運維絕不是背鍋、填坑和救火,價值在于持續集成與交付!
原創【51CTO.com原創稿件】運維能交付的價值不是背鍋,填坑和救火,主動應對變化和風險是做好運維的一個重要能力。
魅族運維團隊通過構建持續集成云端交付平臺提高應對變化的能力,實現主動應對變化提高效益的價值目標,向用戶以及產品團隊提供高效的交付體驗。通過這段自研歷程,希望能給大家帶來些啟示。
2017 年 12 月 01 日-02 日,由 51CTO 主辦的 WOTD 全球軟件開發技術峰會在深圳中州萬豪酒店隆重舉行。
本次峰會以軟件開發為主題,魅族資深架構師古日旗在創新運維探索專場與來賓分享"魅族持續集成云端交付之路"的主題演講,為大家帶來魅族在運維自動化建設的探索以及實踐經驗。
本次分享分為三個部分:
- 自動化建設歷程
- 持續集成及云端交付
- 展望運維智能化
自動化建設歷程
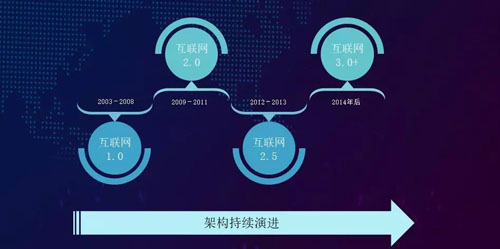
魅族持續集成的建設背景,如上圖:
- 2003 年到 2008 年,互聯網 1.0 時代。我們的互聯網業務還僅限于官網和 BBS,服務端即為 PHP + MySQL。
- 2009 年到 2011 年,互聯網 2.0 時代。我們這時有了真正意義上的服務端和運維的工作,包括:LVS 的架構模式和主從復制的數據庫設計。但是我們的各個業務仍然運行在單個 IDC 上。
- 2012 年到 2013 年,互聯網 2.5 時代。在互聯網業務方面,我們增加了應用中心、多媒體、和 O2O 等。
在架構方面,我們將主從復制的數據庫進行了分庫、分表,和路由選擇。
在緩存方面,我們引入了 Redis 集群,并且增添了分布式的存儲 MFS(MooseFS)。
與此同時,一些相應的支撐服務也隨之出現,如搜索引擎、各種 MQ(Message Queue)等。
- 到了 2014 年,邁入互聯網 3.0 時代。這個時代一個重要的里程碑就是:我們的互聯網業務已經成為了主營業務之一。
發展給運維帶來的挑戰
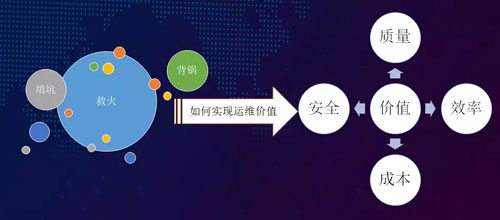
在從互聯網 1.0 到 3.0 的演變過程中,隨著業務的急速增長,我們的運維面對了各種挑戰,主要從質量、效率、成本、安全四個方面來進行解析。
質量方面,衡量質量的最佳方式是看它的可用性指標。一般我們分為直接和間接兩種。
直接指標,我們可以從監控上看到網絡、服務、應用、以及系統的可用性;間接指標,我們可以對標一些體驗性的參數,比如說運行速度;也可以對標一些業務上的參數,比如說手機短信的到達率。
我們的業務可用性曾經非常低,沒有一個完善的監控體系。同時我們的監控狀態也比較混亂,不但覆蓋率較低,而且經常會造成一些誤報、漏報、錯報等狀況。這些直接導致了整個監控的不可相信。
