Kubernetes集群搭建超詳細總結(CentOS版)
本文轉載自微信公眾號「無敵碼農」,作者無敵碼農。轉載本文請聯系無敵碼農公眾號。
學習Kubernetes的關鍵一步就是要學會搭建一套k8s集群。在今天的文章中作者將最近新總結的搭建技巧,無償分享給大家!廢話不多說,直接上干貨!
01、系統環境準備
要安裝部署Kubernetes集群,首先需要準備機器,最直接的辦法可以到公有云(如阿里云等)申請幾臺虛擬機。而如果條件允許,拿幾臺本地物理服務器來組建集群自然是最好不過了。但是這些機器需要滿足以下幾個條件:
要求64位Linux操作系統,且內核版本要求3.10及以上,能滿足安裝Docker項目所需的要求;
機器之間要保持網絡互通,這是未來容器之間網絡互通的前提條件;
要有外網訪問權限,因為部署的過程中需要拉取相應的鏡像,要求能夠訪問到gcr.io、quay.io這兩個docker registry,因為有小部分鏡像需要從這里拉取;
單機可用資源建議2核CPU、8G內存或以上,如果小一點也可以但是能調度的Pod數量就比較有限了;
磁盤空間要求在30GB以上,主要用于存儲Docker鏡像及相關日志文件;
在本次實驗中我們準備了兩臺虛擬機,其具體配置如下:
2核CPU、2GB內存,30GB的磁盤空間;
Unbantu 20.04 LTS的Sever版本,其Linux內核為5.4.0;
內網互通,外網訪問權限不受控制;
02、Kubernetes集群部署工具Kubeadm介紹
作為典型的分布式系統,Kubernetes的部署一直是困擾初學者進入Kubernetes世界的一大障礙。在發布早期Kubernetes的部署主要依賴于社區維護的各種腳本,但這其中會涉及二進制編譯、配置文件以及kube-apiserver授權配置文件等諸多運維工作。目前各大云服務廠商常用的Kubernetes部署方式是使用SaltStack、Ansible等運維工具自動化地執行這些繁瑣的步驟,但即使這樣,這個部署的過程對于初學者來說依然是非常繁瑣的。
正是基于這樣的痛點,在志愿者的推動下Kubernetes社區終于發起了kubeadm這一獨立的一鍵部署工具,使用kubeadm我們可以通過幾條簡單的指令來快速地部署一個kubernetes集群。在接下來的內容中,就將具體演示如何使用kubeadm來部署一個簡單結構的Kubernetes集群。
03、安裝kubeadm及Docker環境
正是基于這樣的痛點,在志愿者的推動下Kubernetes社區終于發起了kubeadm這一獨立的一鍵部署工具,使用kubeadm我們可以通過幾條簡單的指令來快速地部署一個kubernetes集群。在接下來的內容中,就將具體演示如何使用kubeadm來部署一個簡單結構的Kubernetes集群。
前面簡單介紹了Kubernetes官方發布一鍵部署工具kubeadm,只需要添加kubeadm的源,然后直接用yum安裝即可,具體操作如下:
1)、編輯操作系統安裝源配置文件,添加kubernetes鏡像源,命令如下:
- #添加Docker阿里鏡像源
- [root@centos-linux ~]# wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
- #安裝Docker
- [root@centos-linux ~]# yum -y install docker-ce-18.09.9-3.el7
- #啟動Docker并設置開機啟動
- [root@centos-linux ~]# systemctl enable docker
- 添加Kubernetes yum鏡像源,由于網絡原因,也可以換成國內Ubantu鏡像源,如阿里云鏡像源地址:
- 添加阿里云Kubernetes yum鏡像源
- # cat > /etc/yum.repos.d/kubernetes.repo << EOF
- [kubernetes]
- name=Kubernetes
- baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
- enabled=1
- gpgcheck=0
- repo_gpgcheck=0
- gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
- EOF
2)、完成上述步驟后就可以通過yum命令安裝kubeadm了,如下:
- [root@centos-linux ~]# yum install -y kubelet-1.20.0 kubeadm-1.20.0 kubectl-1.20.0
- 當前版本是最新版本1.21,這里安裝1.20。
- #查看安裝的kubelet版本信息
- [root@centos-linux ~]# kubectl version
- Client Version: version.Info{Major:"1", Minor:"20", GitVersion:"v1.20.0", GitCommit:"af46c47ce925f4c4ad5cc8d1fca46c7b77d13b38", GitTreeState:"clean", BuildDate:"2020-12-08T17:59:43Z", GoVersion:"go1.15.5", Compiler:"gc", Platform:"linux/amd64"}
- The connection to the server localhost:8080 was refused - did you specify the right host or port?
