生產環境Kafka集群400W/Tps為啥就扛不住了?
最近公司日志Kafka集群出現了性能瓶頸,單節點還沒達到60W/tps時消息發送就出現了很大延遲,甚至最高超過了10s,截圖說明如下:
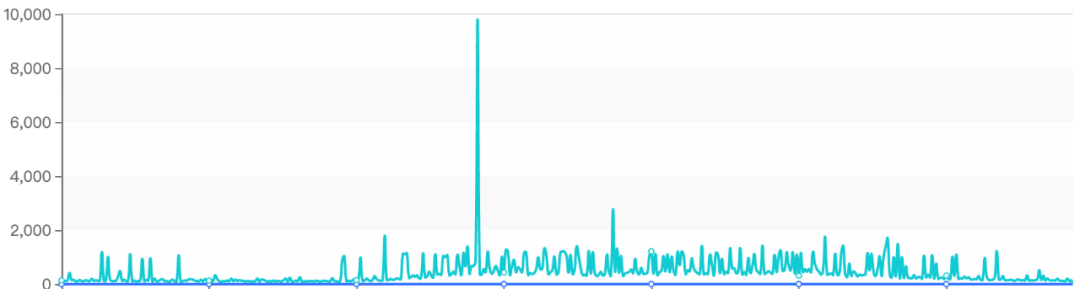
雖說使用的機械磁盤,但這點壓力對Kafka來說應該是小菜一碟,這引起了我的警覺,需要對其進行一番診斷了。
通過監控平臺觀察Kafka集群中相關的監控節點,發現cpu使用率才接近20%左右,磁盤IO等待等指標都并未出現任何異常,那會是什么問題呢?
通常CPU耗時不大,但性能已經明顯下降了,我們優先會去排查kafka節點的線程棧,獲取線程棧的方法比較簡單,命令為:
ps -ef | grep kafka // 獲取pid
jstack pid > j1.log
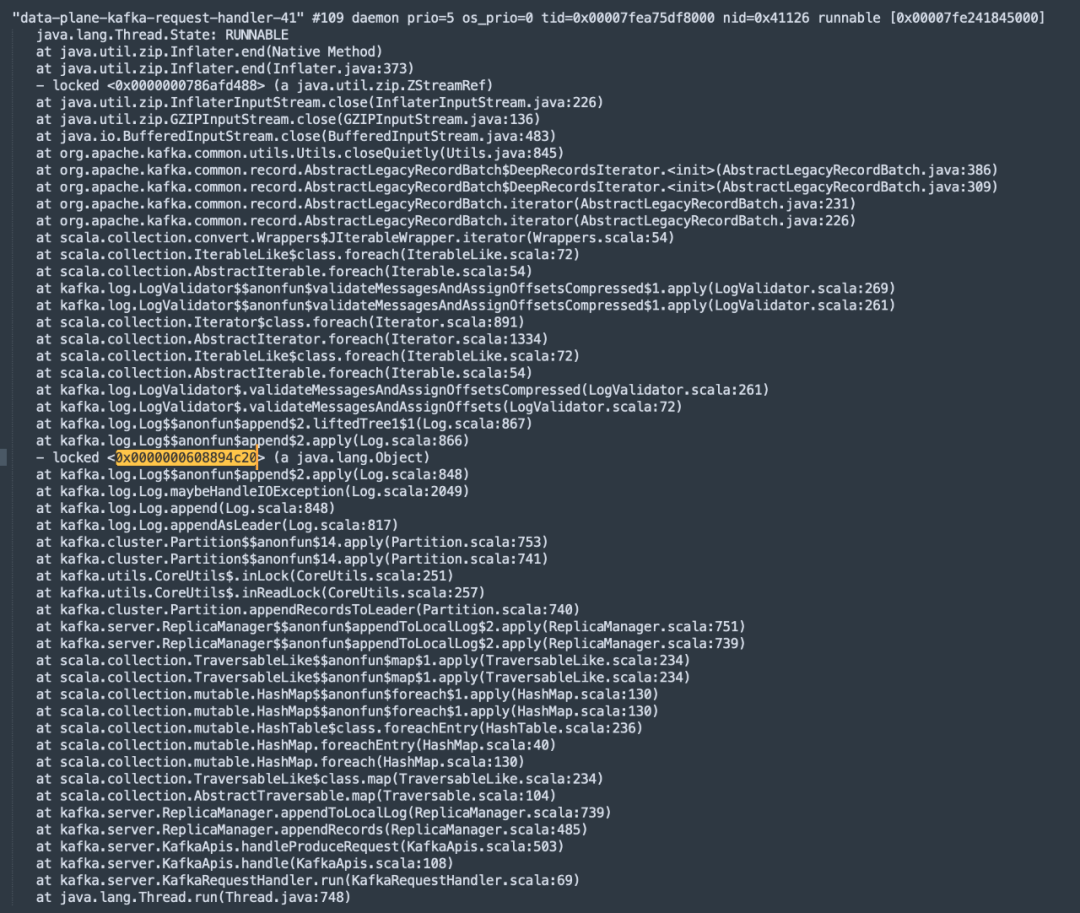
