













千億數據扛不住,三思后還是從MySQL遷走了……
前言
線上某IOT核心業務集群之前采用MySQL作為主存儲數據庫,隨著業務規模的不斷增加,MySQL已無法滿足海量數據存儲需求,業務面臨著容量痛點、成本痛點問題、數據不均衡問題等。
400億該業務遷移MongoDB后,同樣的數據節省了極大的內存、CPU、磁盤成本,同時完美解決了容量痛點、數據不均衡痛點,并且實現了一定的性能提升。
此外,遷移時候的MySQL數據為400億,3個月后的現在對應MongoDB集群數據已增長到1000億,如果以1000億數據規模等比例計算成本,實際成本節省比例會更高。遷移MongoDB后,除了解決業務痛點問題,同時也促進了業務的快速迭代開發,業務不在關心數據庫容量痛點、數據不均衡痛點、成本痛點等問題。
當前國內很多mongod文檔資料、性能數據等還停留在早期的MMAP_V1存儲引擎,實際上從MongoDB-3.x版本開始,MongoDB默認存儲引擎已經采用高性能、高壓縮比、更小鎖粒度的wiredtiger存儲引擎,因此其性能、成本等優勢相比之前的MMAP_V1存儲引擎更加明顯。
一、業務遷移背景
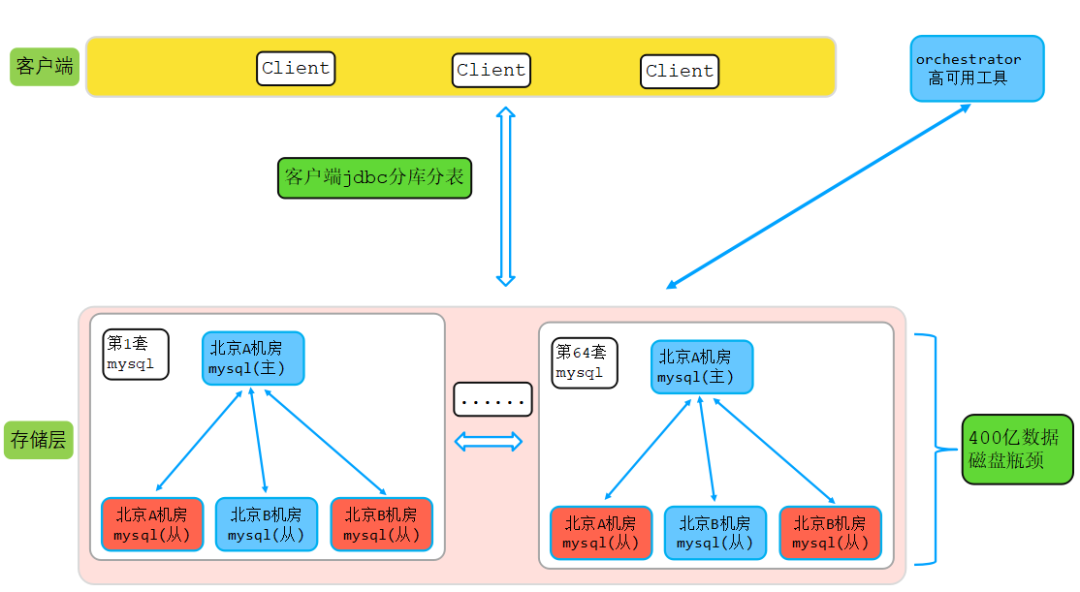
該業務在遷移MongoDB前已有約400億數據,申請了64套MySQL集群,由業務通過shardingjdbc做分庫分表,提前拆分為64個庫,每個庫100張表。主從高可用選舉通過依賴開源orchestrator組建,MySQL架構圖如下圖所示:
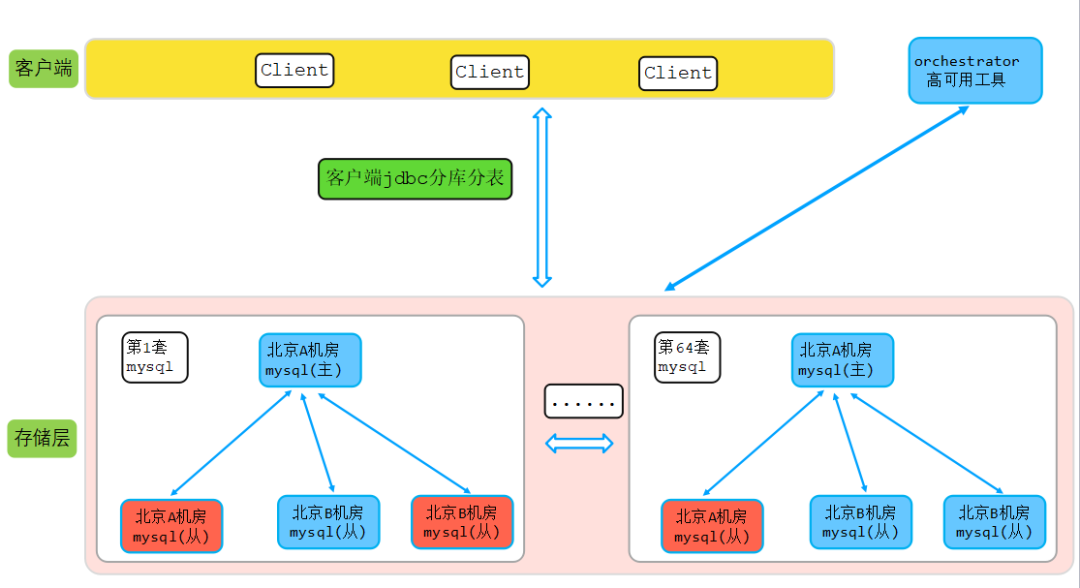
說明:上圖中紅色代表磁盤告警,磁盤使用水位即將100%。如上圖所示,業務一年多前一次性申請了64套MySQL集群,單個集群節點數一主三從,每個節點規格如下:
- cpu:4
- mem:16G
- 磁盤:500G
- 總節點數:64*4=256
- SSD服務器
