電商的千人千面系統(tǒng),這樣搞比較靠譜
本文轉(zhuǎn)載自微信公眾號(hào)「二馬讀書」,作者二馬讀書。轉(zhuǎn)載本文請(qǐng)聯(lián)系二馬讀書公眾號(hào)。
本文詳細(xì)描述了千人千面的具體業(yè)務(wù)邏輯、技術(shù)方案和推薦算法,以及需要注意的問題。
互聯(lián)網(wǎng)行業(yè)的快速發(fā)展,給我們帶來了極大的便利。回顧整個(gè)互聯(lián)網(wǎng)行業(yè)的發(fā)展歷程,從PC時(shí)代到移動(dòng)互聯(lián)網(wǎng)時(shí)代,從移動(dòng)互聯(lián)網(wǎng)時(shí)代到IOT(物聯(lián)網(wǎng))時(shí)代,現(xiàn)在又即將從IOT時(shí)代邁入AI(人工智能)時(shí)代。這些飛速發(fā)展的背后,其實(shí)是對(duì)數(shù)據(jù)利用的巨大變革。
當(dāng)下,移動(dòng)互聯(lián)網(wǎng)技術(shù)和智能手機(jī)的發(fā)展,使得采集用戶數(shù)據(jù)的能力變得空前強(qiáng)大,無時(shí)無刻,無所不在。擁有這些數(shù)據(jù)后,全行業(yè)的個(gè)性化推薦能力變得更加容易實(shí)現(xiàn),不論是淘寶京東,還是今日頭條,無疑是這個(gè)時(shí)代的最大受益者。
不同于個(gè)人電腦,手機(jī)這類私人專屬物品是與其他人很難共用的。從而手機(jī)的型號(hào),以及在手機(jī)上的瀏覽、交易等行為數(shù)據(jù),就具有了極高的分析價(jià)值。
從電商平臺(tái)的角度來講,個(gè)性化推薦的本質(zhì)是根據(jù)不同的人群,將最有可能成交的商品優(yōu)先推薦給相應(yīng)的消費(fèi)者,最大限度的提高購買轉(zhuǎn)化率,促進(jìn)用戶購買下單。