- 在上述安裝kubeadm的過程中,kubeadm和kubelet、kubectl、kubernetes-cni這幾個kubernetes核心組件的二進制文件也都會被自動安裝好。
3)、Docker服務啟動及限制修改
在具體運行kubernetes部署之前需要對Docker的配置信息進行一些調整。首先,編輯系統/etc/default/grub文件,在配置項GRUB_CMDLINE_LINUX中添加如下參數:
- GRUB_CMDLINE_LINUX=" cgroup_enable=memory swapaccount=1"
完成編輯后保存執行如下命令,并重啟服務器,命令如下:
- root@kubernetesnode01:/opt/kubernetes-config# reboot
上述修改主要解決的是可能出現的“docker警告WARNING: No swap limit support”問題。其次,編輯創建/etc/docker/daemon.json文件,添加如下內容:
- # cat > /etc/docker/daemon.json <<EOF
- {
- "registry-mirrors": ["https://6ze43vnb.mirror.aliyuncs.com"],
- "exec-opts": ["native.cgroupdriver=systemd"],
- "log-driver": "json-file",
- "log-opts": {
- "max-size": "100m"
- },
- "storage-driver": "overlay2"
- }
- EOF
- 完成保存后執行重啟Docker命令,如下:
- # systemctl restart docker
- 此時可以查看Docker的Cgroup信息,如下:
- # docker info | grep Cgroup
- Cgroup Driver: systemd
上述修改主要解決的是“Docker cgroup driver. The recommended driver is "systemd"”的問題。需要強調的是以上修改只是作者在具體安裝操作是遇到的具體問題的解決整理,如在實踐過程中遇到其他問題還需要自行查閱相關資料!
最后,需要注意由于kubernetes禁用虛擬內存,所以要先關閉掉swap否則就會在kubeadm初始化kubernetes的時候報錯,具體如下:
- # swapoff -a
該命令只是臨時禁用swap,如要保證系統重啟后仍然生效則需要“vim /etc/fstab”文件,并注釋掉swap那一行。
04、部署Kubernetes的Master節點
在Kubernetes中Master節點是集群的控制節點,它是由三個緊密協作的獨立組件組合而成,分別是負責API服務的kube-apiserver、負責調度的kube-scheduler以及負責容器編排的kube-controller-manager,其中整個集群的持久化數據由kube-apiserver處理后保存在Etcd中。
要部署Master節點可以直接通過kubeadm進行一鍵部署,但這里我們希望能夠部署一個相對完整的Kubernetes集群,可以通過配置文件來開啟一些實驗性的功能。具體在系統中新建/opt/kubernetes-config/目錄,并創建一個給kubeadm用的YAML文件(kubeadm.yaml),具體內容如下:
- apiVersion: kubeadm.k8s.io/v1beta2
- kind: ClusterConfiguration
- controllerManager:
- extraArgs:
- horizontal-pod-autoscaler-use-rest-clients: "true"
- horizontal-pod-autoscaler-sync-period: "10s"
- node-monitor-grace-period: "10s"
- apiServer:
- extraArgs:
- runtime-config: "api/all=true"
- kubernetesVersion: "v1.20.0"
在上述yaml配置文件中“horizontal-pod-autoscaler-use-rest-clients: "true"”這個配置,表示將來部署的kuber-controller-manager能夠使用自定義資源(Custom Metrics)進行自動水平擴展,感興趣的讀者可以自行查閱相關資料!而“v1.20.0”就是要kubeadm幫我們部署的Kubernetes版本號。
需要注意的是,如果執行過程中由于國內網絡限制問題導致無法下載相應的Docker鏡像,可以根據報錯信息在國內網站(如阿里云)上找到相關鏡像,然后再將這些鏡像重新tag之后再進行安裝。具體如下:
- #從阿里云Docker倉庫拉取Kubernetes組件鏡像
- docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver-amd64:v1.20.0
- docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager-amd64:v1.20.0
- docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler-amd64:v1.20.0
- docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy-amd64:v1.20.0
- docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.2
- docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.4.13-0
- docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.7.0