該業務運行一年多時間后,總集群數據量達到了400億,并以每月200億速度增長,由于數據不均衡等原因,造成部分集群數據量大,持續性耗光磁盤問題。由于節點眾多,越來越多的集群節點磁盤突破瓶頸,為了解決磁盤瓶頸,DBA不停的提升節點磁盤容量。業務和DBA都面臨嚴重痛點,主要如下:
- 數據不均衡問題
- 節點容量問題
- 成本持續性增加
DBA工作量劇增(部分磁盤提升不了需要遷移數據到新節點),業務也提心吊膽
二、為何選擇MongoDB-附十大核心優勢總結
業務遇到瓶頸后,基于MongoDB在公司已有的影響力,業務開始調研MongoDB,通過和業務接觸了解到,業務使用場景都是普通的增、刪、改、查、排序等操作,同時查詢條件都比較固定,用MongoDB完全沒任何問題。
此外,MongoDB相比傳統開源數據庫擁有如下核心優索:
優勢一:模式自由
MongoDB為schema-free結構,數據格式沒有嚴格限制。業務數據結構比較固定,該功能業務不用,但是并不影響業務使用MongoDB存儲結構化的數據。
優勢二:天然高可用支持
MySQL高可用依賴第三方組件來實現高可用,MongoDB副本集內部多副本通過raft協議天然支持高可用,相比MySQL減少了對第三方組件的依賴。
優勢三:分布式-解決分庫分表及海量數據存儲痛點
MongoDB是分布式數據庫,完美解決MySQL分庫分表及海量數據存儲痛點,業務無需在使用數據庫前評估需要提前拆多少個庫多少個表,MongoDB對業務來說就是一個無限大的表(當前我司最大的表存儲數千億數據,查詢性能無任何影響)。
此外,業務在早期的時候一般數據都比較少,可以只申請一個分片MongoDB集群。而如果采用MySQL,就和本次遷移的IOT業務一樣,需要提前申請最大容量的集群,早期數據量少的時候嚴重浪費資源。
優勢四:完善的數據均衡機制、不同分片策略、多種片建類型支持
- 關于balance:支持自動balance、手動balance、時間段任意配置balance.
