













I/O多路復用,從來沒遇到過這么明白的文章
本文轉(zhuǎn)載自微信公眾號「 二馬讀書」,作者濤哥 。轉(zhuǎn)載本文請聯(lián)系 二馬讀書公眾號。
很多對技術有追求的讀者朋友,做到一定階段后都希望技術有所精進。有些讀者朋友可能會研究一些中間件的技術架構和實現(xiàn)原理。比如,Nginx為什么能同時支撐數(shù)萬乃至數(shù)十萬的連接?為什么單工作線程的Redis性能比多線程的Memcached還要強?Dubbo的底層實現(xiàn)是怎樣的,為什么他的通信效率非常高?
實際上,上面的一些問題都和網(wǎng)絡模型相關。本文從基礎的概念和網(wǎng)絡編程開始,循序漸進講解Linux五大網(wǎng)絡模型,包括耳熟能詳?shù)亩嗦窂陀肐O模型。相信讀完本文,大家會對網(wǎng)絡編程和網(wǎng)絡模型有一個較清晰的理解。
基本概念
我們先來了解幾個基本概念。
什么是I/O?
所謂的I/O(Input/Output)操作實際上就是輸入輸出的數(shù)據(jù)傳輸行為。程序員最關注的主要是磁盤IO和網(wǎng)絡IO,因為這兩個IO操作和應用程序的關系最直接最緊密。
磁盤IO:磁盤的輸入輸出,比如磁盤和內(nèi)存之間的數(shù)據(jù)傳輸。
網(wǎng)絡IO:不同系統(tǒng)間跨網(wǎng)絡的數(shù)據(jù)傳輸,比如兩個系統(tǒng)間的遠程接口調(diào)用。
下面這張圖展示了應用程序中發(fā)生IO的具體場景:
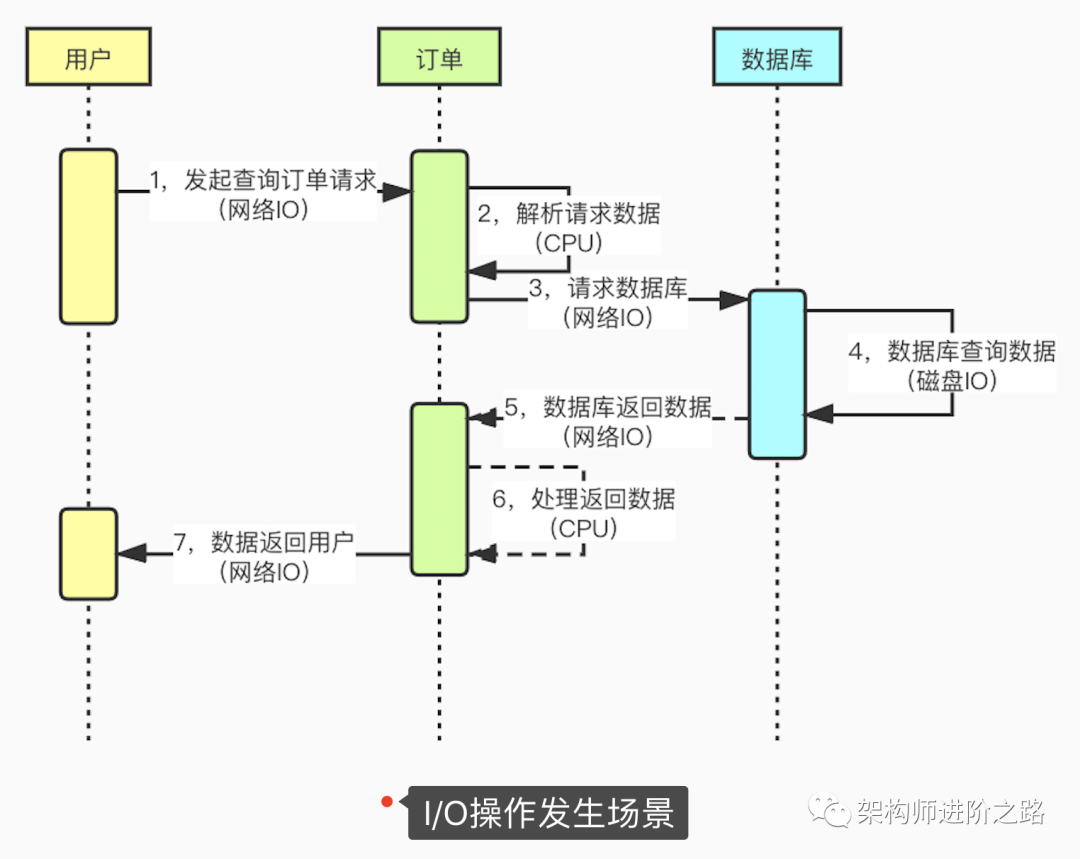
通過上圖,我們可以了解到IO操作發(fā)生的具體場景。一個請求過程可能會發(fā)生很多次的IO操作:
1,頁面請求到服務器會發(fā)生網(wǎng)絡IO
2,服務之間遠程調(diào)用會發(fā)生網(wǎng)絡IO
3,應用程序訪問數(shù)據(jù)庫會發(fā)生網(wǎng)絡IO
4,數(shù)據(jù)庫查詢或者寫入數(shù)據(jù)會發(fā)生磁盤IO
阻塞與非阻塞
所謂阻塞,就是發(fā)出一個請求不能立刻返回響應,要等所有的邏輯全處理完才能返回響應。
非阻塞反之,發(fā)出一個請求立刻返回應答,不用等處理完所有邏輯。
內(nèi)核空間與用戶空間
在Linux中,應用程序穩(wěn)定性遠遠比不上操作系統(tǒng)程序,為了保證操作系統(tǒng)的穩(wěn)定性,Linux區(qū)分了內(nèi)核空間和用戶空間。可以這樣理解,內(nèi)核空間運行操作系統(tǒng)程序和驅(qū)動程序,用戶空間運行應用程序。Linux以這種方式隔離了操作系統(tǒng)程序和應用程序,避免了應用程序影響到操作系統(tǒng)自身的穩(wěn)定性。這也是Linux系統(tǒng)超級穩(wěn)定的主要原因。
所有的系統(tǒng)資源操作都在內(nèi)核空間進行,比如讀寫磁盤文件,內(nèi)存分配和回收,網(wǎng)絡接口調(diào)用等。所以在一次網(wǎng)絡IO讀取過程中,數(shù)據(jù)并不是直接從網(wǎng)卡讀取到用戶空間中的應用程序緩沖區(qū),而是先從網(wǎng)卡拷貝到內(nèi)核空間緩沖區(qū),然后再從內(nèi)核拷貝到用戶空間中的應用程序緩沖區(qū)。對于網(wǎng)絡IO寫入過程,過程則相反,先將數(shù)據(jù)從用戶空間中的應用程序緩沖區(qū)拷貝到內(nèi)核緩沖區(qū),再從內(nèi)核緩沖區(qū)把數(shù)據(jù)通過網(wǎng)卡發(fā)送出去。
