超詳細的PG事務隔離級別總結,值得收藏
今天主要介紹一下PG的事務隔離,事務隔離和鎖機制是息息相關的,希望大家這兩塊都可以掌握。下面先看下SQL標準的四種隔離級別。
四種隔離級別
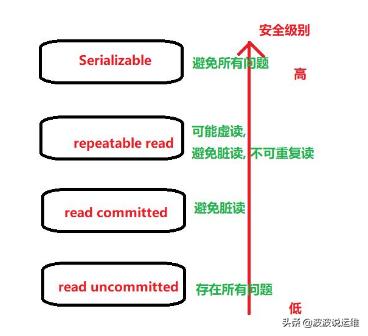
SQL標準定義了四種隔離級別。最嚴格的是可序列化,在標準中用了一整段來定義它,其中說到一組可序列化事務的任意并發執行被保證效果和以某種順序一個一個執行這些事務一樣。其他三種級別使用并發事務之間交互產生的現象來定義,每一個級別中都要求必須不出現一種現象。注意由于可序列化的定義,在該級別上這些現象都不可能發生。
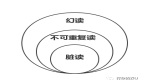
在各個級別上被禁止出現的現象是:
- 臟讀:一個事務讀取了另一個并行未提交事務寫入的數據。
- 不可重復讀:一個事務重新讀取之前讀取過的數據,發現該數據已經被另一個事務(在初始讀之后提交)修改。
- 幻讀:一個事務重新執行一個返回符合一個搜索條件的行集合的查詢, 發現滿足條件的行集合因為另一個最近提交的事務而發生了改變。
- 序列化異常:成功提交一組事務的結果與一次運行這些事務的所有可能順序不一致。
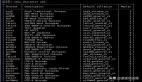
SQL標準和PostgreSQL實現的事務隔離級別如下:
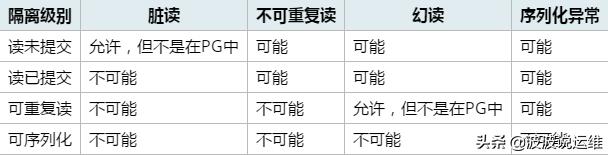
事務隔離級別
在PostgreSQL中可以請求四種標準事務隔離級別中的任意一種。 但是在內部,只實現了三種不同的隔離級別,即:PostgreSQL的讀未提交模式的行為類似于讀已提交。 這是因為這是把標準的隔離級別映射到PostgreSQL的多版本并發控制架構的唯一合理方法。
要設置一個事務的事務隔離級別,使用SET TRANSACTION命令
- SET TRANSACTION transaction_mode [, ...]
- SET TRANSACTION SNAPSHOT snapshot_id
- SET SESSION CHARACTERISTICS AS TRANSACTION transaction_mode [, ...]
- where transaction_mode is one of:
- ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED }
- READ WRITE | READ ONLY
- [ NOT ] DEFERRABLE
1. 讀已提交隔離級別
讀已提交是PostgreSQL中的默認隔離級別。
當一個事務運行使用這個隔離級別時, 一個查詢(沒有FOR UPDATE/SHARE子句)只能看到查詢開始之前已經被提交的數據, 而無法看到未提交的數據或在查詢執行期間其它事務提交的數據。(假設SQL查詢了10s,這10s中間插入的新數據是看不到的)實際上,SELECT查詢看到的是一個在查詢開始運行的瞬間該數據庫的一個快照。不過SELECT可以看見在它自身事務中之前執行的更新的效果,即使它們還沒有被提交。還要注意的是,即使在同一個事務里兩個相鄰的SELECT命令可能看到不同的數據, 因為其它事務可能會在第一個SELECT開始和第二個SELECT開始之間提交。
UPDATE、DELETE、SELECT FOR UPDATE和SELECT FOR SHARE命令在搜索目標行時的行為和SELECT一樣: 它們將只找到在命令開始時已經被提交的行。
帶有ON CONFLICT DO UPDATE子句的INSERT的行為類似。 在讀已提交模式下,建議插入的每一行都將插入或更新。除非有無關的錯誤, 否則這兩個結果中的一個是有保證的。如果沖突源于另一個其影響對于 INSERT不可見的事務,則將對該行使用UPDATE子句, 即使可能沒有命令常規可見的該行的版本。
帶有ON CONFLICT DO NOTHING子句的INSERT 可能由于其影響對INSERT快照不可見的另一事務的結果而不插入行。 同樣,只有在讀已提交模式下才是這種情況。
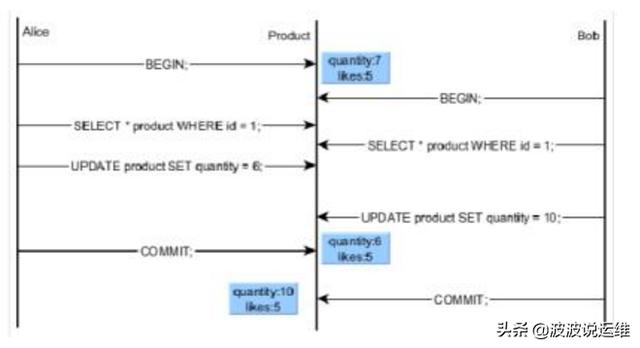