通過上述命令我們就可以獲取到kafka進程的堆棧信息,通過查看線程名稱中包含kafka-request-handler字眼的線程(Kafka中處理請求),發現了大量的鎖等待,具體截圖如下所示:
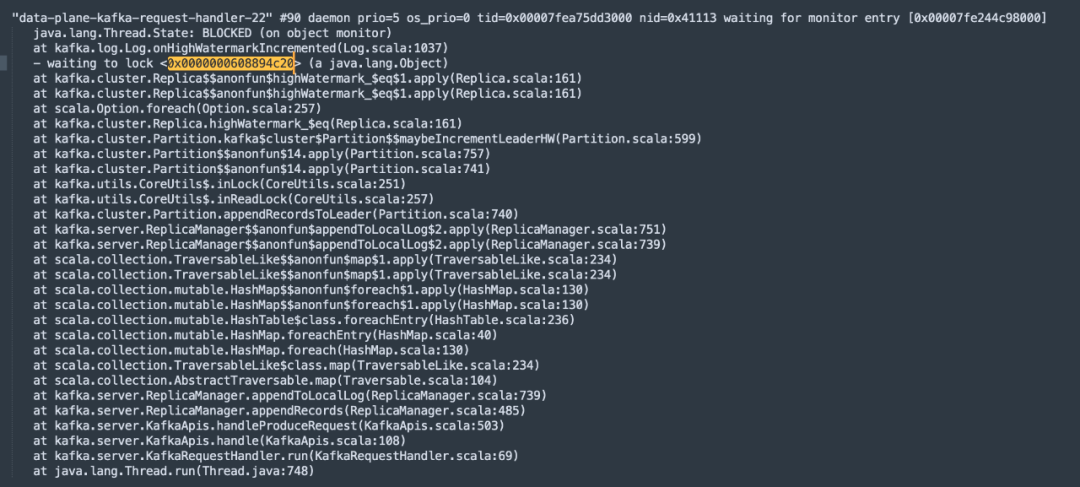
并且在jstack文件中發現很多線程都在等待這把鎖,截圖如下:
我們先根據線程堆棧查看代碼,找到對應的源代碼如下圖所示:
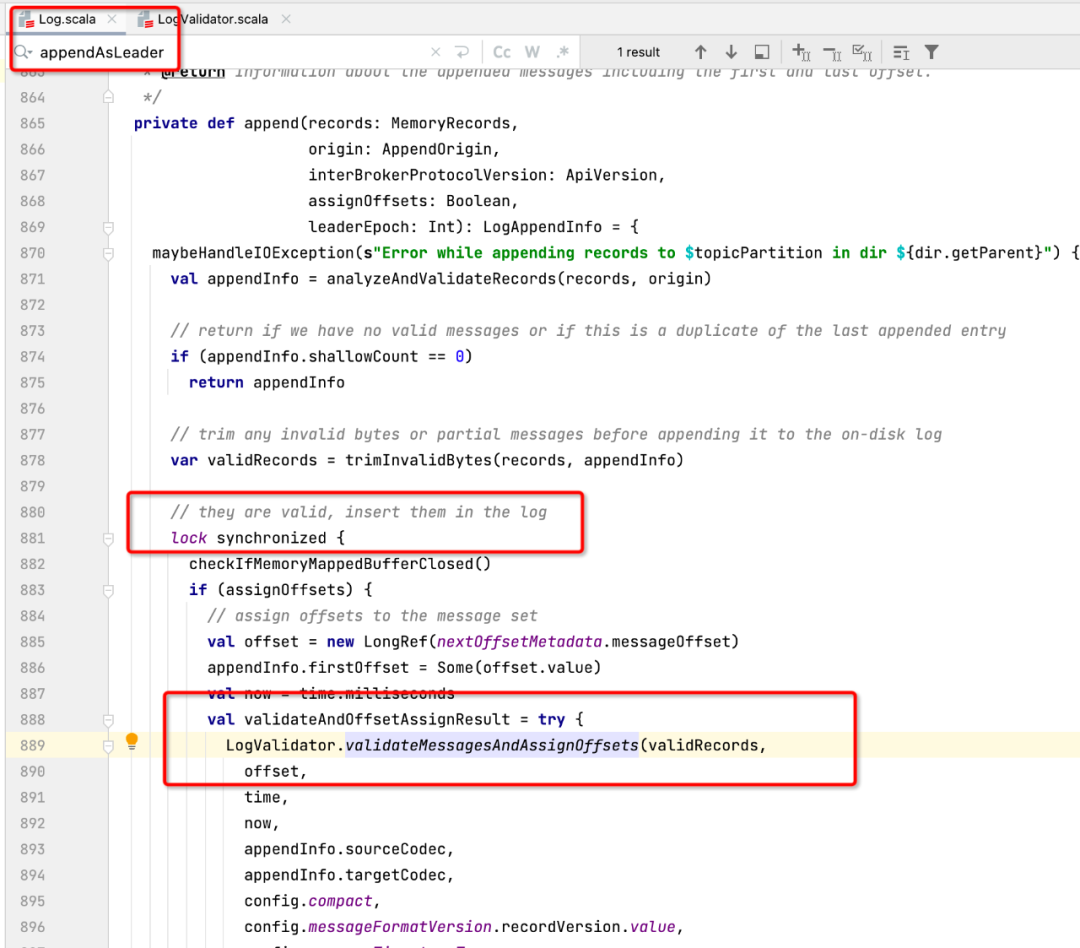
通過閱讀源碼,這段代碼是分區Leader在追加數據時為了保證寫入分區時數據的完整性,對分區進行的加鎖,即如果對同一個分區收到多個寫入請求,則這些請求將串行執行,這個鎖時必須的,無法進行優化,但仔細觀察線程的調用棧,發現在鎖的代碼塊出現了GZIPInputstream,進行了zip壓縮,一個壓縮處在鎖中,其執行性能注定低下,那在什么時候需要在服務端進行壓縮呢?