下載完成后再將這些Docker鏡像重新tag下,具體命令如下:
- #重新tag鏡像
- docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler-amd64:v1.20.0 k8s.gcr.io/kube-scheduler:v1.20.0
- docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager-amd64:v1.20.0 k8s.gcr.io/kube-controller-manager:v1.20.0
- docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver-amd64:v1.20.0 k8s.gcr.io/kube-apiserver:v1.20.0
- docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy-amd64:v1.20.0 k8s.gcr.io/kube-proxy:v1.20.0
- docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.2 k8s.gcr.io/pause:3.2
- docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.4.13-0 k8s.gcr.io/etcd:3.4.13-0
- docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.7.0 k8s.gcr.io/coredns:1.7.0
- 此時通過Docker命令就可以查看到這些Docker鏡像信息了,命令如下:
- root@kubernetesnode01:/opt/kubernetes-config# docker images
- REPOSITORY TAG IMAGE ID CREATED SIZE
- k8s.gcr.io/kube-proxy v1.18.1 4e68534e24f6 2 months ago 117MB
- registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy-amd64 v1.18.1 4e68534e24f6 2 months ago 117MB
- k8s.gcr.io/kube-controller-manager v1.18.1 d1ccdd18e6ed 2 months ago 162MB
- registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager-amd64 v1.18.1 d1ccdd18e6ed 2 months ago 162MB
- k8s.gcr.io/kube-apiserver v1.18.1 a595af0107f9 2 months ago 173MB
- registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver-amd64 v1.18.1 a595af0107f9 2 months ago 173MB
- k8s.gcr.io/kube-scheduler v1.18.1 6c9320041a7b 2 months ago 95.3MB
- registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler-amd64 v1.18.1 6c9320041a7b 2 months ago 95.3MB
- k8s.gcr.io/pause 3.2 80d28bedfe5d 4 months ago 683kB
- registry.cn-hangzhou.aliyuncs.com/google_containers/pause 3.2 80d28bedfe5d 4 months ago 683kB
- k8s.gcr.io/coredns 1.6.7 67da37a9a360 4 months ago 43.8MB
- registry.cn-hangzhou.aliyuncs.com/google_containers/coredns 1.6.7 67da37a9a360 4 months ago 43.8MB
- k8s.gcr.io/etcd 3.4.3-0 303ce5db0e90 8 months ago 288MB
- registry.cn-hangzhou.aliyuncs.com/google_containers/etcd-amd64
解決鏡像拉取問題后再次執行kubeadm部署命令就可以完成Kubernetes Master控制節點的部署了,具體命令及執行結果如下:
- root@kubernetesnode01:/opt/kubernetes-config# kubeadm init --config kubeadm.yaml --v=5
- ...
- Your Kubernetes control-plane has initialized successfully!
- To start using your cluster, you need to run the following as a regular user:
- mkdir -p $HOME/.kube
- sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
- sudo chown $(id -u):$(id -g) $HOME/.kube/config
- Alternatively, if you are the root user, you can run:
- export KUBECONFIG=/etc/kubernetes/admin.conf
- You should now deploy a pod network to the cluster.
- Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
- https://kubernetes.io/docs/concepts/cluster-administration/addons/
- Then you can join any number of worker nodes by running the following on each as root:
- kubeadm join 10.211.55.13:6443 --token yi9lua.icl2umh9yifn6z9k \
- --discovery-token-ca-cert-hash sha256:074460292aa167de2ae9785f912001776b936cec79af68cec597bd4a06d5998d
從上面部署執行結果中可以看到,部署成功后kubeadm會生成如下指令:
- kubeadm join 10.211.55.13:6443 --token yi9lua.icl2umh9yifn6z9k \
- --discovery-token-ca-cert-hash sha256:074460292aa167de2ae9785f912001776b936cec79af68cec597bd4a06d5998d
這個kubeadm join命令就是用來給該Master節點添加更多Worker(工作節點)的命令,后面具體部署Worker節點的時候將會使用到它。此外,kubeadm還會提示我們第一次使用Kubernetes集群所需要配置的命令:
- mkdir -p $HOME/.kube
- sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
- sudo chown $(id -u):$(id -g) $HOME/.kube/config
而需要這些配置命令的原因在于Kubernetes集群默認是需要加密方式訪問的,所以這幾條命令就是將剛才部署生成的Kubernetes集群的安全配置文件保存到當前用戶的.kube目錄,之后kubectl會默認使用該目錄下的授權信息訪問Kubernetes集群。如果不這么做的化,那么每次通過集群就都需要設置“export KUBECONFIG 環境變量”來告訴kubectl這個安全文件的位置。
執行完上述命令后,現在我們就可以使用kubectl get命令來查看當前Kubernetes集群節點的狀態了,執行效果如下:
- # kubectl get nodes
- NAME STATUS ROLES AGE VERSION
- centos-linux.shared NotReady control-plane,master 6m55s v1.20.0
在以上命令輸出的結果中可以看到Master節點的狀態為“NotReady”,為了查找具體原因可以通過“kuberctl describe”命令來查看下該節點(Node)對象的詳細信息,命令如下:
- # kubectl describe node centos-linux.shared
該命令可以非常詳細地獲取節點對象的狀態、事件等詳情,這種方式也是調試Kubernetes集群時最重要的排查手段。根據顯示的如下信息:
- ...
- Conditions
- ...
- Ready False... KubeletNotReady runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
- ...
可以看到節點處于“NodeNotReady”的原因在于尚未部署任何網絡插件,為了進一步驗證這一點還可以通過kubectl檢查這個節點上各個Kubernetes系統Pod的狀態,命令及執行效果如下:
- # kubectl get pods -n kube-system
- NAME READY STATUS RESTARTS AGE
- coredns-66bff467f8-l4wt6 0/1 Pending 0 64m
- coredns-66bff467f8-rcqx6 0/1 Pending 0 64m
- etcd-kubernetesnode01 1/1 Running 0 64m
- kube-apiserver-kubernetesnode01 1/1 Running 0 64m
- kube-controller-manager-kubernetesnode01 1/1 Running 0 64m
- kube-proxy-wjct7 1/1 Running 0 64m
- kube-scheduler-kubernetesnode01 1/1 Running 0
命令中“kube-system”表示的是Kubernetes項目預留的系統Pod空間(Namespace),需要注意它并不是Linux Namespace,而是Kuebernetes劃分的不同工作空間單位。回到命令輸出結果,可以看到coredns等依賴于網絡的Pod都處于Pending(調度失敗)的狀態,這樣說明了該Master節點的網絡尚未部署就緒。
05、部署Kubernetes網絡插件
前面部署Master節點中由于沒有部署網絡插件,所以節點狀態顯示“NodeNotReady”狀態。接下來的內容我們就來具體部署下網絡插件。在Kubernetes“一切皆容器”的設計理念指導下,網絡插件也會以獨立Pod的方式運行在系統中,所以部署起來也很簡單只需要執行“kubectl apply”指令即可,例如以Weave網絡插件為例:
- # kubectl apply -f https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')
- serviceaccount/weave-net created