效率方面,效率是衡量運維平臺功能性的標準,主要體現為服務器的交付,線上的各種變更,以及我們對故障的及時發現水平。我們頻繁地交付和變更,卻沒有將流程與自動化結合起來,因此整體效率低下。
成本方面,主要體現在業務的總體調度,和交付能力的改進與優化。由于我們的流程不完善、工作不透明,導致了某個業務到底需要多少容量完全無法評估。因此“填坑”、“救火”、“背鍋”就成了我們運維的“家常便飯”。
安全方面,是整個互聯網產品的生命基線。所以在早期產品研發的過程中,我們就制定了一些安全的規范和制度。
隨后又建立了一套比較完善的安全體系,從而通過系統、數據和應用等維度,來體現團隊對于安全問題的管控程度。
運維平臺現狀
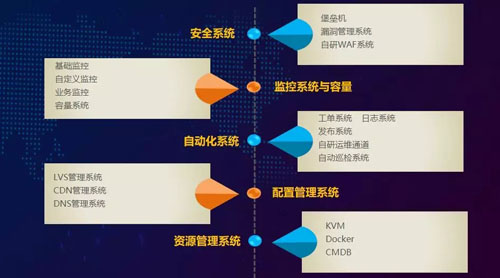
我們以價值為導向建立了一系列的系統。從功能上來看,主要分成以下幾個系統:
- 資源管理系統,我們通過 KVM + Docker 建立了一個云平臺。基于該云平臺,我們組建了一個虛擬化計算與網絡的資源管理系統,并通過 CMDB 進行管控。
- 配置管理系統,我們擁有 LVS、CDN、DNS 等管理系統。同時我們對外開放了一些 API,這樣做的好處在于可以精細化其相應的權限,從而實現所有的操作都能在我們的系統上得到管控。
- 自動化系統,我們有工單、日志、發布、自研運維通道、以及自動巡檢系統。這些都能為運維的交付和變更提供效率上的提升。
- 監控和容量系統,我們有基礎監控、自定義監控、業務監控、和容量系統。容量系統既可以幫我們評估某個業務到底需要多少資源,又可以針對該業務實現成本上的管控。
- 安全系統,我們所有的運維都是通過堡壘機進行登錄的。此舉可方便我們審計用戶的各種操作。
通過自研的 WAF 系統和漏洞管理系統,我們可以自主地發現攻擊和各個漏洞。然后進一步將漏洞信息導入到漏洞管理平臺中,進行迭代、修復、與跟蹤。
發布平臺演進
我們的發布平臺經歷了周發布、日發布和自助發布三個發布歷程。由于業務剛開始時較簡單,我們當時采用的是手動方式。
后來隨著業務的大幅增長,手動操作不得不被自動化工具所取代。比如:我們用自動化工具向服務器下發各種命令、腳本、以及任務。
這樣雖然解決了一些問題,但是其整體的發布效率仍比較低下,而且成功率也不高。
針對此問題,我們在發布平臺將 CMDB 的“業務樹”與業務模塊進行了關聯,并制定出了發布的一些相關規范和指標,從而提升了發布的成功率和容錯性。
為了把發布做得更為靈活,我們把權限下發到了各個業務部門,由各個業務部門的負責人來進行審核。如此一來,我們的整個發布過程就不需要運維的參與了。
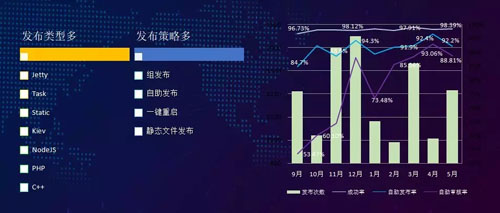
我們來看當前的發布平臺現狀。我們的特點是發布策略比較多,有自主發布、一鍵重啟、靜態文件發布等。
同時,支持的發布類型也比較多,常見的有 Jetty、task、chef、PHP、C++ 等。
