針對數據庫變更的持續集成與交付
譯文
【51CTO.com快譯】近年來,一種被稱為DevOps的軟件工程文化已悄然在許多組織中流行起來。它旨在統一軟件開發(Dev)和IT運營(Ops),并且通過持續集成(CI)和持續交付(CD)兩個主要概念,在軟件工程的實踐中倡導自動化。如今,許多應用開發團隊都能夠從此類敏捷開發的實踐中實現:頻繁的軟件交付,盡早地收到客戶的反饋,擁有組織內跨職能的團隊,更快地讓產品面市,以及保持客戶的滿意度。
不過傳統的數據庫手動變更管理過程,正在逐漸成為持續交付的瓶頸。對此,本文將重點討論如何將其簡化到應用代碼的統一交付管道中。
持續集成
作為敏捷開發過程的核心原則之一,持續集成強調的是確保由團隊內多個成員所開發出的代碼,能夠順暢實現集成,進而避免出現各自為政的“集成地獄”。它主要涉及到獨立且自動化的構建、以及自動化的測試。可以說,持續集成促進了以測試為驅動的開發,以及對版本控制系統的基線、主分支、主干(trunk)的頻繁“原子性”提交的實踐。
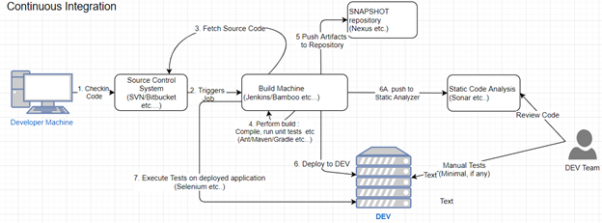
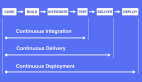
圖1:典型的持續集成過程
如上圖所示,開發人員一旦將代碼簽入源控制系統,就會觸發在持續集成服務器中的配置構建作業。該作業將從版本控制系統中簽出代碼,進行構建,執行測試,并將生成的工件(如jar文件),部署到工件存儲庫(artifact repository)中。一部分定時觸發的CI作業,則會將代碼部署到開發環境中,將詳細信息推送到靜態分析工具中,對已部署的代碼、或團隊認為實用的自動化過程進行系統測試,進而確保代碼庫的運行狀況良好。同時,敏捷團隊有責任確保上述自動化流程在出現任何失敗時,能夠暫緩代碼的提交,直至自動化的構建被修復。
持續交付
持續交付除了需要確保軟件系統中的不同模塊能夠被始終集成之外,還要確保代碼能夠始終被部署到生產環境中。這意味著,系統除了擁有自動化的構建和測試套件之外,還具有自動化的交付過程。通常,我們只需單擊按鈕,便可在幾分鐘之內完成軟件的部署。同樣作為DevOps的核心原則,持續交付的優勢包括:可預測的部署,降低引入新功能的風險,縮短客戶反饋的周期,以及提高軟件的總體質量。
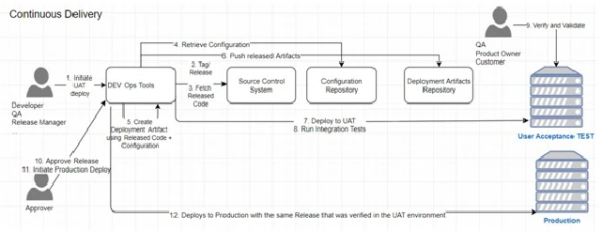
圖2:典型的連續交付過程