- 關于分片策略:支持范圍分片、hash分片,同時支持預分片。
- 關于片建類型:支持單自動片建、多字段片建
優勢五:不同等級的數據一致性及安全性保證
MongoDB在設計上根據不同一致性等級需求,支持不同類型的Read Concern 、Write Concern讀寫相關配置,客戶端可以根據實際情況設置。此外,MongoDB內核設計擁有完善的rollback機制來保證數據安全性和一致性。
優勢六:高并發、高性能
為了適應大規模高并發業務讀寫,MongoDB在線程模型設計、并發控制、高性能存儲引擎等方面做了很多細致化優化。
優勢七:wiredtiger高性能存儲引擎設計
網上很多評論還停留在早期MMAPv1存儲引擎,相比MMAPv1,wiredtiger引擎性能更好,壓縮比更高,鎖粒度更小,具體如下:
- WiredTiger提供了低延遲和高吞吐量
- 處理比內存大得多的數據,而不會降低性能或資源
- 系統故障后可快速恢復到最近一個checkpoint
- 支持PB級數據存儲
- 多線程架構,盡力利用樂觀鎖并發控制算法減少鎖操作
- 具有hot-caches能力
- 磁盤IO最大化利用,提升磁盤IO能力
- 其他
優勢八:成本節省-WT引擎高壓縮比支持
- MongoDB對數據的壓縮支持snappy、zlib算法,在以往線上真實的數據空間大小與真實磁盤空間消耗進行對比,可以得出以下結論:
- MongoDB默認的snappy壓縮算法壓縮比約為2.2-4.5倍
zlib壓縮算法壓縮比約為4.5-7.5倍(本次遷移采用zlib高壓縮算法)

此外,以線上已有的從MySQL、Es遷移到MongoDB的真實業務磁盤消耗統計對比,同樣的數據,存儲在MongoDB、MySQL、Es的磁盤占比≈1:3.5:6。
后續會有數千億hbase數據遷移MongoDB,到時候總結同樣數據MongoDB和Hbase的磁盤消耗比。
優勢九:天然N機房(不管同城還是異地)多活容災支持
MongoDB天然高可用機制及代理標簽自動識別轉發功能的支持,可以通過節點不同機房部署來滿足同城和異地N機房多活容災需求,從而實現成本、性能、一致性的“三豐收”。更多機房多活容災的案例詳見Qcon分享:
優勢十:完善的客戶端均衡訪問策略
MongoDB客戶端訪問路由策略由客戶端自己指定,該功能通過Read Preference實現,支持primary 、primaryPreferred 、secondary 、secondaryPreferred 、nearest 五種客戶端均衡訪問策略。
分布式事務支持
MongoDB-4.2 版本開始已經支持分布式事務功能,當前對外文檔版本已經迭代到 version-4.2.11,分布式事務功能也進一步增強。此外,從 MongoDB-4.4 版本產品規劃路線圖可以看出,MongoDB 官方將會持續投入開發查詢能力和易用性增強功能,例如 union 多表聯合查詢、索引隱藏等。