因為上面的規則,正在更新的命令可能會看到一個不一致的快照: 它們可以看到并發更新命令在它嘗試更新的相同行上的作用, 但是卻看不到那些命令對數據庫里其它行的作用。 這樣的行為令讀已提交模式不適合用于涉及復雜搜索條件的命令。不過, 它對于更簡單的情況是正確的。例如,考慮用這樣的命令更新銀行余額:
- BEGIN;
- UPDATE accounts SET balancebalance = balance + 100.00 WHERE acctnum = 12345;
- UPDATE accounts SET balancebalance = balance - 100.00 WHERE acctnum = 7534;
- COMMIT;
如果兩個這樣的事務同時嘗試修改帳號 12345 的余額,那我們很明顯希望第二個事務從賬戶行的已更新版本上開始工作。(這里是考慮第二個update的時候accounts表數據改動了)因為每個命令只影響一個已經決定了的行,讓它看到行的已更新版本不會導致任何麻煩的不一致性。
因為在讀已提交模式中,每個命令都是從一個新的快照開始的,而這個快照包含在該時刻已提交的事務, 因此同一事務中的后續命令將看到任何已提交的并行事務的效果。以上的焦點在于單個命令是否看到數據庫的絕對一致的視圖。
讀已提交模式提供的部分事務隔離對于許多應用而言是足夠的,并且這個模式速度快并且使用簡單。 不過,它不是對于所有情況都夠用。做復雜查詢和更新的應用可能需要比讀已提交模式提供的更嚴格一致的數據庫視圖。
2. 可重復讀隔離級別
可重復讀隔離級別只看到在事務開始之前被提交的數據;它從來看不到未提交的數據或者并行事務在本事務執行期間提交的修改(不過,查詢能夠看見在它的事務中之前執行的更新,即使它們還沒有被提交)。這是比SQL標準對此隔離級別所要求的更強的保證,標準只描述了每種隔離級別必須提供的最小保護。
這個級別與讀已提交不同之處在于,一個可重復讀事務中的查詢看到 事務中第一個非事務控制語句開始時的一個快照, 而不是事務中當前語句開始時的快照。 因此,在一個單一事務中的后續SELECT 命令看到的是相同的數據(就是我前面說的一個事務兩個update那種情況),即它們看不到其他事務在本事務啟動后提交的修改。
使用這個級別的應用必須準備好由于序列化失敗而重試事務。
UPDATE、DELETE、SELECT FOR UPDATE和SELECT FOR SHARE命令在搜索目標行時的行為和SELECT一樣: 它們將只找到在事務開始時已經被提交的行。 不過,在被找到時,這樣的目標行可能已經被其它并發事務更新(或刪除或鎖住)。在這種情況下, 可重復讀事務將等待第一個更新事務提交或者回滾(如果它還在進行中)。 如果第一個更新事務回滾,那么它的作用將被忽略并且可重復讀事務可以繼續更新最初發現的行。 但是如果第一個更新事務提交(并且實際更新或刪除該行,而不是只鎖住它),則可重復讀事務將回滾并帶有如下消息
- ERROR: could not serialize access due to concurrent update
因為一個可重復讀事務無法修改或者鎖住被其他在可重復讀事務開始之后的事務改變的行。
當一個應用接收到這個錯誤消息,它應該中斷當前事務并且從開頭重試整個事務。在第二次執行中,該事務將見到作為其初始數據庫視圖一部分的之前提交的改變,這樣在使用行的新版本作為新事務更新的起點時就不會有邏輯沖突。
注意只有更新事務可能需要被重試;只讀事務將永遠不會有序列化沖突。
可重復讀模式提供了一種嚴格的保證,在其中每一個事務看到數據庫的一個完全穩定的視圖。不過,這個視圖并不需要總是和同一級別上并發事務的某些序列化(一次一個)執行保持一致。例如,即使這個級別上的一個只讀事務可能看到一個控制記錄被更新,這顯示一個批處理已經被完成但是不能看見作為該批處理的邏輯組成部分的一個細節記錄,因為它讀取空值記錄的一個較早的版本。
3. 可序列化隔離級別
可序列化隔離級別提供了最嚴格的事務隔離。這個級別為所有已提交事務模擬序列事務執行;就好像事務被按照序列一個接著另一個被執行,而不是并行地被執行。
但是,和可重復讀級別相似,使用這個級別的應用必須準備好因為序列化失敗而重試事務。事實上,這個給力級別完全像可重復讀一樣地工作,除了它會監視一些條件,這些條件可能導致一個可序列化事務的并發集合的執行產生的行為與這些事務所有可能的序列化(一次一個)執行不一致。這種監控不會引入超出可重復讀之外的阻塞,但是監控會產生一些負荷,并且對那些可能導致序列化異常的條件的檢測將觸發一次序列化失敗。