Socket(套接字)
Socket可以理解成,在兩個應用程序進行網(wǎng)絡通信時,一個應用程序?qū)?shù)據(jù)寫入Socket,然后通過網(wǎng)卡把數(shù)據(jù)發(fā)送到另外一個應用程序的Socket中。
所有的網(wǎng)絡協(xié)議都是基于Socket進行通信的,不管是TCP還是UDP協(xié)議,應用層的HTTP協(xié)議也不例外。這些協(xié)議都需要基于Socket實現(xiàn)網(wǎng)絡通信。5種網(wǎng)絡IO模型也都要基于Socket實現(xiàn)網(wǎng)絡通信。實際上,HTTP協(xié)議是建立在TCP協(xié)議之上的應用層協(xié)議。HTTP協(xié)議負責如何包裝數(shù)據(jù),而TCP協(xié)議負責如何傳輸數(shù)據(jù)。
絕大部分編程語言,都支持Socket編程,例如Java,Php,Python等等。而這些語言的Socket SDK都是基于操作系統(tǒng)提供的 socket() 函數(shù)來實現(xiàn)的。不管是Linux還是windows,都提供了相應的 socket() 函數(shù)。
Socket 編程過程
我們來看看Socket 編程過程是怎樣的。
不管Java、Python還是Php,很多編程語言都支持Socket編程。Linux,Windows等操作系統(tǒng)都開放了網(wǎng)絡編程接口。只不過,各種編程語言對底層操作系統(tǒng)提供的網(wǎng)絡編程接口做了封裝而已。