三、MongoDB資源評估及部署架構
業務開始遷移MongoDB的時候,通過和業務對接梳理,該集群規模及業務需求總結如下:
- 已有數據量400億左右
- 數據磁盤消耗總和30T左右
- 讀寫峰值流量4-5W/s左右,流量很小
- 同城兩機房多活容災
- 讀寫分離
- 每月預計增加200億數據
- 滿足幾個月內1500億新增數據需求
說明:數據規模和磁盤消耗按照單副本計算,例如MySQL 64個分片,256個副本,數據規模和磁盤消耗計算方式為:64個主節點數據量之和、64個分片主節點磁盤消耗之和。
1、MongoDB資源評估
分片數及存儲節點套餐規格選定評估過程如下:
內存評估
我司都是容器化部署,以往經驗來看,MongoDB對內存消耗不高,歷史百億級以上MongoDB集群單個容器最大內存基本上都是64Gb,因此內存規格確定為64G。
分片評估
業務流量峰值3-5W/s,考慮到可能后期有更大峰值流量,因此按照峰值10W/s寫,5w/s讀,也就是峰值15W/s評估,預計需要4個分片。
磁盤評估
MySQL中已有數據400億,磁盤消耗30T。按照以網線上遷移經驗,MongoDB默認配置磁盤消耗約為mysql的1/3-1/5,400億數據對應MongoDB磁盤消耗預計8T。考慮到1500億數據,預計4個分片,按照每個分片400億規模,預計每個分片磁盤消耗8T。
線上單臺物理機10多T磁盤,幾百G內存,幾十個CPU,為了最大化利用服務器資源,我們需要預留一部分磁盤給其他容器使用。另外,因為容器組套餐化限制,最終確定確定單個節點磁盤在7T。預計7T節點,4個分片存儲約1500億數據。
CPU規格評估
由于容器調度套餐化限制,因此CPU只能限定為16CPU(實際上用不了這么多CPU)。
mongos代理及config server規格評估
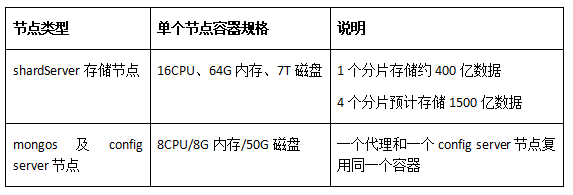
此外,由于分片集群還有mongos代理和config server復制集,因此還需要評估mongos代理和config server節點規格。由于config server只主要存儲路由相關元數據,因此對磁盤、CUP、MEM消耗都很低;mongos代理只做路由轉發只消耗CPU,因此對內存和磁盤消耗都不高。最終,為了最大化節省成本,我們決定讓一個代理和一個config server復用同一個容器,容器規格如下:
- 8CPU/8G內存/50G磁盤,一個代理和一個config server節點復用同一個容器。
- 分片及存儲節點規格總結:4分片/16CPU、64G內存、7T磁盤。
- mongos及config server規格總結:8CPU/8G內存/50G磁盤
2、集群部署架構
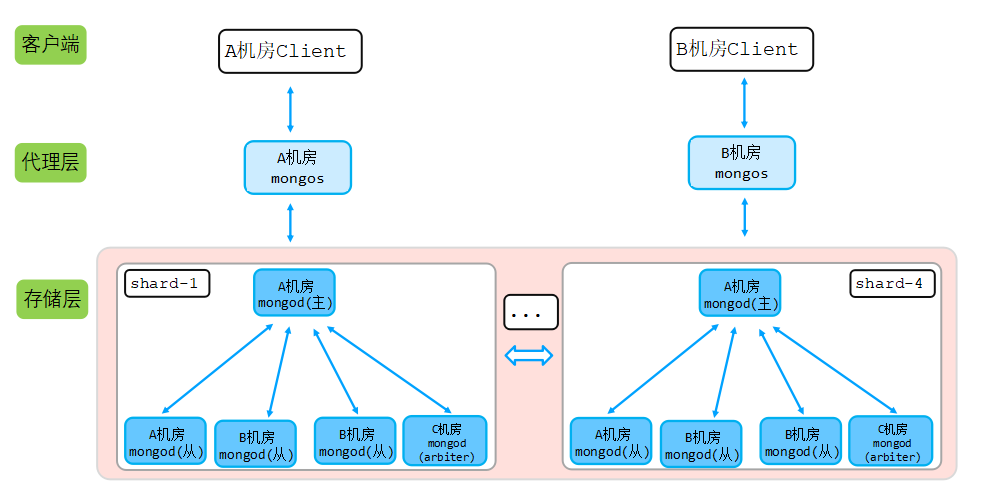