“持續交付”的過程往往基于“持續集成”過程之上。上圖包含了用戶驗收測試(UAT)和生產兩種環境。不過,在軟件進入生產環境之前,不同的組織可能會設有諸如:質量保證(QA)、負載測試、預生產等多個staging(模擬)環境。當然,所有staging環境和生產環境的部署,都是通過相同的自動化過程來執行的,并且采用的是不同環境的相同版本代碼庫。我們可以使用多種工具來實現配置的自動化、受控、可重復、可靠、可審核、以及可逆(或稱可回滾)。
數據庫變更管理的瓶頸問題
不可否認,幾乎所有的項目除了交付已開發的應用代碼,也會涉及到諸如schema(結構模式)變更等與數據庫相關的工作。目前,我們認為在數據庫的開發領域尚未采用敏捷原則,或實現持續集成。因此,此類數據庫的相關工作會或多或少地拖慢整個軟件產品的交付進程。
讓我來看一個真實的案例。某開發團隊通過遵循Scrum的敏捷方式,進行了2周的sprint(迭代)。當前的一條story(故事線)是在文檔中添加一個能與下游系統交互的新字段。開發團隊估計:就代碼開發而言,業務事件觸發應用會將文檔發送到下游系統,以及后期的檢索系統,這些僅涉及到數據訪問層中的微小變更。因此,如果不涉及數據庫(本例為關系數據庫管理系統)的變更,這個僅向現有數據表中添加新列的story,很容易在當前的sprint中被實現。但是,正是因為涉及到數據庫的修改,開發團隊可能會對此類迭代的可行性缺乏信心。
這是為什么呢?其原因在于,他們需要將架構的變更請求發送給數據庫管理員(DBA)。而DBA將會花時間去確定該變更請求的優先級,并將它與從其他開發團隊處收到的變更請求進行比較。而在開發數據庫完成了變更以后,DBA則會通知開發人員,并等待他們的反饋,以便將變更推廣到QA或其他階段的環境中。同時,開發人員將測試新架構中代碼的變更。最后,通過開發團隊與DBA的緊密協調,將應用的變更和數據庫的變更共同交付到生產環境中。
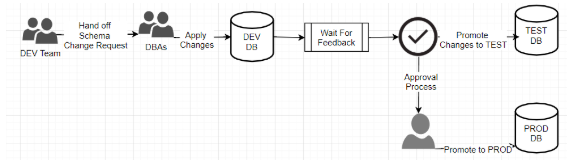
圖3:交付數據庫變更的手動與半自動過程
值得注意的是,在上圖中,該過程并非由開發人員檢入代碼而觸發的,而是需要兩個團隊之間的交互。也就是說,即使數據庫側的部署過程是自動化的,也無法與應用代碼的交付管道集成在一起。雖說應用代碼的變更在某種程度上直接取決于數據庫的變更,但是這兩個變更的生命周期是完全相互獨立的。
下面,讓我們來討論如何將那些與數據庫變更相關的工作(包括數據建模和schema變更等)置于CI/CD過程的范疇之內。
DBA應該成為跨職能敏捷團隊的一部分