- clusterrole.rbac.authorization.k8s.io/weave-net created
- clusterrolebinding.rbac.authorization.k8s.io/weave-net created
- role.rbac.authorization.k8s.io/weave-net created
- rolebinding.rbac.authorization.k8s.io/weave-net created
- daemonset.apps/weave-net created
部署完成后通過“kubectl get”命令重新檢查Pod的狀態:
- # kubectl get pods -n kube-system
- NAME READY STATUS RESTARTS AGE
- coredns-66bff467f8-l4wt6 1/1 Running 0 116m
- coredns-66bff467f8-rcqx6 1/1 Running 0 116m
- etcd-kubernetesnode01 1/1 Running 0 116m
- kube-apiserver-kubernetesnode01 1/1 Running 0 116m
- kube-controller-manager-kubernetesnode01 1/1 Running 0 116m
- kube-proxy-wjct7 1/1 Running 0 116m
- kube-scheduler-kubernetesnode01 1/1 Running 0 116m
- weave-net-746qj 2/2 Running 0 14m
可以看到,此時所有的系統Pod都成功啟動了,而剛才部署的Weave網絡插件則在kube-system下面新建了一個名叫“weave-net-746qj”的Pod,而這個Pod就是容器網絡插件在每個節點上的控制組件。
到這里,Kubernetes的Master節點就部署完成了,如果你只需要一個單節點的Kubernetes,那么現在就可以使用了。但是在默認情況下,Kubernetes的Master節點是不能運行用戶Pod的,需要通過額外的操作進行調整,在本文的最后將會介紹到它。
06、部署Worker節點
為了構建一個完整的Kubernetes集群,這里還需要繼續介紹如何部署Worker節點。實際上Kubernetes的Worker節點和Master節點幾乎是相同的,它們都運行著一個kubelet組件,主要的區別在于“kubeadm init”的過程中,kubelet啟動后,Master節點還會自動啟動kube-apiserver、kube-scheduler及kube-controller-manager這三個系統Pod。
在具體部署之前與Master節點一樣,也需要在所有Worker節點上執行前面“安裝kubeadm及Decker環境”小節中的所有步驟。之后在Worker節點執行部署Master節點時生成的“kubeadm join”指令即可,具體如下:
root@kubenetesnode02:~# kubeadm join 10.211.55.6:6443 --token jfulwi.so2rj5lukgsej2o6 --discovery-token-ca-cert-hash
- root@kubenetesnode02:~# kubeadm join 10.211.55.6:6443 --token jfulwi.so2rj5lukgsej2o6 --discovery-token-ca-cert-hash sha256:d895d512f0df6cb7f010204193a9b240e8a394606090608daee11b988fc7fea6 --v=5
- ...
- This node has joined the cluster:
- * Certificate signing request was sent to apiserver and a response was received.
- * The Kubelet was informed of the new secure connection details.
- Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
完成集群加入后為了便于在Worker節點執行kubectl相關命令,需要進行如下配置:
- #創建配置目錄
- root@kubenetesnode02:~# mkdir -p $HOME/.kube
- #將Master節點中$/HOME/.kube/目錄中的config文件拷貝至Worker節點對應目錄
- root@kubenetesnode02:~# scp root@10.211.55.6:$HOME/.kube/config $HOME/.kube/
- #權限配置
- root@kubenetesnode02:~# sudo chown $(id -u):$(id -g) $HOME/.kube/config
之后可以在Worker或Master節點執行節點狀態查看命令“kubectl get nodes”,具體如下:
- root@kubernetesnode02:~# kubectl get nodes
- NAME STATUS ROLES AGE VERSION
- kubenetesnode02 NotReady <none> 33m v1.18.4
- kubernetesnode01 Ready master 29h v1.18.4
通過節點狀態顯示此時Work節點還處于NotReady狀態,具體查看節點描述信息如下:
- root@kubernetesnode02:~# kubectl describe node kubenetesnode02
- ...
- Conditions:
- ...