故我們繼續看一下LogValidator的validateMessagesAndAssignOffsets方法,最終調用validateMessagesAndAssignOffsetsCompressed方法,部分代碼截圖如下所示:
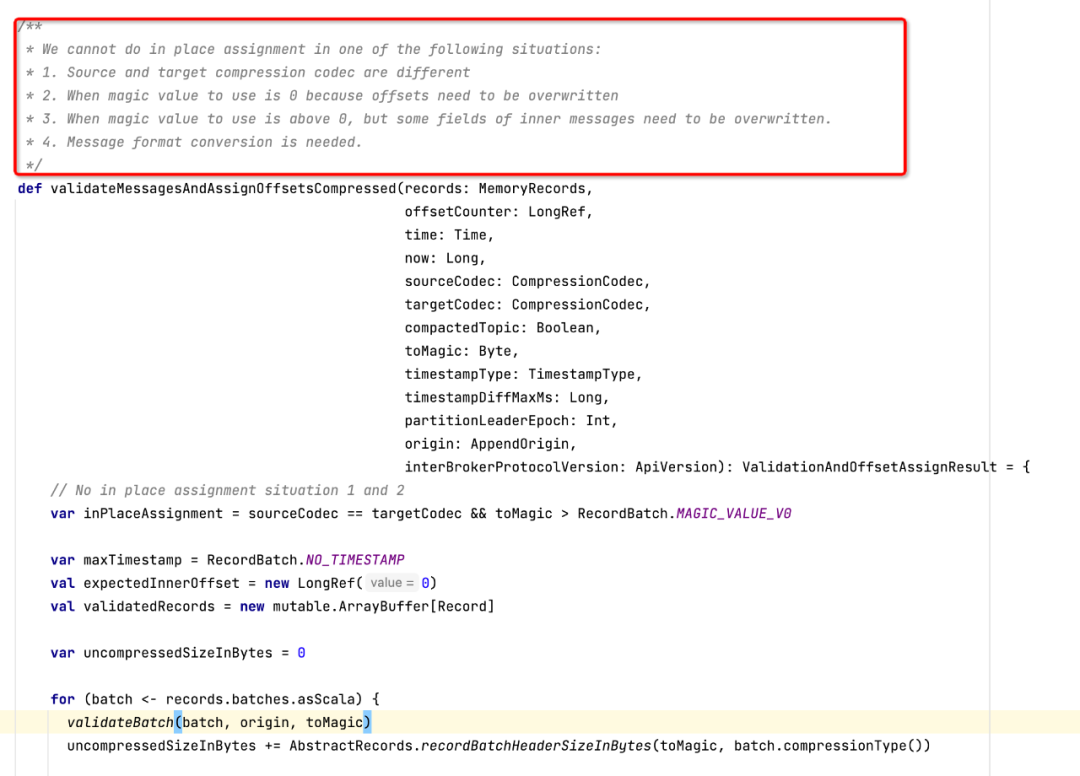
這段代碼的注釋部分詳細介紹了kafka在服務端需要進行壓縮的4種情況,對其進行翻譯,其實就是兩種情況:
- 客戶端與服務端端壓縮算法不一致
- 客戶端與服務端端的消息版本格式不一樣,包括offset的表示方法、壓縮處理方法
關于客戶端與服務端壓縮算法不一致,這個基本不會出現,因為服務端通常可以支持多種壓縮算法,會根據客戶端的壓縮算法進行自動匹配。
最有可能的就是服務端與客戶端端消息協議版本不一致,如果版本不一致,則需要在服務端重新偏移量,如果使用了壓縮機制,則需要重新進行解壓縮,然后計算位點,再進行壓縮存儲,性能消耗極大。
后面排查日志使用端,確實是客戶端版本與服務端版本不一致導致,最終需要對客戶端進行統一升級。