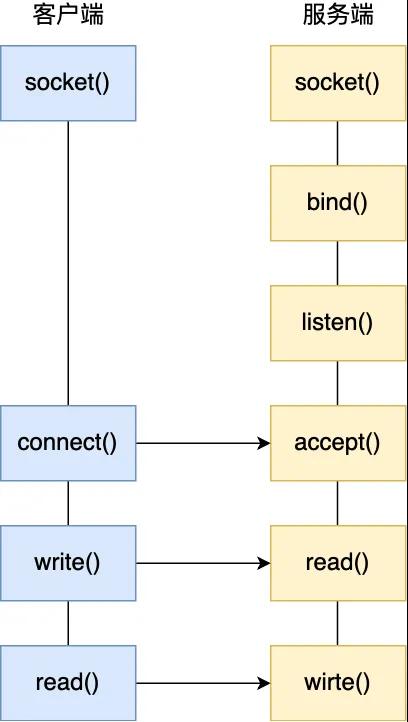
從服務端開始,服務端首先調(diào)用 socket() 函數(shù),按指定的網(wǎng)絡協(xié)議和傳輸協(xié)議創(chuàng)建 Socket ,例如創(chuàng)建一個網(wǎng)絡協(xié)議為 IPv4,傳輸協(xié)議為 TCP 的Socket。接著調(diào)用 bind() 函數(shù),給這個 Socket 綁定一個 IP 地址和端口,綁定這兩個的目的是什么?
- 綁定端口的目的:當內(nèi)核收到 TCP 報文,通過 TCP 頭里的端口號,來找到我們的應用程序,然后把數(shù)據(jù)傳遞給我們
- 綁定 IP 地址的目的:一臺機器可能有多個網(wǎng)卡,每個網(wǎng)卡都對應一個 IP 地址,只有綁定一個網(wǎng)卡對應的IP時,內(nèi)核在收到該網(wǎng)卡上的包,才會發(fā)給我們的應用程序
綁定完 IP 地址和端口后,就可以調(diào)用 listen() 函數(shù)進行監(jiān)聽。如果我們要判定服務器上某個網(wǎng)絡程序有沒有啟動,可以通過 netstat 命令查看對應的端口號是否被監(jiān)聽。
服務端進入了監(jiān)聽狀態(tài)后,通過調(diào)用 accept() 函數(shù),來從內(nèi)核獲取客戶端的連接,如果沒有客戶端連接,則會阻塞等待客戶端連接的到來。
那客戶端是怎么發(fā)起連接的呢?客戶端在創(chuàng)建好 Socket 后,調(diào)用 connect()函數(shù)發(fā)起連接,該函數(shù)的參數(shù)要指明服務端的 IP 地址和端口號,然后眾所周知的 TCP 三次握手就開始了。