如圖所示,我們發布的成功率一直都能保持在 98% 以上,而我們的自助發布率也是在持續增長中。在發布的過程,我們有超過 90% 的業務不需要運維的參與。
交付流程
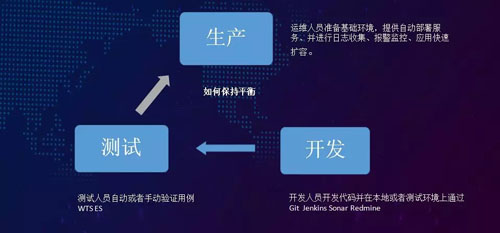
我們的交付流程可分為開發、測試和生產三個環境。開發,是在本地編寫代碼,通過自測、然后再提交到頁面。
通過 Jenkins 的打包,然后再到 WTS Redmine。這樣的測試就會進行一次測試環境的部署,然后再進行一些自動或者手動的驗證。
而我們在對生產環境進行運維時都會準備一些基礎性的環境,以提供給那些自動部署的服務進行各種日志的搜集、報警監控、和應用的快速擴容等。
這里存在著一個微妙的平衡:它要求我們有一套比較完善的技術環境,而且負責自主框架的人員應當盡可能地穩定。
這樣有利于我們擁有良好的文檔和技術上的沉淀。否則一旦該平衡被打破,如一些流程沒有被遵守、或是我們的相關人員出現離職、又或者我們的框架更新太快,都會導致整個交付變得不可完成。
那么在交付過程中,存在過哪些問題呢?我們總結如下:
- 在質量上,我們發現有些代碼未完成單元測試,我們需要統計其相應的覆蓋率和 Bug 數量。
- 在效率上,自動化部署、自動化測試和自動化構建這些都服務分散在不同的職能部門,造成了“圍墻”未被打通,因此我們也無法做到精細化的運營。
- 溝通的成本高,交付變得很復雜。
- 我們的代碼是否安全,是否能通過安全測試,這些都需要予以解決。
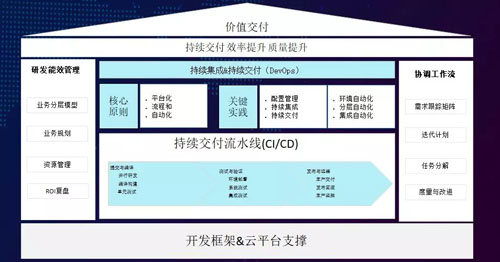
那么我們追求的是一個什么樣的價值框架呢?如圖所示,最下面是一個開發框架平臺。
首先我們的云平臺需要實現落地環境的自動化,這樣就可以保證我們所交付出去的環境都是標準化的。
其次是整體開發框架,我們的技術委員會持續推行基礎性的開發框架、及架構,從而保證我們擁有一套基礎性的技術棧,和一個環境化的自動化流程。
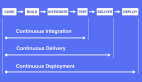
交付流水線的一個核心原則就是:將標準化的流程自動化。我們在其中制定了較多的流程和規范,以實現一個可靠的、可重復的持續交付流水線。
該過程會包含許多的內容,如:提交編譯階段的并行研發、編譯構建、單元測試,以及驗證階段的系統測試與集成測試。
最后是發布與運維階段的生產交付,涉及到某個發布的回滾,以及后繼的生產監控。這些過程都是在該流水線上完成的。
另外,該系統是一個多角色的平臺,上面會有一些負責開發的人員角色和一些運維測試的人員進行各種協調,使得該平臺對于我們整個團隊都能受益。
持續集成及云端交付
標準化建設
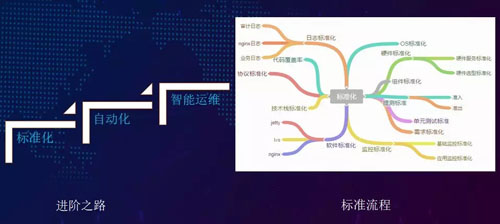
我們的自動化分為三個階段,分別是標準化、自動化和智能化。
在標準化方面,我們有硬件的標準化、組件的標準化,和技術棧的標準化(例如我們所用到的協議類型),以及監控的標準化。