例如,考慮一個表mytab,它初始時包含:
- class | value
- ------+-------
- 1 | 10
- 1 | 20
- 2 | 100
- 2 | 200
假設可序列化事務 A 計算:
- SELECT SUM(value) FROM mytab WHERE class = 1;
并且接著把結果(3)作為一個新行的value插入,新行的class = 2。同時,可序列化事務 B 計算:
- SELECT SUM(value) FROM mytab WHERE class = 2;
并得到結果 300,它會將其與class = 1插入到一個新行中。然后兩個事務都嘗試提交。如果其中一個事務運行在可重復讀隔離級別,兩者都被允許提交;但是由于沒有執行的序列化順序能在結果上一致,使用可序列化事務將允許一個事務提交并且將回滾另一個并伴有這個消息:
- ERROR: could not serialize access due to read/write dependencies among transactions
這是因為,如果 A 在 B 之前執行,B 將計算得到合計值 330 而不是 300,而且相似地另一種順序將導致 A 計算出一個不同的合計值。
當依賴可序列化事務來阻止異常時,重要的一點是任何從一個持久化用戶表讀出數據都不被認為是有效的,直到讀它的事務已經成功提交為止。即便是對只讀事務也是如此,除了在一個可推遲的只讀事務中讀取的數據是讀出以后立刻有效的,因為這樣的一個事務在開始讀取任何數據之前會等待,直到它能獲得一個快照保證來避免這種問題為止。在所有其他情況下,應用不能依靠在一個后來被中斷的事務中讀取的結果;相反,它們應當重試事務直到它成功。
要保證真正的可序列化,PostgreSQL使用了謂詞鎖,這意味著它會保持鎖,這些鎖讓它能夠判斷在它先運行的情況下,什么時候一個寫操作會對一個并發事務中之前讀取的結果產生影響。在PostgreSQL中,這些鎖并不導致任何阻塞,并且因此不會導致一個死鎖。它們被用來標識和標志并發可序列化事務之間的依賴性,這些事務的組合可能導致序列化異常。相反,一個想要保證數據一致性的讀已提交或可重復讀事務可能需要拿走一個在整個表上的鎖,這可能阻塞其他嘗試使用該表的用戶,或者它可能會使用不僅會阻塞其他事務還會導致磁盤訪問的SELECT FOR UPDATE或SELECT FOR SHARE。
像大部分其他數據庫系統,PostgreSQL中的謂詞鎖基于被一個事務真正訪問的數據。這些謂詞鎖將顯示在pg_locks系統視圖中,它們的mode為SIReadLock。這種在一個查詢執行期間獲得的特別的鎖將依賴于該查詢所使用的計劃,并且在事務過程中多個細粒度鎖(如元組鎖)可能和少量粗粒度鎖(如頁面鎖)相結合來防止耗盡用于跟蹤鎖的內存。如果一個READ ONLY事務檢測到不會有導致序列化異常的沖突發生,它可以在完成前釋放其 SIRead 鎖。事實上,READ ONLY事務將常常可以在啟動時確立這一事實并避免拿到任何謂詞鎖。如果你顯式地請求一個SERIALIZABLE READ ONLY DEFERRABLE事務,它將阻塞直到它能夠確立這一事實(這是唯一一種可序列化事務阻塞但可重復讀事務不阻塞的情況)。在另一方面,SIRead 鎖常常需要被保持到事務提交之后,直到重疊的讀寫事務完成。
可序列化事務的一致性使用可以簡化開發。并發可序列化事務的任意集合將得到和一次運行一個相同效果的這種保證意味著,如果你能證明一個單一事務在獨自運行時能做正確的事情,則你可以相信它在任何混合的可序列化事務中也能做正確的事情,即使它不知道那些其他事務做了些什么。重要的是使用這種技術的環境有一種普遍的方法來處理序列化失敗(總是會返回一個 SQLSTATE 值 '40001'),因為它將很難準確地預計哪些事務可能為讀/寫依賴性做貢獻并且需要被回滾來阻止序列化異常。讀/寫依賴性的監控會產生開銷,如重啟被序列化失敗中止的事務,但是作為在該開銷和顯式鎖及SELECT FOR UPDATE或SELECT FOR SHARE導致的阻塞之間的一種平衡,可序列化事務是在某些環境中最好性能的選擇。