













這個世界,又多了一點抽象!
本文轉載自微信公眾號「小姐姐味道」,作者小姐姐養的狗。轉載本文請聯系小姐姐味道公眾號。
首先,我對群里這個動圖心情十分復雜。又愛又恨。
然后,我們來到正題。
如果你常年在處理一些日志、監控方面的東西,一定會在一定程度上聽過OpenTracing,像 Zipkin、Jaeger、SkyWalking都對其有很好的支持。
但是可惜,OpenTracing已經成為過去式了,現在的APM世界,由一種叫做OpenTelemetry的規范所統治。
那是因為,作為一個標準,OpenTracing遇到了對手。
1. 小歷史
很多同學已經開始喊了,我的OpenTracing還沒學熱乎呢,現在直接被凍結了。這要怪google。
OpenTracing誕生于2016年11月,CNCF接受了它,成為自己基金會的第三個項目。但是google并不認為這個東西是標準,所以推出了自己的OpenCensus規范。
CNCF是什么呢?cn并不是中國的意思,它的全稱是Cloud Native Computing Foundation,是Linux基金會旗下的基金會,可以理解為一個非盈利組織。當年google就把自己的k8s捐獻給CNCF。
眾所周知,Prometheus出自google之手,已經成為監控界事實上的規范。再加上市面上的APM都是出自Dapper這篇論文,所以google的這個規范,自然會被引起重視。而且OpenCensus除了調用鏈追蹤之外,還加上了度量指標,所以功能上更豐富一些。
這可苦了開發者。難道一個技術場景需要兩種規范?
終于在2019年,兩者和解,共同推出了OpenTelemetry,Telemetry是遙測術的意思,可以看到它的野心是非常大的。
2. OpenTelemetry包含什么?
關于日志、監控和調用鏈,兩年之前,我曾畫過一張圖,但從中只能看到有哪些組件參與,只看圖是模棱兩可的。整個體系就是收集、處理、應用這大三類數據(logs、metrics、trace)。
時至今日,情況又有一些改變。目前的主流方案,是Promethus,加Grafana,加Telegraf(或者各種export),加Loki(ELKB),加Skywallking等。使用者需要了解多個系統,并給出有效的集成方案。
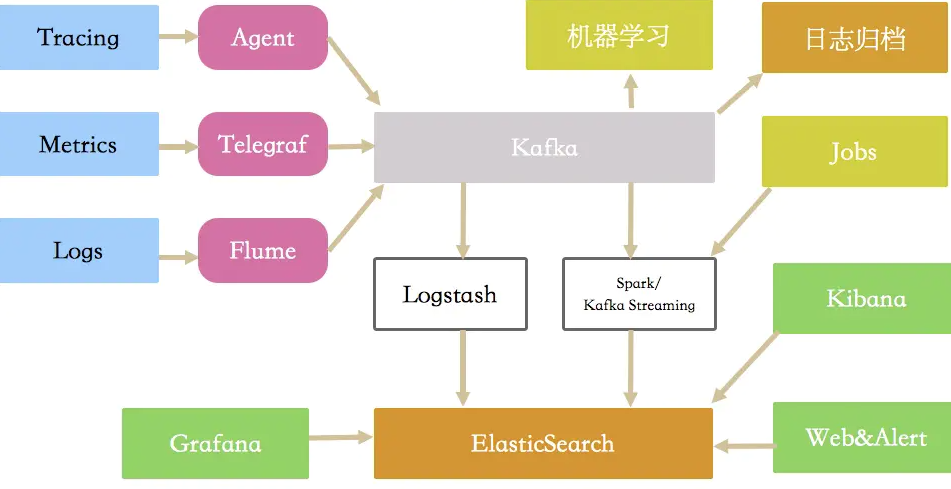
具體的數據流轉和處理,每種結構都不盡相同,這也是為什么我一直強調分而治之的原因。但使用方式上,最好相差不要太大。無論后端的架構如何復雜,一個整體的外觀將讓產品變得更加清晰,你目前的工作,是不是也集中在此處呢?
上面的是xjjdog的原話,代表了作為一個使用者和規范的實踐者,對于這三類數據(指標、日志、調用鏈)的迷思。現在這種情況,有所改善。因為OpenTelemetry規范,就想要把這些技術指標,全部囊括進來。它是一種廠商獨立的規范和一組工具,可以讓開發者變得更加幸福。但規范本來就不是一件容易的事,直到2021.02.10,OpenTelemetry 的1.0版本才算完成。
看一下OpenTelemetry 的官網吧,https://opentelemetry.io/。解決的,正是這些。
- Traces 就是傳統調用鏈的樹
- Metrics 運行時所抓取的指標值或計算的統計值,隨著時間流逝會有不同
- Logs 日志,比如異常日志或者額外附加信息
信息處理,當然也離不開采集、處理、展示三個階段。
可以看到,相對于OpenTracing,多了Metrics這樣的監控指標。隨著分布式系統存儲能力和計算能力的增加,我們有可能把這些信息放在一塊了!由于提供了專用的sdk,統一的協議,以前難搞的跨平臺,現在也不在話下。
關于日志監控等等,可以看xjjdog以前的文章。
《主流監控一梭子》
3. 如何使用?