連接建立后,客戶端和服務端就開始相互傳輸數(shù)據(jù)了,雙方可以通過 read()和 write() 函數(shù)來讀寫數(shù)據(jù)。
基于TCP 協(xié)議的 Socket 編程過程就結束了,整個過程如下圖所示:
網(wǎng)絡IO模型
5種Linux網(wǎng)絡IO模型包括:同步阻塞IO、同步非阻塞IO、多路復用IO、信號驅(qū)動IO和異步IO。
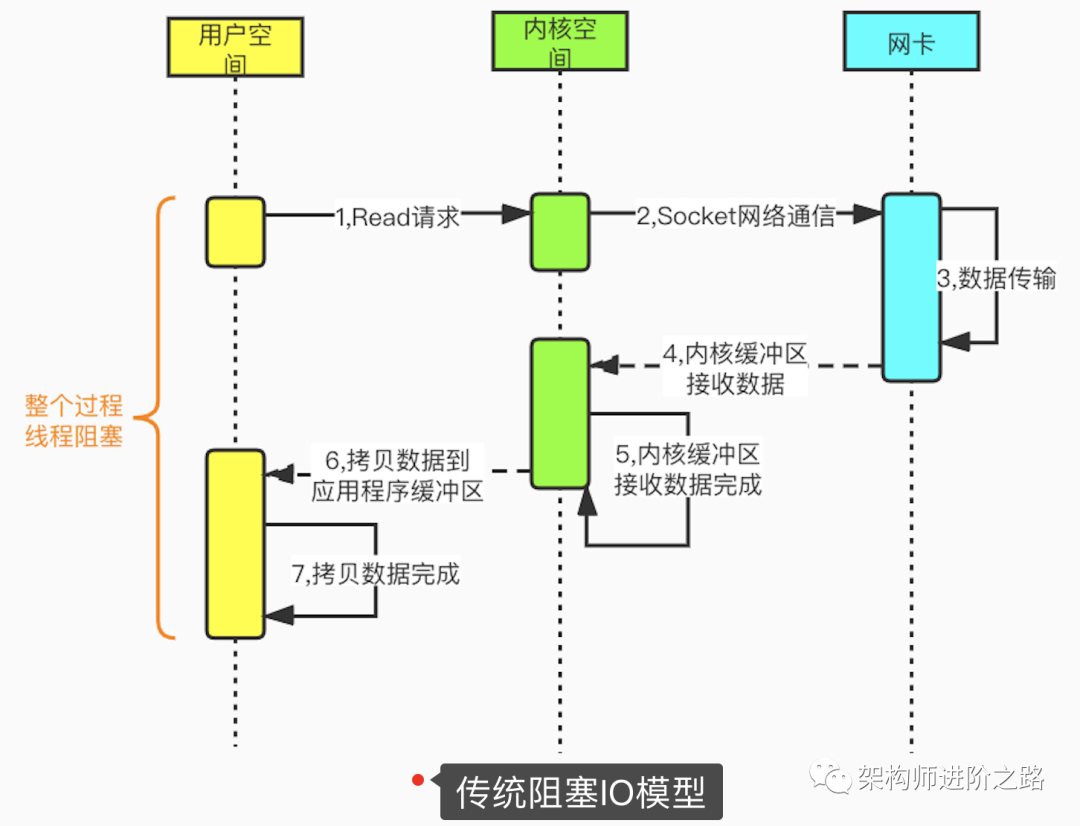
同步阻塞IO
我們先看一下傳統(tǒng)阻塞IO。在Linux中,默認情況下所有socket都是阻塞模式的。當用戶線程調(diào)用系統(tǒng)函數(shù)read(),內(nèi)核開始準備數(shù)據(jù)(從網(wǎng)絡接收數(shù)據(jù)),內(nèi)核準備數(shù)據(jù)完成后,數(shù)據(jù)從內(nèi)核拷貝到用戶空間的應用程序緩沖區(qū),數(shù)據(jù)拷貝完成后,請求才返回。從發(fā)起read請求到最終完成內(nèi)核到應用程序的拷貝,整個過程都是阻塞的。為了提高性能,可以為每個連接都分配一個線程。因此,在大量連接的場景下就需要大量的線程,會造成巨大的性能損耗,這也是傳統(tǒng)阻塞IO的最大缺陷。
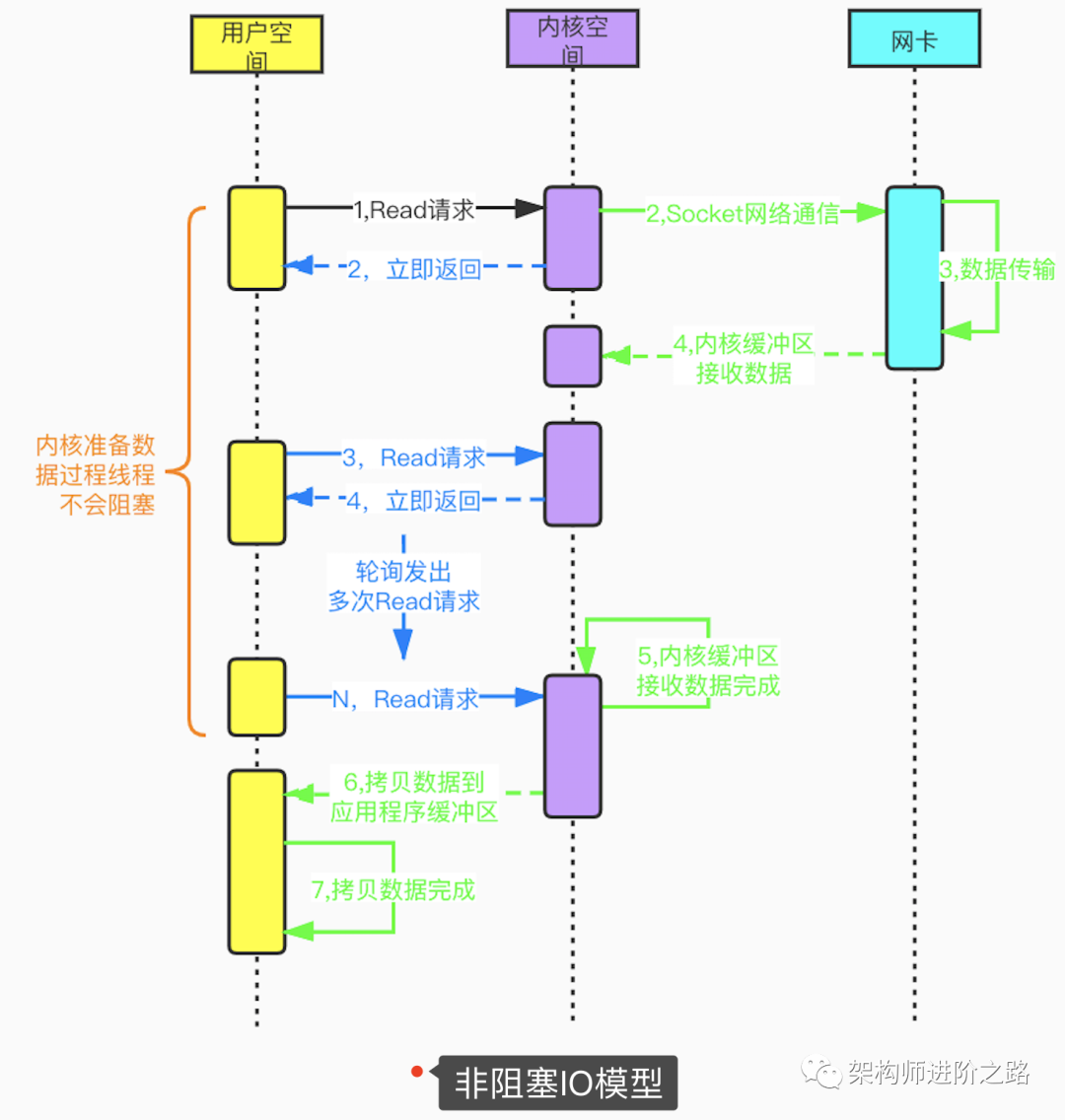
同步非阻塞IO