- Ready False ... KubeletNotReady runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
- ...
根據描述信息,發現Worker節點NotReady的原因也在于網絡插件沒有部署,繼續執行“部署Kubernetes網絡插件”小節中的步驟即可。但是要注意部署網絡插件時會同時部署kube-proxy,其中會涉及從k8s.gcr.io倉庫獲取鏡像的動作,如果無法訪問外網可能會導致網絡部署異常,這里可以參考前面安裝Master節點時的做法,通過國內鏡像倉庫下載后通過tag的方式進行標記,具體如下:
- #從阿里云拉取必要鏡像
- docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy-amd64:v1.20.0
- docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.2
- #將鏡像重新打tag
- docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy-amd64:v1.20.0 k8s.gcr.io/kube-proxy:v1.20.0
- docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.2 k8s.gcr.io/pause:3.2
- 如若一切正常,則繼續查看節點狀態,命令如下:
- root@kubenetesnode02:~# kubectl get node
- NAME STATUS ROLES AGE VERSION
- kubenetesnode02 Ready <none> 7h52m v1.20.0
- kubernetesnode01 Ready master 37h v1.20.0
可以看到此時Worker節點的狀態已經變成“Ready”,不過細心的讀者可能會發現Worker節點的ROLES并不像Master節點那樣顯示“master”而是顯示了
- root@kubenetesnode02:~# kubectl label node kubenetesnode02 node-role.kubernetes.io/worker=worker
再次運行節點狀態命令就能看到正常的顯示了,命令效果如下:
- root@kubenetesnode02:~# kubectl get node
- NAME STATUS ROLES AGE VERSION
- kubenetesnode02 Ready worker 8h v1.18.4
- kubernetesnode01 Ready master 37h v1.18.4
到這里就部署完成了具有一個Master節點和一個Worker節點的Kubernetes集群了,作為實驗環境它已經具備了基本的Kubernetes集群功能!
07、部署Dashboard可視化插件
在Kubernetes社區中,有一個很受歡迎的Dashboard項目,它可以給用戶一個可視化的Web界面來查看當前集群中的各種信息。該插件也是以容器化方式進行部署,操作也非常簡單,具體可在Master、Worker節點或其他能夠安全訪問Kubernetes集群的Node上進行部署,命令如下:
- root@kubenetesnode02:~# kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.3/aio/deploy/recommended.yaml
部署完成后就可以查看Dashboard對應的Pod運行狀態,執行效果如下:
- root@kubenetesnode02:~# kubectl get pods -n kubernetes-dashboard
- NAME READY STATUS RESTARTS AGE
- dashboard-metrics-scraper-6b4884c9d5-xfb8b 1/1 Running 0 12h
- kubernetes-dashboard-7f99b75bf4-9lxk8 1/1 Running 0 12h
除此之外還可以查看Dashboard的服務(Service)信息,命令如下:
- root@kubenetesnode02:~# kubectl get svc -n kubernetes-dashboard
- NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
- dashboard-metrics-scraper ClusterIP 10.97.69.158 <none> 8000/TCP 13h