當(dāng)然,對(duì)于淘寶這類電商平臺(tái)來說,個(gè)性化推薦也能充分利用有限的廣告位資源,將流量的價(jià)值最大化。隨著用戶個(gè)人數(shù)據(jù)的不斷豐富,推薦能力也在逐步升級(jí),從基礎(chǔ)的千人一面逐漸演化到千人千面。下面描述千人千面的具體業(yè)務(wù)邏輯、技術(shù)方案和推薦算法,以及需要注意的問題。
電商千人千面業(yè)務(wù)邏輯
我們了解到千人千面的本質(zhì)是根據(jù)不同的人群,將最有可能成交的商品優(yōu)先推薦給相應(yīng)的消費(fèi)者,最大限度上促進(jìn)用戶購買下單。那么具體的商品展現(xiàn)邏輯是怎樣的呢?
千人千面,主要應(yīng)用于首頁、購物車、商品詳情頁、搜索列表等位置。

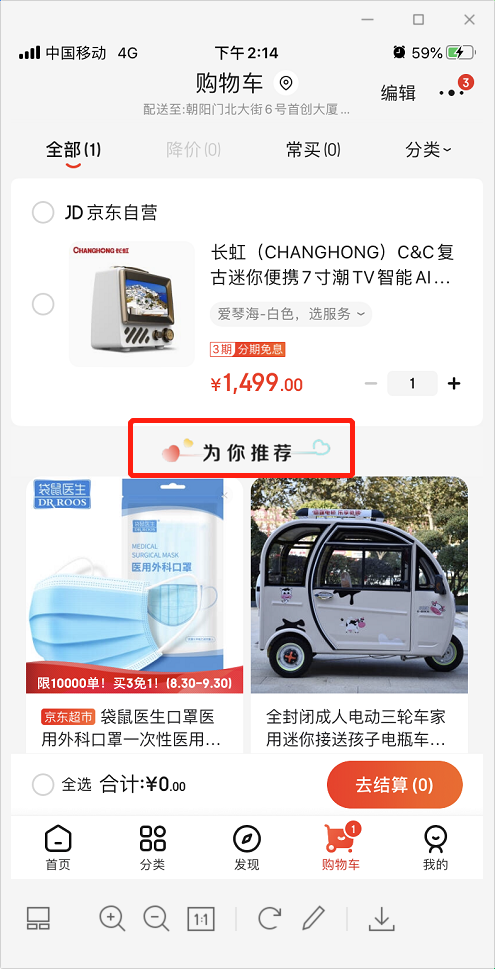

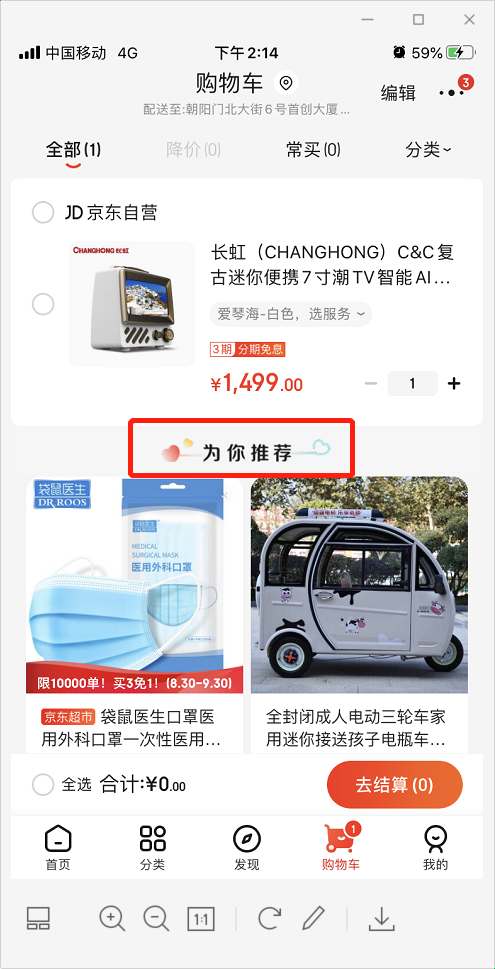
上面三個(gè)截圖分別是首頁、購物車和商品詳情頁,紅框部分的“為你推薦”即是根據(jù)用戶數(shù)據(jù)對(duì)用戶進(jìn)行的個(gè)性化商品推薦,不同用戶展現(xiàn)的商品都不一樣,也就是所謂的“千人千面”。
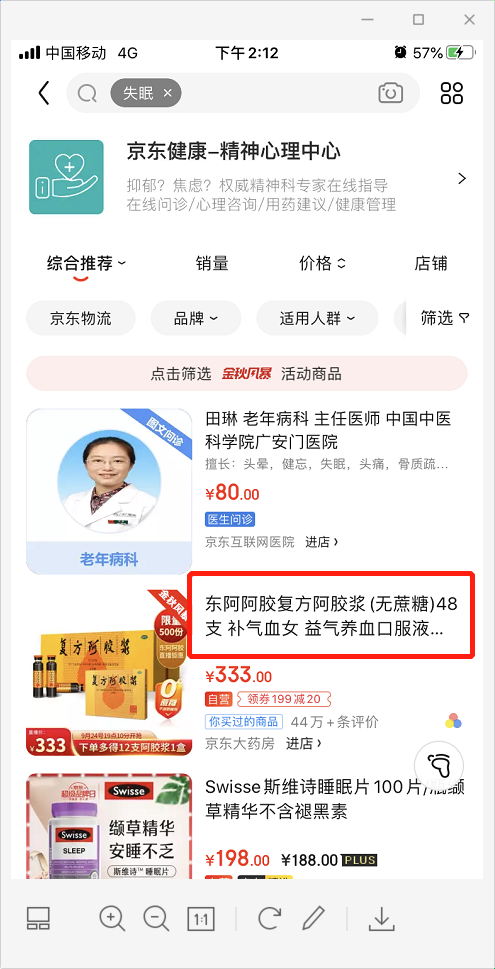
上面這張截圖是搜索列表。其實(shí)搜索跟推薦也是分不開的,為了提高轉(zhuǎn)化率,搜索結(jié)果往往要依賴于用戶行為數(shù)據(jù)。我在搜索欄搜索“失眠”后,列表中顯示了阿膠漿,很眼熟。對(duì)了,幾天前我在APP里瀏覽過阿膠漿,剛好阿膠漿其中一個(gè)功效就是助眠,所以搜索列表就顯示了這款商品。如果換一個(gè)用戶搜索,很可能會(huì)搜不到阿膠漿,至少大概率不會(huì)顯示在列表頂部。
如上圖所示,千人千面買家的購買和瀏覽行為決定著產(chǎn)品的展示順序,第一到第三層,很容易理解,也是大家常規(guī)對(duì)千人千面的基本認(rèn)識(shí),那么,第四層級(jí)是什么意思呢?類似的標(biāo)簽?