許多組織會根據:協助建立應用開發的數據庫,以及維護生產環境的數據庫,來區分DBA的角色。其中,服務于生產環境的DBA的主要職責是:通過監控數據庫,處置升級與補丁,分配存儲空間,執行備份與恢復等,以確保生產環境中數據庫的可用性。而開發類DBA需要與應用開發團隊緊密合作,估計存儲需求,并協助他們進行數據模型的設計,將邏輯模型轉換為數據庫的物理schema等。
可見,為了將數據庫的工作和應用開發工作整合到一個交付管道中,我們勢必讓開發類DBA成為開發團隊的一部分,并由具有良好數據庫知識的全棧開發人員來擔任。
數據庫作為代碼(Database As Code)
為了實現將數據庫變更和應用代碼集成到單個管道中,我們需要對數據庫中的每一項變更編寫腳本,并對其予以版本控制,進而按需通過腳本自動建立一個新的數據庫實例。如果我們必須將數據庫的對象捕獲為代碼,那么需要根據腳本(即代碼)的類型,對數據庫進行評估與分類。具體區別標準如下:
數據庫結構:
就是我們經常提到的schema(模式),它定義了數據庫存儲數據的結構,其中包括針對表、視圖、約束、索引和類型的定義。數據字典也可以被視為數據庫結構的一部分。
已存儲的代碼:
它們與應用代碼非常相似,其不同之處在于,它們被存儲在數據庫中,并由數據庫引擎來執行。它們包括:存儲過程、函數、程序包、以及觸發器等。
參考數據:
它們通常存儲著被其他業務數據表所引用的一組允許值(permissible values)。在理想情況下,參考數據表中幾乎沒有數據記錄。它們只有在某些業務流程發生變更時,才可能跟著變化,而在正常業務過程中是不會發生變更的。
應用數據或業務數據:
它們是應用程序在正常業務過程中產生的數據記錄,這是任何數據庫被加入到應用系統的主要目的。
總的說來,在以上四種類型的數據庫對象中,前三種可以并且應該被捕獲為腳本,進而被存儲在版本控制系統中。
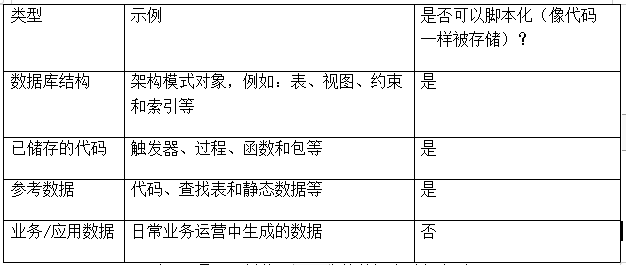
表1:是否可被編寫為腳本的數據庫對象類型
如上表所示,業務或應用數據是唯一不能被腳本化、或存儲為代碼的類型。所有回滾、修改、歸檔等都是由數據庫本身來執行的。唯一例外的是,當schema變更導致數據發生遷移時(例如,填充了新的列,或將數據從基表移至規范化表中),遷移腳本將被視為代碼,并且應當遵循與schema變更相同的生命周期。
下面,讓我們以一個簡單的數據模型為例(您可以認為數據建模的“Hello World”),來說明如何將腳本存儲為代碼。
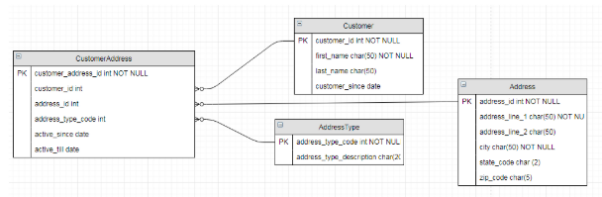
圖4:該示例模型中包含了業務數據表和參考數據表
