













企業級機器學習 會成為下一個萬億級的新市場嗎?
科技云報道原創。
在哈利·波特的魔法世界中,分院帽是一頂磨得很舊,打著補丁,而且臟得要命的尖頂巫師。不過可別小看它,它可是充滿智能、會思想的魔法帽,能看出學生具備何種才能,從而將學生分到適合的學院。
如果現實世界存在分院帽的話,那么它應該類似于機器學習的應用程序,可以根據復雜的數據集自主地做出決策。
如今,機器學習正在推動數萬億規模的全球產業,市場調查機構Grand View Research最近發布的《機器學習市場報告2025》預計,到2025年,全球機器學習市場規模將達到967億美元。2019年-2025年的年復合增長率為43.8%,其中金融服務,零售和汽車領域處于領先地位。如果機器學習有望創造更大規模的市場價值,那么問題來了:這些價值將在哪里產生呢?
從初創公司到科技巨頭 機器學習深度嵌入垂直場景
早在50年前,機器學習的概念就出現了。只是直到今天,隨著云計算的出現,人工智能和機器學習才進入千千萬萬的企業,不再局限于少數科技巨頭和硬核的研究機構。云計算時代的到來,掃清了企業應用人工智能和機器學習的障礙,而即便最保守的企業在當今都無法忽視人工智能的作用。根據IDC的數據,當前40%的企業數字化轉型項目都會運用人工智能。
Facebook、Amazon、Apple、Netflix、Google等科技巨頭在機器學習方面的創新廣為人知,從新聞推送到推薦引擎不一而足。其實,這些科技巨頭在機器學習領域早已布局。比如Amazon就在這個領域已經投入了20多年,其在線零售的個性化產品推薦、機器人倉儲中心、無人機送貨、Alexa語音助理、Amazon GO無人值守超市,都依靠人工智能和機器學習技術的支持。
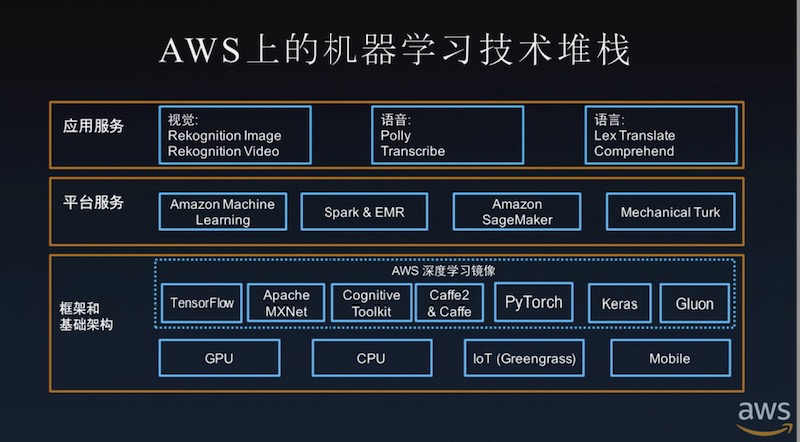
但就更多場景而言,人工智能的應用仍然較為局限。目前,制約人工智能廣泛應用的因素有三個方面:一是掌握人工智能專業知識的人才不足;二是構建和擴展人工智能的技術產品有難度;三是在生產經營中部署人工智能應用費時且成本高。最終導致缺乏低成本、易使用、可擴展的人工智能產品和服務。就機器學習而言,多數機器學習方法的性能在很大程度上依賴于過量的模型設計策略,這導致新手難以較快地掌握和應用機器學習。
對此,Amazon SageMaker的出現幫助企業解決了這些挑戰。作為一個工具集,Amazon SageMaker提供了用于機器學習的所有組件,比如彈性筆記本、實驗管理、自動模型創建、調試與分析,以及模型概念漂移檢測等多元化工具和功能,貫穿整個機器學習的工作流程,從而以更少的努力、更低的成本、更快地將機器學習模型投入生產。
2021年5月11日,Amazon SageMaker以落地中國區域一周年為契機,進一步在中國區域落地多項人工智能與機器學習的新服務和功能,“希望通過將更多服務落地到中國區域,并堅持‘授人以魚不如授人以漁’,甚至更進一步‘扶上馬,送一程’的方式,幫助客戶更快應用機器學習技術,把機器學習的能力交到每一位構建者手中,加速人工智能和機器學習的普惠。”亞馬遜云科技大中華區云服務產品管理總經理顧凡表示。
亞馬遜云科技大中華區云服務產品管理總經理顧凡
除了科技巨頭,全球一些初創型的公司也都在將機器學習與垂直領域相結合,最好的機器學習公司都有著清晰的垂直重點。他們甚至不會將自己定義為機器學習公司。比如在工業和物流領域,Covariant是一家結合了強化學習和神經網絡的初創公司,該公司讓機器人能夠管理大型倉庫設施中的物體;Interos應用機器學習技術評估全球供應鏈網絡,幫助企業圍繞供應商管理、業務連續性和風險做出關鍵決策。
在醫療領域,Athelas已將機器學習應用于免疫監測,通過收集病人白血球數量的數據幫助他們優化藥物攝入。Curai利用機器學習技術來提高醫生推薦的效率和質量,讓他們可以把更多的時間花在治療患者的工作上。Zebra和AIdoc通過訓練數據集來更快地確定醫療狀況,從而提高了放射科醫生的工作能力。
然而,大規模部署機器學習模型也可能為企業帶來諸多挑戰。例如,規模化的部署需要實現“數據-模型-成果”這一復雜且反復的端到端工作流程。而且,企業也需要提高自身治理能力,合理應對模型部署可能帶給終端客戶服務的影響(如隱私問題),并著眼于數據應用的合規性和安全性,以及該模型是否能轉化成為生產級模型等。