用戶線程在發(fā)起Read請求后立即返回,不用等待內(nèi)核準備數(shù)據(jù)的過程。如果Read請求沒讀取到數(shù)據(jù),用戶線程會不斷輪詢發(fā)起Read請求,直到數(shù)據(jù)到達(內(nèi)核準備好數(shù)據(jù))后才停止輪詢。非阻塞IO模型雖然避免了由于線程阻塞問題帶來的大量線程消耗,但是頻繁的重復輪詢大大增加了請求次數(shù),對CPU消耗也比較明顯。這種模型在實際應用中很少使用。
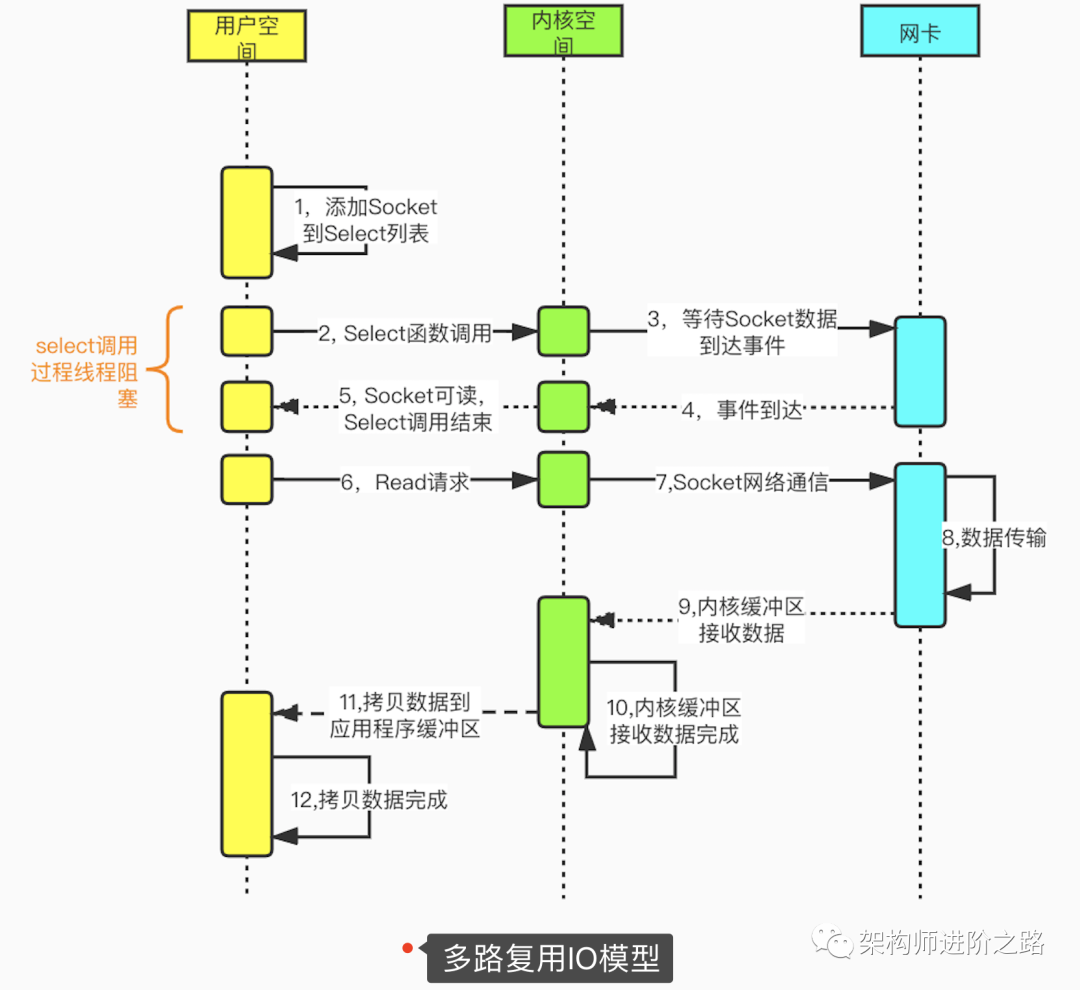
多路復用IO模型
多路復用IO模型,建立在多路事件分離函數(shù)select,poll,epoll之上。在發(fā)起read請求前,先更新select的socket監(jiān)控列表,然后等待select函數(shù)返回(此過程是阻塞的,所以說多路復用IO并非完全非阻塞)。當某個socket有數(shù)據(jù)到達時,select函數(shù)返回。此時用戶線程才正式發(fā)起read請求,讀取并處理數(shù)據(jù)。這種模式用一個專門的監(jiān)視線程去檢查多個socket,如果某個socket有數(shù)據(jù)到達就交給工作線程處理。由于等待Socket數(shù)據(jù)到達過程非常耗時,所以這種方式解決了阻塞IO模型一個Socket連接就需要一個線程的問題,也不存在非阻塞IO模型忙輪詢帶來的CPU性能損耗的問題。多路復用IO模型的實際應用場景很多,比如大家耳熟能詳?shù)腏ava NIO,Redis,Nginx以及Dubbo采用的通信框架Netty都采用了這種模型。
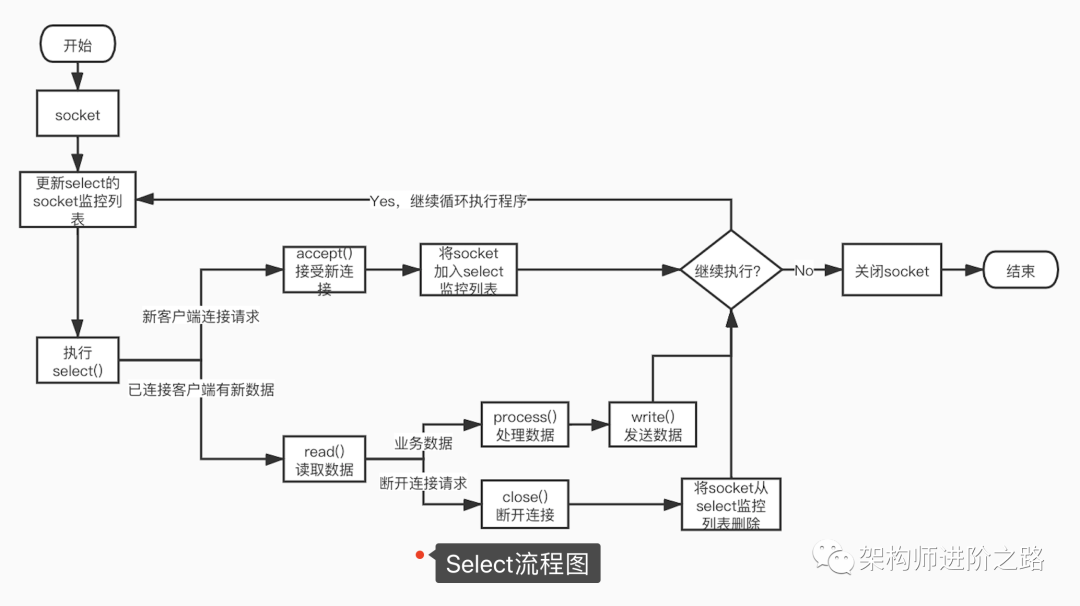
下圖是基于select函數(shù)Socket編程的詳細流程。
