參數。
這些只是最初的概念驗證實驗。DeepMind 表示,希望能夠看到更多利用已開發接口的靈活性優勢開發的應用程序,比如以各種草圖屬性為條件,給定實體來推斷約束,以自動完成圖紙。





