在上述模型中,客戶可能與諸如:帳單地址、送貨地址等多個地址相關聯。AddressType表存儲了諸如:帳單、送貨、住所、工作等不同類型的地址。存儲在AddressType中的數據可以被視為參考數據,畢竟它們在日常業務運營中不會有激增。而其他包含著業務數據的表,會隨著客戶的增多,而繼續增長。
下面是各種示例腳本:
表:

限制條件:
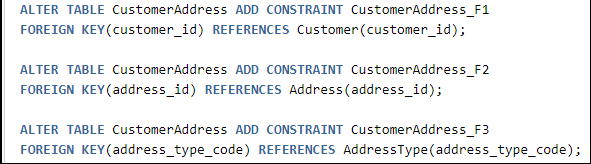
參考數據:

由上述示例可知,除了業務數據,其他所有的數據庫對象都能夠被捕獲到SQL腳本中。
與應用代碼位于同一存儲庫中的版本控制數據庫工件:
將數據庫工件與應用代碼保存到版本控制系統的同一存儲庫中,有著諸多好處。由于在大多數情況下,數據庫schema的變更往往會涉及到應用代碼的變更,因此將它們標記為共同發布,可以避免應用代碼和數據庫出現不同步的狀況。同時,由于與項目相關的所有內容都放在了一處,因此新的團隊成員可以更加輕松方便的獲悉與查閱,進而加快了工作效率。
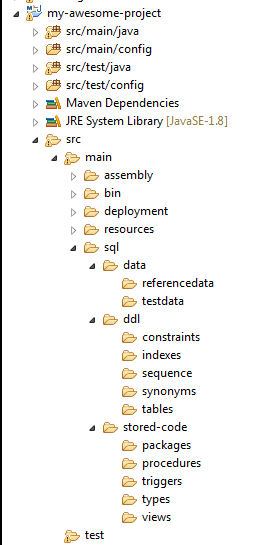
圖5:包含了數據庫代碼的Java Maven項目的結構示例
上面的目錄結構展示了如何在Java Maven項目中,將數據庫腳本與應用代碼一起存儲。當然,這對于Ruby或.Net等應用,也是通用的。CI/CD自動化工具可以在同一處找到它們,并對其執行諸如:從頭開始構建架構、生成遷移、以及產生部署腳本等必要的操作。
將數據庫工件集成到構建腳本中:
為了確保數據庫的變更能夠與同一交付管道中的應用代碼“齊頭并進”,我們在構建的過程中包含數據庫腳本是非常必要的。通常,數據庫工件是某種形式的SQL腳本,而且大多數主流構建工具都能夠支持本地、或通過插件的方式執行SQL腳本。
在此,讓我們先討論在本地環境、或CI服務器中的構建,稍后再涉及到暫存環境。其中包括的典型任務包括:
- 刪除Schema。
- 創建Schema。
- 創建數據庫結構(或Schema對象),包括表、約束、索引、序列和同義詞。
- 部署已存儲的代碼,包括過程、函數、以及包等。
- 加載參考數據。
- 加載測試數據。
構建工具可以確保數據庫在加載已知數據集時處于穩定的狀態,并且通過充分的集成測試,以避免出現應用代碼與數據模型的不同步。這是在數據庫變更管理過程中,實現持續交付模型的第一步。
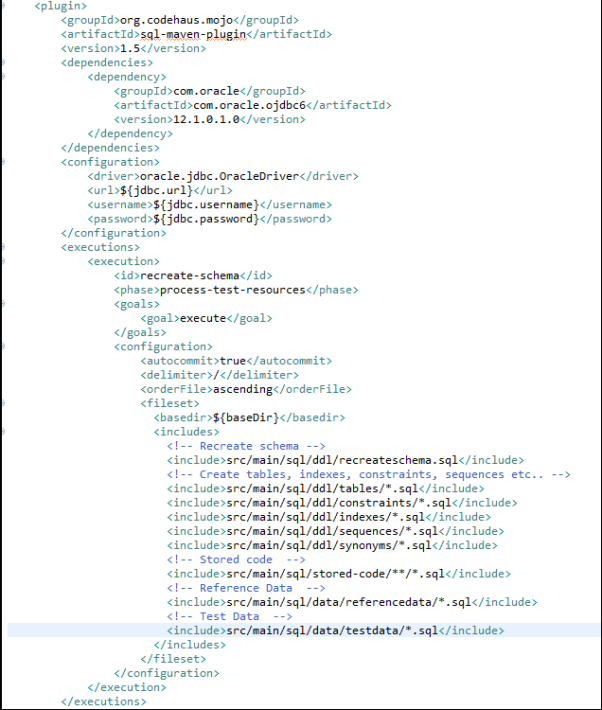
圖6:該代碼片段展示了用于運行數據庫腳本的Maven構建