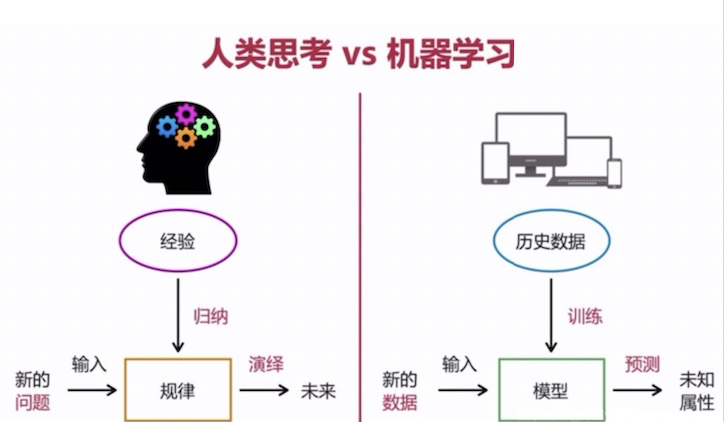
前途光明但道路曲折 機器學習模型仍面臨四大挑戰
據國外知名科技媒體VentureBeat報道,大約90%的機器學習模型從未投入生產。換句話說,機器學習只有10%能夠真正產出對公司有用的東西。盡管大家都相信,人工智能將成為下一次科技革命的中心,但人工智能的采用和部署尚未獲得長足的發展。目前來看,機器學習要想大規模應用仍然還面臨比較大的挑戰。
挑戰一:數據獲取和訪問難度大
許多公司的IT系統都是高度筒倉化的,這意味著每個部門都有自己收集數據的方式、首選格式、存儲位置以及安全和隱私偏好。另一方面,機器學習經常需要來自多個部門的數據,筒倉化模式增加了清理和處理這些數據的難度。但在今天這個技術飛速變革的時代,企業將需要加快步伐,在整個過程中建立起統一的數據結構。
挑戰二:IT、數據科學和工程脫節
如果公司的目標是減少“數據筒倉”,就意味著各部門需要更多地相互溝通,調整各自的目標。但在許多公司中,IT部門和數據部門之間存在著根本性的分歧。IT傾向于優先考慮讓事情正常運轉并保持穩定,而數據專家則更喜歡進行一些嘗試性創造,這就會導致一些不穩定情況發生,使雙方的溝通產生困難。此外,對于數據專家來說,與IT工程師的溝通也是一道障礙,因為IT工程師有時候可能無法了解數據專家所設想的所有細節,或者可能會由于溝通錯誤而改變實現方式。
挑戰三:重復性工作多 應用擴展較難
機器學習模型可能在小規模數據樣本的環境中工作得很好,但這并不意味著它在任何地方都可以工作得很好。首先,可能沒有處理更大數據集的硬件或云存儲空間可供使用。此外,在規模很大時,機器學習模型的模塊并不總是像規模較小時那么有效。另外,由于公司的筒倉結構,數據獲取可能也比較困難,這也是在組織之間統一數據結構、鼓勵不同部門之間進行交流的另一個原因。
在部署機器學習模型的漫長道路上,超過25%的企業都存在重復工作。例如,軟件工程師可能會按數據專家的說法進行實現,后者可能也會自己做一些工作。這不僅浪費時間和資源,而且在遇到任何錯誤時就不知道應該向誰求助,這會導致額外的混亂。如果數據專家能夠實現他們的模型,但對于職責如何劃分、如何明確分工,他們應該與IT工程師溝通清楚,這樣就可以節省時間和資源。
挑戰四:不能跨語言且缺少框架支持
由于機器學習模型仍處于起步階段,不同的語言和框架仍有相當大的差距。有些模型開始時使用的是Python語言開始,中間切換到R語言,最后用的是Julia語言。有的則相反,或者完全使用其他語言。由于每種語言都有自己獨特的庫和依賴項,項目很快就變得很難跟蹤。此外,有些模型可能會使用Docker和Kubernetes進行容器化,并部署特定的API,其他模型則不會,這樣的例子不勝枚舉。為了彌補這種不足,像TFX、Mlflow和Kubeflow這樣的工具出現了。但這些工具仍處于起步階段,但到目前為止,這方面的專業人才還很少。
事實上,模仿人類的思維并不是機器學習的唯一目標,相反機器學習可以通過對大型數據集進行詳盡的分析來提高人類的智能水平,就像搜索引擎能夠通過組織Web來擴展人類的知識一樣。機器學習還可以匯總多個數據集的信息,探索模式,并為一些問題提出新的解決方案,從而在醫療、商業、交通等多個領域為人類提供新型服務。
機器學習技術必將推動企業機構的變革,目前許多機器學習應用已經為企業機構帶來了實際的業務成果。機器學習可以實現流程自動化、發現新洞察,從而幫助企業創造新產品或增強現有產品及服務,從而提供更好的客戶體驗。
但企業機構要想真正將機器學習應用到實際業務場景之中,還需完成全方位運營轉型,具備建立和開發機器學習模型以及部署和運營整個模型的能力,從而全方位發掘機器學習的潛力。目前為止,大型企業孵化了最先進的技術,但是真正的希望存在于下一波機器學習應用程序和工具之中,將圍繞機器智能將哈利·波特式的幻想轉化為有形的社會價值。
【關于科技云報道】
專注于原創的企業級內容行家——科技云報道。成立于2015年,是前沿企業級IT領域Top10媒體。獲工信部權威認可,可信云、全球云計算大會官方指定傳播媒體之一。深入原創報道云計算、大數據、人工智能、區塊鏈等領域。