- kubernetes-dashboard ClusterIP 10.111.30.214 <none>
需要注意的是,由于Dashboard是一個Web服務,從安全角度出發Dashboard默認只能通過Proxy的方式在本地訪問。具體方式為在本地機器安裝kubectl管理工具,并將Master節點$HOME/.kube/目錄中的config文件拷貝至本地主機相同目錄,之后運行“kubectl proxy”命令,如下:
- qiaodeMacBook-Pro-2:.kube qiaojiang$ kubectl proxy
- Starting to serve on 127.0.0.1:8001
本地proxy代理啟動后,訪問Kubernetes Dashboard地址,具體如下:
- http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/
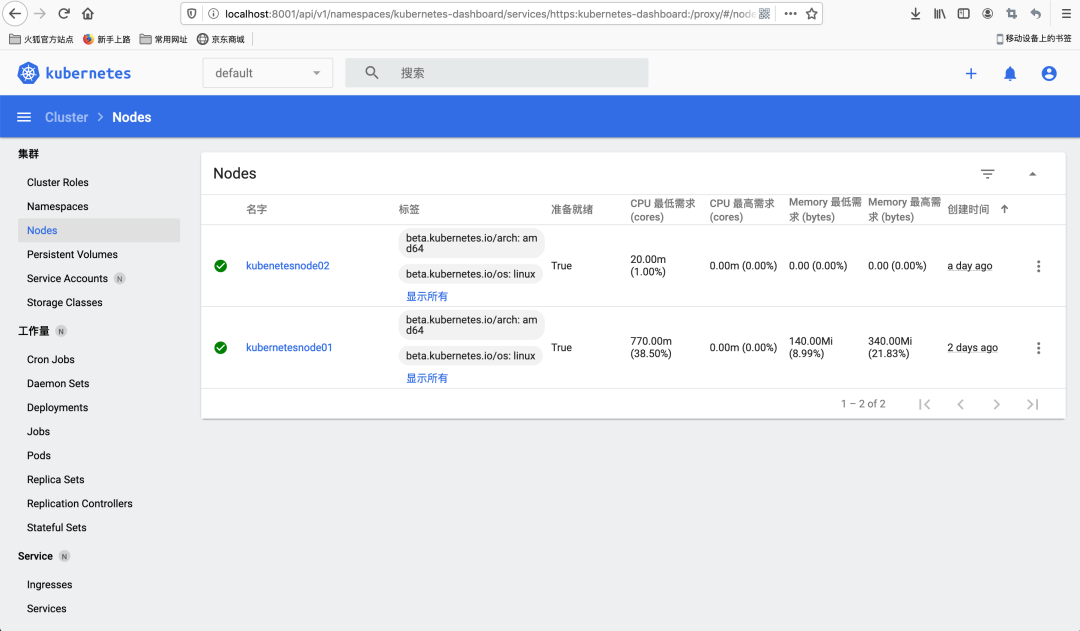
如果訪問正常,就會看到如下圖所示界面:

如上圖所示Dashboard訪問需要進行身份認證,主要有Token及Kubeconfig兩種方式,這里我們選擇Token的方式,而Token的生成步驟如下:
1)、創建一個服務賬號
首先在命名空間kubernetes-dashboard中創建名為admin-user的服務賬戶,具體步驟為在本地目錄創建類似“dashboard-adminuser.yaml”文件,具體內容如下:
- apiVersion: v1
- kind: ServiceAccount
- metadata:
- name: admin-user
- namespace: kubernetes-dashboard
編寫文件后具體執行創建命令:
- qiaodeMacBook-Pro-2:.kube qiaojiang$ kubectl apply -f dashboard-adminuser.yaml
- Warning: kubectl apply should be used on resource created by either kubectl create --save-config or kubectl apply
- serviceaccount/admin-user configured
2)、創建ClusterRoleBinding
在使用kubeadm工具配置完Kubernetes集群后,集群中已經存在ClusterRole集群管理,可以使用它為上一步創建的ServiceAccount創建ClusterRoleBinding。具體步驟為在本地目錄創建類似“dashboard-clusterRoleBingding.yaml”的文件,具體內容如下:
- apiVersion: rbac.authorization.k8s.io/v1
- kind: ClusterRoleBinding
- metadata:
- name: admin-user
- roleRef:
- apiGroup: rbac.authorization.k8s.io
- kind: ClusterRole
- name: cluster-admin
- subjects:
- - kind: ServiceAccount
- name: admin-user
- namespace: kubernetes-dashboard
執行創建命令:
- qiaodeMacBook-Pro-2:.kube qiaojiang$ kubectl apply -f dashboard-clusterRoleBingding.yaml
- clusterrolebinding.rbac.authorization.k8s.io/admin-user created
3)、獲取Bearer Token
接下來執行獲取Bearer Token的命令,具體如下:
- qiaodeMacBook-Pro-2:.kube qiaojiang$ kubectl -n kubernetes-dashboard describe secret $(kubectl -n kubernetes-dashboard get secret | grep admin-user | awk '{print $1}')
- Name: admin-user-token-xxq2b
- Namespace: kubernetes-dashboard
- Labels: <none>
- Annotations: kubernetes.io/service-account.name: admin-user