其實(shí)每個(gè)消費(fèi)者只要有在淘寶網(wǎng)上購買或是瀏覽過,平臺(tái)就會(huì)給用戶打上標(biāo)簽,比如年齡、客單價(jià)、喜好、關(guān)注點(diǎn)等。根據(jù)用戶標(biāo)簽的不同,每個(gè)用戶訪問APP時(shí)展示的商品就會(huì)有所差別。假設(shè)兩個(gè)男生從來沒有買過女性產(chǎn)品,第一次給女性買東西,搜索同一個(gè)關(guān)鍵詞比如“連衣裙 女”,他們看到的商品列表也不一樣,平臺(tái)會(huì)根據(jù)你以往的一些購買行為打上標(biāo)簽,比如用戶有“年輕、高客單價(jià)、愛名牌”等標(biāo)簽,那么展示給這個(gè)用戶的就會(huì)是年輕款、高客單價(jià)的連衣裙相關(guān)商品。也就是說:根據(jù)用戶的標(biāo)簽特征,將最有可能成交的商品優(yōu)先推薦給相應(yīng)的消費(fèi)者,最大限度的提高購買轉(zhuǎn)化率,促進(jìn)用戶購買下單。這就是千人千面的主要目的。
上面我們提到的用戶標(biāo)簽,我們也經(jīng)常稱之為“用戶特征”。我們一般會(huì)維護(hù)一個(gè)用戶特征數(shù)據(jù)庫,這是千人千面的基礎(chǔ)。在搜索和推薦時(shí)往往需要這些用戶特征數(shù)據(jù)。
推薦系統(tǒng)架構(gòu)
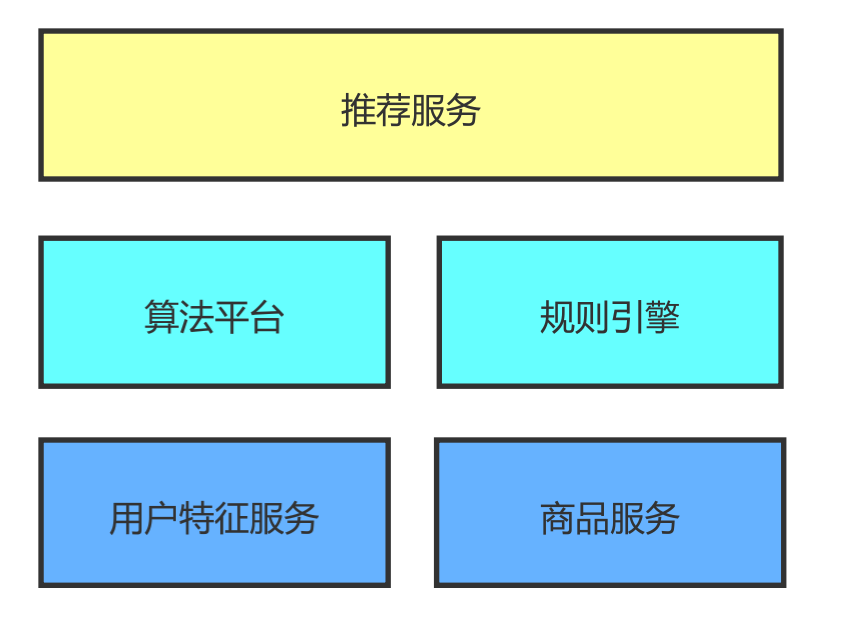
上面是一個(gè)簡單的推薦系統(tǒng)的架構(gòu)圖。推薦服務(wù)依賴于算法和規(guī)則,對(duì)于簡單的規(guī)則直接走規(guī)則引擎,對(duì)于較復(fù)雜的邏輯可以走算法,比如需要做機(jī)器學(xué)習(xí)或深度學(xué)習(xí)模型訓(xùn)練的場景。不管是規(guī)則引擎還是模型訓(xùn)練,都需要數(shù)據(jù)的支撐,用戶特征服務(wù)和商品服務(wù)會(huì)給他們提供最基礎(chǔ)的用戶特征數(shù)據(jù)和商品數(shù)據(jù)。
數(shù)據(jù)存儲(chǔ),快速存取
數(shù)據(jù)存儲(chǔ)主要是指用戶特征數(shù)據(jù)的存儲(chǔ),這個(gè)量比較大。至于商品數(shù)據(jù)一般不會(huì)太大,淘寶這種體量的平臺(tái)也不過三五千萬的商品數(shù)量。我們的用戶量大概有兩億多,月活躍用戶5000萬。為了保證系統(tǒng)的高性能,我們將數(shù)據(jù)存放在Redis集群中,在Redis中做分片存儲(chǔ)。以u(píng)serID做為Key,這個(gè)用戶的特征數(shù)據(jù)作為Value。以u(píng)serID做為Redis分片的路由Key。為了減少Redis存儲(chǔ)空間,我們選用了protobuf作為數(shù)據(jù)存儲(chǔ)格式。Protobuf是Google開源的,protobuf的序列化和反序列化性能很高,而且占用的空間比一般的格式要減少一半以上。
推薦算法