上面的代碼截圖說明了如何使用Maven插件來運行SQL腳本。它能夠刪除與重建schema,并通過運行所有的DDL腳本,來創建表、約束、索引、序列和同義詞。接著,它將所有已存儲的代碼部署到數據庫中,并最后加載所有的參考數據和測試數據。
避免共享數據庫
讓多個應用共享一個數據庫schema并非一個好主意。除非數據庫真正屬于某個應用、且不被其他應用所共享,否則將應用代碼和數據庫變更置于同一交付管道下,將難以達到預期的效果。同時,共享數據庫還會導致應用之間的緊密耦合、以及許多其他問題。
讓每個提交和CI服務器都能專享Schema
開發人員總希望能夠在自己的“沙箱”中工作,而不必擔心諸如開發數據庫實例之類通用環境等問題。而CI服務器就是這樣的沙箱,它遵循了如何開發應用代碼的模式。開發人員可以執行各種變更,在本地運行構建,并且在構建成功且測試通過后,再提交變更。通常,此類沙盒既可以是在開發人員本地電腦上、已安裝的獨立數據庫實例,也可以是共享數據庫實例中的其他架構。
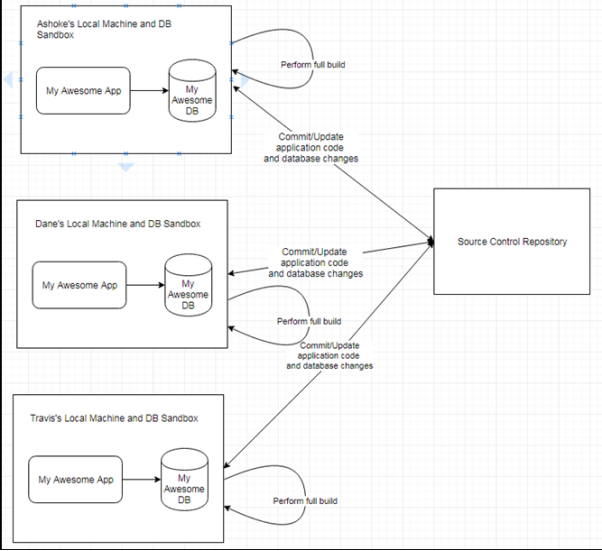
圖7:開發人員在其本地環境中進行頻繁的變更與提交
如上圖所示,每個開發人員都擁有自己的schema副本。在執行完成構建之后,除了構建應用,它還會從頭開始構建數據庫的schema。其中包括:刪除與重建schema,執行DDL腳本,以加載所有的schema對象(如:表、視圖、序列、約束和索引)。同時,它會創建代表著已存儲的代碼對象,其中包括:函數、過程、包和觸發器。最后,它將加載所有的參考數據和測試數據。而自動化的測試則可確保應用代碼和數據庫對象始終同步。值得注意的是,由于數據模型的變更不如應用代碼那樣頻繁,因此出于構建性能的考慮,我們應當讓構建腳本應具有跳過數據庫構建的選項。
其實,CI構建作業也應當被設置為帶有自己的數據庫沙箱。畢竟,構建腳本會執行完整的構建,其中就包括了構建應用,以及從頭開始構建數據庫的schema。而且,它會運行一整套的自動化測試,以確保應用本身、及其與之交互的數據庫能夠保持同步。

圖8:修改后的CI流程,集成了數據庫構建和應用代碼的構建
上圖中描述的過程與圖1中的過程較為相似。CI服務器包含了在對存儲庫提交時觸發的構建作業。它所執行的構建包含了應用和數據庫的構建。至此,數據庫腳本就能夠被整合為應用代碼了。
處置遷移
我們在前文中已經討論了如何針對持續集成和本地環境,從頭開始構建數據庫的schema對象、已存儲的代碼、參考數據和測試數據。那么對于生產環境中的數據庫、以及QA或UAT環境又該如何處理呢?