- kubernetes.io/service-account.uid: 213dce75-4063-4555-842a-904cf4e88ed1
- Type: kubernetes.io/service-account-token
- Data
- ====
- ca.crt: 1025 bytes
- namespace: 20 bytes
- token: eyJhbGciOiJSUzI1NiIsImtpZCI6IlplSHRwcXhNREs0SUJPcTZIYU1kT0pidlFuOFJa
獲取Token后回到前面的認證方式選擇界面,將獲取的Token信息填入就可以正式進入Dashboard的系統界面,看到Kubernetes集群的詳細可視化信息了,如圖所示:
到這里就完成了Kubernetes可視化插件的部署并通過本地Proxy的方式進行了登錄。在實際的生產環境中如果覺得每次通過本地Proxy的方式進行訪問不夠方便,也可以使用Ingress方式配置集群外訪問Dashboard,感興趣的讀者可以自行嘗試下。也可以先通過通過暴露端口,設置dashboard的訪問,例如:
- #查看svc名稱
- # kubectl get sc -n kubernetes-dashboard
- # kubectl edit services -n kubernetes-dashboard kubernetes-dashboard
然后修改配置文件,如下:
- ports:
- - nodePort: 30000
- port: 443
- protocol: TCP
- targetPort: 8443
- selector:
- k8s-app: kubernetes-dashboard
- sessionAffinity: None
- type: NodePort
之后就可以通過IP+nodePort端口訪問了!例如:
- https://47.98.33.48:30000/
08、Master調整Taint/Toleration策略
在前面我們提到過,Kubernetes集群的Master節點默認情況下是不能運行用戶Pod的。而之所以能夠達到這樣的效果,Kubernetes依靠的正是Taint/Toleration機制;而該機制的原理是一旦某個節點被加上“Taint”就表示該節點被“打上了污點”,那么所有的Pod就不能再在這個節點上運行。
而Master節點之所以不能運行用戶Pod,就在于其運行成功后會為自身節點打上“Taint”從而達到禁止其他用戶Pod運行在Master節點上的效果(不影響已經運行的Pod),具體可以通過命令查看Master節點上的相關信息,命令執行效果如下:
- root@kubenetesnode02:~# kubectl describe node kubernetesnode01
- Name: kubernetesnode01
- Roles: master
- ...
- Taints: node-role.kubernetes.io/master:NoSchedule
- ...
可以看到Master節點默認被加上了“node-role.kubernetes.io/master:NoSchedule”這樣的“污點”,其中的值“NoSchedule”意味著這個Taint只會在調度新的Pod時產生作用,而不會影響在該節點上已經運行的Pod。如果在實驗中只想要一個單節點的Kubernetes,那么可以在刪除Master節點上的這個Taint,具體命令如下:
- root@kubernetesnode01:~# kubectl taint nodes --all node-role.kubernetes.io/master-
上述命令通過在“nodes --all node-role.kubernetes.io/master”這個鍵后面加一個短橫線“-”表示移除所有以該鍵為鍵的Taint。
到這一步,一個基本的Kubernetes集群就部署完成了,通過kubeadm這樣的原生管理工具,Kubernetes的部署被大大簡化了,其中像證書、授權及各個組件配置等最麻煩的操作,kubeadm都幫我們完成了。
09、Kubernetes集群重啟命令
如果服務器斷電,或者重啟,可通過如下命令重啟集群:
- #重啟docker
- systemctl daemon-reload
- systemctl restart docker
- #重啟kubelet
- systemctl restart kubelet.service
以上就是在CentOS 7 系統環境下搭建一組Kubernetes學習集群的詳細步驟,其它Linux發行版本的部署方法也類似,大家可以根據自己的需求選擇!