由于該業務所在城市只有兩個機房,因此我們采用2+2+1(2mongod+2mongod+1arbiter模式),在A機房部署2個mongod節點,B機房部署2個mongod節點,C機房部署一個最低規格的選舉節點,如下圖所示:
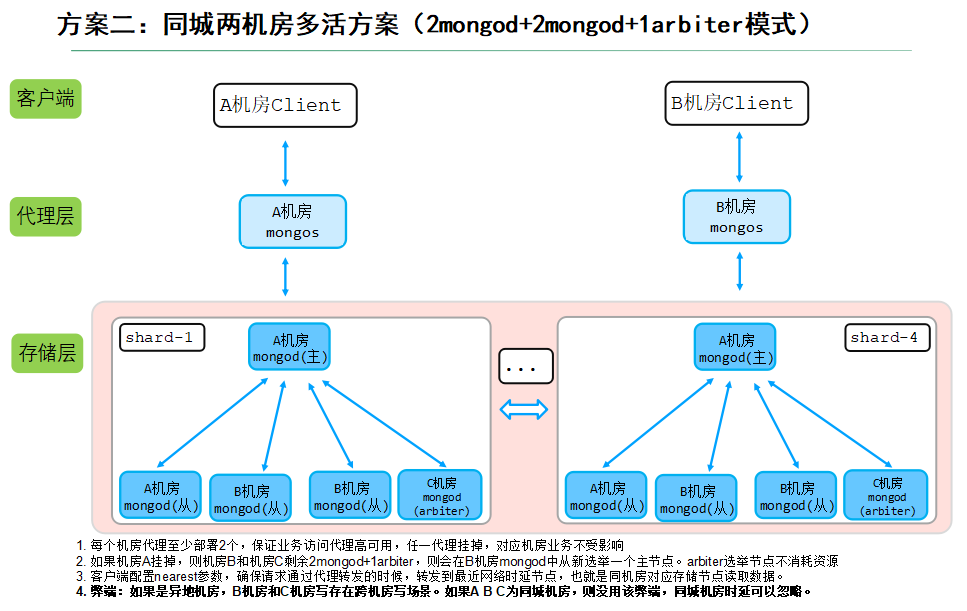
說明:
- 每個機房代理部署2個mongos代理,保證業務訪問代理高可用,任一代理掛掉,對應機房業務不受影響;
- 如果機房A掛掉,則機房B和機房C剩余2mongod+1arbiter,則會在B機房mongod中從新選舉一個主節點。arbiter選舉節點不消耗資源;
- 客戶端配置nearest ,實現就近讀,確保請求通過代理轉發的時候,轉發到最近網絡時延節點,也就是同機房對應存儲節點讀取數據;
- 弊端:如果是異地機房,B機房和C機房寫存在跨機房寫場景。如果A B C為同城機房,則沒用該弊端,同城機房時延可以忽略。
四、業務全量+增量遷移方式
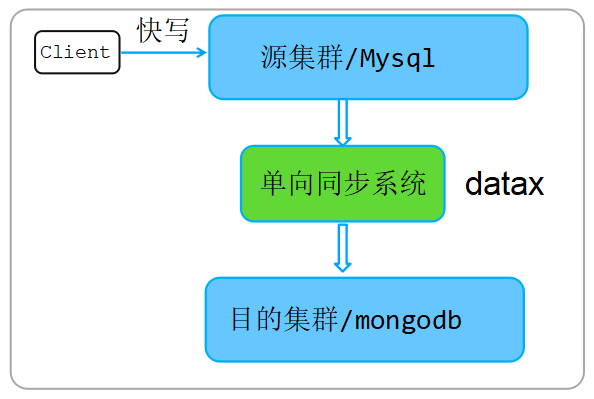
遷移過程由業務自己完成,通過阿里開源的datax工具實現,該遷移工具的更多細節可以參考:https://github.com/alibaba/DataX
五、性能優化過程
該集群優化過程按照如下兩個步驟優化:數據遷移開始前的提前預優化、遷移過程中瓶頸分析及優化、遷移完成后性能優化。
1、數據遷移開始前的提前預操作
和業務溝通確定,業務每條數據都攜帶有一個設備標識ssoid,同時業務查詢更新等都是根據ssoid維度查詢該設備下面的單條或者一批數據,因此片建選擇ssoid。
分片方式
為了充分散列數據到4個分片,因此選擇hash分片方式,這樣數據可以最大化散列,同時可以滿足同一個ssoid數據落到同一個分片,保證查詢效率。
預分片
MongoDB如果分片片建為hashed分片,則可以提前做預分片,這樣就可以保證數據寫進來的時候比較均衡的寫入多個分片。預分片的好處可以規避非預分片情況下的chunk遷移問題,最大化提升寫入性能。
- sh.shardCollection("xxx.xxx", {ssoid:"hashed"}, false, { numInitialChunks: 8192} )
注意事項:切記提前對ssoid創建hashed索引,否則對后續分片擴容有影響。
就近讀
客戶端增加nearest 配置,從離自己最近的節點讀,保證了讀的性能。
mongos代理配置
A機房業務只配置A機房的代理,B機房業務只配置B機房代理,同時帶上nearest配置,最大化的實現本機房就近讀,同時避免客戶端跨機房訪問代理。
禁用enableMajorityReadConcern
禁用該功能后ReadConcern majority將會報錯,ReadConcern majority功能注意是避免臟讀,和業務溝通業務沒該需求,因此可以直接關閉。
存儲引擎cacheSize規格選擇