鑒于數據庫的本質就是為了支持業務數據,我們不可能對當前正在運行的業務交易數據庫,采取刪除schema、或從腳本中重建等操作。因此,我們需要編寫增量腳本,也就是將數據庫的結構從已知的狀態(所謂“軟件定制版”)變更過渡,或將數據遷移到所需的狀態。例如,為了標準化,我們可能需要通過腳本將一個表中的數據遷至一到多個子表中。而schema的變更,則可以在源代碼存儲庫中,通過腳本的編寫,使其成為構建的一部分。這些腳本既可以在主動開發的過程中手工被編寫,也可以由一些自動化工具來完成。其中的一種工具是Flyway,它可以生成遷移腳本,將數據結構從一種狀態轉換為另一種狀態。Schema的變更可以在源代碼存儲庫中被編寫腳本并進行維護,以使它們成為構建的一部分。

圖9:schema遷移與回滾的自動化
在上圖中,左側顯示了與應用先前版本(1.0.1)同步的數據庫狀態。右側顯示了數據庫所需的下一版本狀態。我們在版本控制系統中既可以捕獲并標記左側的狀態,又可以將捕獲到的右側狀態作為基線、主分支或主干。兩者之間的區別正是我們需要讓數據庫在staging環境和生產環境中保持不同的狀態。上圖展示了Flyway工具通過創建遷移腳本,將數據庫從先前的版本過渡到新的版本;以及通過回滾腳本,將數據庫過渡回先前版本的自動化過程。這些生成的腳本將會被標記,并與其他部署工件一起被存儲。因此,我們通過將該自動化過程與持續交付的過程相集成,以確保可重復、可靠、且可逆(通過回滾)的數據庫變更。
將數據庫變更并入連續交付
現在,我們可以將上述各部分整合到一起了,即:通過一個現有的持續集成過程,來重建數據庫和應用代碼;通過一個并入部署工件的過程,為數據庫生成遷移腳本。DevOps工具將使用這些已發布的工件,來構建任何staging環境或生產環境。該部署工件還將包含回滾腳本,以便在出現任何問題時,我們都可以重新部署應用的先前版本,通過運行數據庫的回滾腳本,將數據庫的schema轉換為與應用代碼的先前版本相同步的狀態。
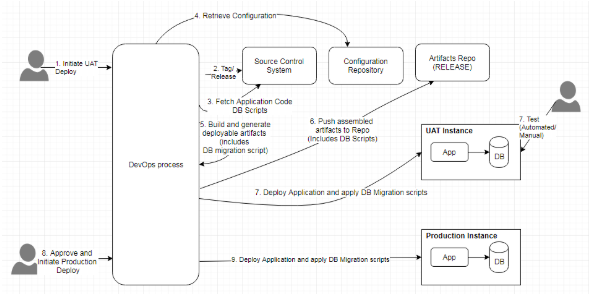
圖10:包含了數據庫變更的持續交付
上圖描述了將數據庫變更管理并入持續交付的過程。此處假設已經存在一個持續集成過程。在啟動了UAT(或測試、QA等其他staging環境)的部署后,自動化流程將負責在源代碼控制存儲庫中創建標簽,并從帶標簽的代碼庫中構建可部署的應用工件,生成數據庫遷移腳本,組裝工件,并執行部署。整個部署的過程包括:應用的部署,以及將遷移腳本應用到數據庫中。按照審批流程,應用程序會通過相同的工件被部署到生產環境中。若要回滾至先前版本,則需重新部署應用程序,并運行數據庫的回滾腳本。
市場上的可用工具
前面我們主要介紹了如何在涉及數據庫變更的項目中,實現CI/CD的過程。而在實踐中,我們往往會根據不同的需求,使用不同的工具,例如:針對構建自動化的Maven或Gradle,針對持續集成的Jenkins或TravisCI,以及針對配置管理的Chef或Puppet等本地解決方案。下面,我為您羅列出針對數據庫DevOps的自動化通用工具:
小結
誠然,持續集成和持續交付的流程為組織帶來了諸如:縮短產品的面市時間,可靠的發布,以及提高軟件整體質量等巨大的好處。鑒于手動執行數據庫變更管理會帶來的交付瓶頸,本文和您討論了如何將數據庫的變更,帶入與應用代碼相同的交付管道中,以及市場上能夠配合此類實踐的各種實用工具。
原文標題:Continuous Integration and Continuous Delivery for Database Changes,作者: Ashoke Bhowmick
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】