在使用之前,需要先搞懂幾個術語。對于熟悉OpenTracing的同學來說,這都不叫事。
- Traces 調用鏈,一個trrace包含多個Span。由root span,parent span和當前的span組成一棵樹
- Metrics 指標,包含Counter、ValueRecorder、SumObserver、ValueObserver等常見的應用場景
- Context 每個span所包含的上下文信息,是一個全局唯一的標識
- Context propagation propagation是傳播的意思,它表示不同的服務之間的上下文傳遞。
OpenTelemetry的定義文件,是使用protobuf來描述的,所以天然具有跨平臺性。信息的收集,有一個叫做opentelemetry-collector的組件來完成,它本質上是一個pipelines,這像極了kafka streaming等流式處理軟件,也像極了logstash和flume這樣的日志處理軟件。
技術翻來覆去,來來回回,新瓶裝舊酒而已。
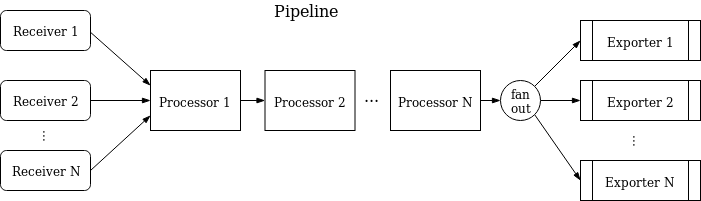
一個典型的配置文件可能如下:
- service:
- pipelines: # section that can contain multiple subsections, one per pipeline
- traces: # type of the pipeline
- receivers: [otlp, jaeger, zipkin]
- processors: [memory_limiter, batch]
- exporters: [otlp, jaeger, zipkin]
其中包含三部分,receivers、processors、exporters。
- receiver 這個的意思是怎么把其他平臺的數據搞到自己的體系里來。比如接收特定的prometheus數據,然后轉化成內循環的數據
- processor 這些內循環數據就可以被processor處理,你可以在這里對數據進行一些更改,當然配置是一如既往的麻煩
- exporter 想要把這些信息發送到什么平臺去。實現了OpenTelemetry規范的組件,很容易的接收這些數據ba
這走的還是傳統的三段式思路,不過在telegraf里,叫做input、output而已。不過也不用擔心,廠商為了證明自己的系統符合標準,會主動去開發這些receiver和exporter。
接下來就好辦的多了。各個版本的SDK,提供各種指標的API,對接平臺就可以了。
3. 如何體驗一下?
官方倒是有個例子,也省了我去做了。
- https://opentelemetry.io/docs/java/instrumentation_examples/
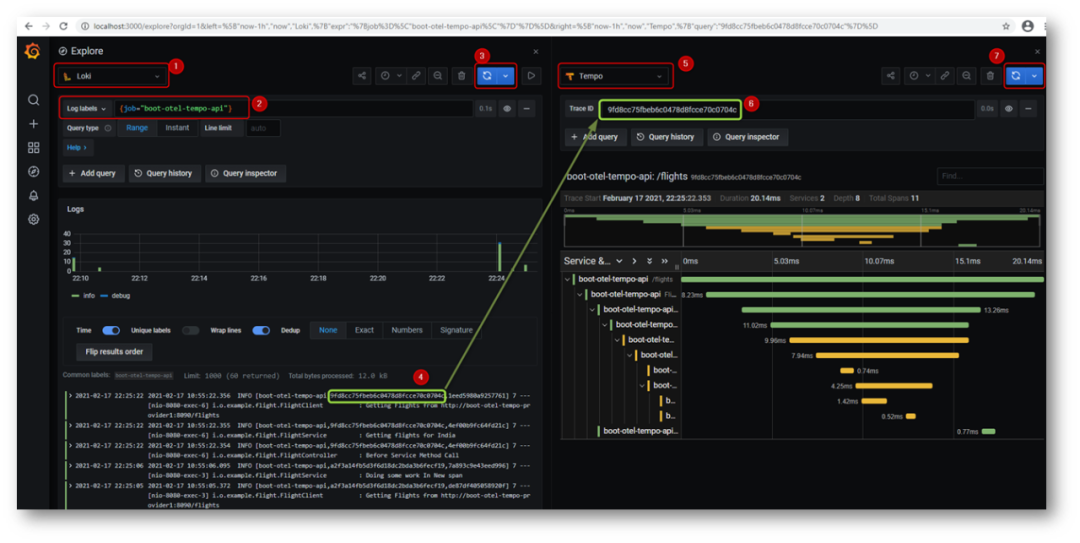
它使用了Prometheus、Loki、Tempo、Grafana等組件,并使用springboot應用做了應用示例。可以看到,里面用了這么多的組件,自己搭建費時費力費腦子,走docker是最好的方式。
事實上,也是如此。
采用下面兩步,即可完成部署。
- mvn clean package docker:build
- docker-compose up
嗯,很好看,也很好用。祝愿規范加快試試吧,因為目前有部分組件還是alpha版本。
作者簡介:小姐姐味道 (xjjdog),一個不允許程序員走彎路的公眾號。聚焦基礎架構和Linux。十年架構,日百億流量,與你探討高并發世界,給你不一樣的味道。我的個人微信xjjdog0,歡迎添加好友,進一步交流。