常見的個(gè)性推薦算法主要包括:基于內(nèi)容的推薦、基于協(xié)同過濾的推薦、基于知識(shí)的推薦等。在實(shí)際應(yīng)用中,很多電商平臺(tái)往往以多種推薦方式融合的方式,實(shí)現(xiàn)個(gè)性化推薦。
基于內(nèi)容的推薦(CB,Content-Based Recommendation)
基于內(nèi)容相關(guān)性為用戶推薦商品,利用內(nèi)容本身的特征進(jìn)行推薦。從類目、品牌、商品屬性、商品標(biāo)題、商品標(biāo)簽等多個(gè)維度計(jì)算內(nèi)容相似度,將相似度最高的商品推薦給相關(guān)用戶。內(nèi)容的推薦是非常基礎(chǔ)的推薦方法,計(jì)算的是內(nèi)容本身的相關(guān)程度。
比如某個(gè)用戶在淘寶上瀏覽過男士襯衫,在淘寶的發(fā)現(xiàn)好貨就會(huì)給你推薦各種各樣的男士襯衣、男士T恤、男士西裝等,如果這個(gè)用戶繼續(xù)訪問男士七分袖襯衣,系統(tǒng)獲取到這個(gè)產(chǎn)品屬性,會(huì)繼續(xù)給你推薦七分袖的亞麻襯衣、七分袖麻料襯衣、五分袖襯衣、男士七分袖T恤等等。這就相當(dāng)于在商場身邊有個(gè)貼身的導(dǎo)購,你每試穿一次衣服又為你推薦一系列相關(guān)的衣服。
CB的基本實(shí)現(xiàn)原理
(1)提取商品特征
這個(gè)可以根據(jù)商品的一些數(shù)據(jù),比如類目、屬性、品牌、標(biāo)題、標(biāo)簽、商品組合、評(píng)分等因子進(jìn)行提取。
(2)計(jì)算用戶喜歡的特征
根據(jù)用戶以前的喜歡的和不喜歡商品的特征進(jìn)行計(jì)算,得出用戶喜歡的特征。用戶的特征由相關(guān)關(guān)鍵字組成,可以通過TF-IDF模型計(jì)算用戶行為的關(guān)鍵字,從而得出用戶的特征。
(3)相關(guān)商品推薦給用戶
根據(jù)用戶喜歡的特征,去商品庫進(jìn)行選擇,找出相關(guān)性最大的多個(gè)商品進(jìn)行推薦。現(xiàn)在我們提取出了商品的特征,又通過計(jì)算得出了用戶喜歡的特征,那么可以通過余弦相似度計(jì)算出商品間的相似度,做為個(gè)性化推薦的依據(jù)。簡單介紹一下余弦相似度,通過計(jì)算兩個(gè)向量的夾角余弦值來評(píng)估他們的相似度。如圖所示,夾角越小,兩個(gè)向量越相似;夾角越大,兩個(gè)向量越不同。

(4)最后根據(jù)用戶反饋的結(jié)果更新用戶喜歡的特征
用戶的喜好是不斷變化的,今天可能我關(guān)注襯衣,明天我又想看手機(jī),所以系統(tǒng)需要根據(jù)用戶的變化不斷更新用戶的特征。
CB算法的優(yōu)點(diǎn):
- 實(shí)現(xiàn)起來比較簡單,不需要復(fù)雜的算法和計(jì)算,可以很快實(shí)現(xiàn)用戶和商品的相關(guān)性
- 計(jì)算簡單快速
- 結(jié)果可解釋,很容易找到可解釋的相關(guān)特征
CB算法的缺點(diǎn):
- 無法挖掘用戶的潛在興趣