單個容器規格:16CPU、64G內存、7T磁盤,考慮到全量遷移過程中對內存壓力,內存碎片等壓力會比較大,為了避免OOM,設置cacheSize=42G。
2、數據全量遷移過程中優化過程
全量數據遷移過程中,遷移速度較塊,內存臟數據較多,當臟數據比例達到一定比例后用戶讀寫請求對應線程將會阻塞,用戶線程也會去淘汰內存中的臟數據page,最終寫性能下降明顯。
wiredtiger存儲引擎cache淘汰策略相關的幾個配置如下:
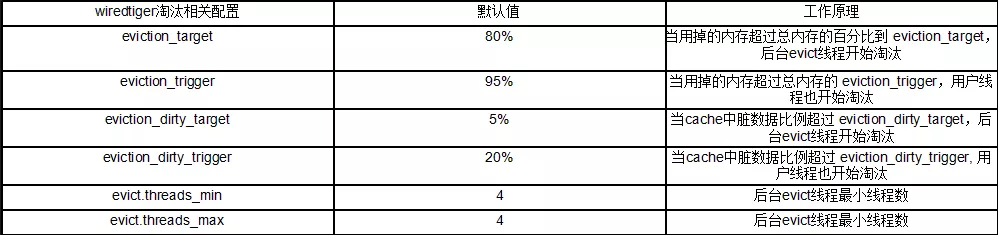
由于業務全量遷移數據是持續性的大流量寫,而不是突發性的大流量寫,因此eviction_target、eviction_trigger、eviction_dirty_target、eviction_dirty_trigger幾個配置用處不大,這幾個參數閥值只是在短時間突發流量情況下調整才有用。
但是,在持續性長時間大流量寫的情況下,我們可以通過提高wiredtiger存儲引擎后臺線程數來解決臟數據比例過高引起的用戶請求阻塞問題,淘汰臟數據的任務最終交由evict模塊后臺線程來完成。
全量大流量持續性寫存儲引擎優化如下:
- db.adminCommand( { setParameter : 1, "wiredTigerEngineRuntimeConfig" : "eviction=(threads_min=4, threads_max=20)"})
3、全量遷移完成后,業務流量讀寫優化
前面章節我們提到,在容器資源評估的時候,我們最終確定選擇單個容器套餐規格為如下:
- 16CPU、64G內存、7T磁盤。
全量遷移過程中為了避免OOM,預留了約1/3內存給MongoDB server層、操作系統開銷等,當全量數據遷移完后,業務寫流量相比全量遷移過程小了很多,峰值讀寫OPS約2-4W/s。
也就是說,前量遷移完成后,cache中臟數據比例幾乎很少,基本上不會達到20%閥值,業務讀流量相比之前多了很多(數據遷移過程中讀流量走原MySQL集群)。為了提升讀性能,因此做了如下性能調整(提前建好索引):
- 節點cacheSize從之前的42G調整到55G,盡量多的緩存熱點數據到內存,供業務讀,最大化提升讀性能;
- 每天凌晨低峰期做一次cache內存加速釋放,避免OOM。
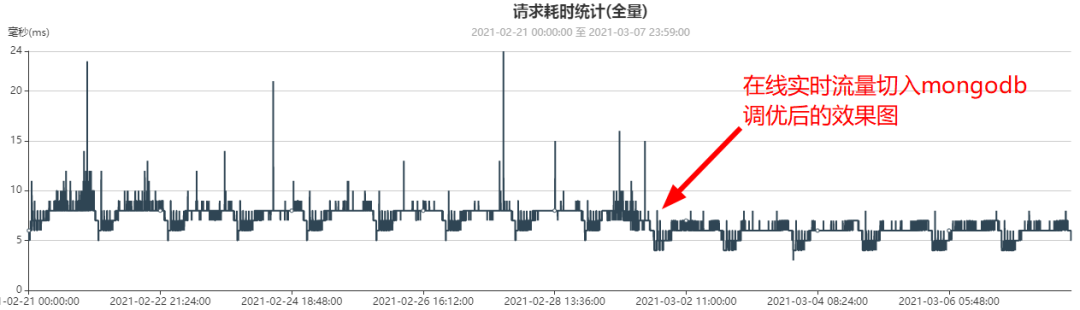
上面的內核優后后,業務測時延監控曲線變化,時延更加平穩,平均時延也有25%左右的性能優后,如下圖所示:
六、遷移前后,業務測時延統計對比(MySQL vs MongoDB)
遷移前業務測時延監控曲線(平均時延7ms, 2月1日數據,此時mysql集群只有300億數據):

遷移MongoDB后并且業務流量全部切到MongoDB后業務測時延監控曲線(平均6ms, 3月6日數據,此時MongoDB集群已有約500億數據)