在測試自動化方面,我們會涉及到廣泛的內容,包括:單元測試、單元覆蓋率、測試的準入準出條件,例如在交付的過程中,是否允許遺留一些 Bug 等。
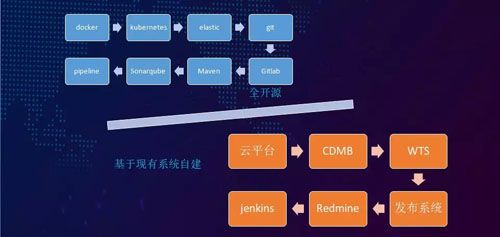
而在建設過程中曾有兩種可選的技術方案:
- 全開源,我們可以用 Docker 來進行環境自動化標準的相關操作,并且用 ES 來做日志系統。但是該方案對于我們現有系統的沖擊較大。
- 基于現有的各種平臺系統實踐,我們在 CMDB、發布平臺上做出了一些規范及流程。
最終我們選擇了第二個方案,當然在方案的實施過程中,由于需要對接的平臺較多,我們也遇到了不小的阻力。
鑒于這些平臺分散在 PMO、測試、運維等不同的部門,要打通這些部門,我們在開發的過程中就用到了不同的規范,例如:
- 在運維處,發布平臺會涉及到與機房有關的規范,包括機房里面有哪些服務器,服務器上又有哪些業務,哪些服務器是灰度環境的,哪些服務器屬于生產環境等。這些都是通過 CMDB 的業務樹來進行運營的。
- 在開發處,開發人員可能會用到一些全開源的平臺,如 Jenkins。由于它是完全開源,且未經改造過,那么其包含的各種運營規范和一些名字的標識,是無法與我們的業務樹相對應的。這些無不增加了改造的難度。
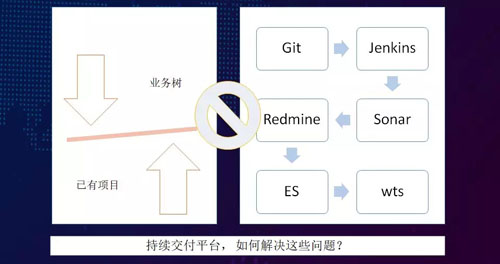
因此在該平臺建設中,我們的一種做法是統一入口。鑒于 Jenkins 是打包過的,我們完全可以調用 Jenkins 的 API,把該打包操作整合到自己的平臺之中。同時,我們把需求的信息也同步到了 Redmine。
此外,為了實現對 Bug 的錄入和跟蹤,我們將 Bug 錄入的入口也整合到此平臺之上。
此舉既不會對我們前期操作造成大的沖擊,又解決了相互間需求與Bug數量相關聯的問題。
最后由于它是一個多用戶的平臺,我們還需要把相關人員的信息(包括開發、測試、運維等負責人)都錄入、且同步到該系統之中。
自動化建設
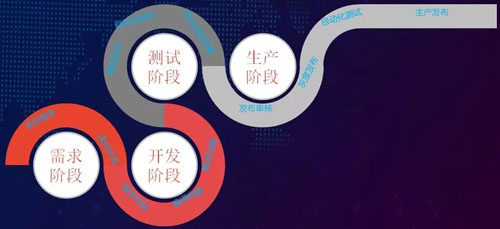
我們再來看持續集成流程:
- 首先是需求階段,比如:我們的某個產品運營人員會把他的需求錄入到該系統中。隨后開發負責人就會對此需求進行分析或預演,評估出一個交付的日期。
- 然后進入開發階段,包括編寫代碼、提交代碼、以及編譯構建。在構建的時候還會進行一些靜態的掃描,同時涉及到代碼的覆蓋率。
- 而在測試階段,系統又會進行一次測試環境的部署,同時進行一些自動化的測試,其中包括各種安全測試和性能測試。
當然,我們也會進行一些手動的驗證,來檢查它是不是符合測試的準入標準。如果有問題的話,該流程就會被退回開發部門,需要他們重新提交代碼,并再執行一次準入的流程。
- 如果該階段沒有問題的話,開發負責人或者業務運維人員就開始進行發布的審核,并且把代碼發布到灰度環境之中。