- 分析特征有限,很難充分提取商品相關(guān)性
無法為新用戶產(chǎn)生推薦,在用戶行為較少時(shí)推薦不準(zhǔn)確
2. 基于協(xié)同過濾的推薦
通過基于內(nèi)容的推薦算法只能基本滿足用戶的推薦需求,但是卻做不到真正的千人千面。所以我們需要通過算法模型自動(dòng)發(fā)掘用戶行為數(shù)據(jù),從用戶的行為中推測出用戶的興趣,從而給用戶推薦滿足他們需求的物品。
基于用戶行為分析的算法是個(gè)性化推薦系統(tǒng)的重要算法,這種算法一般被稱為“協(xié)同過濾算法”。協(xié)同過濾算法是指通過用戶行為分析,不斷獲取用戶互動(dòng)信息,在用戶的推薦列表中不斷過濾掉不感興趣或者不匹配的商品,不斷提升推薦效果。
簡單來說,這種算法不單單只是根據(jù)自己的喜好,而且還引入了“鄰居”的喜好來進(jìn)行推薦。這樣的推薦更加充分,而且可以深入挖掘用戶潛在的興趣。
上面說過協(xié)同過濾是基于用戶行為分析,所以需要引入下面的參數(shù)進(jìn)行計(jì)算:
- 用戶標(biāo)識(shí)
- 商品/物品標(biāo)識(shí)
- 用戶行為的種類(包括瀏覽,點(diǎn)贊,收藏,加入購物車,下單等)
- 用戶行為的上下文(包括時(shí)間、地點(diǎn)等)
- 用戶行為的權(quán)重(包括瀏覽時(shí)長,購買頻次等)
- 用戶行為的內(nèi)容(比如評(píng)價(jià)分值,評(píng)論的文本內(nèi)容等)
協(xié)同過濾主要包括兩種:基于用戶的協(xié)同過濾,User-based CF;和基于商品的協(xié)同過濾,Item-based CF。下面我們別對(duì)這兩者進(jìn)行說明。
(1)基于用戶的協(xié)同過濾User-based CF
系統(tǒng)通過分析某用戶和其他用戶的特征值,找出相近的特征用戶,然后根據(jù)特征用戶喜好的商品,從中找到一些商品推薦給該用戶。
以閱讀為例,比如用戶A一直看架構(gòu)方面的書籍,這樣系統(tǒng)可以找到和他有類似興趣的用戶,然后把這些用戶喜歡看的書(同時(shí)這些書用戶A沒有看過的)推薦給用戶A。簡言之就是計(jì)算出兩個(gè)用戶的相似度,然后給A推薦用戶B喜歡的東西。
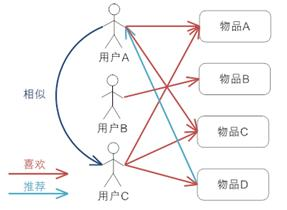
User-based CF基本實(shí)現(xiàn)原理
1)找到和目標(biāo)用戶興趣相似的用戶
先給用戶行為定義分值,比如給瀏覽、收藏、加入購物車、購買、評(píng)分等行為定義分值,然后給各個(gè)行為打分,通過余弦相似度計(jì)算用戶相似度。
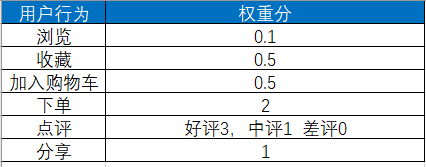
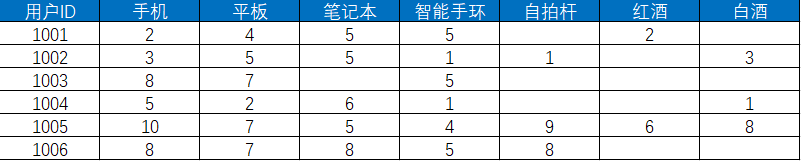
例如,我們有1001,1002,1003,1004,1005,1006這六個(gè)用戶,用戶對(duì)商品的行為包括瀏覽、收藏、下單等。我們需要對(duì)用戶行為賦予不同的權(quán)重分值,比如瀏覽為0.1分,收藏為0.5分,整體的行為分值表如下:
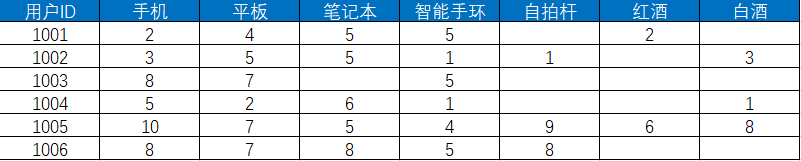
然后我們對(duì)這些用戶在不同商品上的行為進(jìn)行統(tǒng)計(jì),得出下表。下表展示了用戶對(duì)各個(gè)商品的偏好程度的分值,分值越高代表用戶對(duì)商品的感興趣程度越大。
我們可以根據(jù)余弦相似度計(jì)算用戶的相似度。具體公式如下:
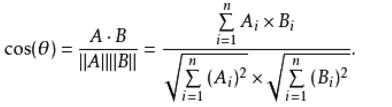
我們現(xiàn)在要計(jì)算 1001 和 1002 兩個(gè)用戶的相似程度,并將數(shù)據(jù)帶入公式中:
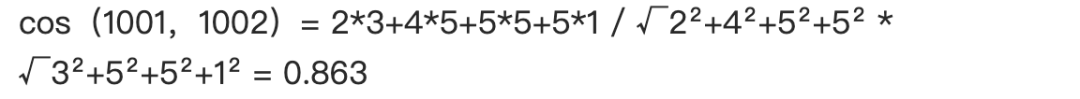
通過計(jì)算我們得出 1001 和 1002 用戶余弦相似值約等于 0.863。相似值的范圍是從 -1 到 1,1 表示用戶之間完全相似,0 表示用戶之間是獨(dú)立的,-1 表示兩個(gè)用戶之間相似度正好相反,在 -1 到 1 之間的值表示其相似和相異。而我們剛剛得出的值是 0.863,表示用戶之間的相似度非常高。同理我們可以計(jì)算出 1001 用戶和其他用戶的相似值。
2)將集合中用戶喜歡的且目標(biāo)用戶沒有聽說過的商品推薦給目標(biāo)用戶
計(jì)算出用戶相似度后,在相似度高的用戶集合中選擇相關(guān)商品,將目標(biāo)用戶沒有瀏覽過的商品推薦給目標(biāo)用戶。
還是上面那個(gè)栗子,我們需要給用戶 1001 推薦沒有瀏覽過的商品,我們計(jì)算出和 1001 相似值較高的用戶集合,假設(shè)我們?cè)O(shè)定一個(gè)閾值 0.85,并把相似值在 0.85 以上的用戶喜好的商品推薦給目標(biāo)用戶,同時(shí)也涉及到推薦排序的問題。
我們根據(jù)以下公式進(jìn)行推薦計(jì)算:
(其中S(u,k)指和用戶 u 興趣最接近的 k 個(gè)用戶集合,N(i)指對(duì)物品 i 有過行為的用戶集合,數(shù)學(xué)符號(hào)∩是取交集,W指用戶U和用戶V的相似度,R表示用戶V對(duì)物品的興趣)
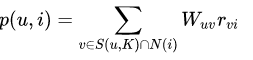
我們需要先計(jì)算出與 1001 相似的用戶,通過計(jì)算得出 1002、1003、1004、1005、1006 用戶的相似值分別是0.863,0.875,0.779,0.812,0.916。我們?nèi)∠嗨浦翟?.85以上的用戶,包括1002,1003,1006。所以可以給用戶1001推薦自拍桿和白酒兩種商品,1001 推薦列表不包括這兩種商品。我們可以通過上面的公式來計(jì)算用戶對(duì)這兩種商品的感興趣程度然后再進(jìn)行排序。
- 自拍桿=0.863*1+0.916*8=8.191
- 白 酒 =0.863*3=2.589
這樣我們可以將自拍桿和白酒排序,推薦給用戶 1001 時(shí),會(huì)將自拍桿排在白酒的前面。
(2)基于商品的協(xié)同過濾Item-based CF
