













IBM開源了5億行代碼數據集,里面最多的編程語言卻不是Python
谷歌服務包含 20 億行代碼,一輛汽車的系統包含 1 億行代碼——寫代碼、debug 這么大的工作量不交給 AI 來做能行?
讓 AI 自動生成代碼,是很多開發者的夢想,近些年來,有關這一方面的研究屢見不鮮。但要想訓練一個好用的 AI,最重要的工作或許就是找到優質數據。
近日,IBM 研究院發布了一個名為 CodeNet 的數據集,該數據集包含 1400 萬個代碼樣本,用于訓練面向編程任務的機器學習模型。該數據集的主要特點包括:
- 迄今為止最大的編碼數據集,其中包含 4000 個問題,1400 萬個代碼樣本,50 + 種編程語言;
- 該數據集添加了注釋,包括問題描述、內存 / 時間限制、語言、代碼通過 / error 等。
IBM 希望 CodeNet 仿效大型圖像數據集 ImageNet,并成為教軟件理解軟件開發藍圖的領先數據集。IBM 希望 CodeNet 可以用于訓練具有如下功能的開發工具:
- 從一種編程語言轉換到另一種編程語言;
- 代碼推薦與補全;
- 代碼優化;
- 搜索應用程序和庫來源以查找所需例程;
- 將一種語言轉換成另一種語言;
- 識別錯誤 / 正確的實現機制。
利用深度學習進行自動化編程
近年來,機器學習領域取得了令人矚目的進步,AI 讓多種工作任務實現了自動化,包括編程。但是 AI 在軟件開發中的滲透卻遇到了極大的困難。
人們在編程時通常會使用大量的有意識和潛意識思維機制發現新的問題并探索不同的解決方案。相比之下,大多數機器學習算法都需要定義明確的問題和大量帶有注釋的數據才能夠開發出解決相同編程問題的模型。
為了解決這一難題,研究者與開發者們已經做出了很多努力,包括創建數據集和基準,以開發和評估「用于編程的 AI」系統。但是,鑒于軟件開發的創造性和開放性,很難為編程創建完美的數據集。
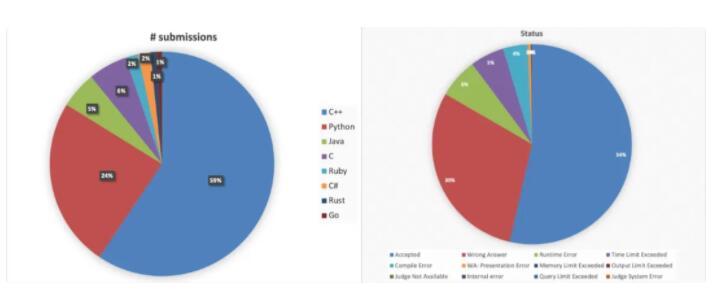
IBM 的研究人員試圖創建一個多用途的數據集,可用于訓練各種任務的機器學習模型。CodeNet 的創建者將其描述為「非常大規模,多樣且高質量的數據集,能夠加快使用 AI 編程的步伐」。該數據集包含 1400 萬個代碼樣本,共有用 55 種編程語言編寫的 5 億行代碼,其中 C++ 是樣本中使用最多的語言,Python 位居第二。這些代碼樣本是從提交給在線編程平臺 AIZU 和 AtCoder 上的近 4,000 項挑戰的提交中獲得的,代碼樣本包括這些挑戰的正確答案和錯誤答案。
CodeNet 項目地址:https://github.com/IBM/Project_CodeNet
CodeNet 的主要特點之一是代碼樣本中添加了注釋。數據集中包含的每個編程挑戰都有一個文本說明以及 CPU 時間和內存限制。每個代碼提交都包含十幾條信息,包括語言,提交日期,內存占用大小,執行時間,接受和 error 類型。為了確保該數據集在編程語言,接受和 error 類型等多個維度上保持平衡,IBM 的研究人員付出了巨大的努力。
機器學習編程任務
CodeNet 并不是訓練機器學習模型來執行編程任務的唯一數據集。相比于其他數據集,CodeNet 具有以下特點:首先是數據集的規模,包括樣本數量和語言的多樣性;但更重要的是編碼樣本附帶的元數據。CodeNet 中添加的豐富注釋使其能夠適用于多種任務,不再只是用于特定編程任務。
使用 CodeNet 開發用于編程任務的機器學習模型包括以下方式:
- CodeNet 可以用來進行語言翻譯任務。由于數據集中包含的每個編程挑戰都包含不同編程語言的提交,因此數據科學家們可以用它來創建機器學習模型,將代碼從一種語言轉換成另一種語言。對于希望將舊代碼移植成新語言、使新一代程序員能夠訪問并使用新型開發工具進行維護的人們而言,這可能很方便;
- CodeNet 還可以用來開發完成代碼推薦任務的機器學習模型開發。推薦工具既可以像完成當前代碼行的自動完成樣式模型一樣簡單,也可以是編寫完整函數或代碼塊的更復雜系統。
由于 CodeNet 擁有大量關于內存和執行時間指標的元數據,數據科學家也可以使用它來開發代碼優化系統。或者,可以使用 error 類型的元數據來訓練機器學習系統,以標記源代碼中的潛在缺陷。
CodeNet 更高級的用例是代碼生成。CodeNet 是一個豐富的問題文本描述庫,并包含對應的源代碼。已經有開發人員使用高級語言模型(如 GPT-3)從自然語言描述生成代碼,CodeNet 或許能夠幫助微調這些語言模型,使其在代碼生成中更加一致。
IBM 的研究人員已經對 CodeNet 進行了一些實驗,這些實驗包括代碼分類、代碼相似性評估和代碼補全。使用的深度學習體系架構包括簡單的多層感知器、卷積神經網絡、圖神經網絡、Transformer。
IBM 和 MIT-IBM Watson AI 實驗室團隊聯合開發了該數據集,研究中的實驗結果顯示大多數任務都能獲得90%以上的準確率。

論文地址:https://github.com/IBM/Project_CodeNet/blob/main/ProjectCodeNet.pdf
建立高效的機器學習系統,需付出巨大努力
IBM 的工程師們進行了大量的工作來管理 CodeNet 數據集并開發其輔助工具。
首先,研究團隊需要從 AIZU 和 AtCoder 收集代碼樣本。二者中只有一個平臺有應用程序接口(API),可以很容易地獲取代碼,而另一個平臺沒有易于訪問的接口,研究團隊需要開發新工具,從平臺的網頁上抓取數據,并將其分解成表格格式。然后研究者們需要手動將兩個數據集合并到一個統一的模式中。
接下來,研究團隊需要開發用于識別和刪除重復代碼和樣本(包含大量無效代碼,運行時未執行的源代碼)的工具,以清除無用數據。
此外,該研究團隊還開發了預處理工具,使得在 CodeNet 語料庫上訓練機器學習模型變得更容易,包括用于不同編程語言的 tokenizer、分析樹(parse tree)和用于圖神經網絡的圖表征生成器。
所有這些都提醒我們,要創建高效的機器學習系統,需要付出巨大的努力。人工智能要取代程序員還有很長的路要走。
【責任編輯:張燕妮 TEL:(010)68476606】





