用一句話解釋多路復用模型。多路:可以理解成多個網(wǎng)絡連接(TCP連接)。復用:服務端反復使用同一個線程去監(jiān)聽所有網(wǎng)絡連接中是否有IO事件(如果有IO事件就交給工作線程從對應的連接中讀取并處理數(shù)據(jù))。
信號驅(qū)動IO模型
信號驅(qū)動IO模型,應用進程使用sigaction函數(shù),內(nèi)核會立即返回,也就是說內(nèi)核準備數(shù)據(jù)的階段應用進程是非阻塞的。內(nèi)核準備好數(shù)據(jù)后向應用進程發(fā)送SIGIO信號,接到信號后數(shù)據(jù)被復制到應用程序進程。
采用這種方式,CPU的利用率很高。不過這種模式下,在大量IO操作的情況下可能造成信號隊列溢出導致信號丟失,造成災難性后果。
異步IO模型
異步IO模型的基本機制是,應用進程告訴內(nèi)核啟動某個操作,內(nèi)核操作完成后再通知應用進程。在多路復用IO模型中,socket狀態(tài)事件到達,得到通知后,應用進程才開始自行讀取并處理數(shù)據(jù)。在異步IO模型中,應用進程得到通知時,內(nèi)核已經(jīng)讀取完數(shù)據(jù)并把數(shù)據(jù)放到了應用進程的緩沖區(qū)中,此時應用進程
直接使用數(shù)據(jù)即可。
很明顯,異步IO模型性能很高。不過到目前為止,異步IO和信號驅(qū)動IO模型應用并不多見,傳統(tǒng)阻塞IO和多路復用IO模型還是目前應用的主流。Linux2.6版本后才引入異步IO模型,目前很多系統(tǒng)對異步IO模型支持尚不成熟。很多應用場景采用多路復用IO替代異步IO模型。





