在灰度環境里,我們同樣需要做一些自動化的測試,以檢查該服務的安全性。只有達到其接口通過率,我們才能最后發布到生產環境中。
可見,從項目需求到發布的整個階段,我們都是在自己的平臺上進行操作的,整個交付流程實現了細粒度的進度管理。

下面我們再來看發布流程:
- 首先是環境檢查,這里主要檢查服務器上是否有一系列的用戶目錄,以及一些相關的權限。
- 同時,我們會從打包平臺將文件拉取到 IDC 處。
- 然后需要關閉監控。因為在該服務的部署過程中,會有短暫的不可用,進而會引發監控的報警;所以我們會針對相應的服務器進行監控的關閉。
- 當然也要將 Web 下線,從而使得新的流量不再涌入。
- 隨后便是停止服務,以確保該文件不會被占用。
- 我們進行更新文件操作。
- 我們在上述過程完成之后再啟動服務。
- 而在啟動服務之后,我們還需進行監控檢查。該檢查的主要目的是為了保證我們更新上去的服務為可用的。
- 隨后就是 Web 上線,我們把服務加入到 LVS 的集群之上。
- 最后再開啟監控。
在上述發布的過程中,我們會針對業務的某些特點進行并行或者串性的發布。這樣在能夠保證成功率的前提下,也能夠進一步地提升我們的發布效率。
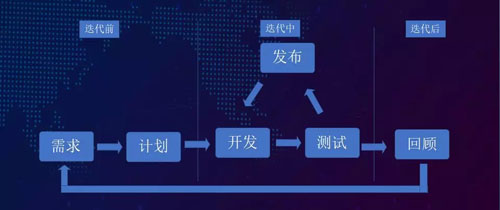
有了該持續交付平臺之后,我們就可以用它來支撐互聯網常見的、急速迭代的產品研發模式。
我們既可以實現迭代前的需求計劃,又能保證迭代中的開發、測試和發布,以及迭代后的回顧。
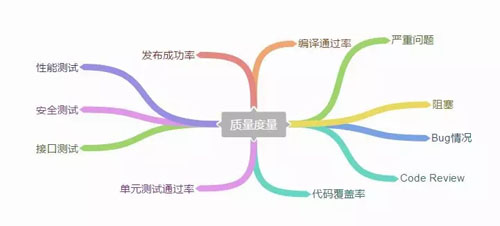
通過收集信息和數據,我們可以看到:系統在代碼質量上有沒有出現過嚴重的問題,有沒有發生阻塞的情況。
另外,Bug fix 的情況也是一目了然。我們還可以獲取代碼的覆蓋率,代碼測試的通過率,性能測試、安全測試和接口測試的數據。
同時,我們不但能夠獲知編譯的通過率、發布的成功率,還能夠獲取其他與效率相關的數據。
這些質量數據可以驅動和提升我們的技術能力,保證系統在上線前的質量。當然我們也可以利用這些數據來進一步地完善和優化交付流程,以確保交付過程的可靠。
運維智能化
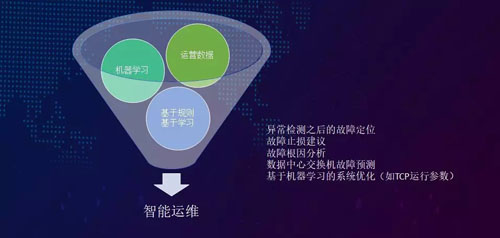
回顧上述自動化建設的三個階段,我們可以發現:運維智能化主要是通過搜集數據來進行學習,并實現分析和預測的目的。
例如:搜集的數據如果顯示近期磁盤的換盤率比較高,那么我們就能預測到該磁盤下一次可能出故障的時間。
同時,我們還能進一步預測那些可能導致數據中心全面癱瘓的關鍵交換機的出錯點。
古日旗,曾工作于金山和奇虎 360,參與過快盤、天擎等項目,2015 年加入魅族,現任職魅族科技運維架構師,負責運維自動化平臺建設。

【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】