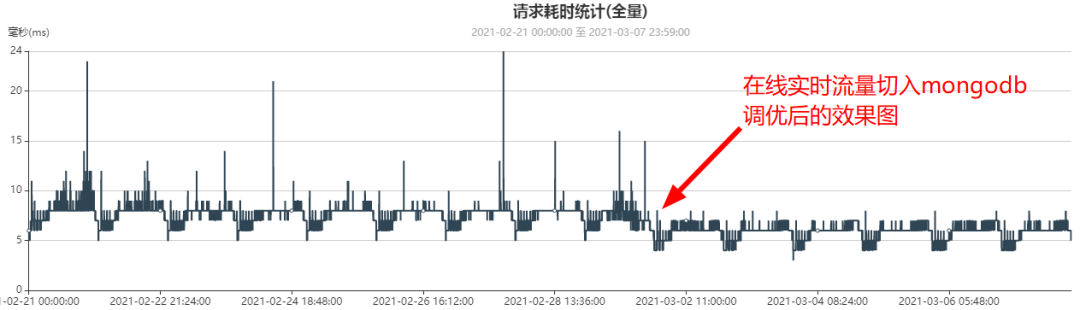
總結:
- MySQL(300億數據)時延:7ms
- MongoDB(500億數據)時延:6ms
七、遷移成本收益對比
1、MySQL集群規格及存儲數據最大量
原mysql集群一共64套,每套集群4副本,每個副本容器規格:4CPU、16G mem、500G磁盤,總共可以存儲400億數據,這時候大部分節點已經開始磁盤90%水位告警,DBA對部分節點做了磁盤容量提升。
總結如下:
- 集群總套數:64
- 單套集群副本數:4
- 每個節點規格:4CPU、16G mem、500G磁盤
- 該64套集群最大存儲數據量:400億
2、MongoDB集群規格及存儲數據最大量
MongoDB從MySQL遷移過來后,數據量已從400億增加到1000億,并以每個月增加200億數據。MongoDB集群規格及存儲數據量總結如下:
- 分片數:4
- 單分片副本數:4
- 每個節點規格:16CPU、64G mem、7T磁盤
- 四個分片存儲數據量:當前已存1000億,最大可存1500億數據。
3、成本對比計算過程
說明:由于MySQL遷移MongoDB后,數據不在往MySQL中寫入,流量切到MongoDB時候MySQL中大約存儲有400億數據,因此我們以這個時間點做為對比時間點。以400億數據為基準,資源消耗對比如下表(每個分片只計算主節點資源消耗,因為MySQL和MongoDB都是4副本):
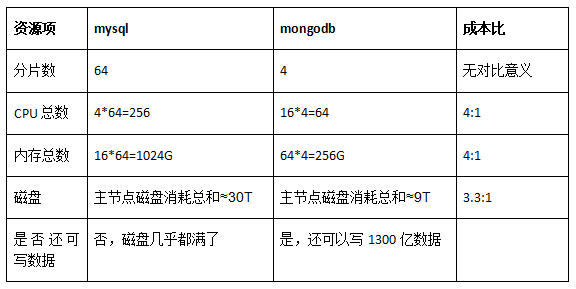
由于MongoDB四個分片還有很多磁盤冗余,該四個分片相比400億數據,還可以寫1100億數據。如果按照1500億數據計算,如果還是按照MySQL之前套餐規格,則MySQL集群數需要再增加三倍,也就是總集群套數需要64*4=256套,資源占用對比如下:
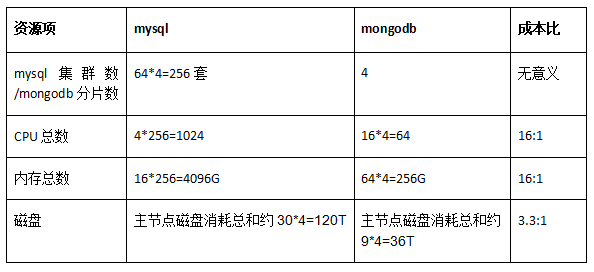
4、收益總結(客觀性對比)
從上面的內容可以看出,該業務遷移MongoDB后,除了解決了業務容量痛點、促進業務快速迭代開發、性能提升外,成本還節省了數倍。成本節省總結如下:
400億維度計算(mysql和MongoDB都存儲相同的400億數據):
CPU和內存成本比例:4:1
磁盤成本比例:3.3:1
1500億維度計算(假設mysql集群都采用之前規格等比例換算):
CPU和內存成本比例:16:1
磁盤成本比例:3.3:1
從上面的分析可以看出,數據量越大,按照等比例換算原則,MongoDB存儲成本會更低,原因如下:
CPU/內存節省原因:
主要是因為MongoDB海量數據存儲及高性能原因,索引建好后,單實例單表即使幾百億數據,讀寫也是ms級返回(注意:切記查詢更新建好索引)。
此外,由于MongoDB分布式功能,對容量評估更加方便,就無需提前一次性申請很多套mysql,而是根據實際需要可以隨時加分片。
磁盤節省原因:
MongoDB存儲引擎wiredtiger默認高壓縮、高性能。
最后,鑒于客觀性成本評價,CPU/內存成本部分可能會有爭議,比如mysql內存和CPU是否申請的時候就申請過大。MongoDB對應CPU也同樣存在該問題,例如申請的單個容器是16CPU,實際上真實只消耗了幾個CPU。
但是,磁盤節省是實實在在的,是相同數據情況下mysql和MongoDB的真實磁盤消耗對比。
當前該集群總數據量已經達到近千億,并以每個月200億規模增加,單從容器計費層面上換算,1000億數據按照等比例換算,預計節省成本10倍。
八、最后:千億級中等規模MongoDB集群注意事項
MongoDB無需分庫分表,單表可以無限大,但是單表隨著數據量的增多會引起以下問題:
切記提前建好索引,否則影響查詢更新性能(數據越多,無索引查詢掃描會越慢)。
切記提前評估好業務需要那些索引,單節點單個表數百億數據,加索引執行時間較長。
服務器異常情況下節點替換時間相比會更長。
切記數據備份不要采用mongodump/mongorestore方式,而是采用熱備或者文件拷貝方式備份。
節點替換盡量從備份中拷貝數據加載方式恢復,而不是通過主從全量同步方式,全量同步過程較長。
九、未來挑戰(該集群未來萬億級實時數據規模挑戰)
隨著時間推移,業務數據增長也會越來越多,單月數據量增長曲線預計會直線增加(當前每月數據量增加200億左右),預計未來2-3年該集群總數據量會達到萬億級,分片數也會達到20個分片左右,可能會遇到各自各樣的問題。
- 但是,IOT業務數據存在明顯的冷數問題,一年前的數據用戶基本上不會訪問,因此我們考慮做如下優后來滿足性能、成本的進一步提升:冷數據歸檔到低成本SATA盤
- 冷數據提升壓縮比,最大化減少磁盤消耗
- 如何解決冷數據歸檔sata盤過程中的性能問題
十、最后說明(業務場景)
本千億級IOT業務使用場景總結如下:
- 本分享的業務數據讀、更新、排序等都可以走索引,包括單字段索引、多字段索引、數組索引,所有查詢和更新都能確定走具體的某個最優索引。
- 查詢都是單表查詢,不涉及多表聯合查詢。
- 數據庫場景非常重要,脫離業務場景談數據庫優劣無任何意義。例如本文的業務場景,業務能確定需要建那些索引,同時所有的更新、查詢、排序都可以對應具體的最優索引,因此該場景就非常適合MongoDB。
- 每種數據庫都有其適合的業務場景,沒有萬能的數據庫。此外,不能因為某種場景不適合而全盤否定沒數據庫,主流數據庫都有其存在的意義,千萬不能因為某種場景下的不合適而全盤否定某個數據庫。
作者介紹
楊亞洲,前滴滴出行專家工程師,現任OPPO文檔數據庫MongoDB負責人,負責數萬億級數據量文檔數據庫MongoDB內核研發、性能優化及運維工作,一直專注于分布式緩存、高性能服務端、數據庫、中間件等相關研發。后續持續分享《MongoDB內核源碼設計、性能優化、最佳運維實踐》。