這種算法是亞馬遜最先提出來的,系統(tǒng)通過分析用戶標(biāo)簽數(shù)據(jù)和行為數(shù)據(jù),判斷出用戶喜好商品的類型,然后挑選一些類似的商品推薦給這些喜歡共同類型商品的用戶。
比如,該算法會(huì)因?yàn)槟阗徺I過“佛珠手串”而給你推薦“茶具”和“檀香”。該算法是目前在電商領(lǐng)域使用較多的算法。很多朋友會(huì)覺得item CF算法和基于內(nèi)容的推薦算法很類似,實(shí)際上 CF 算法并不基于商品的屬性和類目來計(jì)算相似度,他主要通過分析用戶行為來記錄內(nèi)容之間的相關(guān)性。所以算法不會(huì)計(jì)算 佛珠手串和茶具,檀香的相似度,而是喜歡佛珠手串的用戶也喜歡茶具和檀香,系統(tǒng)就判斷手串和茶具、檀香之間有相關(guān)性。
Item-based CF基本實(shí)現(xiàn)原理
1)計(jì)算內(nèi)容之間的相似度
計(jì)算商品間的相似度同樣會(huì)用到余弦相似度。兩個(gè)商品產(chǎn)生相似關(guān)系,是因?yàn)樗麄児餐缓芏嘤脩粝矚g,商品相似度越高,說明這兩個(gè)商品都被很多用戶所喜歡。
這里同樣用到了余弦相似度,但是公式略有不同,其中,|N(i)| 是喜歡商品i的用戶集合,|N(j)|是喜歡商品j的用戶集合,|N(i)∩N(j)| 是同時(shí)喜歡商品i和商品j的用戶交集。
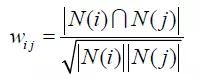
舉例說明,首先我們假定有3個(gè)用戶,分別為A、B、C,用戶A購買了A,C兩個(gè)商品,用戶B購買了A,B,C三個(gè)商品,用戶C只買了商品A。
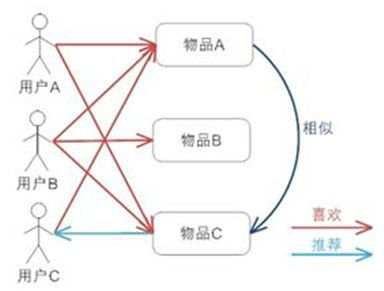
- 商品A:用戶A 用戶B 用戶C
- 商品B:用戶B
- 商品C:用戶A 用戶B
根據(jù)上面公式進(jìn)行計(jì)算,我們先進(jìn)行商品A、商品B、商品C之間的相似度計(jì)算

從以上的結(jié)果可以看出,商品A和商品C相似度最高,所以在需要推薦的場景下,系統(tǒng)會(huì)優(yōu)先把商品C推薦給用戶C。
2)根據(jù)用戶的偏好,給用戶生成推薦列表。
計(jì)算完商品相似度,我們需要把商品推薦給用戶。如果用戶近期有多個(gè)行為記錄,我們先計(jì)算每條行為記錄的相似值,然后可以得出多個(gè)推薦列表,我們需要將這些列表做相似值的去重和排序,需要注意的是如果重復(fù)記錄在單個(gè)推薦列表相似值不高,但是多條推薦列表都有涉及到,這時(shí)我們需要提升其權(quán)重。然后根據(jù)相似值進(jìn)行排序展示。
3. 其他推薦算法
除此之外,還有一些其他的推薦算法。比如基于知識(shí)的推薦,以及基于人口統(tǒng)計(jì)學(xué)的推薦。由于篇幅原因,在這里不詳細(xì)介紹了。
全文完,感謝閱讀。
作者簡介:曾任職于阿里巴巴,每日優(yōu)鮮等互聯(lián)網(wǎng)公司,任技術(shù)總監(jiān),15年電商互聯(lián)網(wǎng)經(jīng)歷。